文章目录
- pdb
- pdb开始调试python
- pdb设置断点
- 单步执行
- 进入到函数的内部
- 执行到下一个断点或程序结束
- 调用栈查看命令
- 查看当前函数调用堆栈
- 向上一层函数查看调用堆栈
- 查看源代码
- import
- import 用法
- numpy
- 导入numpy模块
- numpy常用函数
- np.argmax
- np.sum
- range
- 生成连续序列
- 生成不连续序列
- print 格式化输出
- 格式化浮点数
- 打印格式化浮点数
- 字典
- 定义
- 初始化
pdb
pdb开始调试python
python -m pdb 源程序.py
pdb设置断点
- linenumber是断点所在行数
break linenumber
b linenumber
- 取消断点
clear linenumber
单步执行
n(ext)
进入到函数的内部
s(tep)
执行到下一个断点或程序结束
c(ontinue)
调用栈查看命令
w(here)
查看当前函数调用堆栈
up
向上一层函数查看调用堆栈
down
查看源代码
ll 查看当前函数的源代码
import
import 用法
-
导入整个模块。基本的import语句用于导入整个模块,可以使用模块名直接访问模块中的内容。例如,import math后可以使用math.sqrt()或math.fabs()等函数。
-
为模块指定别名。使用as关键字可以为导入的模块指定别名,例如import math as m,然后可以使用m.sqrt()代替math.sqrt()。
-
导入模块中的特定成员。使用from…import…语句可以导入模块中的特定函数、变量或类,例如from math import sqrt,这样可以直接使用sqrt()函数,而不需要通过模块名前缀。
-
导入模块中的所有内容。from…import *语句用于导入模块中的所有函数、类和变量,这样可以直接使用这些内容,而无需通过模块名前缀。但这种方法可能导致命名冲突,因此不推荐在大型项目中使用。
+ 导入包中的模块。可以使用点模块名来导入包中的模块,例如import os或import math
numpy
导入numpy模块
import numpy as np #导入numpy并设置别名
numpy常用函数
np.argmax
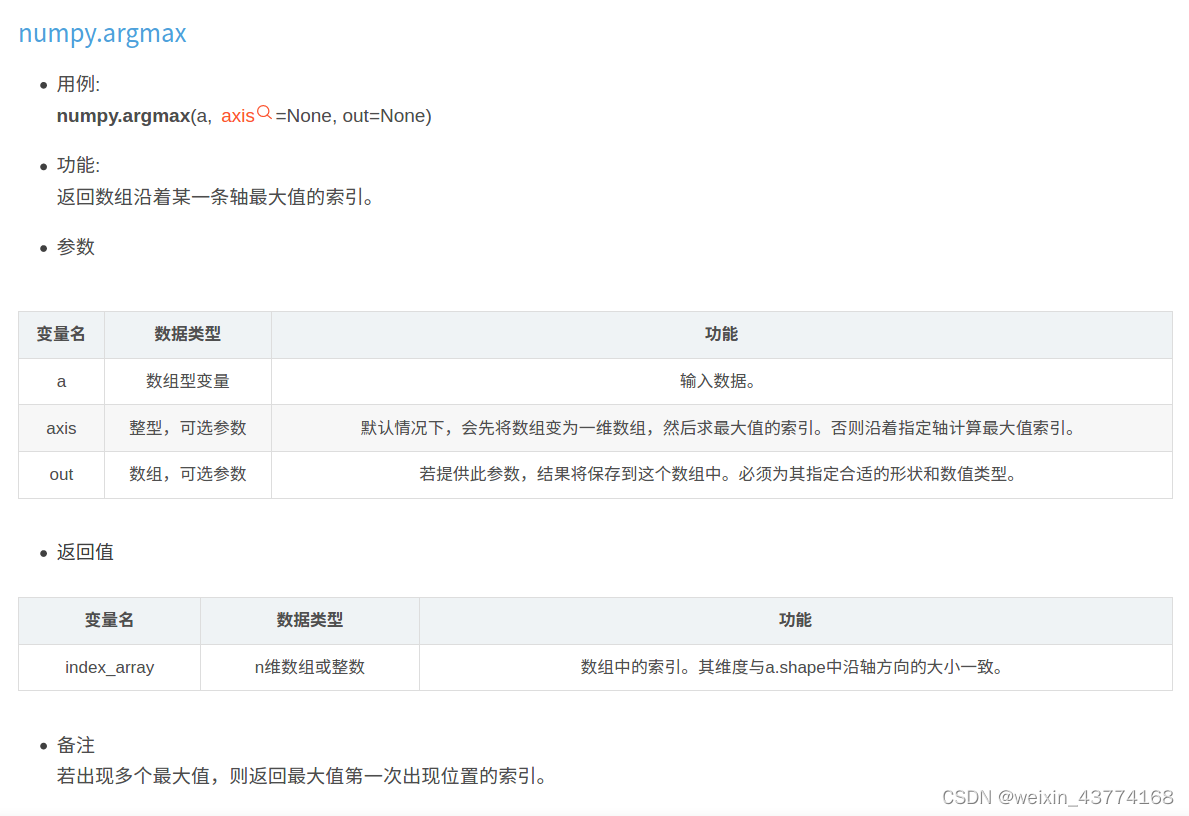
import numpy as np
a = np.arange(6).reshape(2,3)
print('a数组:\n{}'.format(a))
print('a数组中最大值的索引:{}'.format(np.argmax(a)))
print('a数组沿列方向最大值的索引:{}'.format(np.argmax(a, axis=0)))
print('a数组沿行方向最大值的索引:{}'.format(np.argmax(a, axis=1)))
b = np.arange(6)
b[1] = 5
print('b数组:\n{}'.format(b))
print('b数组最大值的索引:{}'.format(np.argmax(b))) # 仅仅返回5第一次出现的位置
a数组:
[[0 1 2]
[3 4 5]]
a数组中最大值的索引:5
a数组沿列方向最大值的索引:[1 1 1]
a数组沿行方向最大值的索引:[2 2]
b数组:
[0 5 2 3 4 5]
b数组最大值的索引:1
np.sum
- 不传参数是对所有函数求和
传axis(看懂了一点,以后要用的时候再看看)
添加链接描述
range
生成连续序列
for i in range(start,end): #start 到 end-1间隔为1 的序列
生成不连续序列
for i in range(start,end,interval): #start 到 end-1间隔为interval 的序列
print 格式化输出
name = 'Alice'
age = 25
print("My name is %s and I am %d years old." % (name,age))
格式化浮点数

打印格式化浮点数
print('%10.3f' % 3.1415926)
字典
定义
- 和C++的map差不多,都是保存键值对
初始化
- 空字典
network = {}- 赋值
#法一
network = {'W1':np.array([[0.1,0.3,0.5],[0.2,0.4,0.6] ]) }
#法二
network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])