一、PCIE与SATA区别
1 SATA是半双工,类似于打电话,同一时间只能一端发送或者接收数据;PCIE是全双工,双端可以同时发送或者接收数据;
2 PCIE是串行总线,速率计算,如果双边速率(单边除以2),一条lane计算如下:
| gen1 | 2.5Gbps×2 (双向通道)) /10=0.5GB/s |
| gen2 | ( 5Gbps×2 (双向通道)) /10=1GB/s |
| gen3 | ( 8Gbps×2 (双向通道) × ( 128bit/130bit )) /8≈2GB/s |
实际应用中,一般接入4个lane,即gen3 * 4。(注:上面是双边带宽,单边= 双边/2)
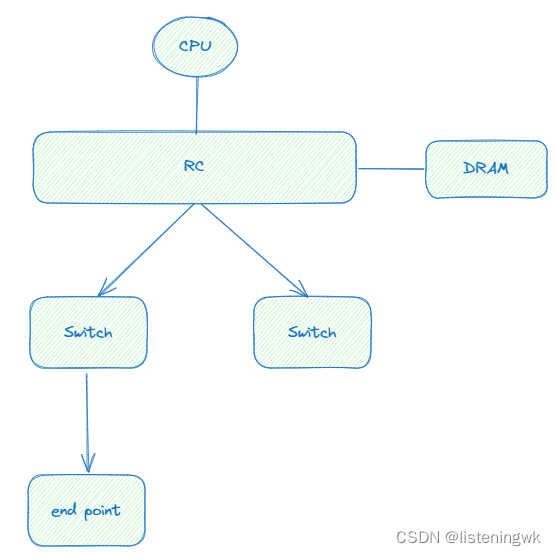
3 PCIE的拓扑结构
以及网状拓扑。PCIE使用的树形拓扑结构。
二、PCIE分层结构
PCIE通过事务层-> 数据链路层->物理层,数据包发送到硬件模块,接收端再经历相同的层次进行解析。发送是封装,解析是拆包。

 事务层负责发送或者接收TLP,以及流量控制、QoS、事务排序;
事务层负责发送或者接收TLP,以及流量控制、QoS、事务排序;
数据链路层创建或者解析DLLP、ACK/NAK、流控、电源管理;
物理层负责传输packet,平均发送到各个lane,加扰,然后接收时候解扰,以及编解码;

三、TLP类型
TLP有message TLP、 memory TLP、configuation TLP;以及complete TLP。(IO TLP不常用)
| message TLP | Msg MsgD |
| memory TLP | MRd、MWr |
| configuation TLP | CfgRd0、CfgRd1、CfgWr0、CfgWr1 |
| complete TLP | Cpl CplD |

MRd为例:
1 device发起TLP read,send到switch,switch也需要解析TLP包,转发给RC;
2 CPU把需要读取的数据放到DRAM,RC把DRAM内的data写入CplD中,然后传给switch,再传输给device,device收到解析cplD,拿到data
注:cplD一次最大携带4k数据,如果一笔数据16k,那么需要4次CplD传输才行(发送1次MRd);
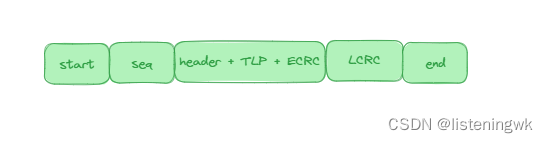
TLP的结构是header + data + ERC,其中比较重要的点就是header结构(参考深入浅出SSD):

不同的TLP类型,结构可能不完全相同,但是header基本一致
memory TLP具体是看header填地址是32位为还是64位,即映射到主机内存空间是否超过4GB,TLP格式对比如下:

如上图,如果TLP携带的地址超过32bit,那么TLP需要4DW。
configuration TLP用于初始化把device configuration映射到主机内存空间,方便主机访问,RC发送configuration TLP来读写device内部的configuration,实现配置空间映射。

这里可以提下两个TLP不同点,上面memory TLP包含了地址信息,host可以通过映射到主机地址空间的地址,去访问device;但是configuration TLP,只能通过Bus + Device + Func确定唯一的设备,加Ext Reg Number和register Number设置偏移,就可以访问到指定的地址。
message TLP用于报异常和中断 电源管理等信息。如下图:

complete TLP用于non-post类型的TLP,主要是收到TLP,回复信息,具体的header结构如下:

四、PCIE配置空间和地址空间
PCIE设备都有一段空间,Host可以通过读写该段空间,访问设备内部寄存器,获取该设备的一些信息,配置空间设定都是协议规定好的,具体可以参考nvme协议。

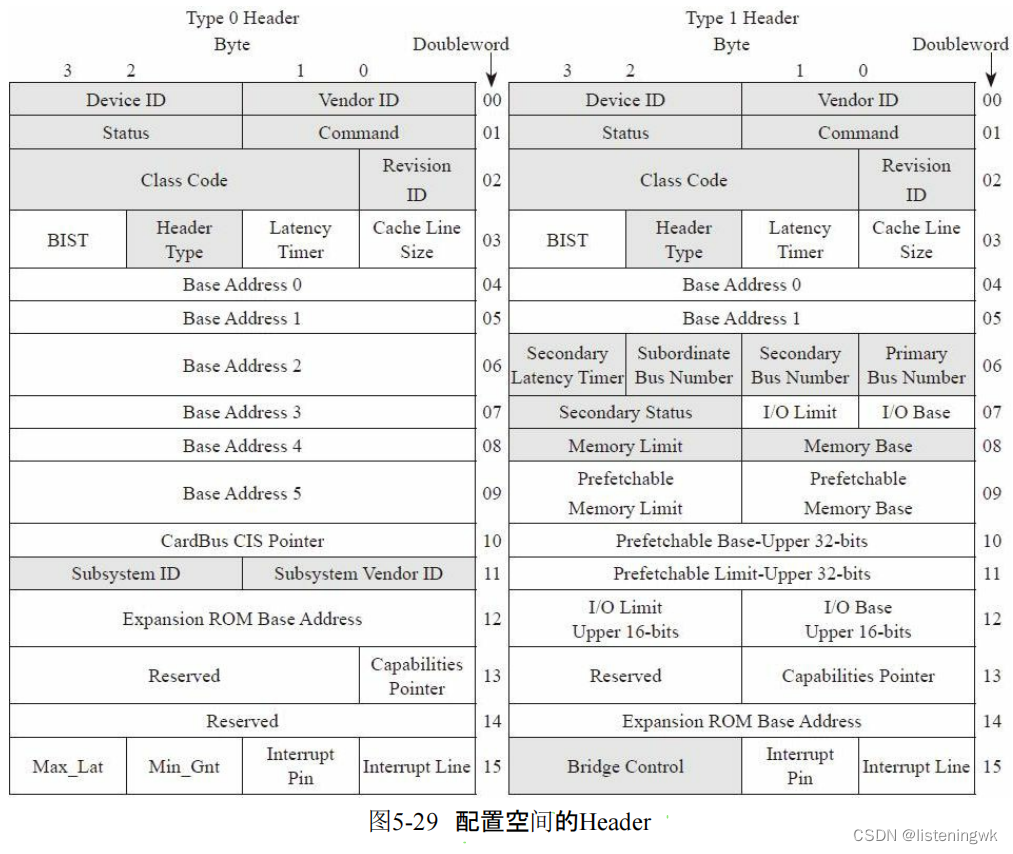
type0 是pcie设备的header,type1是switch的header;
pcie设备的配置空间需要映射到主机的内存空间。上电时,主机RC发送 configuration TLP读取设备的configuration中header里面bar地址,然后主机在内存中创建一个映射地址,作为该设备的内存地址空间,并将host开辟的地址写入到BAR中。
step1:RC发起configuration TLP read,读取configuration bar地址;
step2:由于bar地址有些是只读的属性(默认为0),不可写,因此,可以全1写入bar地址,如果有些bit位保持原样,那么是只读的;
step3:host在内存空间开辟4k buffer,映射设备的4k配置空间,并把基地址写入到bar地址。
一个pcie设备可能若干个内部空间需要映射,依次设置bar1 bar2...。 PCIE设备至少有一个4k的配置空间,有些设备包含几个功能(既能当网卡又能当硬盘),那么配置空间也对应几个,即function和配置空间一一对应。
五、TLP路由方式
其实,根据上面记录的知识点,也能了解到,memory TLP header内部包含地址信息,可以通过host内部地址空间找到指定pcie的映射地址,发送TLP到该设备,称之为地址路由。
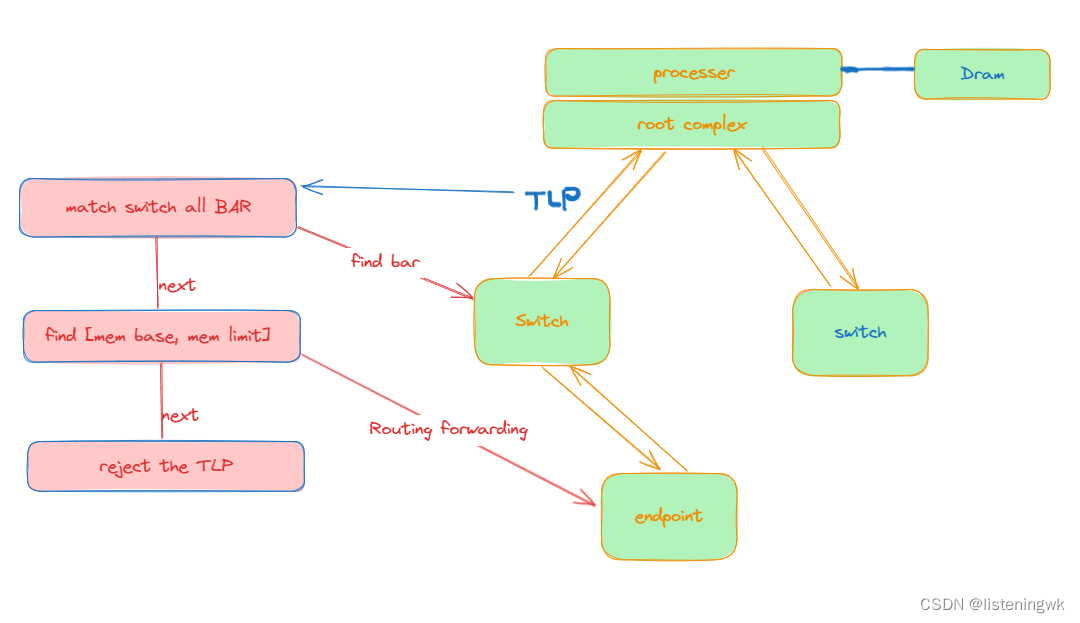
上图所示,Host发送TLP到Switch,首先匹配switch的配置空间的所有bar地址,如果匹配上了,那么switch解析该TLP,如果不是发给switch的TLP包,查看mem base + mem limt,即查看下游的设备的地址范围,如果在范围内,那么是发给下游设备的,switch此时发挥路由功能,转发该TLP包;否则就拒绝该TLP包。(上游->下游)
从下游到上游的情况:也是看Switch上面的bar地址,如果匹配了,那么就解析;如果是落到了[mem base, mem limit]上,需要拒绝该TLP(一般情况下,两个pcie设备不直接通信,会通过host),除去上面情况,向上发送TLP。
另外,当使用Bus + Device + Func去寻址,用于configuration TLP,主要用于映射设备配置空间到host的内存空间。
注意三个寄存器:Subordinate Bus Number、Secondary Bus Number和Primary Bus Number,

首先基于ID路由,如果RC发送TLP,如果此Switch的Bus + Device + Func与TLP上面信息匹配,那么就是发送给该Switch的TLP,如果不是,那么看Bus Number 是否是在Secondary Bus Number和Primary Bus Number之间,如果是,那么路由转化到下游设备。
还有一种路由方式是隐式路由,即RC发送TLP后,如果是广播TLP(TLP类型在header上标记),那么就转发,如果是终结message,那么收到此TLP,就接收于此,不再转发。上游到下游还是下游到上游,规则一样。
六、数据链路层
1 保证TLP包的数据一致性:握手协议ACK NAK、retry重传;
2 DLLP包来实现流量控制和电源管理;
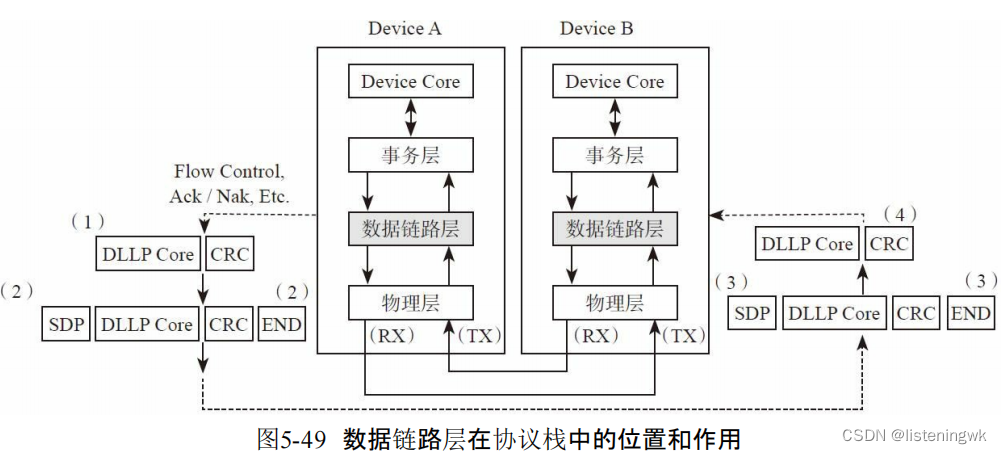
DLLP存在数据链路层,上层事务层感知不到。TLP包包含地址,可以跨越多个设备进行通信,但是DLLP是端-端通信,限制两个设备之间通信。
 ACK/NAK DLLP的流程如下:
ACK/NAK DLLP的流程如下:



七、物理层
1 物理层使用串行总线,差分信号;
2 data均分每个lane,编解码;