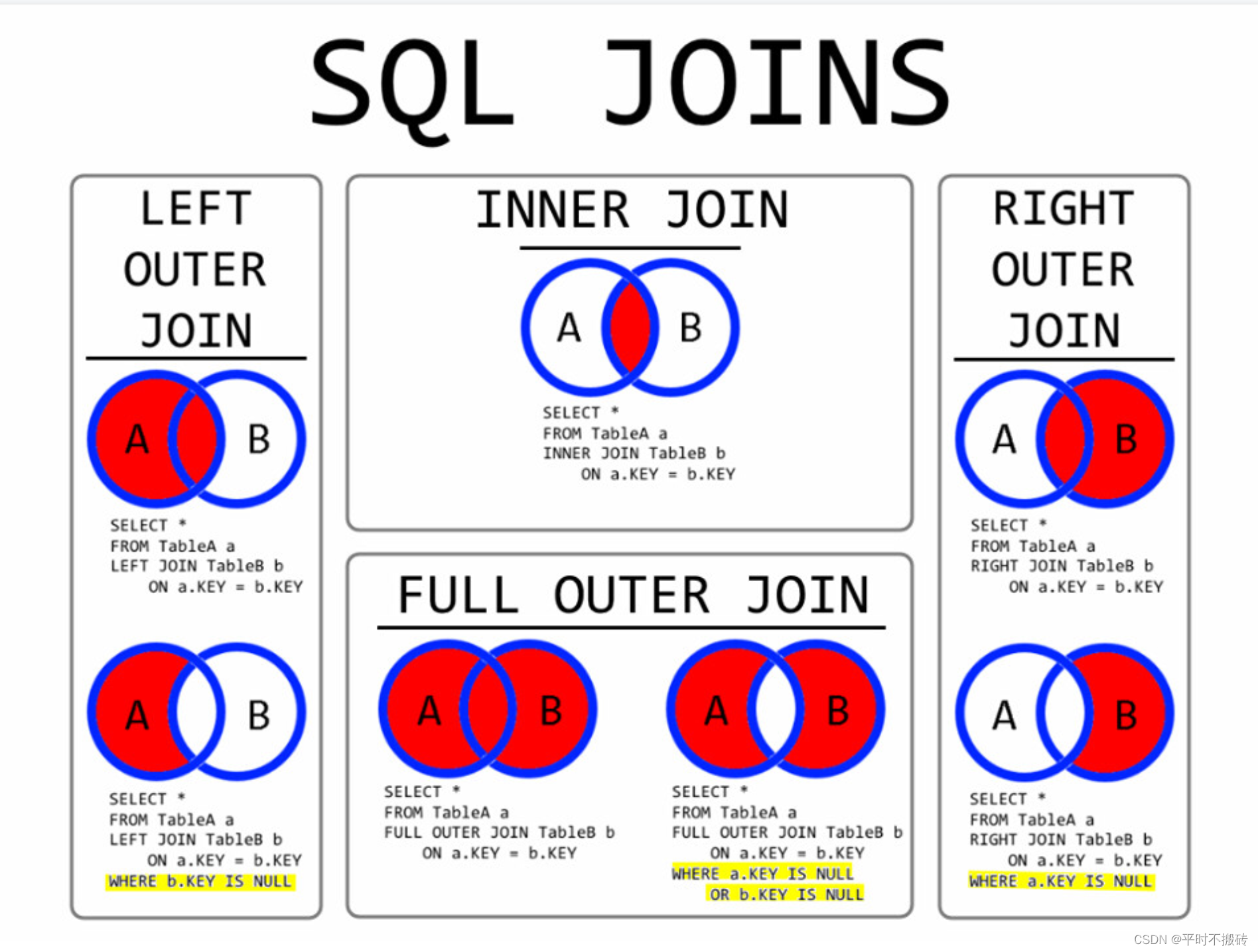
目录
关联规则 - 基本概念
关联规则的挖掘步骤:
Apriori算法
Apriori算法简介:
Apriori算法举例:
Apriori算法优缺点:
Apriori算法应用
FP-growth算法:
FP-growth算法简介:
FP-growth的数据结构:
FP-Growth算法流程:
FP-Growth算法优缺点:
关联规则 - 基本概念
项集:项的集合,包含k个项的项集称为k项集。
频繁项集:满足规定的最小支持度的项集。
支持度:support((X,Y)) =|X交Y|/N,表示物品集X和Y同时出现的次数占总记录数的比例。就是几个关联的数据在数据集中出现的次数占总数据集的比重,或者说几个数据关联出现的概率。一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
置信度:confidence(X→Y) = |X交Y|/|X| ,集合X与集合Y同时出现的总次数/集合X出现的记录数 。体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
提升度:lift(X→Y)=confidence(X→Y)/P(Y),表示含有X的条件下,同时含有Y的概率,与Y总体发生的概率之比。
利用提升度体现了X和Y之间的关联关系:
- 提升度大于1则𝑋→𝑌是强关联规则;
- 提升度小于等于1则𝑋→𝑌是无效的关联规则;
- 如果X和Y独立,则有 Lift(X→Y)=1 ,因为此时P(X|Y)=P(X)。
最小支持度:专家定义的衡量支持度的阈值,表示项目集在统计意义上的最低重要性。
最小置信度:专家定义的衡量置信度的阈值,表示关联规则的最低可靠性。
强关联规则:同时满足最小支持度阈值和最小置信度阈值的规则。
关联规则的挖掘步骤:
生成频繁项集和生成规则
找出强关联规则
找到所有满足强关联规则的项集
Apriori算法
Apriori算法简介:
Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过频繁项集生成和关联规则生成两个阶段来挖掘频繁项集。它的主要任务就是设法发现事物之间的内在联系。
比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了频繁出现的数据集,那么对于超市,我们可以优化产品的位置摆放,对于电商,我们可以优化商品所在的仓库位置,达到节约成本,增加经济效益的目的。
Apriori算法举例:

Apriori使用频繁项集的先验知识,使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。其原理是如果某个项集是频繁的,那么它的子集也是频繁的。反过来说,如果一个项集是非频繁的,那么它的所有超集也是非频繁的。比如{1,2}出现的次数已经小于最小支持度了(非频繁的),那么超集{0,1,2}的组合肯定也是非频繁项集。
连接步
若有两个k-1项集,每个项集按照“属性-值”(一般按值)的字母顺序进行排序。如果两个k-1项集的前k-2个项相同,而最后一个项不同,则证明它们是可连接的,即这个k-1项集可以联姻,即可连接生成k项集。使如有两个3项集:{a, b, c}{a, b, d},这两个3项集就是可连接的,它们可以连接生成4项集{a, b, c, d}。又如两个3项集{a, b, c}{a, d, e},这两个3项集显示是不能连接生成3项集的;
剪枝步
若一个项集的子集不是频繁项集,则该项集肯定也不是频繁项集。例如,若存在3项集{a, b, c},如果它的2项子集{a, b}的支持度即同时出现的次数达不到阈值,则{a, b, c}同时出现的次数显然也是达不到阈值的。因此,若存在一个项集的子集不是频繁项集,那么该项集就应该被无情的舍弃。
Apriori算法优缺点:
优点:
(1)使用先验原理,大大提高了频繁项集逐层产生的效率;
(2)简单易理解;数据集要求低。
缺点:
(1)每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此人们开始寻求更好性能的算法。
Apriori算法是一个非常经典的频繁项集的挖掘算法,很多算法都是基于Apriori算法而产生的,包括FP-Tree,GSP, CBA等。这些算法利用了Apriori算法的思想,但是对算法做了改进,数据挖掘效率更好一些,因此现在一般很少直接用Apriori算法来挖掘数据了,但是理解Apriori算法是理解其它Apriori类算法的前提,同时算法本身也不复杂。
scikit-learn中并没有频繁集挖掘相关的算法类库,这不得不说是一个遗憾。
Apriori算法应用
推荐系统:用关联算法做协同过滤
可以找出用户购买的所有物品数据里频繁出现的项集,找到满足支持度阈值的关联物品的频繁N项集或者序列。如果用户购买了频繁N项集或者序列里的部分物品,可以将频繁项集或序列里的其他物品按一定的评分准则推荐给用户,这个评分准则可以包括支持度,置信度和提升度等。
Apriori不适于非重复项集数元素较多的案例,建议分析的商品种类为10类左右。
FP-growth算法:
FP-growth算法简介:
FP-growth算法建立在Apriori算法的概念之上,不同之处是它采用了更高级的数据结构FP-tree减少扫描数据次数,只需要两次扫描数据库,相比于Apriori减少了I/O操作,克服了Apriori算法需要多次扫描数据库的问题。
FP-growth的数据结构:
为了减少I/O次数, FP-growth算法引入了一些数据结构来临时存储数据。这个数据结构包括三部分:
一个项头表里面记录了所有的1项频繁集出现的次数,按照次数降序排列。
FP-Tree将原始数据集映射到了内存中的一颗FP树。
节点链表所有项头表里的1项频繁集都是一个节点链表的头,它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP-Tree之间的联系查找和更新,也好理解。
https://www.cnblogs.com/pinard/p/6307064.html
FP-Growth算法流程:
- 扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
- 扫描数据,将读到的原始数据剔除非频繁1项集,并将每一条再按照支持度降序排列。
- 读入排序后的数据集,逐条插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
- 从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集。
- 如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。
FP-Growth算法优缺点:
优点:
FP-Growth一般要快于Apriori ;
缺点:
FP-Growth实现比较困难,在某些数据集上性能会下降;
FP-Growth适用数据类型:离散型数据
由于python中并未封装有关关联规则欸到第三方库,因此代码实现部分我会放在将spark时在对关联规则进行代码实现