文章目录
- 前言
- 关于token_counter
- 关于class StableDiffusionProcessingTxt2Img(StableDiffusionProcessing)
- 如何超出77个token的限制?
- 对提示词加权的底层实现
- Overcoming the 77 token limit in diffusers
- 方法1 手动拼
- 方法2 compel
- 问询、帮助请看:
前言
CLIP的输出是77*768的特征,现在基本上一个图像的prompt提示词的token数肯定是很高,会超过77,那超出的时候是如何计算的呢?
sdwebui输入的文本token是自动更新计算的,如何做到的呢?

关于token_counter
追溯一下代码:
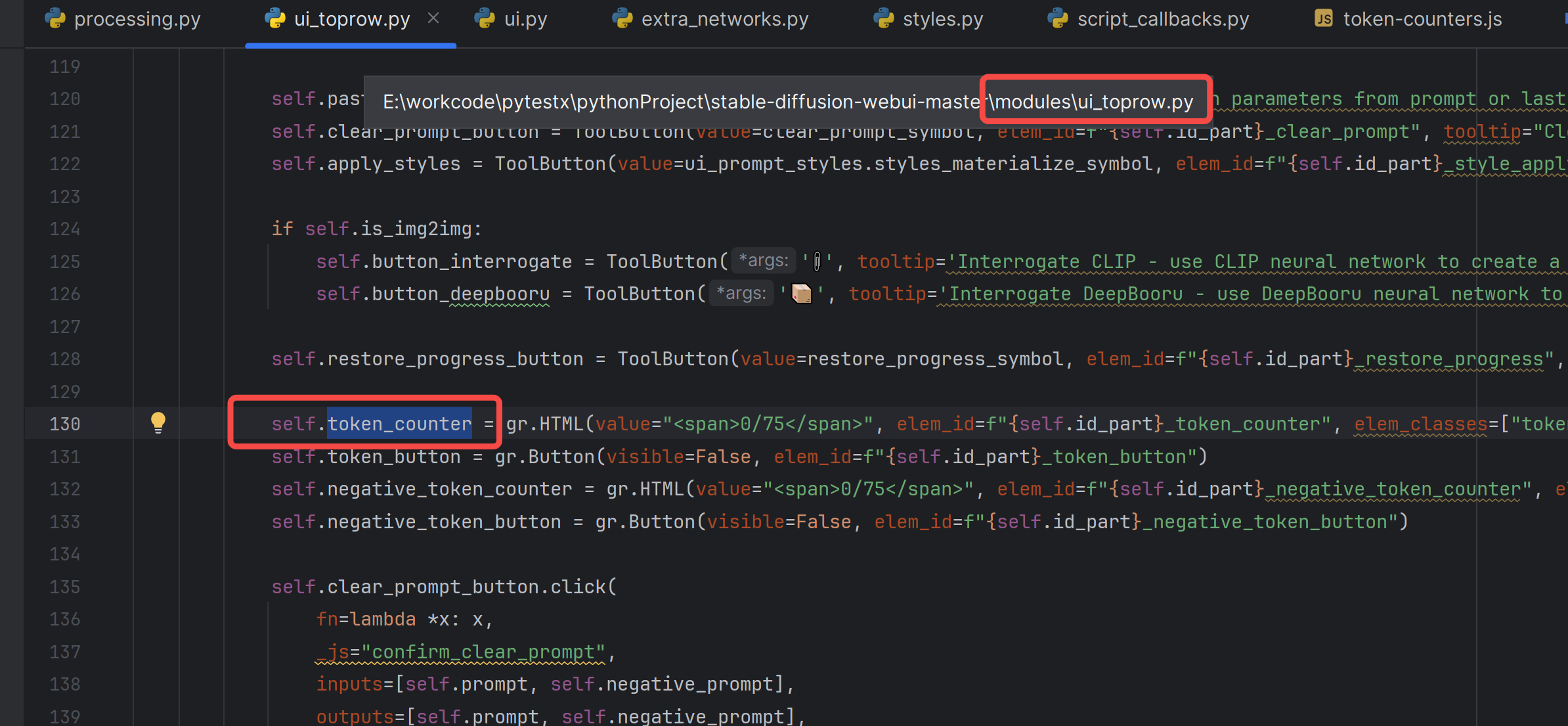
然后追到js:
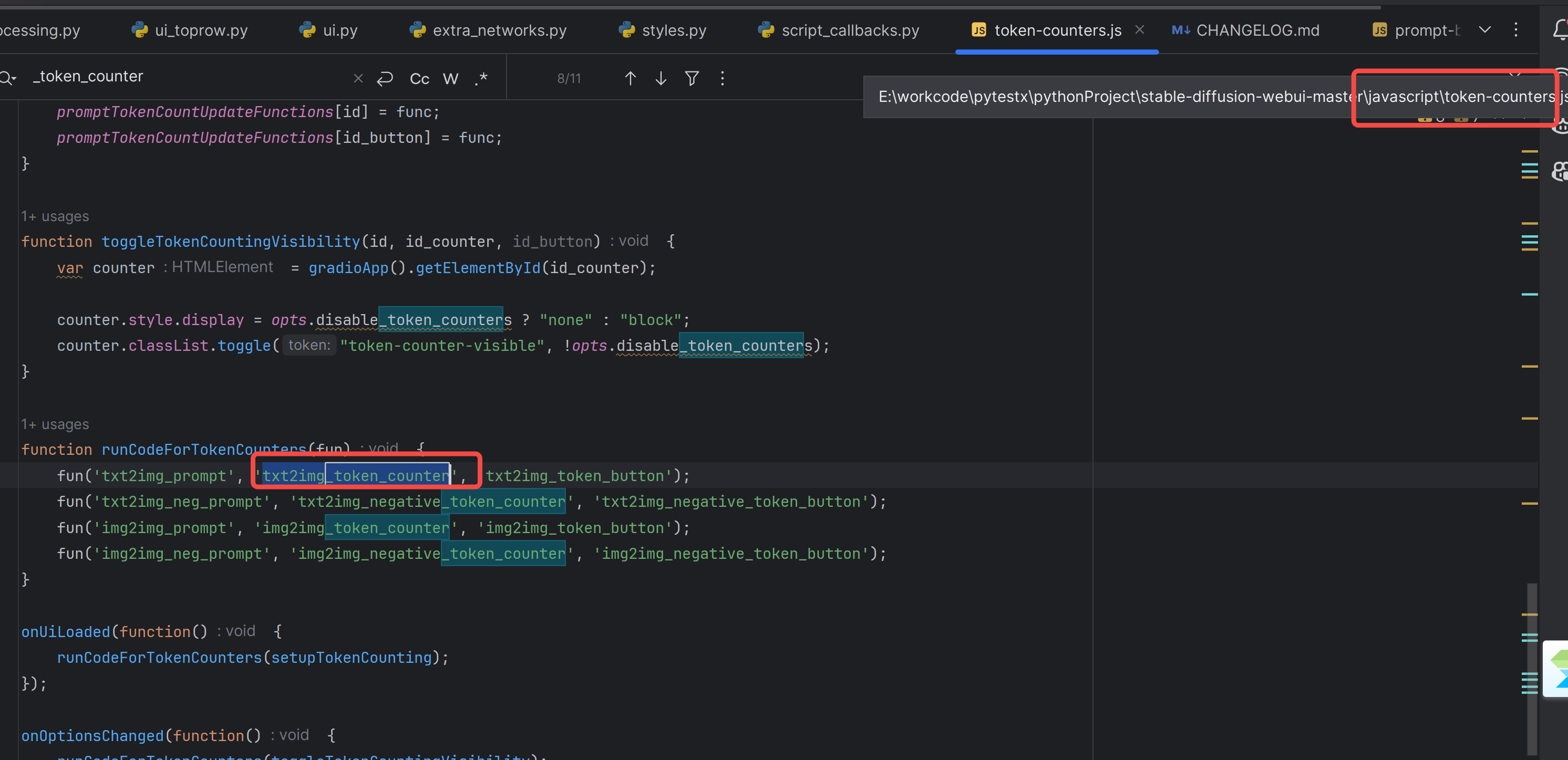
然后追到更新逻辑:
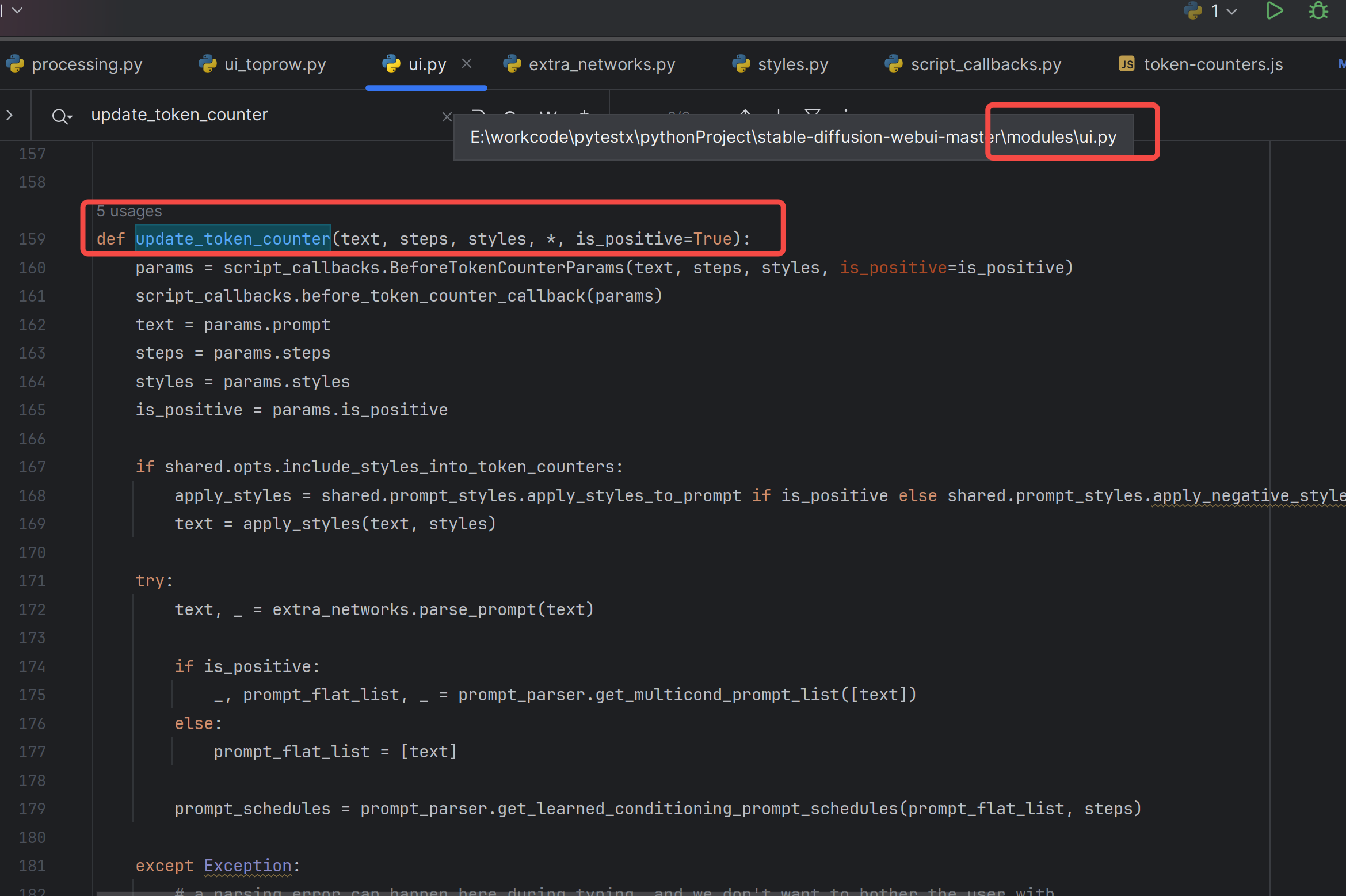
重要的是这个函数:
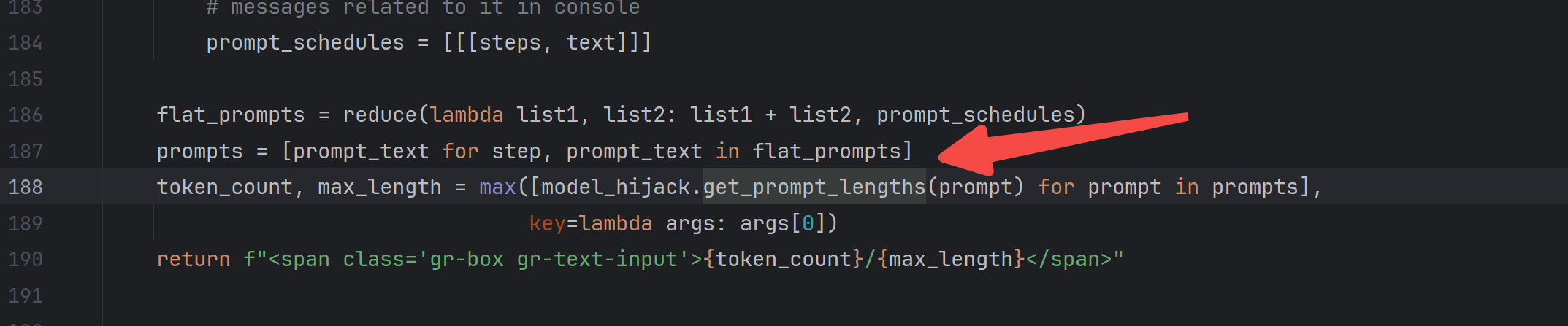
可以看到是clip的分词器在统计token数量:
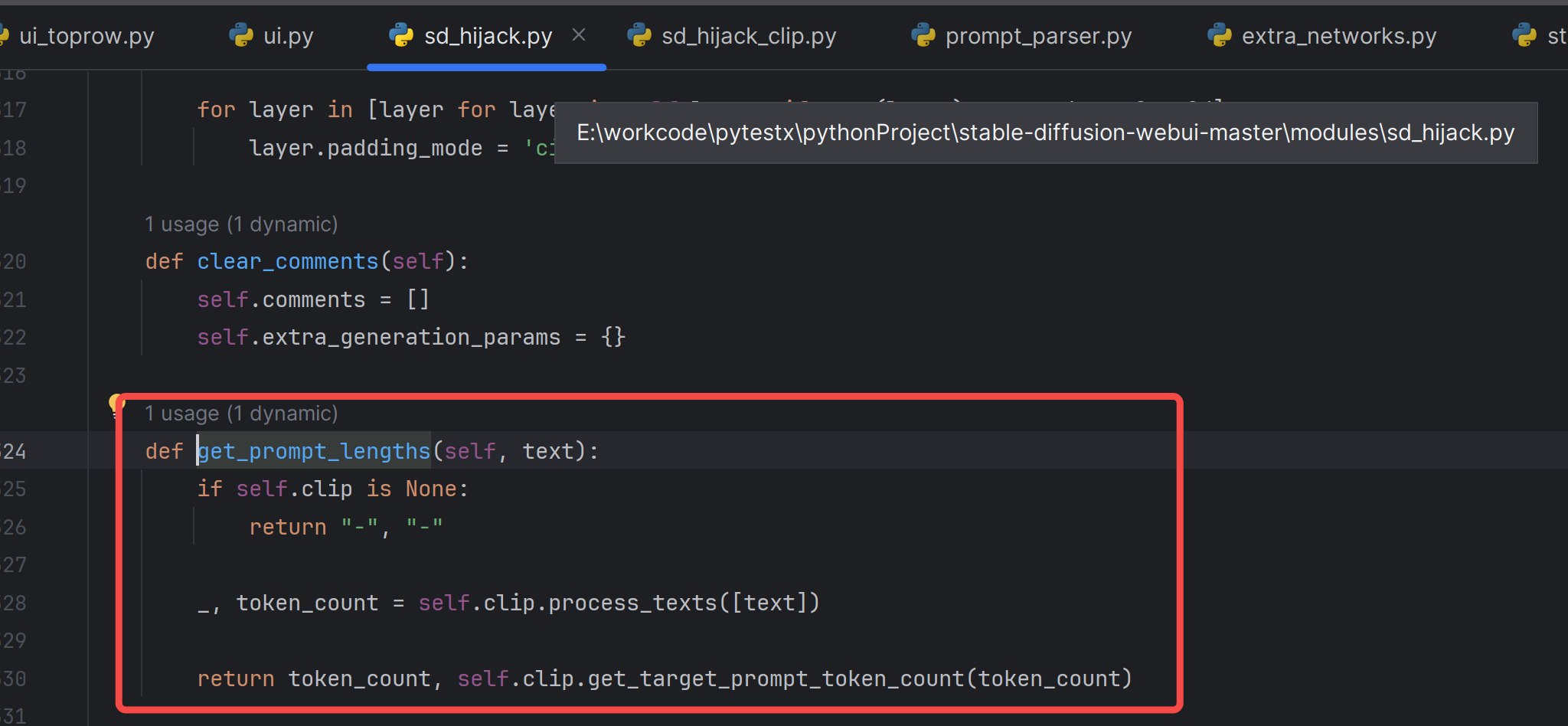
估计是要算上开始符号结束符号:
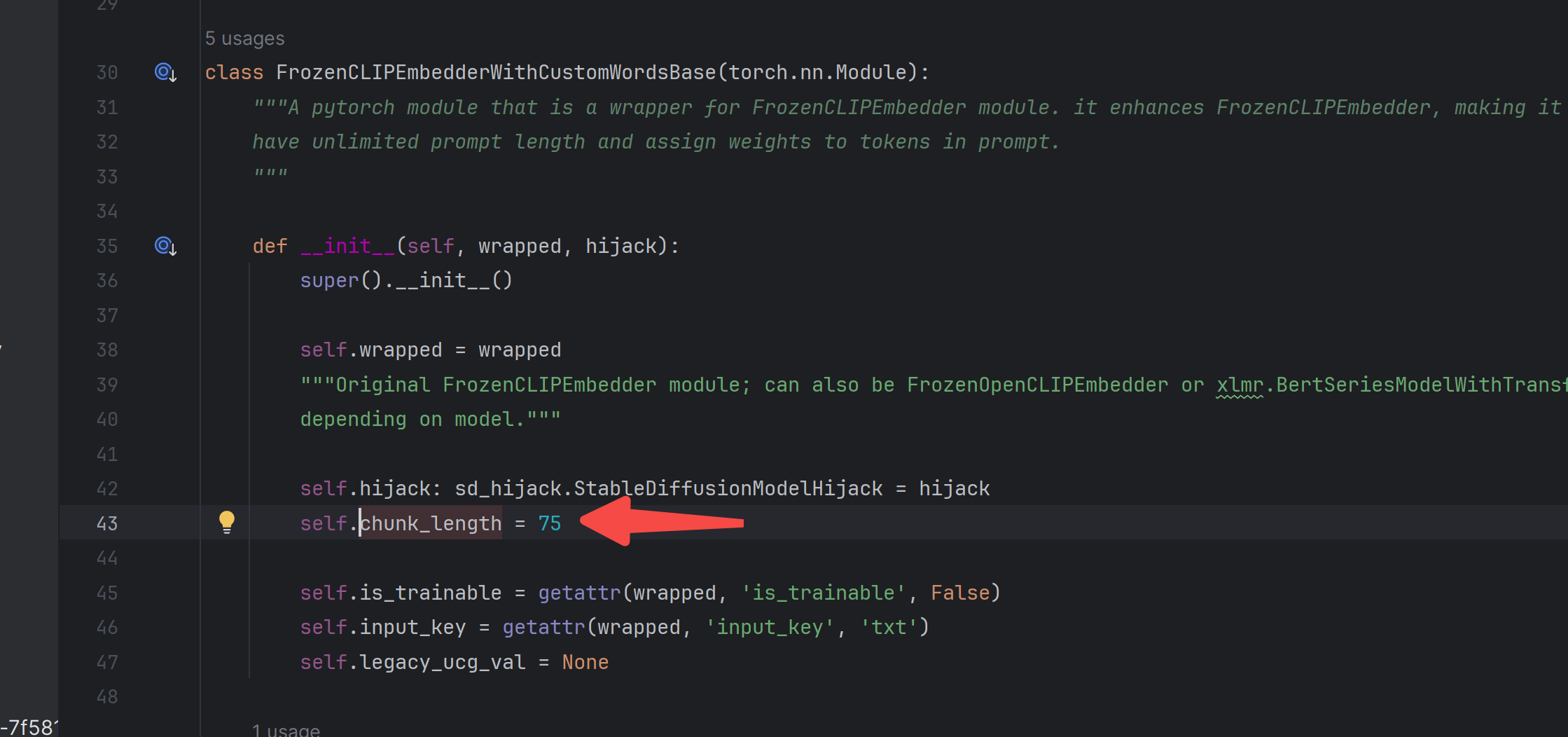
如何使用这个token,继续追这里的代码:
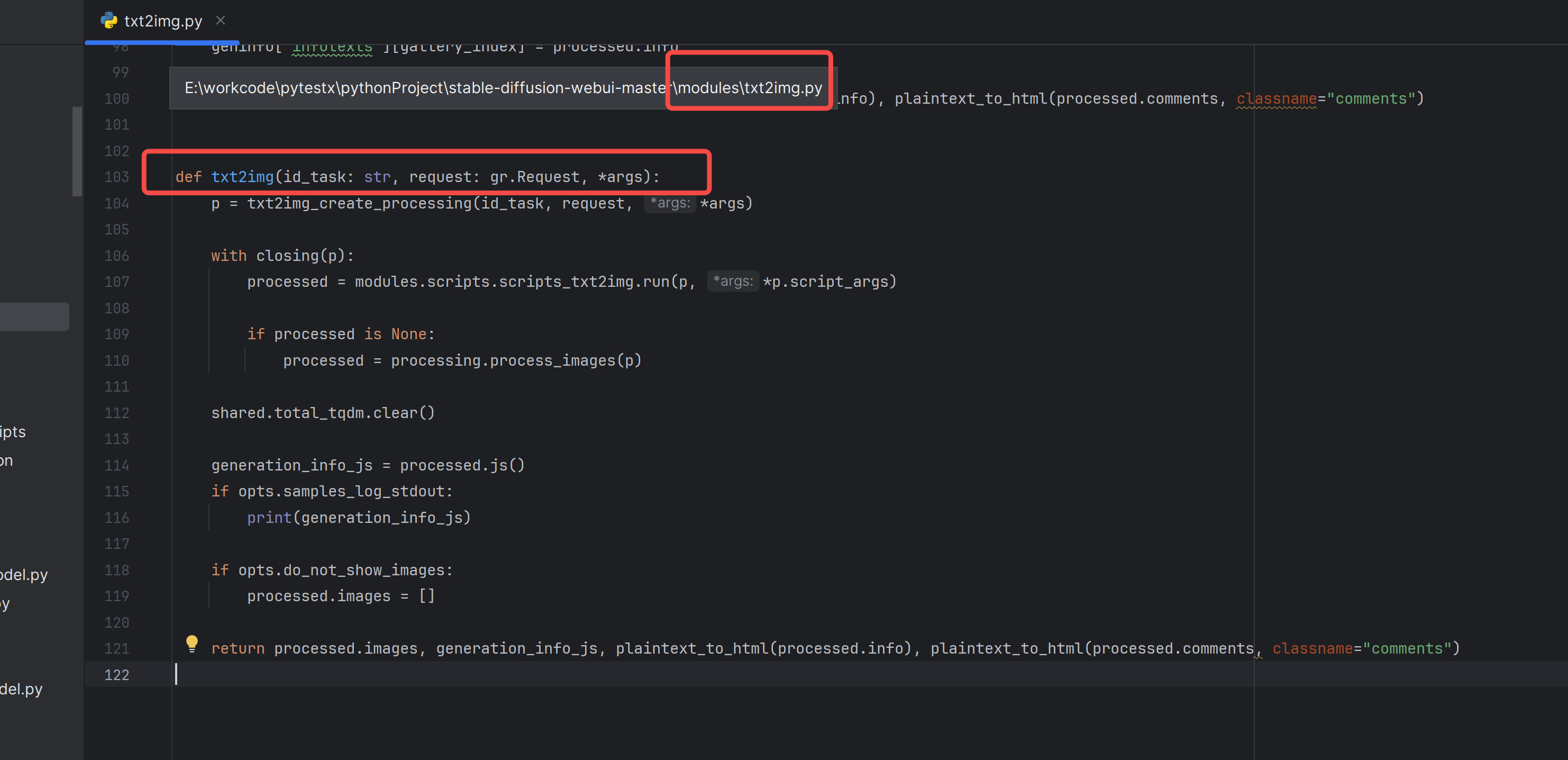
写得很抽象:processed = modules.scripts.scripts_txt2img.run(p, *p.script_args)
生图任务,生图参数,给到了scripts_txt2img: ScriptRunner 去跑,除了基础的文生图,还需要考虑各个插件的回调。
如 before_process_batch()、process_batch()、postprocess_batch() 等,它们在批量化生成图像的不同阶段被调用,以便在生成过程中插入自定义逻辑。
关于class StableDiffusionProcessingTxt2Img(StableDiffusionProcessing)
生图的逻辑在这里:
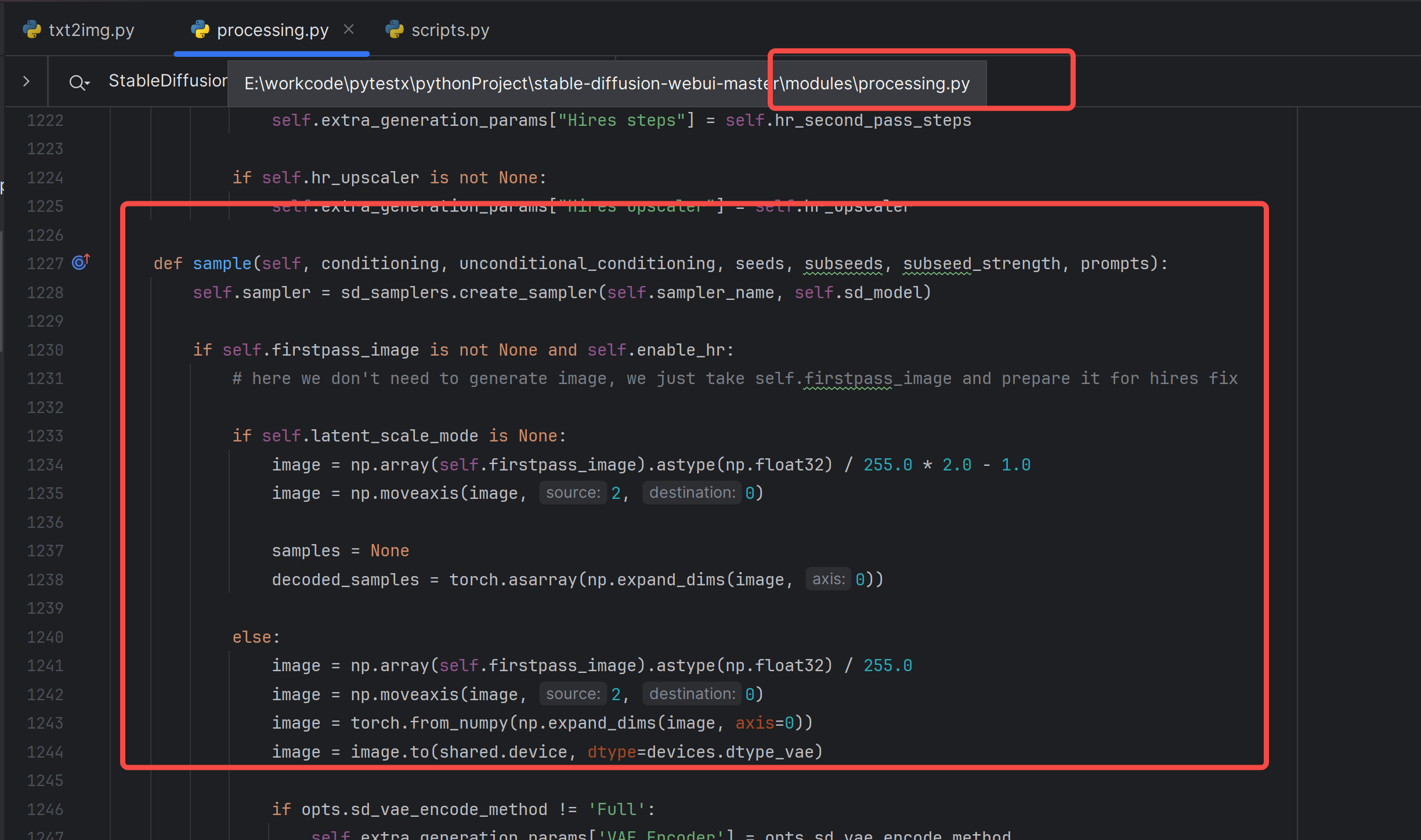
当我进一步研究这里的代码的时候,我对python的**kwargs 感到恐怖,强大的灵活性的代价就是追踪代码更难了,我不得不打开断点调试来继续。
运行webui.py
运行参数:
--enable-insecure-extension-access --skip-python-version-check --skip-torch-cuda-test --skip-install --timeout-keep-alive 300 --ckpt ./models/Stable-diffusion/majicmixRealistic_v7.safetensors --port 7867 --no-download-sd-model --api --listen
对于我给的np:worst quality, low quality, low res, blurry, cropped image, jpeg artifacts, error, ugly, out of frame, deformed, poorly drawn, mutilated, mangled, bad proportions, long neck, missing limb, floating limbs, disconnected limbs, long body, missing arms, malformed limbs, missing legs, extra arms, extra legs, poorly drawn face, cloned face, deformed iris, deformed pupils, deformed hands, twisted fingers, malformed hands, poorly drawn hands, mutated hands, mutilated hands, extra fingers, fused fingers, too many fingers, duplicate, multiple heads, extra limb, duplicate artifacts
在这里就已经拼接为2个77,即是(154,768)的形状。
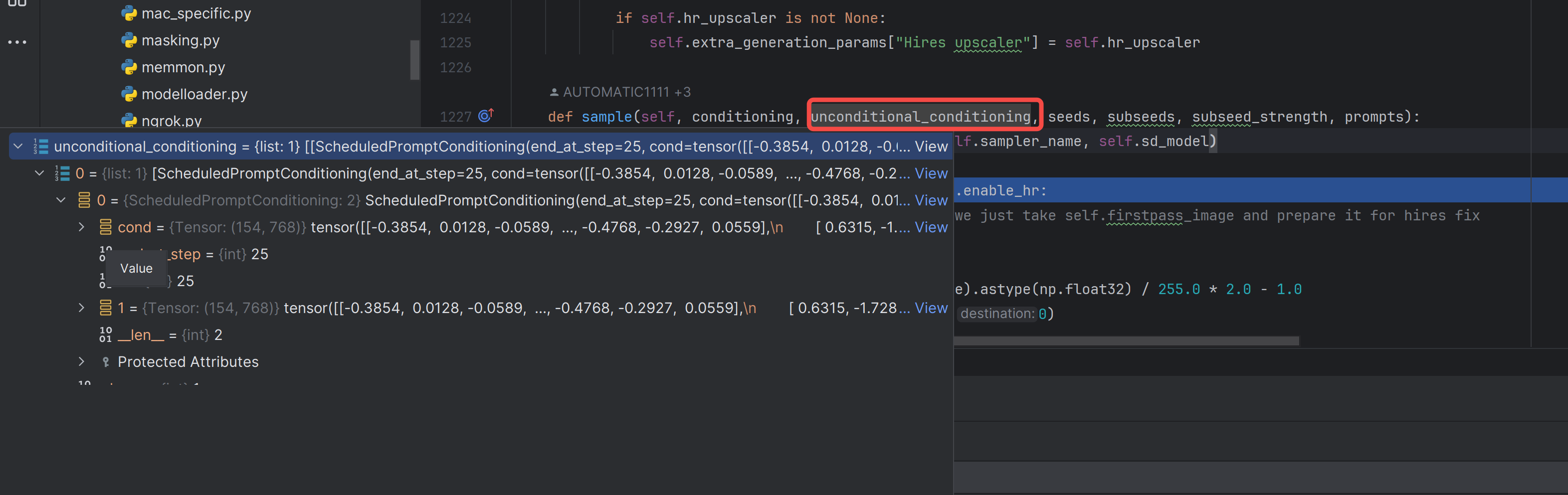
定位到这里
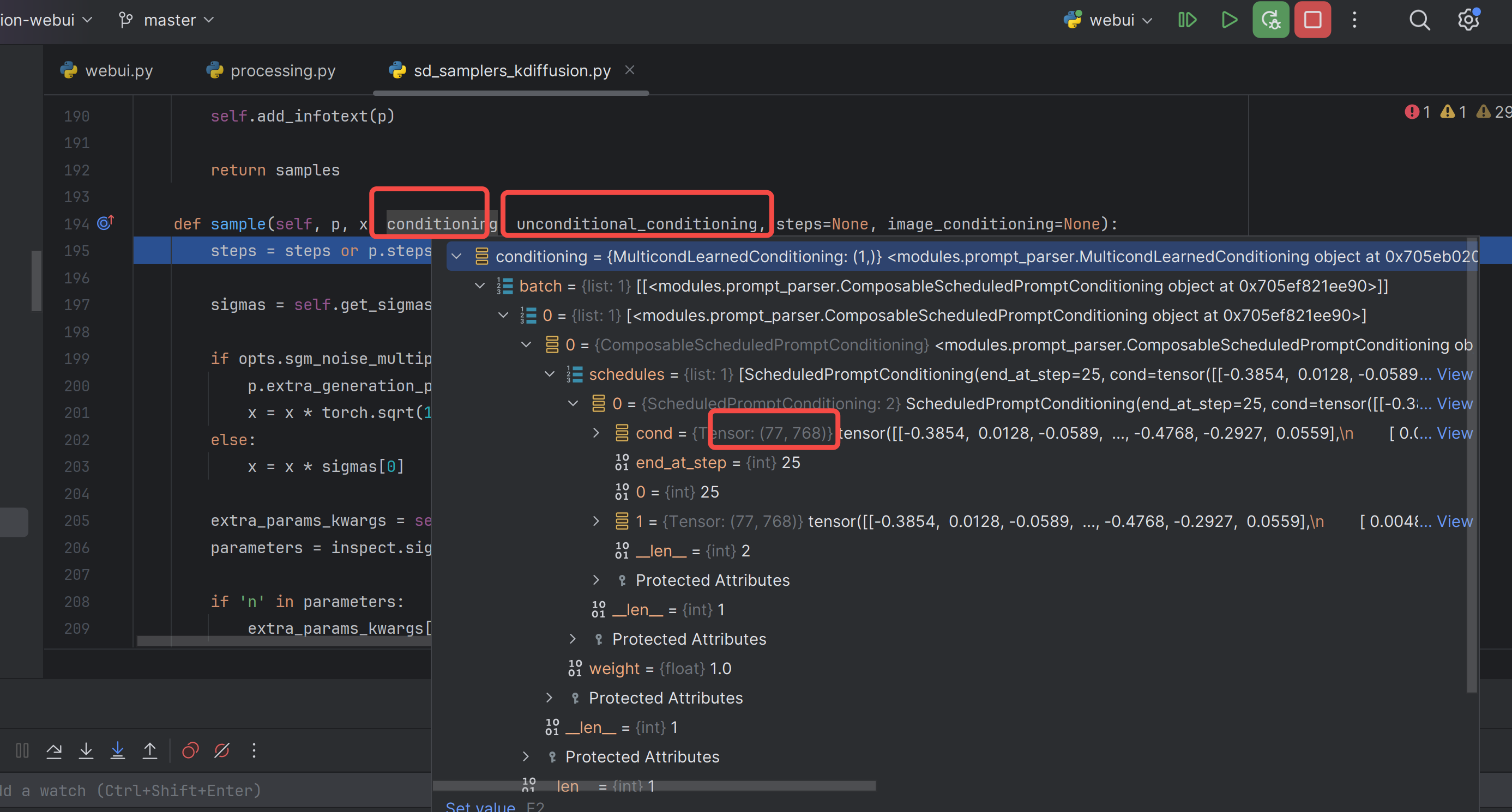
跟到这里就是已经在采样预测噪声去噪了:
如何超出77个token的限制?
靠纯补,只要是77的倍数就行。
对提示词加权的底层实现
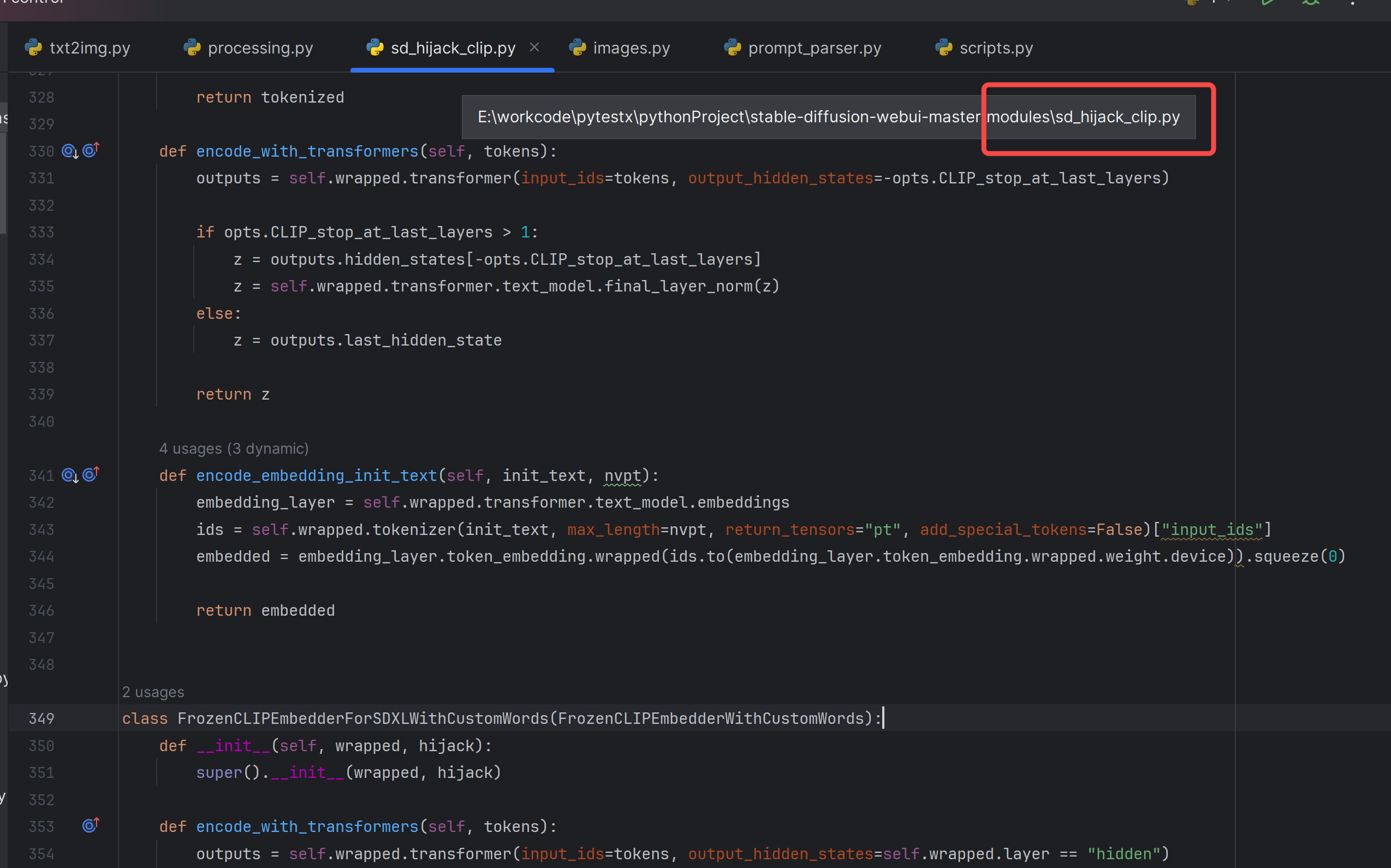
这段代码实现了一个文本提示权重加权的功能,它将自然语言提示转换为具有权重的token序列。当prompt中包含如(a cute girl: 2)这样的权重信息时,程序通过以下步骤处理:
-
首先,
prompt_parser.parse_prompt_attention(line)会解析prompt,提取出带有权重的部分。 -
在
tokenize_line方法中,针对每个带权重的文本片段(例如:text, weight),将其token化并按照权重分配到PromptChunk对象中。对于权重部分,它会被相应地添加到chunk.multipliers列表中,这个列表与chunk.tokens一一对应,表示每个token的权重。 -
当遇到需要添加到Embedding的特殊标记时,使用
PromptChunkFix记录下在PromptChunk中的偏移量和对应的Embedding信息,以便稍后应用到模型的嵌入层。 -
最后,在调用
forward函数时,根据这些权重对tokens进行处理,并在传递给transformer网络之前,将权重与token的嵌入向量相乘(或以其他方式结合权重)。这样就实现了对prompt中括号内指定权重的加权处理。
程序通过解析prompt文本,提取出权重值,并在生成token嵌入向量时将权重应用到相应的token上,从而实现了对prompt中括号内权重的加权功能。
这段代码在这里:
def process_tokens(self, remade_batch_tokens, batch_multipliers):"""sends one single prompt chunk to be encoded by transformers neural network.remade_batch_tokens is a batch of tokens - a list, where every element is a list of tokens; usuallythere are exactly 77 tokens in the list. batch_multipliers is the same but for multipliers instead of tokens.Multipliers are used to give more or less weight to the outputs of transformers network. Each multipliercorresponds to one token."""tokens = torch.asarray(remade_batch_tokens).to(devices.device)# this is for SD2: SD1 uses the same token for padding and end of text, while SD2 uses different ones.if self.id_end != self.id_pad:for batch_pos in range(len(remade_batch_tokens)):index = remade_batch_tokens[batch_pos].index(self.id_end)tokens[batch_pos, index+1:tokens.shape[1]] = self.id_padz = self.encode_with_transformers(tokens)pooled = getattr(z, 'pooled', None)emphasis = sd_emphasis.get_current_option(opts.emphasis)()emphasis.tokens = remade_batch_tokensemphasis.multipliers = torch.asarray(batch_multipliers).to(devices.device)emphasis.z = zemphasis.after_transformers()z = emphasis.zif pooled is not None:z.pooled = pooledreturn z
这段代码定义了一个名为process_tokens的方法,它属于一个继承自FrozenCLIPEmbedderWithCustomWordsBase的类,并且主要功能是对一组带有权重的tokens进行预处理并经过transformers神经网络编码。
-
方法接受两个参数:
remade_batch_tokens:这是经过重构的批次级别的tokens列表,其中每个元素也是一个包含多个tokens的列表,通常每个列表长度为77个tokens。batch_multipliers:与tokens对应的权重列表,结构同tokens列表一致,每个权重值对应于一个token,用于调整transformers网络输出的权重。
-
首先,将
remade_batch_tokens转换为PyTorch张量,并移动到当前设备上(devices.device)。 -
对于SD2情况(一种假设的变体),如果结束符id (
self.id_end) 和填充符id (self.id_pad) 不相同,则会将每个样本中结束符之后的所有位置替换为填充符id。 -
使用
self.encode_with_transformers方法对调整后的tokens张量进行编码,得到编码后的向量z。 -
获取编码后向量
z中的pooling结果(如果有)。 -
创建一个名为
emphasis的对象,该对象应该是某种策略类,用于处理强调(权重分配)。设置其属性为传入的tokens和multipliers,以及刚刚经过transformers编码的结果z。 -
调用
emphasis.after_transformers()方法来应用权重强调策略。 -
更新
z为强调策略处理后的编码结果。 -
如果有pooling结果,则将其重新赋给更新后的
z的.pooled属性。 -
最后返回经过整个处理流程后的编码结果
z。
通过这段代码可以看出,权重的确是在emphasis对象的相关方法中使用的,可能是通过某种方式改变z的某些部分(比如self-attention中的权重分布或是最终的输出向量),以便在模型计算中体现不同token的重要性差异。
Overcoming the 77 token limit in diffusers
在sdwebui这些知名库,都不用diffusers,因为diffusers定制化能力太弱,比如这个需求Overcoming the 77 token limit in diffusers,diffusers一年了都不好好写个文档解决:
有人提过这个问题:
https://github.com/huggingface/diffusers/issues/2136
方法1 手动拼
也就是下面这个代码可以用,但其实未使用77的倍数这个规则,这让我对unet中的交叉注意力如何接收clip出来的特征有很大的兴趣,改天换个文章介绍。
import torch
from diffusers import StableDiffusionPipelinepipe = StableDiffusionPipeline.from_pretrained("/ssd/xiedong/src_data/eff_train/Stable-diffusion/majicmixRealistic_v7_diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")# 2. Forward embeddings and negative embeddings through text encoder
prompt = 25 * "a photo of an astronaut riding a horse on mars"
max_length = pipe.tokenizer.model_max_length
print(max_length)input_ids = pipe.tokenizer(prompt, return_tensors="pt").input_ids
input_ids = input_ids.to("cuda")negative_ids = pipe.tokenizer("", truncation=False, padding="max_length", max_length=input_ids.shape[-1], return_tensors="pt").input_ids
negative_ids = negative_ids.to("cuda")concat_embeds = []
neg_embeds = []
for i in range(0, input_ids.shape[-1], max_length):concat_embeds.append(pipe.text_encoder(input_ids[:, i: i + max_length])[0])neg_embeds.append(pipe.text_encoder(negative_ids[:, i: i + max_length])[0])prompt_embeds = torch.cat(concat_embeds, dim=1)
negative_prompt_embeds = torch.cat(neg_embeds, dim=1)# 3. Forward
image = pipe(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_prompt_embeds).images[0]
image.save("astronaut_rides_horse.png")
方法2 compel
对提示词里做各种各样的加强操作,这个库还是挺6的:
https://github.com/damian0815/compel#compel
diffuers官方也喜欢这个库,有一段说明:
https://huggingface.co/docs/diffusers/main/en/using-diffusers/weighted_prompts
问询、帮助请看:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2