概念背景
IO的本质就是输入输出
刚开始学网络的时候,我们简单的写过一些网络服务,其中用到了read,write这样的接口,当时我们用的就是基础IO,高级IO主要就是效率问题。
我们在应用层调用read&&write的时候,本质就是把数据由用户层写给OS,所以这些函数本质就是拷贝函数。
在应用层,尤其是在网络通信的时候,我们在IO的时候,其实大部分的时间都是在做 “等待” 的操作,只有数据来了,才进行拷贝,所以IO = 等待 + 拷贝。但是大部分时间都花在了 等 上面,所以IO本质就是 等 + 拷贝。
因此要进行拷贝,我们必须先判断条件是否成立,在网络IO这里,我们叫做读写事件是否就绪。
在了解了IO的本质之后,我们就理解什么是高效的IO了,高效的IO在IO过程中,等所占的比重越小,IO的效率越高。 所以几乎所有提高IO效率的策略都是为了降低等待的时间。
我们之前写过简单的线程池,为什么线程池效率高呢?很大的原因都是线程们的等待是并行的,减少了等待所占的时间比重,所以效率高。
五种IO模型
介绍
1.阻塞IO:也是最常见的IO模型,在内核数据准备好之前,系统调用一直会阻塞式的等待。所有的套接字,默认都是阻塞方式。
2.非阻塞IO:如果内核数据尚未准备好,那么系统调用会直接返回,返回EWOULDBLOCK错误码。非阻塞IO往往需要程序猿通过轮询的方式不断尝试读写文件描述符,对CPU来说是比较大的浪费。
3.信号驱动IO:内核数据准备好的时候,使用SIGIO的信号通知应用程序进行IO操作。
4.多路转接/复用IO:以阻塞等待的方式,同时等待多个文件描述符的就绪状态。
以上的IO都是同步IO。
5.异步IO:由内核在数据拷贝完成时,通知应用程序。(注意不是数据准备好,而是拷贝完成)可以理解为用户给OS一个缓冲区,OS一有数据就自动将数据拷贝到缓冲区里,等缓冲区满了就通知应用程序。也就是进程并不参与IO具体的过程。
阻塞IOvs非阻塞IO
因为IO = 等 + 拷贝,所以阻塞IO和非阻塞IO的IO效率是一样的,但是因为非阻塞IO可以在等待失败返回后做一下其他事情,所以效率会比阻塞IO的高一些。因此阻塞IO和非阻塞IO的区别只是等的方法不同而已。
同步IOvs异步IO
是否是同步IO,就看特定的某个进程是否参与了IO,这个参与可以是参与了等,也可以是参与了拷贝。只要参与了就是同步IO。
而异步IO的本质是不参与IO,它只是发起IO,最后拿结果就可以了。
另外,同步IO中的同步与线程同步里的同步是两个完全不同的东西。同步IO指的是IO层面上的概念,而线程同步的同步是指线程之间谁先运行,谁要等待的问题。
这些IO模型里面,效率最高的就是多路复用IO。异步IO往往会带来IO混乱。
非阻塞IO/fcntl
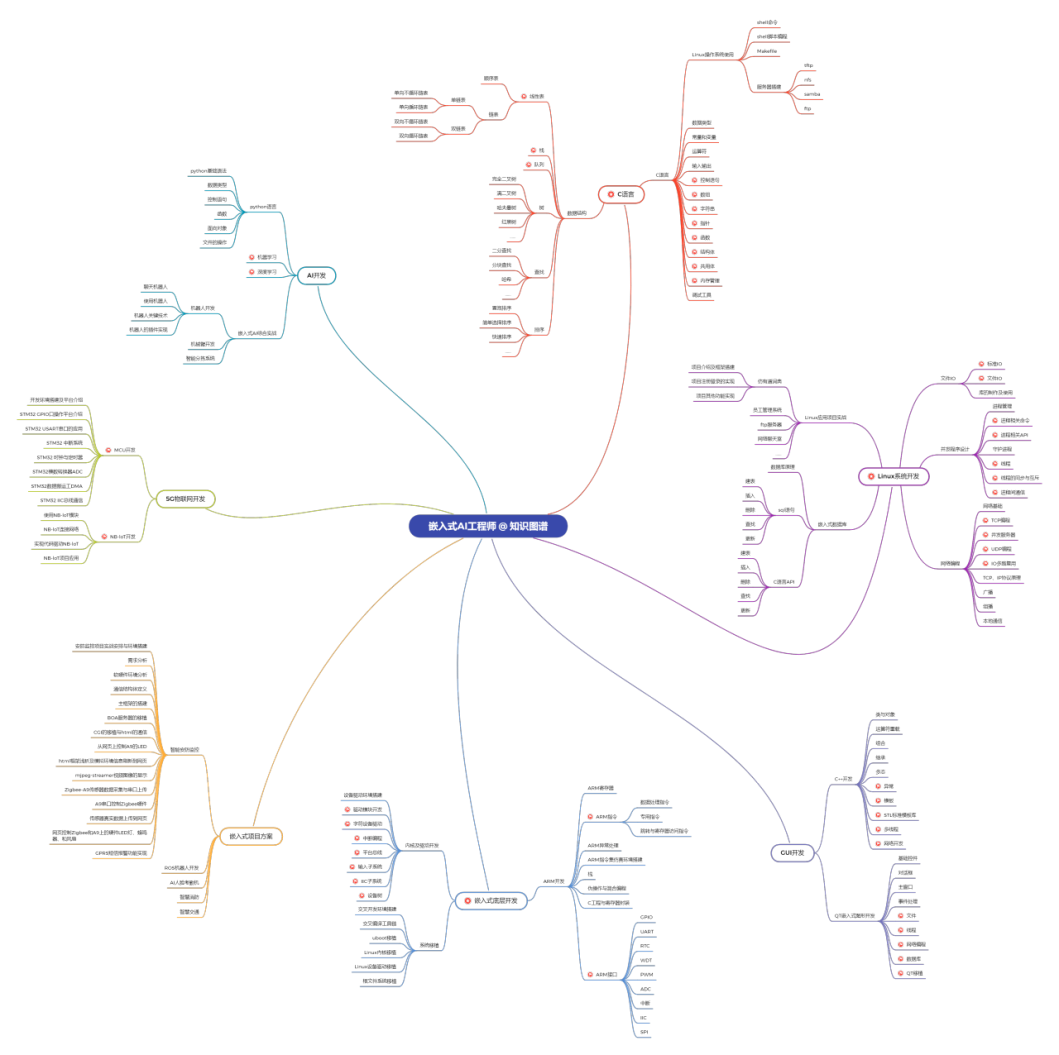
先看看recv,read也可以
我们看到recv前三个参数跟read一模一样,但是多了个flags ,看看read的

以前flags我们默认都是设置为0,代表是阻塞式读取,我们可以进行设置flags来设置非阻塞。
除此之外,我们还可以用fcntl 来直接对文件描述符进行设置

其中cmd可以传入以下:
void SetNoBlock(int fd)
{ int fl = fcntl(fd, F_GETFL); if (fl < 0) { perror("fcntl");return; }fcntl(fd, F_SETFL, fl | O_NONBLOCK);
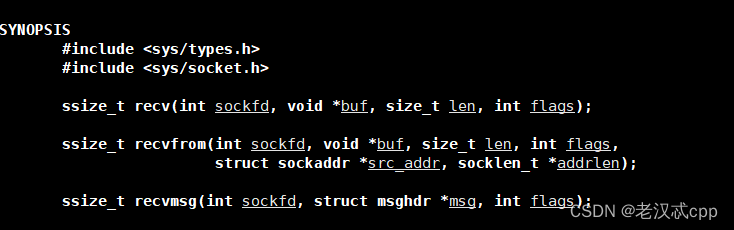
}如果我们设置成为非阻塞,如果底层fd数据没有就绪,recv/read/write/send就会以出错的形式返回。所以,如果如果有错误形式返回了,它有两种情况:
1.真的出错了。
2.底层没有就绪。
可以通过errnor进行区分。底层没有就绪的错误码是11(EWOULDBLOCK)。
例,当返回值小于0时
多路转接之select
多路转接也是五种IO模型中的一种。
以前我们学到的所有接口都是既做等又做拷贝的,所以效率就很难提高。
 而select只可以做等的工作,函数原型
而select只可以做等的工作,函数原型
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);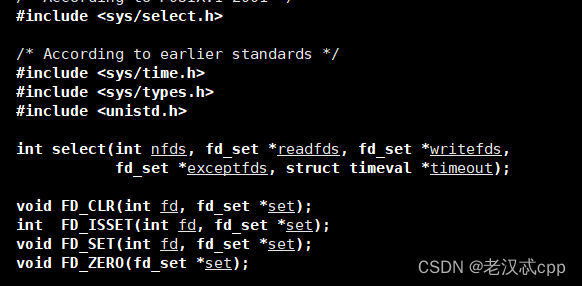
新标准只要包一个头文件就可以了,就是
#include <sys/select.h>select只负责等,并且可以一次等待多个fd。
程序会在select这里等待,直到监视的文件描述符有一个或多个发生了状态的改变。
参数解释:
nfds就是需要监视的最大文件描述符 + 1。
后面的readfds,writefds,exceptfds其实本质都是位图,所对应的就是需要检测的文件描述符的可读/可写/是否出错的集合。虽然fd_set也是一个结构体,但是里面是位图。它们都是输入输出型参数,我们也可以同时传入多个fd_set表示我们关心多个状态的就绪。
对于输入输出理解:
1.输入时:是用户告诉内核,要内核关心哪些fd,哪些fd就绪了,要及时告诉用户。
2.输出时:是内核告诉用户,哪些fd就绪了,要用户赶快处理。
因为是位图结构的,那么:
比特位的位置代表的是文件描述符的编号。
比特位的内容,代表是否需要内核关心。
所以fd_set本质是一张位图,它是让用户与内核之前传递fd是否就绪的信息的。
所以我们在使用select的时候,会先有大量的位图操作。

位图的操作接口
void FD_CLR(int fd, fd_set *set); // 用来清除描述词组set中相关fd 的位int FD_ISSET(int fd, fd_set *set); // 用来测试描述词组set中相关fd 的位是否为真void FD_SET(int fd, fd_set *set); // 用来设置描述词组set中相关fd的位void FD_ZERO(fd_set *set); // 用来清除描述词组set的全部位timval是一个结构体,用来设置select()的等待时间。
它的定义如下
struct timeval
{
__time_t tv_sec; /* Seconds. */
__suseconds_t tv_usec; /* Microseconds. */
};这个tv_sec也就是秒,tv_usec就是微秒。
我们在设置 timeout的时候,一般是 timeout = {5,0},其中这个5代表的含义就是5秒timeout一次,如果是{0.0},那么就是立马返回,没有阻塞。或者我们也可以直接将timeout设置成为NULL,表示阻塞等待。这个timeval也是输入输出型参数。
即便还在等待时间里,只要有fd就绪了,就立马返回,假设是在2秒的时候就绪了,然后返回,那么timeout里面的值就变成了{5 - 2 = 3,0}也就是{3,0},就是剩余的返回时间。如果一个fd都没有就绪,那么会在timeout被减到0的时候自动返回一次,那么此时的timeout已经是{0,0}了,也就是非阻塞了。因此timeout可能要进行周期的重复设置。
关于select的返回值:
1.n > 0:有n个fd就绪了。
2.n == 0:超时了,没有出错,但是也没有fd就绪。
3.n < 0:出错了。
所以现在我们写网络服务的时候,就不能直接accept了,因此accept也是检测并获取listensock上面的事件,期间也是在阻塞式等待,新连接到来,等价于读事件就绪了。
所以我们可以先用select进行等待,如果select告诉用户就绪了,那么接下来的一次读取fd的时候,就不会被阻塞了,因为已经不需要等了,只要读了。
如果事件就绪了,上层不处理,那么select会一直通知用户。
简单实现基于select的多路转接的echo服务器:
SelectServer.hpp
#pragma once#include <iostream>
#include <sys/select.h>
#include <sys/time.h>
#include "Socket.hpp"
#include "Log.hpp"using namespace std;static const int defaultport = 8080;
// *8是因为一字节有8个比特位,一个比特位就可以表示一个fd
static const int fd_num_max = (sizeof(fd_set) * 8);
int defaultfd = -1;class SelectServer
{
public:SelectServer(uint16_t port = defaultport):_port(port){for(int i = 0; i < fd_num_max; ++i){fd_array[i] = defaultfd;}}bool Init(){_listensock.Socket();_listensock.Bind(_port);_listensock.Listen();return true;}void Accepter(){// 说明连接事件就绪了std::string clientip;uint16_t clientport = 0;;int sock = _listensock.Accept(&clientip,&clientport); // 这里已经不会再阻塞了,select已经帮我们等完了if(sock < 0) return;lg(Info,"accept success,%s : %d,sock fd : %d",clientip.c_str(),clientport,sock);//这里下标是从1开始的,因为0号下标是listensockfd的。int pos = 1;for(;pos < fd_num_max; ++pos) // 这里是第二个循环,是为了将新的fd插入到用户维护的数组中{if(fd_array[pos] != defaultfd)continue;else break;}if(pos == fd_num_max){lg(Warning,"server is full,close %d now!",sock);close(sock);}else {fd_array[pos] = sock;PrintFd();}}void Recver(int fd,int pos){// 这里只是一个demo,我们并没有处理都上来的数据是否是完整的报文char buffer[1024];ssize_t n = read(fd,&buffer,sizeof(buffer) - 1); //数据不一定完整 ,但是这里不会阻塞了if(n > 0){buffer[n] = 0;cout << "get a messge : " << buffer << endl;}else if(n == 0) // 对方关闭连接了{lg(Info,"client quit , me too, close fd is : %d",fd);close(fd);fd_array[pos] = defaultfd; // 这里本质是从select中移除}else {// 读出错了也要关闭lg(Warning,"recv error : fd is : %d",fd);close(fd);fd_array[pos] = defaultfd; // 本质还是从select中移除}}void Dispatcher(fd_set& rfds) // 任务派发器{for(int i = 0; i < fd_num_max; ++i) // 这里是第三个循环了{int fd = fd_array[i];if(fd == defaultfd)continue;if(FD_ISSET(fd,&rfds)){if(fd == _listensock.Fd()) // 说明是新链接就绪了{Accepter(); // 连接管理器}else // 说明某个链接的读事件就绪了{Recver(fd,i);}}}}void Start(){int listensock = _listensock.Fd();fd_array[0] = listensock;while(true){fd_set rfds;FD_ZERO(&rfds);int maxfd = fd_array[0];for(int i = 0; i < fd_num_max; ++i) // 第一次循环{if(fd_array[i] == defaultfd)continue;FD_SET(fd_array[i],&rfds);if(maxfd < fd_array[i]){maxfd = fd_array[i];lg(Info,"maxfd updata,maxfd is : %d",maxfd);}}// 这里不能直接accept了,read也是,因为是单进程的,如果直接用// 这里直接就因为一个链接可能就阻塞了struct timeval timeout = {1,0}; // 因为是输入输出型参数,所以要周期的重复设置int n = select(maxfd + 1,&rfds,nullptr,nullptr,&timeout);if(n > 0){// 说明有事件就绪了cout << "get a new link" << endl;// 我们也不知道是一个就绪了还是多个就绪了// 而且这里也不知道是新链接来了,还是读事件就绪了Dispatcher(rfds); }else if(n == 0){cout << "time out ..." << endl;}else if(n == -1){cout << "select error!!!" << endl;}}}void PrintFd(){cout << "online fd list : ";for(int i = 0; i < fd_num_max; ++i){if(fd_array[i] == defaultfd)continue;cout << fd_array[i] << " ";}cout << endl;}~SelectServer(){_listensock.Close();}
private:Sock _listensock;uint16_t _port;int fd_array[fd_num_max]; // 这是用户维护的数组。
};select那里,rfds也是输入输出型参数,它的输出就是告诉我们哪些fd就绪了,将位图对应的位置修改成1,没有就绪的修改成0。 比如一开始传入的是1111 1111,假如只有一个fd就绪了,那么它返回的就是0000 0001,可见,其他的只是会被置为0的,如果我们还要对其他的fd继续关心,就需要我们在用户层维护一个数组,表示我们要关心哪些fd。
因为这里我们写的比较简单,只关心读事件,所以也只维护了一个读事件的数组,将来如果要关心写,或者异常事件,那么还需要相应的增加数组。
我们每次在select前,都要重新对位图进行设置,这个时候就要用循环来遍历我们维护的数组,将它设置进位图当中,另外select传入的fd,表示的是我们需要关心的最大fd + 1,那么也就是需要我们每次循环都要知道当前的maxfd是多少,所以在每次在select前,还要顺便在这个循环中更新出maxfd。
另外,fd_set位图的比特位最多是1024个,也就是最多能表示1024个fd。
timeval参数那里,我们也可以传入nullptr,这样就是阻塞式等待了。
在任务派发器那里,因为就绪的不一定只有1个fd,因此我们又加上了一个循环,以便将这次就绪的fd全部处理。
Main.cc
#include <memory>
#include "SelectServer.hpp"int main()
{std::unique_ptr<SelectServer> svr(new SelectServer());svr->Init();svr->Start();return 0;
}之间一直使用的Socket.hpp简单加入了setsockopt,顺便复习一下
Socket.hpp
#pragma once#include <iostream>
#include <string>
#include <unistd.h>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "Log.hpp"enum
{SocketErr = 2,BindErr,ListenErr
};const int backlog = 10;class Sock
{
public:Sock(){}~Sock(){}public:void Socket(){sockfd_ = socket(AF_INET,SOCK_STREAM,0);if(sockfd_ < 0){lg(Fatal,"socker error,%s: %d",strerror(errno),errno);exit(SocketErr);}int opt = 1;setsockopt(sockfd_,SOL_SOCKET,SO_REUSEADDR | SO_REUSEPORT,&opt,sizeof(opt)); // 防止服务器挂掉后不能立即重启。}void Bind(uint16_t port){struct sockaddr_in local;memset(&local,0,sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if(bind(sockfd_,(struct sockaddr*)&local,sizeof(local)) < 0){lg(Fatal,"bind error, %s: %d",strerror(errno),errno);exit(BindErr);}}void Listen(){if(listen(sockfd_,backlog) < 0){lg(Fatal,"listen error,%s: %d",strerror(errno),errno);exit(ListenErr);}}int Accept(std::string *clientip,uint16_t *clientport) // 两个输出型参数{struct sockaddr_in peer;socklen_t len = sizeof(peer);int newfd = accept(sockfd_,(struct sockaddr*)&peer,&len);if(newfd < 0){lg(Warning,"accept error,%s: %d",strerror(errno),errno);return -1;}// 开始准备输出ip和端口号char ipstr[64];inet_ntop(AF_INET,&peer.sin_addr,ipstr,sizeof(ipstr));*clientip = ipstr;*clientport = ntohs(peer.sin_port);return newfd;}bool Connect(const std::string &ip,const uint16_t &port){struct sockaddr_in peer;memset(&peer,0,sizeof(peer));peer.sin_family = AF_INET;peer.sin_port = htons(port);inet_pton(AF_INET,ip.c_str(),&(peer.sin_addr));int n = connect(sockfd_,(struct sockaddr*)&peer,sizeof(peer));if(n == -1){std::cout << "connect to " << ip << ":" << port << "error" << std::endl;return false;}return true;}void Close(){close(sockfd_);}int Fd(){return sockfd_;}
private:int sockfd_;
};select总结:
优点:
1.就如实现的那样,select已经是多路转接的一种方案了,我们可以把所有的fd交给select去等待,就绪后通知我们去处理,这样的话即便是单进程也可以高效的处理多个fd的读写事件。
缺点:
1.等待的fd数量是有上限的(centos中是1024个)。这不是操作系统的限制,而是它的接口设计就是这样的。(这也是最大的缺点)
2.输入输出型参数比较多,用户到内核,内核到用户,数据拷贝频率较高。
3.也是因为输入输出型参数比较多,每次都要对关心的fd进行事件重置。
4.对于用户层,使用第三方数组来管理用户的fd,用户层需要很多次遍历。对于内核层,检测fd事件就绪,也要遍历。
所以总的看来,select在所有的IO中效率算高的,毕竟它是多路转接的一种方案,但是它实际上会有很多的拷贝和遍历,这也是比较影响效率的。
一般select在小型的场景下可以简单使用。
多路转接之poll
学完select之后,我们明白了select有很多的短板,我们看poll是如何解决的。

这里的timeout跟select不一样,这里是一个整形,代表的单位是毫秒。
其中这个pollfd的结构体
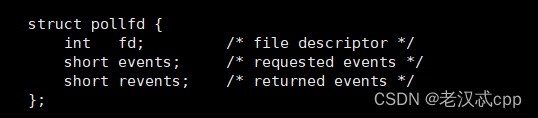
看描述就可以知道,events 是我们需要内核关心哪些事件,而revents则是内核告诉用户,哪些事件就绪了,而fd则是我们告诉内核是哪个文件描述符需要被关心。
所以poll这里我们第一个参数传入的是一个结构体数组,第二个参数是结构体数组的大小。
因此,poll最大的特点的是,将输入和输出事件进行了分离!
关于events的传参,这里也设计成了位图的样子
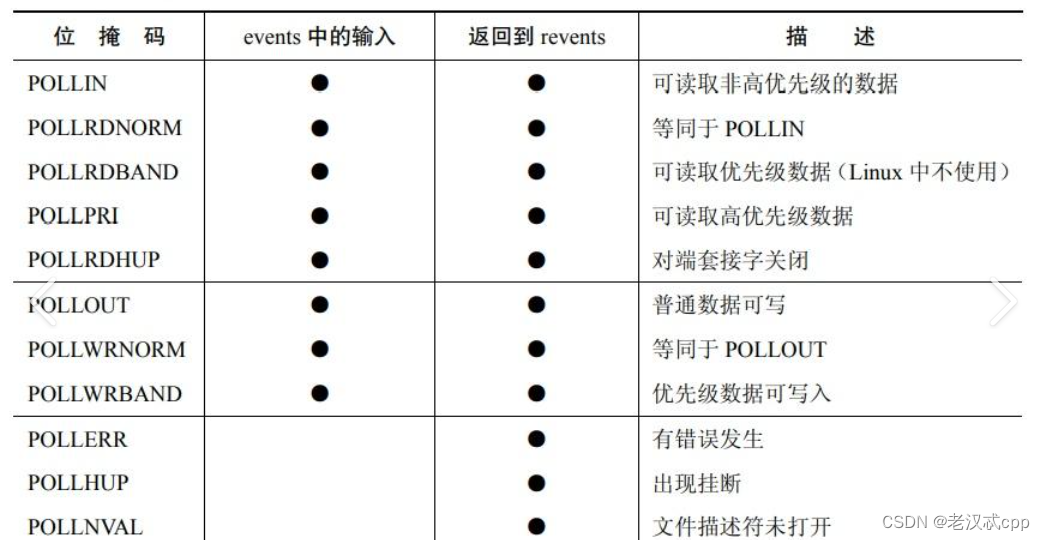
通过传入不同的参,来表示关心的事件。这些大写的都是宏。这里我们可以重点看POLLIN和POLLOUT,分别代表的读和写。
简单讲代码替换成基于poll实现的服务器
PollServer.hpp
#pragma once#include <iostream>
#include <poll.h>
#include <time.h>
#include "Socket.hpp"
#include "Log.hpp"using namespace std;static const int defaultport = 8080;
static const int fd_num_max = 128; // 这里直接设置成65535也没问题
int defaultfd = -1;
int non_event = 0;class PollServer
{
public:PollServer(uint16_t port = defaultport):_port(port){for(int i = 0; i < fd_num_max; ++i){_event_fds[i].fd = defaultfd;_event_fds[i].events = non_event;_event_fds[i].revents = non_event;}}bool Init(){_listensock.Socket();_listensock.Bind(_port);_listensock.Listen();return true;}void Accepter(){// 说明连接事件就绪了std::string clientip;uint16_t clientport = 0;;int sock = _listensock.Accept(&clientip,&clientport); // 这里已经不会再阻塞了,select已经帮我们等完了if(sock < 0) return;lg(Info,"accept success,%s : %d,sock fd : %d",clientip.c_str(),clientport,sock);int pos = 1;for(;pos < fd_num_max; ++pos) // 这里是第1个循环,是为了将新的fd插入到用户维护的数组中{if(_event_fds[pos].fd != defaultfd)continue;else break;}if(pos == fd_num_max){lg(Warning,"server is full,close %d now!",sock);close(sock);}else {_event_fds[pos].fd = sock;_event_fds[pos].events = POLLIN; // 如果要同时关心读写, POLLIN | POLLOUT_event_fds[pos].revents = non_event;PrintFd();}}void Recver(int fd,int pos){// 这里只是一个demo,我们并没有处理都上来的数据是否是完整的报文char buffer[1024];ssize_t n = read(fd,&buffer,sizeof(buffer) - 1); //数据不一定完整 ,但是这里不会阻塞了if(n > 0){buffer[n] = 0;cout << "get a messge : " << buffer << endl;}else if(n == 0) // 对方关闭连接了{lg(Info,"client quit , me too, close fd is : %d",fd);close(fd);_event_fds[pos].fd = defaultfd; // 这里本质是从select中移除}else {// 读出错了也要关闭lg(Warning,"recv error : fd is : %d",fd);close(fd);_event_fds[pos].fd = defaultfd; // 本质还是从select中移除}}void Dispatcher() // 任务派发器{for(int i = 0; i < fd_num_max; ++i) // 这里是第二个循环了{int fd = _event_fds[i].fd;if(fd == defaultfd)continue;if(_event_fds[i].revents & POLLIN) {if(fd == _listensock.Fd()) // 说明是新链接就绪了{Accepter(); // 连接管理器}else // 说明某个链接的读事件就绪了{Recver(fd,i);}}}}void Start(){_event_fds[0].fd = _listensock.Fd();_event_fds[0].events = POLLIN;int timeout = 3000; // 代表的是3swhile(true){int n = poll(_event_fds,fd_num_max,timeout);if(n > 0){// 说明有事件就绪了cout << "get a new link" << endl;// 我们也不知道是一个就绪了还是多个就绪了// 而且这里也不知道是新链接来了,还是读事件就绪了Dispatcher(); }else if(n == 0){cout << "time out ..." << endl;}else if(n == -1){cout << "select error!!!" << endl;}}}void PrintFd(){cout << "online fd list : ";for(int i = 0; i < fd_num_max; ++i){if(_event_fds[i].fd == defaultfd)continue;cout << _event_fds[i].fd << " ";}cout << endl;}~PollServer(){_listensock.Close();}
private:Sock _listensock;uint16_t _port;struct pollfd _event_fds[fd_num_max]; // 依旧是由用户维护的数组//int fd_array[fd_num_max]; // 这是用户维护的数组。
};Main.cc和makefile简单改改就好了。
这样实现的话,我们发现不仅接口变简单了,而且每次poll前相比select,少了一次循环。
更重要的是,fd的数量上限不再受接口限制了。
select已经比较古老了,如果要在select和poll二选一,建议还是选择poll,除非平台也很古老,只支持select。
我们很轻易的就将select替换成poll了,说明两者还是有很多相似的地方了。
主要还是遍历的问题:虽然少了一次,但是依旧需要在用户层遍历,在内核层也是。如果数组很大,每次遍历的消耗也大,效率就不一定像原本想的那样高。
这个已经不是功能方面的问题了,这是效率方面的问题。