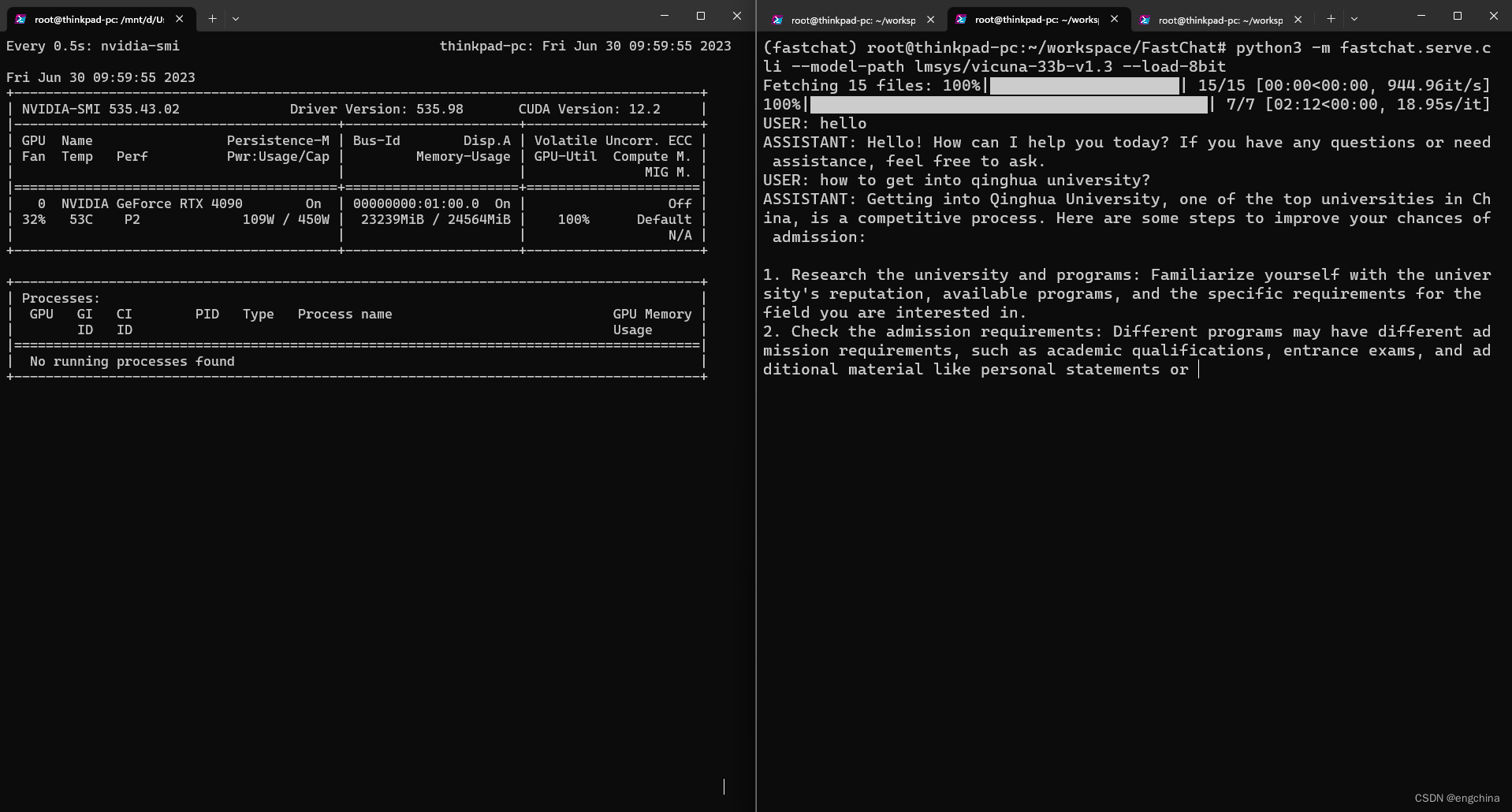
测试在 4090 上运行 vicuna-33b 进行推理
今天尝试在 4090 上运行 vicuna-33b 进行推理,使用的是 8bit 量化。
运行命令如下,
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-33b-v1.3 --load-8bit
结论,使用 8bit 量化在 4090 上可以运行 vicuna-33b 进行推理,显存用到大概 23239MiB,GPU 使用率基本全程 100%,推理过程非常非常慢。
完结!