最近(2024年3月29日),号称比Python快6.8万倍的Mojo编程语言开源啦!6.8万倍?你敢相信这个数字是真的吗?不过,就连Mojo官网都把这个结果贴了出来(见下图),这就很难让你不对这个数字引起好奇。很显然,Mojo官方的结果难免有“自卖自夸”的嫌疑,但至少说明在某些特殊的场景下确实得到了这个数字,官网不会造假。那么,究竟是什么原因让Mojo能比Python快这么多呢?下面我们就揭开这一神秘的面纱,也借此机会让我们进一步了解Mojo这门比较火的编程语言。

Mojo简介
Mojo编程语言是由Modular公司开发的,旨在为人工智能领域提供统一的编程框架。它是基于Python语法的超集,结合了Python的易用性和C语言的性能,支持多核、向量单元和加速器单元等硬件功能。Mojo能够对大量低级AI硬件进行编程,模型扩展性更强,为开发者提供卓越的性能体验。Mojo的创始人是Chris Lattner,他是Swift语言的创始人,也参与了LLVM和Clang的开发。他与Google的机器学习产品经理Tim Davis共同创立了Modular公司,并在2022年推出了Mojo语言。
特殊的例子
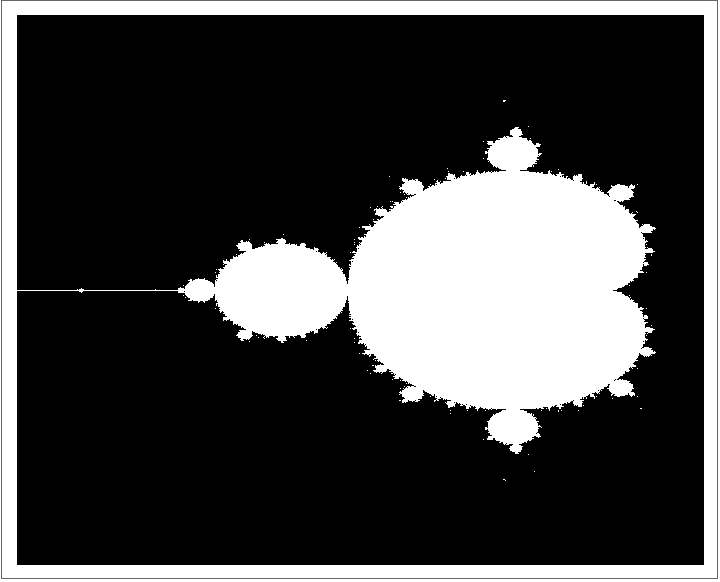
可以猜想,这个6.8万倍的结果是在一个特殊的例子上完成,具体来说,它计算和绘制了Mandelbrot集,就是下面的分图案。这是一个非常简单但是又非常耗费计算资源的例子,测试者也给出了选择这个作为例子的理由:
- 简单表达:只有很少的代码
- 纯计算:曼德勃罗集没有内存开销
- 容易并行
- 可向量化
所以6.8万倍的第1个秘密就是这个计算场景非常适合发挥Mojo的所有优势,这是经典的以己之长比别人之短。
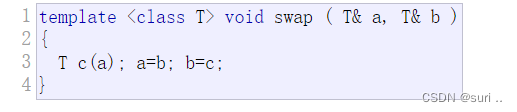
# 代码示例:下面函数中z是复数
MAX_ITERS = 1000
def mandelbrot_kernel(c): z = cnv = 0for i in range(MAX_ITERS):if abs(z) > 2:breakz = z*z + cnv += 1return nv编译语言vs解释语言
众所周知,Python是解释型语言,性能上天然会有一些劣势。Mojo是虽然语法上兼容Python(很多写法上是一样的),但却是一个编译语言。除此之外,Mojo除了像Python一样支持动态类型(在运行的时候才知道变量的类型),还支持另一种静态类型的写法(见下面代码示例),当使用静态类型的时候编译器可以提前对代码做出很多针对性的优化,提升性能。6.8万倍的第2个秘密就是这Mojo是一门支持静态类型的编译语言。
fn mandelbrot_2(c: ComplexFloat64) -> Int:var z = cvar nv = 0for i in range(1, MAX_ITERS):if z.squared_norm() > 4:breakz = z.squared_add(c)nv += 1return nv向量化
前面两个秘密其实还谈不上多神秘,很容易理解和想到。我认为接下来谈到的这个才算是Mojo真正厉害的地方。
正如宣传所说,Mojo是面向人工智能的语言,人工智能计算的特点是什么?大量的向量计算。于是Mojo对向量计算进行了针对性的优化,并且这种优化深入到了底层硬件。为此,Mojo内置了SIMD类型。
单指令多数据(SIMD)是一种并行处理技术,内置于许多现代CPU、GPU和定制加速器中。SIMD允许您一次对多个数据执行单个操作。例如,如果您想对数组中的每个元素求平方根,可以使用SIMD来并行化工作。
Mojo中的SIMD类型就是专门负责针对不同的CPU/GPU进行这种优化的,具体是实现细节在这里就不展开了。在原作者测试的机器上,CPU具有512bit长的向量寄存器,这意味着CPU可以一次操作512/64=8个双精度浮点数,理论上可以实现8x的加速,实测结果是实现了6x以上的加速。此外,原作者在SIMD的基础上还进行了进一步针对CPU的指令的优化:现代 x86 系统具有多个融合乘加(FMA)单元,使其能够在每个时钟周期执行多个 FMA。这一优化也将速度再原有基础上提升了一倍多,不过这一技巧很难适用于所有的计算场景,不多讨论。
鉴于Mojo内置了SIMD数据类型,所以实现上面的优化并不算复杂,这一向量化加速的技术还真是非常适合人工智能计算的场景呢。6.8万倍的第3个秘密就是SIMD向量化加速。
多线程加速
Python实是单线程的,如果要利用多核CPU的特性还需要一些特殊的处理,很不方便。Mojo是原生支持多线程的,可以很方便利用多核CPU的特性。用多核CPU对比Python的单核CPU,这不是作弊吗?确实,不过在这里我们先不谈公平问题,先看看在Mojo中是如何实现多线程加速的。
fn compute_row(chunk_idx:Int):let y = chunk_size * chunk_idxlet cy = min_y + y * scale_y@parameterfn compute_vector[simd_width:Int](w:Int):let cx = min_x + iota[DType.float64, simd_width]() * scale_xoutput.simd_store[simd_width](Index(h,w), mandelbrot_kernel(ComplexSIMD[DType.float64, simd_width](cx,cy))vectorize[num_ports * simd_width, compute_vector](width)# !!! 重点代码在这里with Runtime(num_cores()) as rt:parallelize[compute_row](rt, height)实事求是的说,在Mojo中实现并行确实方便的多啊!无论如何还是要为这一特性点个赞。所以6.8万倍的第4个秘密就是多线程并行加速。
原作者测试的机器具有88个CPU,通过这一“作弊行为”,直接将性能在原有的基础上提升了 30 倍,效果那是相当明显😀。但是你可能好奇,为什么没有提升到88倍呢?
负载均衡和数据倾斜
我相信“负责均衡”和“数据倾斜”这两个概念至少有一个你是比较熟悉的,通俗点讲它们都反应了一个问题:分工不均,活都让少数人干了。这就是上面的例子中为什么88核CPU只实现了30倍加速的原因:计算在88个CPU中并不是均匀分布的。那么如何进一步优化呢?
方法其实也并不复杂,我们可以把任务进一步拆分成更小的单元,拆分的越细,平均分配给每个cpu之后越不容易产生“分工不均”的现象(如果你写过Spark,应该听过这个最佳实践:任务/Task的数量最好是Executor/Core数量的2-3倍,而不是等于)。值得庆幸的是,Mojo 包含一个高性能并发运行时,因此我们不必自己创建线程池或进行循环选择和执行。Mojo 的运行时包含高级功能,可以充分利用像这样的多核系统。
# 只需要对原来代码做很少改动
with Runtime(num_cores()) as rt:let partition_factor = 16 # Is autotuned.parallelize[compute_row](rt, height, partition_factor * num_cores())6.8万倍的第5个秘密就是负载均衡。
总结
以上每一个优化都会使得性能提升几倍到数十倍不等,这些数字相乘之后确实就得到了6.8万这一耸人听闻的数字。一路学习了解下来,我觉得Mojo确实是一门相当不错的编程语言,同时Mojo团队也是很懂营销啊!
关注【黑客悟理】,不错过任何奇奇怪怪的知识
参考资料
- https://www.modular.com/blog/how-mojo-gets-a-35-000x-speedup-over-python-part-1
- https://www.modular.com/blog/how-mojo-gets-a-35-000x-speedup-over-python-part-2
- https://www.modular.com/blog/mojo-a-journey-to-68-000x-speedup-over-python-part-3
- https://mojocn.org/
如果你喜欢我的文章,欢迎到我的个人网站关注我,非常感谢!