目前b题已全部更新包含详细的代码模型和文章,本文也给出了结果展示和使用模型说明。
同时文章最下方包含详细的视频教学获取方式,手把手保姆级,模型高精度,结果有保障!
分析:
本题待解决问题
目标:利用提供的数据集,通过特征提取和多模态特征融合模型建立,实现图像与文本间的互检索。
具体任务:
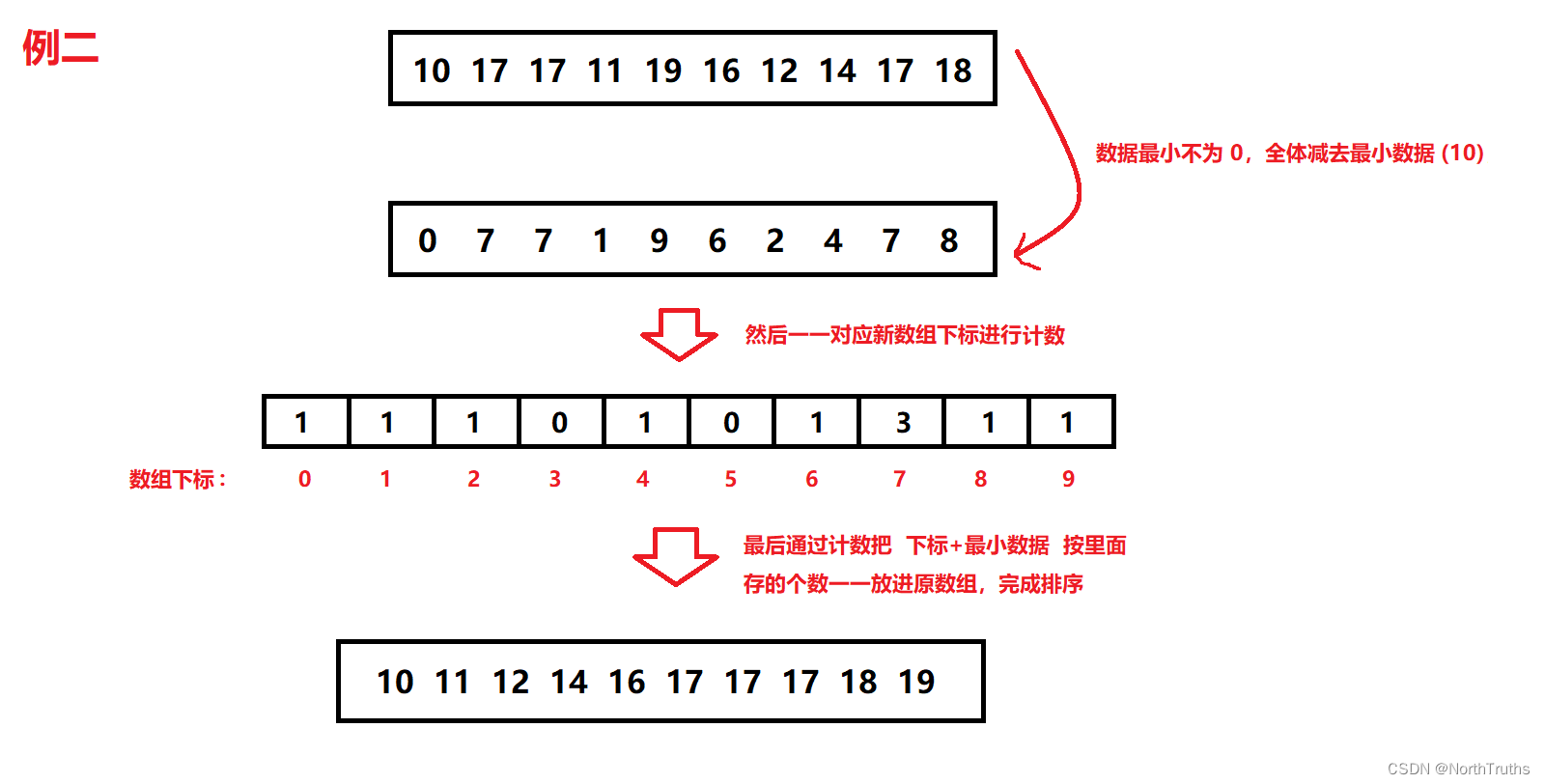
基于图像检索的文本:利用提供的文本信息,对图像进行检索,输出相似度较高的前五张图像。
基于文本检索的图像:利用提供的图像ID,对文本进行检索,输出相似度较高的前五条文本。
数据集和任务要求
附件1:包含五万张图像和对应的文本信息。
附件2和附件3:分别提供了任务1和任务2的数据信息,包括测试集文本、图像ID和图像数据库。
附件4:提供了任务结果的模板文件。
评价标准
使用**召回率Recall at K(R@K)**作为评价指标,即查询结果中真实结果排序在前K的比率,本赛题设定K=5,即评价标准为R@5。
步骤一:构建图文检索模型
采用图文检索领域已经封装好的模型:多模态图文互检模型
基于本题附件一所给的数据进行调优
可以给大家展示以下我们模型的效果,和那种一两天做出来的效果完全不一样,我们的模型效果和两个任务的预测情况完整是准确且符合逻辑的。

任务一结果展示:

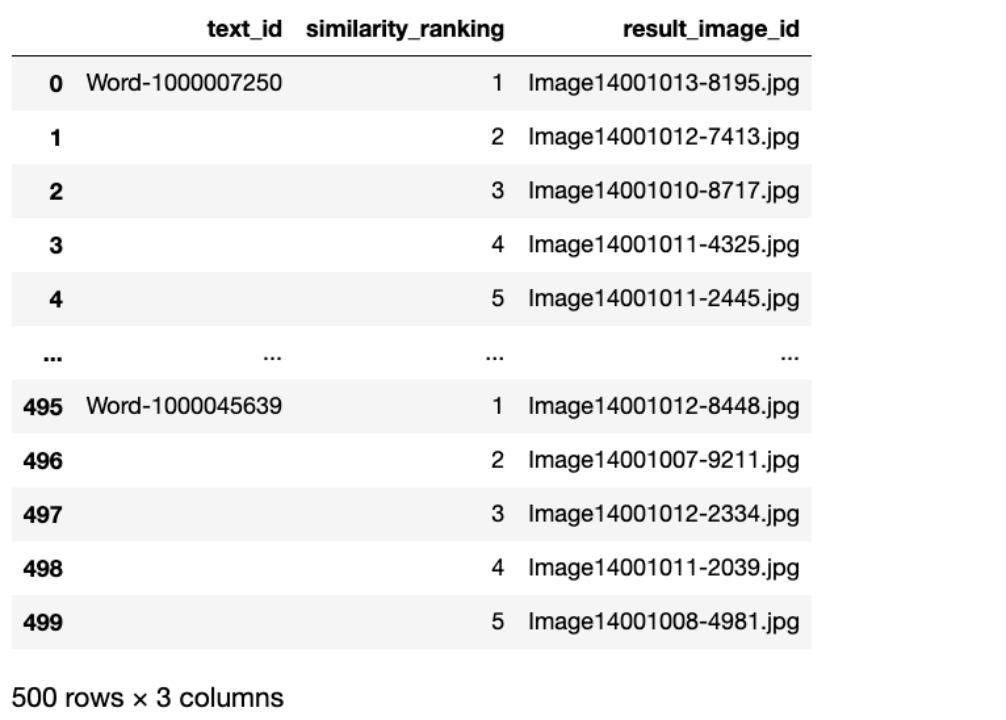
任务二结果展示:

步骤二:基于图像检索文本
1.数据预处理和特征提取
文本数据预处理:
清洗文本:去除文本中的停用词、标点符号等无关信息。
文本向量化:利用NLP技术(如Word2Vec, GloVe, BERT等)将文本转换为数值向量,以便进行计算和比较。

import jieba
import pandas as pd
from collections import Counter
#读取CSV文件
image_word_data = pd.read_csv('附件1/ImageWordData.csv')
#加载自定义的停用词表(如果有的话),或使用jieba内置的停用词表
#例如: stop_words = set(open('path_to_stop_words.txt').read().strip().split('\n'))
stop_words = set() # 假设暂时没有自定义的停用词表
#文本预处理函数
def preprocess_text(captions):
preprocessed_captions = []
for caption in captions:
# 使用jieba进行分词
tokens = jieba.lcut(caption)
# 去除停用词
tokens = [token for token in tokens if token not in stop_words and len(token) > 1]
# 将处理过的词加入结果列表
preprocessed_captions.append(" ".join(tokens))
return preprocessed_captions
#对caption列进行预处理
preprocessed_captions = preprocess_text(image_word_data['caption'])
#查看处理过的一些示例文本
for i in range(5):
print(preprocessed_captions[i])
#(可选)统计词频
word_counts = Counter(" ".join(preprocessed_captions).split())
print(word_counts.most_common(10))
图像数据预处理:
图像标准化:将所有图像调整到相同的大小和色彩空间。
特征提取:使用深度学习模型(如CNN, ResNet, VGG等)从图像中提取特征向量。
image_word_data = pd.read_csv('附件1/ImageWordData.csv')
#图像预处理函数
def preprocess_images(image_folder, image_ids, target_size=(224, 224)):
processed_images = {}
for image_id in image_ids:
image_path = os.path.join(image_folder, image_id)
try:
# 打开图像文件
with Image.open(image_path) as img:
# 调整图像尺寸
img = img.resize(target_size)
# 将图像转换为数组
img_array = np.array(img)# 对图像数组进行归一化
img_array = img_array / 255.0
processed_images[image_id] = img_array
except IOError as e:
print(f"无法打开或找到图像 {image_path}。错误信息: {e}")
processed_images[image_id] = None
return processed_images
#假设图像位于"附件1/ImageData"文件夹中
image_folder_path = '附件1/ImageData'
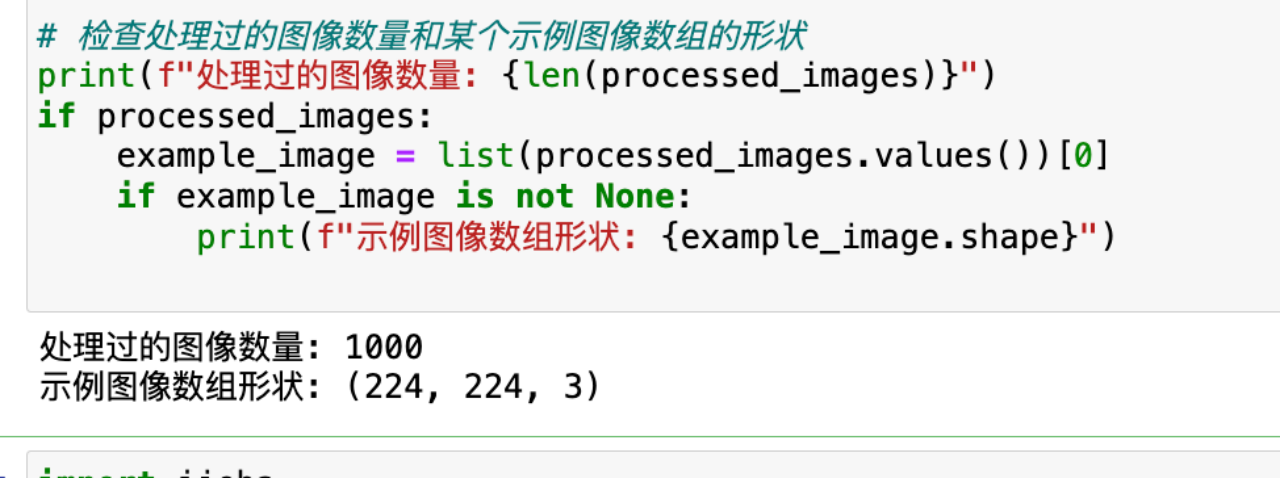
processed_images = preprocess_images(image_folder_path, image_word_data['image_id'])
#检查处理过的图像数量和某个示例图像数组的形状
print(f"处理过的图像数量: {len(processed_images)}")
if processed_images:
example_image = list(processed_images.values())[0]
if example_image is not None:
print(f"示例图像数组形状: {example_image.shape}")
2.多模态特征融合
由于文本和图像特征位于不同的特征空间,我们需要采取方法将它们映射到同一个空间,以便进行相似度比较。这可以通过以下方法之一实现:
联合嵌入空间:通过训练一个深度学习模型来同时学习文本和图像的嵌入,使得相似的图像和文本对靠近。
交叉模态匹配网络:设计一个网络,它可以接受一种模态的输入,并预测另一种模态的特征表示。
文本特征提取:
from sklearn.feature_extraction.text import TfidfVectorizer
#初始化TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=1000) # 使用最多1000个词语的词汇量
#将文本数据转换为TF-IDF特征矩阵
tfidf_matrix = vectorizer.fit_transform(preprocessed_captions)
#查看TF-IDF特征矩阵的形状
print(tfidf_matrix.shape)
图像特征提取:
import torch
from torchvision import models, transforms
from PIL import Image
import os
#图像预处理函数
def preprocess_image(img_path):
# 读取图像,转换为RGB(如果是灰度图像)
img = Image.open(img_path).convert('RGB')
# 转换图像
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
return batch_t
#定义预处理流程,确保模型接收三通道的图像
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
#你可以在这里选择较小的模型来减少内存使用
#比如使用 ResNet18
model = models.resnet18(pretrained=True)
model.eval() # 设置为评估模式
#修改图像特征提取部分,使用上面定义的preprocess_image函数
def extract_image_features(image_folder, image_ids):
image_features = {}
for image_id in image_ids:
image_path = os.path.join(image_folder, image_id)
try:
batch_t = preprocess_image(image_path)
#batch_t = batch_t.to(device)
with torch.no_grad():
features = model(batch_t)
image_features[image_id] = features.cpu().numpy().flatten()
except Exception as e:
print(f"无法处理图像 {image_path}: {e}")
image_features[image_id] = None
return image_features
#假设图像位于"附件1/ImageData"文件夹中
image_folder_path = '附件1/ImageData'
#调用函数提取特征
image_features = extract_image_features(image_folder_path, image_word_data['image_id'])
特征融合:
#转换图像特征字典为矩阵
image_features_matrix = np.array([features for features in image_features.values() if features is not None])
#特征融合
#这里我们简单地将归一化的图像特征和TF-IDF特征进行连接
#确保TF-IDF特征矩阵是稠密的
tfidf_features_dense = tfidf_matrix.todense()
multimodal_features = np.concatenate((image_features_matrix, tfidf_features_dense), axis=1)
#现在 multimodal_features 矩阵包含了每个样本的融合特征
3.图文检索
根据训练好的模型进行图文检索匹配
检索和排序:根据计算出的相似度,对数据库中的图像进行排序,选出相似度最高的前五张图像。
结果展示:

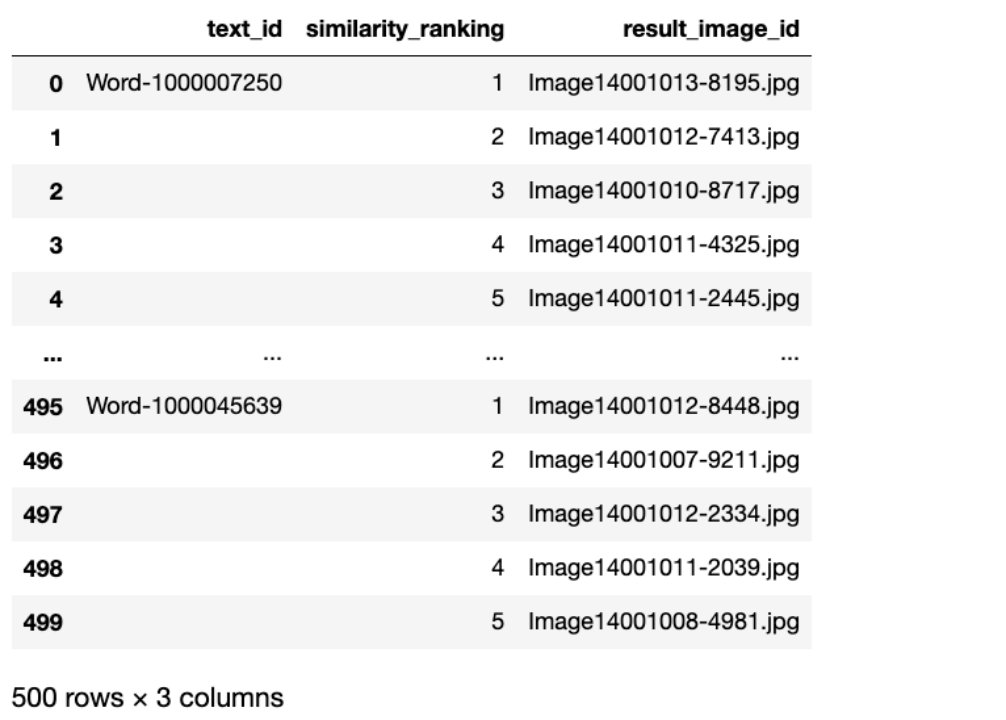
步骤三:基于文本检索图像
与步骤三类似,这里直接展示结果。

下面内容打开内含详细的视频教学,手把手保姆级,模型高精度,结果有保障!
【腾讯文档】2024泰迪杯数据挖掘助攻合集docs.qq.com/doc/DVVlhb2xmbUFEQUJL