2023年6月第4周大模型荟萃
- 2023.6.30
- 版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、腾讯云首次公布大模型进展
6月19日,腾讯云召开行业大模型及智能应用技术峰会,首次公布腾讯云行业大模型研发进展,联合22家客户正式启动行业大模型共建合作,并携手17家生态伙伴共同发起了“腾讯云行业大模型生态计划”,致力于共同推进大模型在产业领域的创新和落地。据透露,基于腾讯HCC高性能计算集群和大模型能力,腾讯云已经为传媒、文旅、政务、金融等10余个行业提供了超过50个大模型行业解决方案。会上,腾讯公布腾讯云 MaaS 服务解决方案。
腾讯云认为,相比通用大模型,企业更需要针对自身具体行业的大模型,并结合企业自身的数据进行训练和精调,以打造出更实用的智能服务。企业对提供的专业服务要求高,且容错性低,因此使用的大模型必须具备可控、可追溯和可修正的特点,并经过反复充分的测试。

2、OpenAI 或将推出 AI 模型商店,平台可以实现双向对接
OpenAI 正计划推出一个类似苹果“App Store”的 AI 模型应用商店,平台可以实现双向对接,开发者可以上架他们基于 OpenAI 技术搭建的产品,企业也可以按需使用市面上的 LLM,例如识别金融欺诈,或根据内部文件回答特定市场的问题。很多 ChatGPT 的企业客户通常会根据自己的特定用途定制 AI 模型,定制模型一多,OpenAI 便有了搭建模型商店的想法。OpenAI 还表示,目前基于 ChatGPT 相关的插件使用率不高,搭建一个类似“应用商店”的平台可以有效提高插件的使用率。
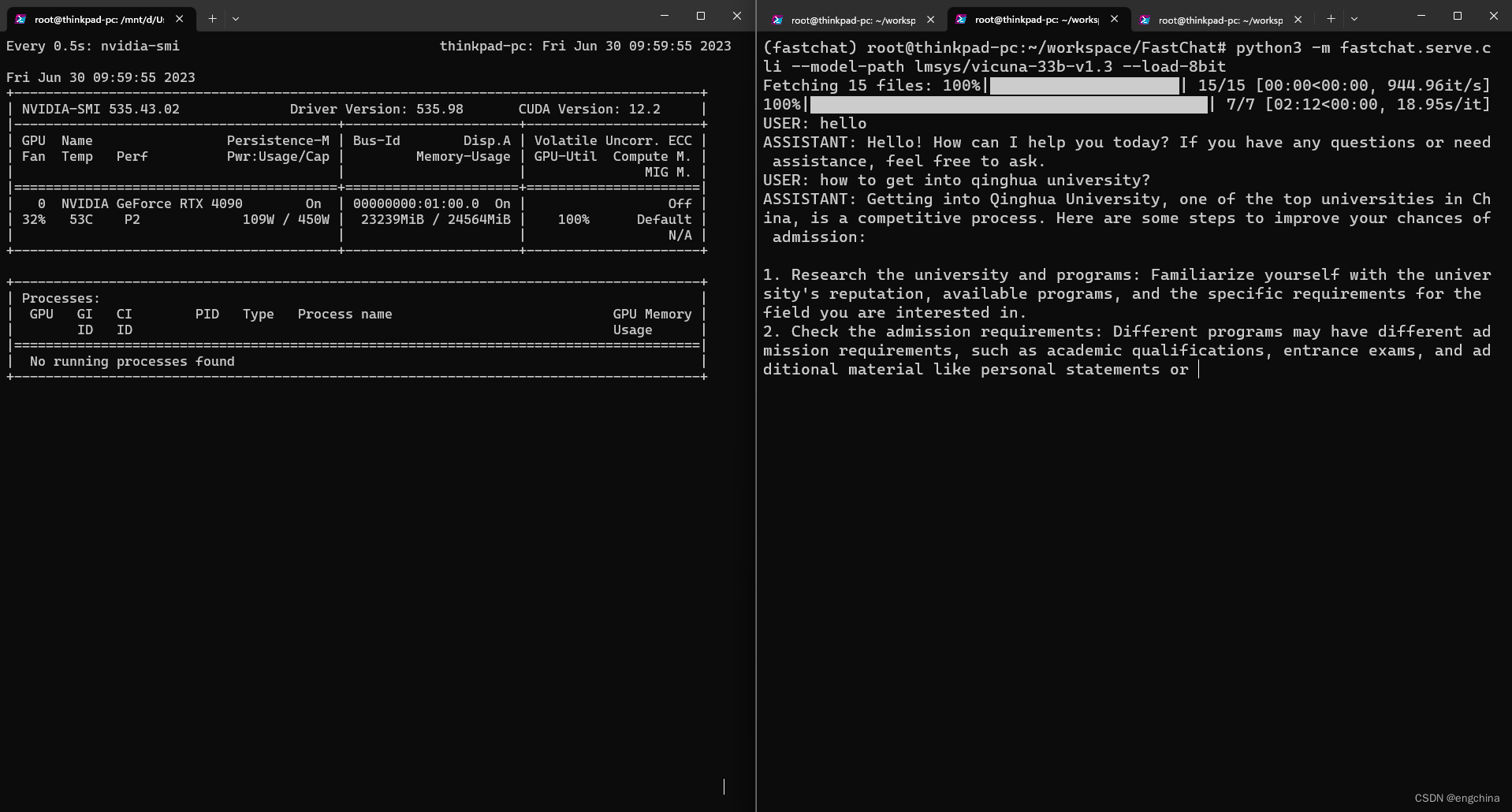
3、MosaicML 发布 MPT-30B 大语言模型,训练成本仅 70 万美元
AI 创业公司 MosaicML 近日发布了 MPT-30B 大语言模型,该模型具有 300 亿参数,训练成本为 70 万美元(约 502.44 万元人民币),远低于 GPT-3 等同类产品所需的数千万美元训练成本。由于 MPT-30B 的成本较低,体积较小,它也可以更快速地被训练,并且更适合部署在本地硬件上,有望促进行业逐步降低此类模型训练成本,扩大 AI 模型在更广泛领域的运用。
4、美国律师因引用 ChatGPT 虚构案例被罚
当地时间 6 月 22 日,美国纽约联邦法官作出了一项判决,Levidow, Levidow & Oberman 律师事务所引用了 ChatGPT 撰写的一份由虚假案例引证的法庭简报,行为恶劣,对其处以罚款 5000 美元。就目前来看,类似 ChatGPT 之类的生成式 AI 也许可以在一些基础的法律服务方面给用户提供帮助,比如受众需求比较大的劳动案件、房地产案件、买卖纠纷、继承纠纷等,可以提供一些简单的解答。但对于比较复杂的纠纷,可能还是需要律师来服务。
5、Dropbox 推出 AI 搜索工具
云存储服务商 Dropbox 的日本子公司 Dropbox Japan 近日发布了基于 AI 的通用搜索工具 Dropbox Dash 测试版,该工具聚合了多个热门办公平台和应用,能有效提高用户的信息搜索效率。根据官方介绍,Dropbox Dash 与 Google Workspace、微软 Outlook 和 Salesforce 等平台集成,使用户可以在同一个搜索栏中快速找到工作所需信息,无需在应用程序之间来回跳转就能共享内容、加入会议或查找演示文稿。由于 Dropbox Dash 采用了机器学习技术,因此随着用户使用次数增加,其搜索结果也会依据用户偏好持续改进。此外,Dropbox Dash 也提供了堆栈功能,允许用户快速存储、整理和检索网页地址,并像文件夹列表一样对这些地址进行可视化的分级归纳。
6、清华唐杰团队发布开源 WebGLM
清华唐杰团队发布并开源 WebGLM,一个参数 100 亿的联网问答聊天机器人,相关论文入选 KDD2023。你可以问它任何问题,然后它将列举出网上(例如维基百科、相关官网)相关的文章链接,整理出答案。据介绍,在性能对比测试中,WebGLM 的水平已经高于 OpenAI 135 亿参数的 WebGPT,根据评估结果,尽管 WebGLM 的搜索结果略逊于 WebGPT-175B,但远好于Perplexity.ai 和 WebGPT-13B。
WebGLM 的目标是通过 Web 搜索和检索功能,增强预训练大语言模型,同时可以进行高效的实际部署。为此,作者基于三种策略进行开发:大模型增强检索器、自举生成器、基于人类偏好的打分器。大型语言模型增强检索器会将前五个最相关的页面作为参考源,让自举生成器生成多个答案,最终打分器选出最可能符合人类偏好的那一个作为最终输出。
7、东北大学发布以知识图谱构建为核心的大模型 TechGPT
2023 年 6 月 26 日,东北大学知识图谱研究组正式发布大语言模型 TechGPT。与当前其他各类大模型相比,TechGPT 主要强化了以“知识图谱构建”为核心的关系三元组抽取等各类信息抽取任务、以“逻辑推理”为核心的机器阅读理解等各类智能问答任务、以“文本理解”为核心的关键词生成等各类序列生成任务。在这三大自然语言处理核心能力之内,TechGPT 还具备了对计算机科学、材料、机械、冶金、金融和航空航天等十余种垂直专业领域自然语言文本的处理能力。
TechGPT 以 BELLE 作为强大的中文预训练 LLM 基座,并在 TechKG 大规模的中文学术语料支持下训练完成。得益于 BELLE 的前期工作,不仅完成了 70 亿参数(7B)版本的训练,也完成了 130 亿参数(13B)版本的训练。7B 的模型可以在显存和性能受限的设备上运行,而 13B 的模型可以提供更具逻辑和更高精度的回答。目前 7B 版本的 TechGPT 已经在 Hugging Face 和 GitHub 上开源。
8、大模型v1.2版评测榜单
综合能力得分为分类能力、信息抽取能力、阅读理解能力三者得分的平均值。见:https://zhuanlan.zhihu.com/p/634608422

无论是百度还是讯飞的老大,在他们的嘴中,早就脚踩ChatGPT,拳打OpenAI了,但是第三方测评却不这么看。
9、第 2 个“GPT 产业联盟"宣布成立
据证券时报,为实现战略协同、资源协同和能力协同,由中国互联网协会、中国信息通信研究院云大所、360集团联合主办的“GPT产业联盟”成立大会将在 6 月 28 日举办,以期携手推动 AI 技术的创新与发展。
早在今年 4 月 18 日,在北京举行的“2023 全球元宇宙大会”上,由中国移动通信联合会、中国电信、中国移动、中国联通、中国广电等单位共同发起成立了“GPT产业联盟”。
这种现象,跟目前国内大模型乱战环境分不开。大家都在搞大模型,谁也不服谁,大家的水平都差不多,都自称脚踩ChatGPT。
10、清华大学发布 ChatGLM2-6B 第二代大模型
6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代 ChatGLM2-6B 大模型。与第一代大模型想必,主要有四点升级:
- 性能大幅提升。第二代的ChatGLM2-6B的基座模型使用了GLM模型的混合目标函数,在1.4万亿中英文tokens数据集上训练,并做了模型对齐,使得性能提升很高。
- 更长的上下文。在第一代ChatGLM-6B上,模型的最高上下文长度是2K。而第二代的ChatGLM2-6B的基座模型使用了FlashAttention技术,升级到32K。
- 更高效的推理,更快更便宜。ChatGLM2-6B使用了Multi-Query Attention技术,可以在更低地显存资源下以更快的速度进行推理,官方宣称,推理速度相比第一代提升42%。
- 更加开放的协议。在第一代ChatGLM-6B模型中,有一个比较遗憾的是它的模型开源协议限制较大,完全禁止商用。而第二代的ChatGLM2-6B则宣布对学术研究完全开放,而且允许申请商用授权,不过需要书面申请,并且没有说明是否收费。