文章目录
- 字符串
- 缓存
- 计数
- 共享Session
- 限速
- 哈希
- 缓存
- 列表
- 消息队列
- 文章列表
- 栈
- 队列
- 有限集合
- 集合
- 标签
- 抽奖
- 社交需求
- 有序集合
- 排行榜系统
字符串
缓存
(1)使用原生字符类型缓存
优点:简单直观,每个属性都支持更新操作
缺点:占用过多的键、内存占用量较大,同时用户内聚性比较差。
(2)使用序列化字符串类型缓存
优点:简化编程,如果合理地使用序列化可以提高内存的利用效率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出来,反序列化,更新后在序列化存到Redis中。
计数
许多应用都会使用Redis作为计数的基础工具。它可以实现快速计数、查询缓存等功能,同时数据可以异步落到其它数据源。比如视频播放系统使用Redis作为视频播放计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1。
long incrVideoCounter(long id){key = "video:playCount:" + id;return redis.incr(key);
}
图解mysql专栏:count( * )这么慢,我该怎么办?
Redis计数和数据库同步的问题:
以InnoDB为存储引擎的数据库,由于MVCC机制,count(*)计数时需要一行一行的读取,判断是否对当前事务可见, 然后计数加1或者不加。所以当数据量很大时,执行count(*)的效率很慢。
假设某个网站有这样一个页面,要显示数据库中某张操作记录表的总数,同时还要显示最新的100条记录。由于count(*)的效率很慢,我们可以用Redis来计数,如果这张操作记录表插入了一行,Redis计数就加1,删除了一行,Redis计数减1。
我们用一张表模拟两个事务的操作过程,事务B负责这个页面的业务查询,即获取Redis计数和操作表中最新的100条记录,事务A向表中插入一条记录,Redis计数加1
由于多线程中,线程的执行顺序是不确定的,如果事务B的代码在t2时刻执行,则查询到底100条记录里面有最新的插入记录,但redis计数却没变。
| 时刻 | 事务A | 事务B |
|---|---|---|
| t0 | ||
| t1 | 向操作表中插入一条记录 | |
| t2 | 读取Redis计数 获取表中最新的100条记录 | |
| t3 | Redis记录加1 |
如果事务A变化一下添加记录的执行过程,先去Redis计数加1,再向操作表中执行插入操作。事务B在t2时刻执行,此时该页面显示的情况是,Redis的计数变了,但是查询到的100行记录里面没有最新的改变
| 时刻 | 事务A | 事务B |
|---|---|---|
| t0 | ||
| t1 | Redis记录加1 | |
| t2 | 读取Redis计数 获取表中最新的100条记录 | |
| t3 | 向操作表中插入一条记录 |
以上两种情况,对于事物B来说,查计数值和“最近的100条记录”看到的结构,逻辑上是不一致的。
共享Session
查看我写的另一篇博客
什么是Redis共享Session?
限速
很多应用出了安全考虑,会在每次进行登录的时候,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信验证接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
此功能可以通过Redis来实现:
phoneNum = "173xxxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// 将这个key的生命周期设置为60s,也就是1分钟
// key初始时的次数是1
isExists = redis.set(key,1,"EX 60","NX");
if(isExists != null || redis.incr(key) <= 5){// 第一次创建这个键// 或者// 不是第一次创建键,但 key 对应的次数小于等于5// 通过
}else{// 限速
}
哈希
缓存
优点:简单直观,如果合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
列表
消息队列
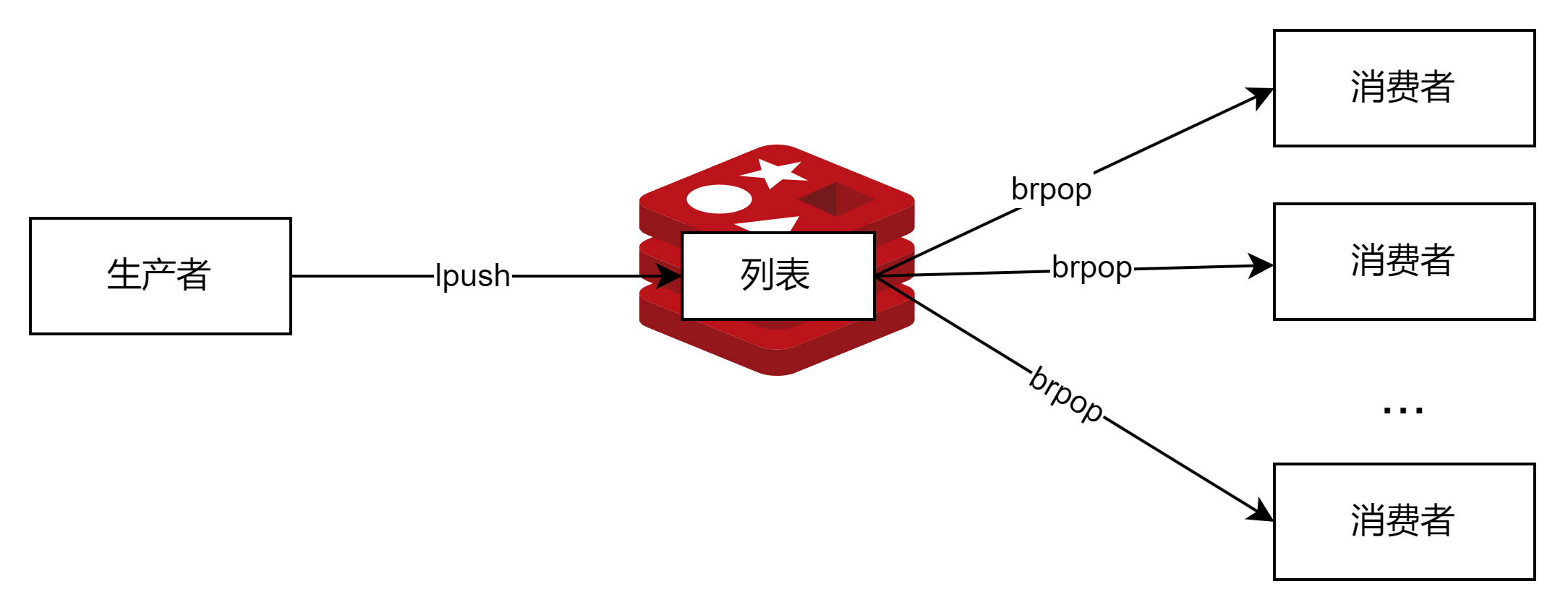
如图所示,Redis的lpush+brpop命令组合即可实现阻塞队列,生产者使用lpush命令从列表左侧插入元素,多个消费者使用brpop命令阻塞式地抢列表尾部的元素。
文章列表
每个用户有属于自己文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表是索引有序的,可以支持按照索引范围获取元素。
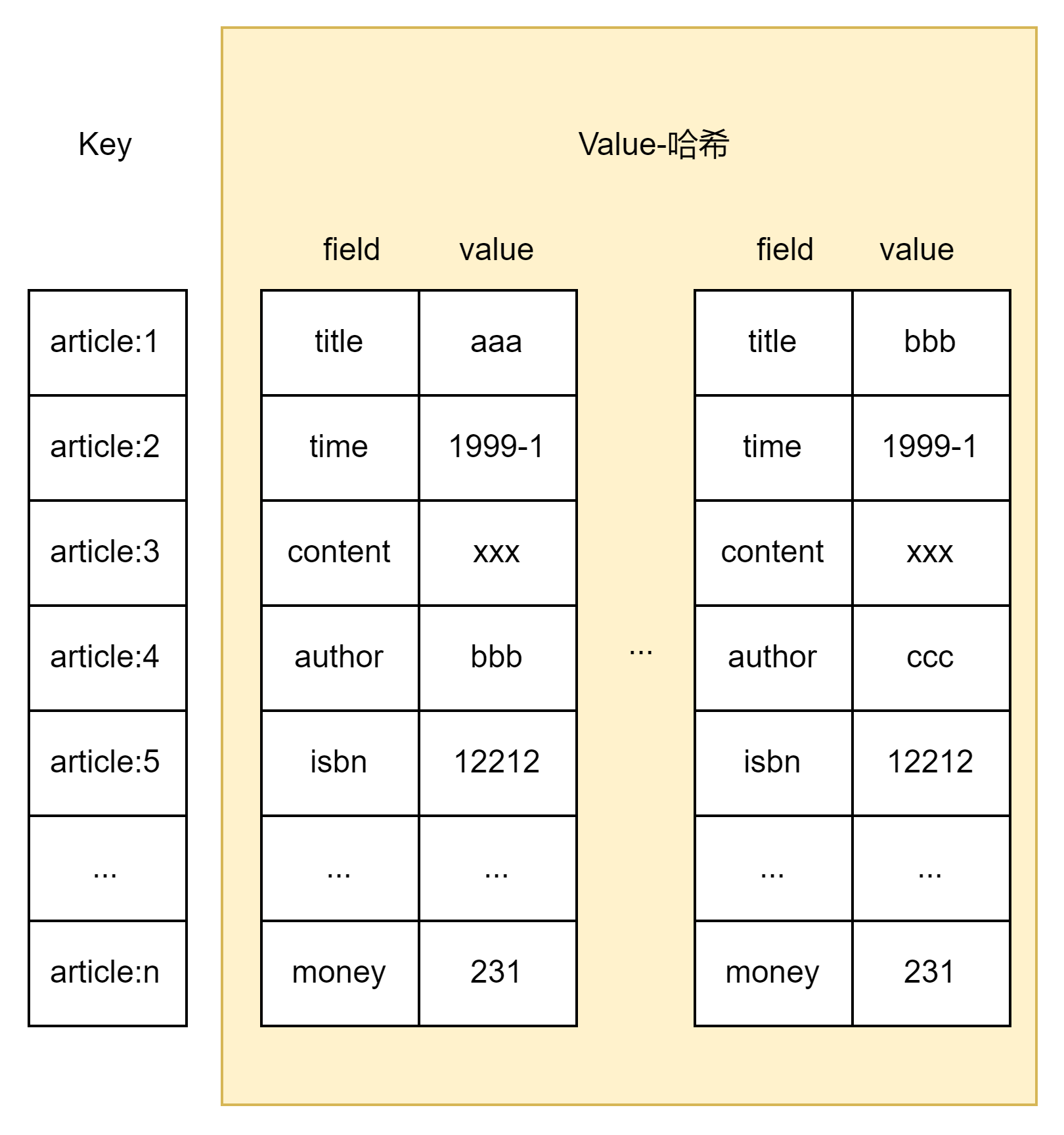
(1)每篇文章用哈希类型存储,例如每篇文章有一些属性:title、time、author、content、isbn、money等
hmset acticle:1 title xx time 1476536196 content xxxx ...
...
hmset acticle:k title xx time 1476536196 content xxxx ...
使用类似这样的命令构造k篇文章的数据
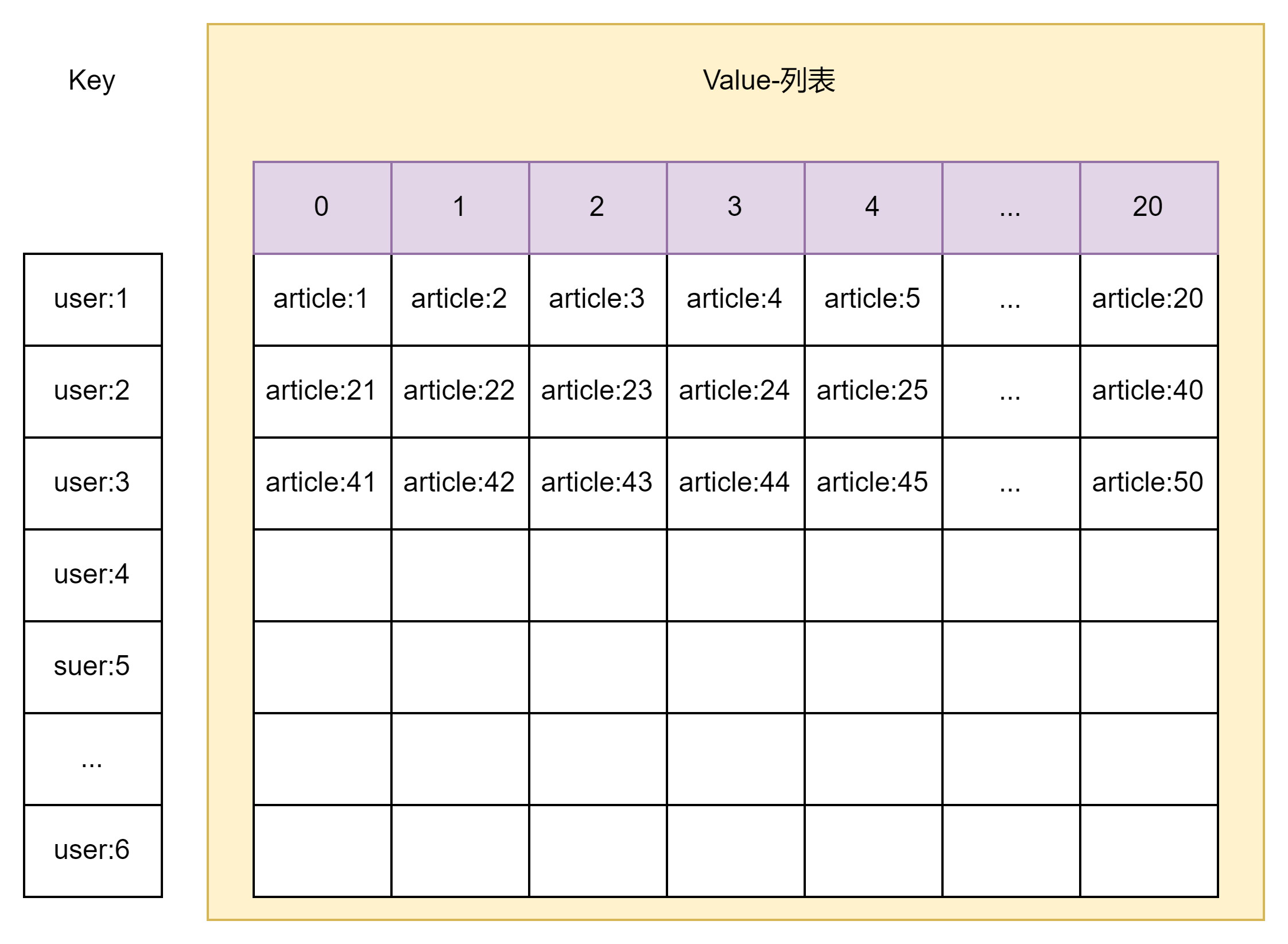
(2)向用户添加文字列表
lpush user:1:acticles article:1 article:3 ...
...
lpush user:n:acticles article:2 article:4
每个用户有自己的一个文章列表
(3)分页获取用户文章列表,例如通过下面的伪代码获取用户id=1的前10篇文章:
articles = lrange user:1:articles 0 9
for (article : articles){hgetall {article}
}
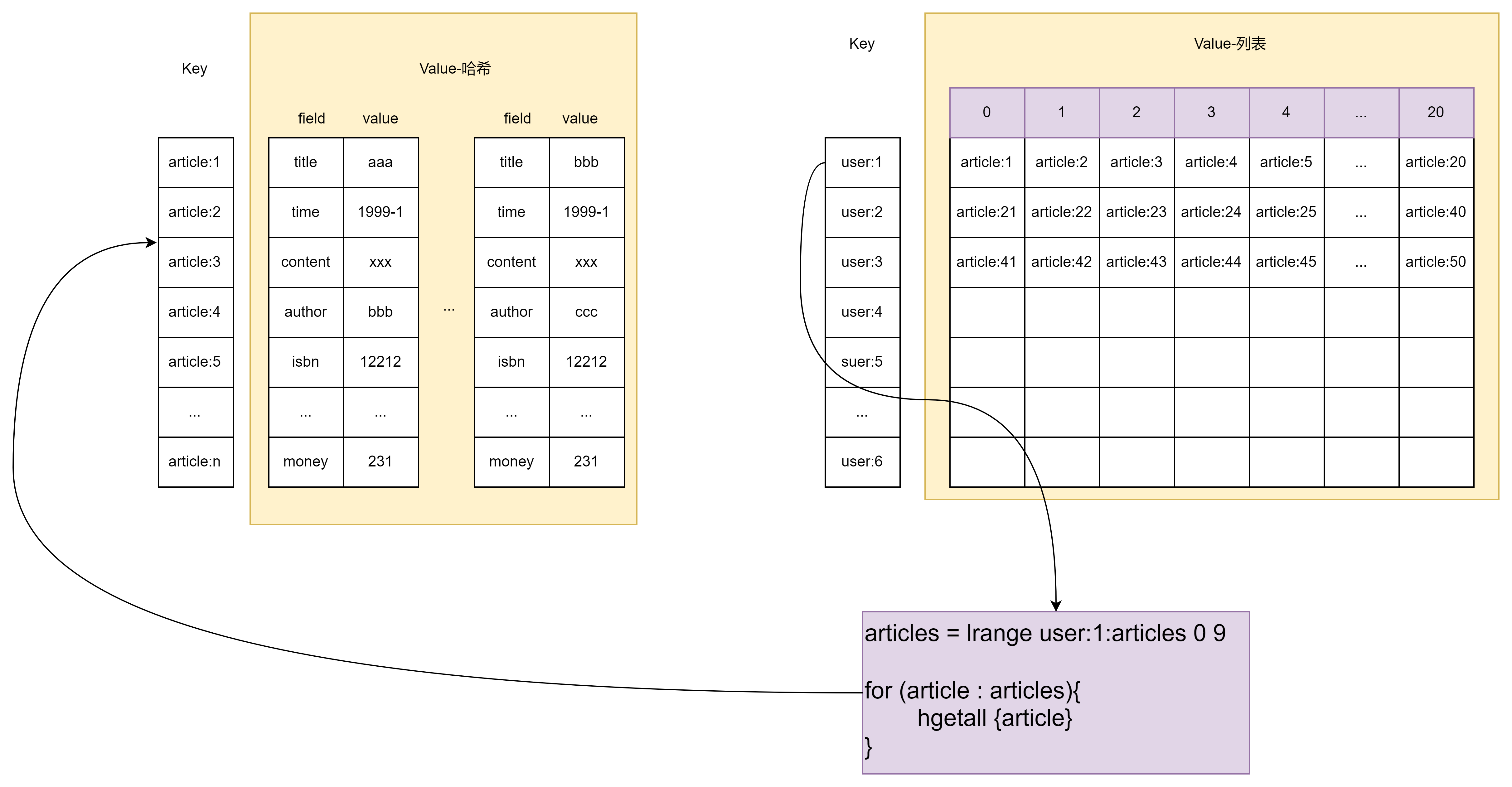
使用列表类型保存或获取文章列表会存在两个问题:
- 如果每次分页获取的文章数目较多,需要执行多次hgetall操作,此时可以考虑使用Pipeline批量获取。或者考虑将文章数据序列化为字符串类型,使用mget来获取。
- 分页获取文章列表时,lrange命令在列表的两端性能比较好,但如果列表较大,lrange获取列表中间元素性能会变差,此时可以考虑将列表做二级拆分。或者使用Redis quciklist内部编码实现。
栈
lpush + lpop = Stack
队列
lpush + rpop = Queue
有限集合
lpush + ltrim = Capped Collection
集合
标签
一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了标签之后我们可以得到:
- 喜欢同一个标签的人(站在标签角度)
- 两个或多个用户共同喜欢的标签(站在用户角度)
这些数据对于用户体验,以及增强用户黏度比较重要。
例如,一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品感兴趣的人,在各个页面或通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的收益。
下面使用集合类型实现标签的若干功能
(1)给用户添加标签
SADD user:1:tags tag1 tag2 tag3
SADD user:2:tags tag2 tag4 tag5
SADD user:3:tags tag1 tag3 tag5
SADD user:4:tags tag2 tag3 tag4
SADD user:5:tags tag1 tag4 tag5
SADD user:6:tags tag3 tag4 tag5
在redis种可以使用lua脚本一次性执行这命令:
EVAL "
redis.call('SADD', 'user:1:tags', 'tag1', 'tag2', 'tag3')
redis.call('SADD', 'user:2:tags', 'tag2', 'tag4', 'tag5')
redis.call('SADD', 'user:3:tags', 'tag1', 'tag3', 'tag5')
redis.call('SADD', 'user:4:tags', 'tag2', 'tag3', 'tag4')
redis.call('SADD', 'user:5:tags', 'tag1', 'tag4', 'tag5')
redis.call('SADD', 'user:6:tags', 'tag3', 'tag4', 'tag5')
" 0
(2) 给标签添加用户
SADD tag1:users user:1 user:3 user:5
SADD tag2:users user:1 user:2 user:4
SADD tag3:users user:1 user:3 user:4
SADD tag4:users user:2 user:4 user:5 user:6
SADD tag5:users user:2 user:3 user:5 user:6
在redis种可以使用lua脚本一次性执行这命令:
EVAL "
redis.call('SADD', 'tag1:users', 'user:1', 'user:3', 'user:5')
redis.call('SADD', 'tag2:users', 'user:1', 'user:2', 'user:4')
redis.call('SADD', 'tag3:users', 'user:1', 'user:3', 'user:4')
redis.call('SADD', 'tag4:users', 'user:2', 'user:4', 'user:5', 'user:6')
redis.call('SADD', 'tag5:users', 'user:2', 'user:3', 'user:5', 'user:6')
" 0
(3)删除用户下标签
srem user:1:tags tag1 tag2
(4)删除标签下的用户
srem tag1:users user:1
srem tag2:users user:1
(1)和(2)尽量放在一个事务中执行。
(3)和(4)尽量放在一个事务中执行。
(5)获取喜欢同一个标签的人
smembers tag1:users
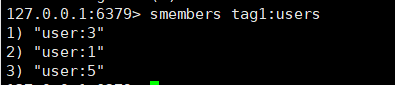
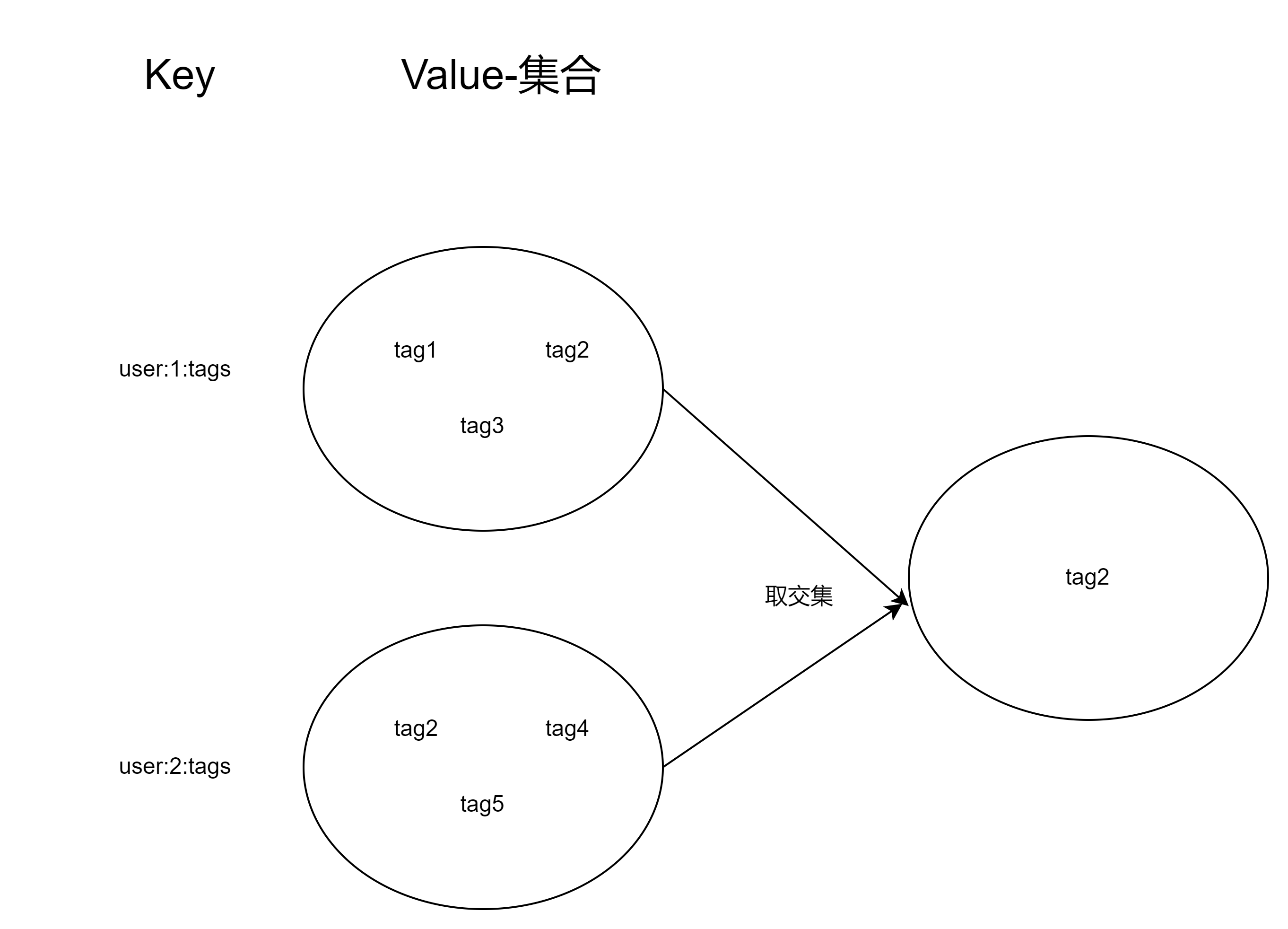
(6)获取user:1与user:2共同喜欢的标签
sinter user:1:tags user:2:tags

抽奖
spop/srandmember = Random item
社交需求
sadd + sinter = Social Graph
有序集合
排行榜系统
比如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多方面的,可能按照以下几个维度排名:
- 时间
- 播放数量
- 获得的赞数
- …
以获得的赞数为例,记录每天用户上传的视频的排行榜。
(1)视频添加用户赞数
例如用户mike上传了一个视频,并获得了3个赞,可以使用有序集合的zadd和zincrby功能:
zadd user:ranking:2024_03_12 3 mike
如果之后再获得一个赞,就可以使用zincrby:
zincrby user:ranking:2024_03_12 1 mike
(2)将用户移除榜单
由于各种原因(如用户注销、用户作弊)需要将用户删除,此时需要将用户从榜单中删除掉,可以使用zrem。例如删除榜单中的tom用户
zrem user:ranking:2024_03_12 tom
(3)显示榜单Top10
为了模拟这个功能,我用lua脚本创建了20条模拟数据:
EVAL "
redis.call('ZADD', 'user:ranking:2024_03_12', 3, 'mike')
redis.call('ZADD', 'user:ranking:2024_03_12', 5, 'jack')
redis.call('ZADD', 'user:ranking:2024_03_12', 7, 'tom')
redis.call('ZADD', 'user:ranking:2024_03_12', 9, 'curt')
redis.call('ZADD', 'user:ranking:2024_03_12', 11, 'dexter')
redis.call('ZADD', 'user:ranking:2024_03_12', 13, 'bert')
redis.call('ZADD', 'user:ranking:2024_03_12', 15, 'christian')
redis.call('ZADD', 'user:ranking:2024_03_12', 17, 'cecil')
redis.call('ZADD', 'user:ranking:2024_03_12', 19, 'charles')
redis.call('ZADD', 'user:ranking:2024_03_12', 21, 'bill')
redis.call('ZADD', 'user:ranking:2024_03_12', 23, 'cathy')
redis.call('ZADD', 'user:ranking:2024_03_12', 25, 'crystal')
redis.call('ZADD', 'user:ranking:2024_03_12', 27, 'elaine')
redis.call('ZADD', 'user:ranking:2024_03_12', 29, 'ellie')
redis.call('ZADD', 'user:ranking:2024_03_12', 31, 'hortensia')
redis.call('ZADD', 'user:ranking:2024_03_12', 33, 'kit')
redis.call('ZADD', 'user:ranking:2024_03_12', 35, 'lori')
redis.call('ZADD', 'user:ranking:2024_03_12', 37, 'marian')
redis.call('ZADD', 'user:ranking:2024_03_12', 39, 'lesley')
redis.call('ZADD', 'user:ranking:2024_03_12', 41, 'thirza')
" 0
根据或赞数排序,取前或赞数量前10个用户,可以使用zrevrange命令,从高到地返回成员:
zrevrange user:ranking:2024_03_12 0 9

(4)展示用户信息、用户分数以及用户排名
假设用户信息保存再哈希类型中,用户分数和用户排名可以用zscore和zrank两个命令:
hgetall user:info:tom
zscore user:ranking:2024_03_12 mike
zrank user:ranking:2024_03_12 mike



![[Arduino学习] ESP8266读取DHT11数字温湿度传感器数据](https://img-blog.csdnimg.cn/img_convert/b60776036a0db552385d149d48c7bd4f.png)