文章目录
- 雪花算法介绍
- 起源与命名
- 基本原理与结构
- 优势与特点
- 应用场景
- 代码实现
- 代码结构
- 自定义机器标识
- RandomWorkIdChoose
- LocalRedisWorkIdChoose
- lua脚本
- 实体类
- SnowflakeIdInfo
- WorkCenterInfo
- 雪花算法类
- 配置类
- 雪花算法工具类
- 说明
雪花算法介绍
在复杂而庞大的分布式系统中,确保数据实体的唯一标识性是一项至关重要的任务,生成全局唯一且有序的ID生成机制成为必不可少的环节。雪花算法(Snowflake Algorithm)正是为此目的而生,以其简洁的设计、高效的表现与良好的扩展性赢得了业界的广泛认可。
起源与命名
雪花算法最早由Twitter公司于2010年左右设计并应用于其内部系统,旨在解决分布式环境中大规模、高并发的唯一ID生成问题。算法得名“雪花”,源于自然界中雪花的独特性——每片雪花的形态各异,象征着生成的ID如雪花般独一无二。这一形象化的命名,恰好体现了雪花算法所生成ID的特性:每个ID在全局范围内具有唯一性,且蕴含丰富的内部结构信息。
基本原理与结构
雪花算法的核心思想是将一个64位的长整型数字划分为多个部分,每个部分代表不同维度的信息。典型的雪花ID结构如下:
-
符号位(1位):通常为0,表示生成的ID为正数,符合大多数编程语言的长整数表示习惯。
-
时间戳(41位):记录了ID生成时的精确时间点,通常精确到毫秒级别。这使得ID具备了天然的时间顺序,同时也为系统提供了大致的时间范围参考。
-
数据中心标识(5位):用于区分不同的数据中心或地域,确保在多数据中心部署下ID的唯一性。
-
机器标识(5位):标识生成ID的工作节点,可以是服务器ID、进程ID等,确保同一数据中心内不同机器生成的ID不会冲突。
-
序列号(12位):在同一毫秒内,同一工作节点生成多个ID时,通过递增序列号来区分。序列号部分允许的最大值为4095(即每毫秒可以生成2^12个不重复ID),足以应对大部分场景下的瞬时并发需求。
这种划分方式确保了雪花ID在空间分布上既能容纳足够多的节点和并发请求,又能在时间维度上保持严格递增,从而满足全局唯一、趋势有序的需求。当然,每个部分的位数不是固定的,如果需求更复杂,可以增加相应部分的位数。例如,并发非常高,可以增加序列号的位数。
优势与特点
-
全局唯一:由于时间戳、数据中心标识、机器标识和序列号的组合具有唯一性,雪花算法能确保在分布式环境中生成的每一个ID都是全球唯一的。 -
趋势递增:时间戳作为ID的主要部分,使得生成的ID整体上按照时间顺序排列,有利于数据库索引优化,提升查询效率。 -
高可用:在单个节点故障时,其他节点仍能继续生成ID,不会影响整个系统的运行。同时,通过合理分配数据中心和机器标识,可以轻松应对节点扩容或迁移。 -
高效性:算法实现简单,生成ID过程几乎无锁,性能极高。并且由于ID为纯数字型,存储和传输效率高。 -
易于解析:由于ID结构清晰,可以根据ID直接解析出其包含的时间、数据中心、机器等信息,便于日志分析、问题定位和数据归档。
应用场景
雪花算法适用于多种需要全局唯一ID的分布式场景,包括但不限于:
-
数据库主键:作为数据库表的主键,确保每一行记录具有唯一标识,且插入顺序与生成时间相关联。
-
消息队列:为消息系统中的消息生成唯一ID,便于消息追踪、去重和排序。
-
分布式事务:在分布式事务中,为事务ID或操作记录分配唯一标识。
-
分布式缓存:为缓存中的键生成唯一ID,避免键冲突。
代码实现
代码结构
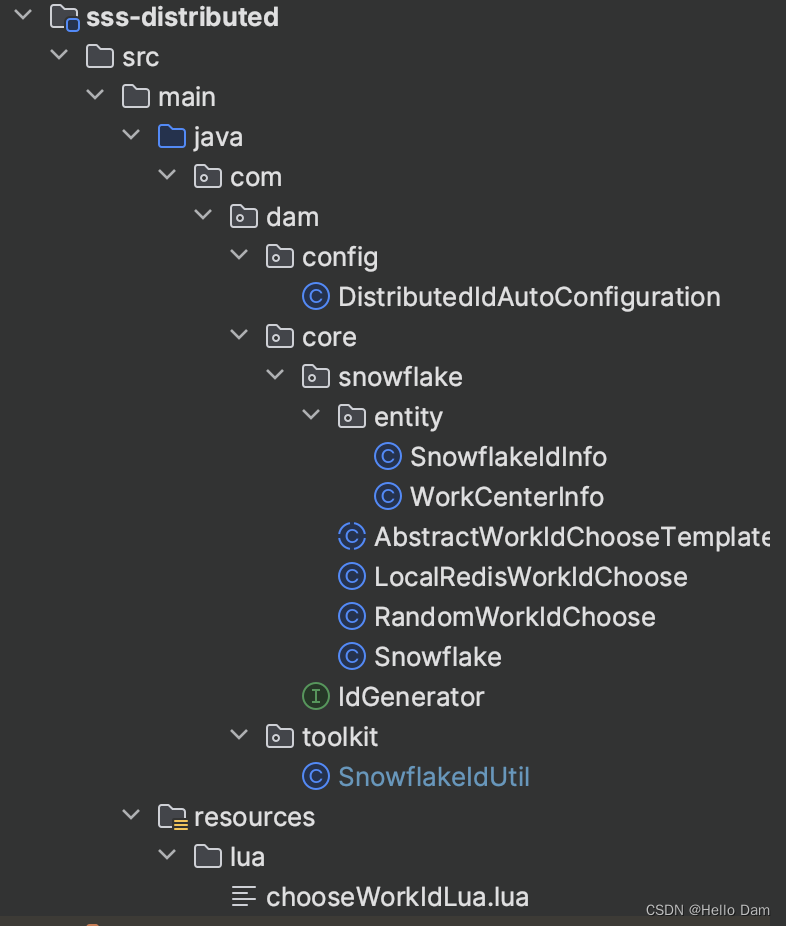
自定义机器标识
package com.dam.core.snowflake;import cn.hutool.core.date.SystemClock;
import com.dam.core.snowflake.entity.WorkCenterInfo;
import lombok.extern.slf4j.Slf4j;
import com.dam.toolkit.SnowflakeIdUtil;
import org.springframework.beans.factory.annotation.Value;/*** 雪花算法模板生成**/
@Slf4j
public abstract class AbstractWorkIdChooseTemplate {/*** 是否使用 {@link SystemClock} 获取当前时间戳*/@Value("${sss.snowflake.is-use-system-clock:false}")private boolean isUseSystemClock;/*** 根据自定义策略获取 WorkId 生成器** @return*/protected abstract WorkCenterInfo chooseWorkId();/*** 选择 WorkId 并初始化雪花*/public void chooseAndInit() {// 模板方法模式: 通过调用抽象方法获取 WorkId 来创建雪花算法,抽象方法的具体实现交给子类WorkCenterInfo workCenterInfo = chooseWorkId();long workId = workCenterInfo.getWorkId();long dataCenterId = workCenterInfo.getDataCenterId();// 生成机器标识之后,初始化工具类的雪花算法静态对象Snowflake snowflake = new Snowflake(workId, dataCenterId, isUseSystemClock);log.info("Snowflake type: {}, workId: {}, dataCenterId: {}", this.getClass().getSimpleName(), workId, dataCenterId);SnowflakeIdUtil.initSnowflake(snowflake);}
}
RandomWorkIdChoose和LocalRedisWorkIdChoose主要用来实现抽象方法chooseWorkId来生成工作中心ID和数据中心ID
- RandomWorkIdChoose:随机生成
- LocalRedisWorkIdChoose:使用Redis的lua脚本,保证分布式部署的时候,每台机器的数据中心ID或工作中心ID不同
RandomWorkIdChoose
通过随机生成的dataCenterId和workId很容易发生冲突,属项目没有Redis的无奈之举。但是在日常开发中,项目基本都是需要使用Redis的,所以RandomWorkIdChoose也很少会使用。
package com.dam.core.snowflake;import com.dam.core.snowflake.entity.WorkCenterInfo;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.InitializingBean;/*** 使用随机数获取雪花 WorkId*/
@Slf4j
public class RandomWorkIdChoose extends AbstractWorkIdChooseTemplate implements InitializingBean {@Overrideprotected WorkCenterInfo chooseWorkId() {int start = 0, end = 31;return new WorkCenterInfo(getRandom(start, end), getRandom(start, end));}@Overridepublic void afterPropertiesSet() throws Exception {chooseAndInit();}private static long getRandom(int start, int end) {long random = (long) (Math.random() * (end - start + 1) + start);return random;}
}
LocalRedisWorkIdChoose
通过使用Redis来记录上一台机器所申请的dataCenterId和workId,新机器申请标识的时候,通过对已有dataCenterId或workId进行递增从而找到没有被使用的dataCenterId和workId组合。但是因为位数的约束,不重复数肯定有一个上限,需要根据集群大小来调整数据中心和工作中心的位数
package com.dam.core.snowflake;import cn.hutool.core.collection.CollUtil;
import com.dam.ApplicationContextHolder;
import com.dam.core.snowflake.entity.WorkCenterInfo;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.scripting.support.ResourceScriptSource;import java.util.ArrayList;
import java.util.List;/*** 使用 Redis 获取雪花 WorkId*/
@Slf4j
public class LocalRedisWorkIdChoose extends AbstractWorkIdChooseTemplate implements InitializingBean {private RedisTemplate stringRedisTemplate;public LocalRedisWorkIdChoose() {System.out.println("执行 LocalRedisWorkIdChoose -----------------------");StringRedisTemplate bean = ApplicationContextHolder.getBean(StringRedisTemplate.class);
// System.out.println("bean = " + bean);this.stringRedisTemplate = bean;}@Overridepublic WorkCenterInfo chooseWorkId() {DefaultRedisScript redisScript = new DefaultRedisScript();redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/chooseWorkIdLua.lua")));List<Long> luaResultList = null;try {redisScript.setResultType(List.class);luaResultList = (ArrayList) this.stringRedisTemplate.execute(redisScript, null);} catch (Exception ex) {log.error("Redis Lua 脚本获取 WorkId 失败", ex);}return CollUtil.isNotEmpty(luaResultList) ? new WorkCenterInfo(luaResultList.get(0), luaResultList.get(1)) : new RandomWorkIdChoose().chooseWorkId();}@Overridepublic void afterPropertiesSet() throws Exception {chooseAndInit();}
}
lua脚本
lua脚本旨在为不同的机器生成不同的数据中心ID或者工作中心ID,避免不同机器生成冲突的ID。但是由于数据中心部分和工作中心部分都是占5 bit,所以最多生成1024个不同的【数据中心、工作中心】组合,如果集群的机器数量大于1024,就要考虑给数据中心和工作中心分配更多的位数。
-- 定义了三个本地变量:
-- hashKey:表示在Redis中存储工作ID和数据中心ID的哈希表(Hash)的键名
-- dataCenterIdKey 和 workIdKey:分别表示哈希表中存储数据中心ID和工作ID的字段名
local hashKey = 'sss:snowflake_work_id_key'
local dataCenterIdKey = 'dataCenterId'
local workIdKey = 'workId'-- 首先,检查哈希表hashKey是否存在。
-- 如果不存在(即首次初始化),则创建该哈希表并使用hincrby命令初始化dataCenterIdKey和workIdKey字段,初始值均为0
-- 然后返回一个数组 { 0, 0 },表示当前工作ID和数据中心ID均为0
if (redis.call('exists', hashKey) == 0) thenredis.call('hincrby', hashKey, dataCenterIdKey, 0)redis.call('hincrby', hashKey, workIdKey, 0)return { 0, 0 }
end-- 若哈希表已存在,从哈希表中获取当前的dataCenterId和workId值,并将其转换为数字类型
local dataCenterId = tonumber(redis.call('hget', hashKey, dataCenterIdKey))
local workId = tonumber(redis.call('hget', hashKey, workIdKey))-- 定义最大值常量max为31,用于判断ID是否达到上限
local max = 31
-- 定义两个局部变量resultWorkId和resultDataCenterId,用于存储最终要返回的新工作ID和数据中心ID
local resultWorkId = 0
local resultDataCenterId = 0-- 如果两者均达到上限(dataCenterId == max且workId == max),将它们重置为0
if (dataCenterId == max and workId == max) thenredis.call('hset', hashKey, dataCenterIdKey, '0')redis.call('hset', hashKey, workIdKey, '0')-- 若只有工作ID未达上限(workId ~= max),递增工作ID(hincrby),并将新的工作ID作为结果,数据中心ID保持不变
elseif (workId ~= max) thenresultWorkId = redis.call('hincrby', hashKey, workIdKey, 1)resultDataCenterId = dataCenterId-- 若只有数据中心ID未达上限(dataCenterId ~= max),递增数据中心ID,将新的数据中心ID作为结果,同时将工作ID重置为0
elseif (dataCenterId ~= max) thenresultWorkId = 0resultDataCenterId = redis.call('hincrby', hashKey, dataCenterIdKey, 1)redis.call('hset', hashKey, workIdKey, '0')
endreturn { resultWorkId, resultDataCenterId }
实体类
SnowflakeIdInfo
package com.dam.core.snowflake.entity;import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;/*** 雪花算法组成部分,通常用来反解析使用*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class SnowflakeIdInfo {/*** 时间戳*/@JsonSerialize(using = ToStringSerializer.class)private Long timestamp;/*** 工作机器节点 ID*/private Integer workerId;/*** 数据中心 ID*/private Integer dataCenterId;/*** 自增序号,当高频模式下时,同一毫秒内生成 N 个 ID,则这个序号在同一毫秒下,自增以避免 ID 重复*/private Integer sequence;/*** 通过基因法生成的序号,会和 {@link SnowflakeIdInfo#sequence} 共占 12 bit*/private Integer gene;
}
WorkCenterInfo
package com.dam.core.snowflake.entity;import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** WorkId 包装器*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class WorkCenterInfo {/*** 工作ID*/@JsonSerialize(using = ToStringSerializer.class)private Long workId;/*** 数据中心ID*/@JsonSerialize(using = ToStringSerializer.class)private Long dataCenterId;
}雪花算法类
package com.dam.core.snowflake;import cn.hutool.core.date.SystemClock;
import cn.hutool.core.lang.Assert;
import cn.hutool.core.util.IdUtil;
import cn.hutool.core.util.RandomUtil;
import cn.hutool.core.util.StrUtil;
import com.dam.core.IdGenerator;
import com.dam.core.snowflake.entity.SnowflakeIdInfo;import java.io.Serializable;
import java.util.Date;/*** 雪花算法真正生成ID的类** Twitter的Snowflake 算法* 分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。** snowflake的结构如下(每部分用-分开):** 符号位(1bit)- 时间戳相对值(41bit)- 数据中心标志(5bit)- 机器标志(5bit)- 递增序号(12bit)* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000* * 第一位为未使用(符号位表示正数),接下来的41位为毫秒级时间(41位的长度可以使用69年)<br>* 然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)<br>* 最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)* * 并且可以通过生成的id反推出生成时间,datacenterId和workerId* * 参考:http://www.cnblogs.com/relucent/p/4955340.html<br>* 关于长度是18还是19的问题见:https://blog.csdn.net/unifirst/article/details/80408050** @author Looly* @since 3.0.1*/
public class Snowflake implements Serializable, IdGenerator {private static final long serialVersionUID = 1L;/*** 默认的起始时间,为Thu, 04 Nov 2010 01:42:54 GMT*/private static long DEFAULT_TWEPOCH = 1288834974657L;/*** 默认回拨时间,2S*/private static long DEFAULT_TIME_OFFSET = 2000L;private static final long WORKER_ID_BITS = 5L;// 最大支持机器节点数0~31,一共32个@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})private static final long MAX_WORKER_ID = -1L ^ (-1L << WORKER_ID_BITS);private static final long DATA_CENTER_ID_BITS = 5L;// 最大支持数据中心节点数0~31,一共32个@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})private static final long MAX_DATA_CENTER_ID = -1L ^ (-1L << DATA_CENTER_ID_BITS);// 序列号12位(表示只允许workId的范围为:0-4095)private static final long SEQUENCE_BITS = 12L;// 机器节点左移12位private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;// 数据中心节点左移17位private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;// 时间毫秒数左移22位private static final long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;// 序列掩码,用于限定序列最大值不能超过4095private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);/*** 初始化时间点*/private final long twepoch;private final long workerId;private final long dataCenterId;private final boolean useSystemClock;/*** 允许的时钟回拨毫秒数*/private final long timeOffset;/*** 当在低频模式下时,序号始终为0,导致生成ID始终为偶数<br>* 此属性用于限定一个随机上限,在不同毫秒下生成序号时,给定一个随机数,避免偶数问题。<br>* 注意次数必须小于{@link #SEQUENCE_MASK},{@code 0}表示不使用随机数。<br>* 这个上限不包括值本身。*/private final long randomSequenceLimit;/*** 自增序号,当高频模式下时,同一毫秒内生成N个ID,则这个序号在同一毫秒下,自增以避免ID重复。*/private long sequence = 0L;private long lastTimestamp = -1L;/*** 构造,使用自动生成的工作节点ID和数据中心ID*/public Snowflake() {this(IdUtil.getWorkerId(IdUtil.getDataCenterId(MAX_DATA_CENTER_ID), MAX_WORKER_ID));}/*** @param workerId 终端ID*/public Snowflake(long workerId) {this(workerId, IdUtil.getDataCenterId(MAX_DATA_CENTER_ID));}/*** @param workerId 终端ID* @param dataCenterId 数据中心ID*/public Snowflake(long workerId, long dataCenterId) {this(workerId, dataCenterId, false);}/*** @param workerId 终端ID* @param dataCenterId 数据中心ID* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳*/public Snowflake(long workerId, long dataCenterId, boolean isUseSystemClock) {this(null, workerId, dataCenterId, isUseSystemClock);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @since 5.1.3*/public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock) {this(epochDate, workerId, dataCenterId, isUseSystemClock, DEFAULT_TIME_OFFSET);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @param timeOffset 允许时间回拨的毫秒数* @since 5.8.0*/public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock, long timeOffset) {this(epochDate, workerId, dataCenterId, isUseSystemClock, timeOffset, 0);}/*** @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用* @param workerId 工作机器节点id* @param dataCenterId 数据中心id* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳* @param timeOffset 允许时间回拨的毫秒数* @param randomSequenceLimit 限定一个随机上限,在不同毫秒下生成序号时,给定一个随机数,避免偶数问题,0表示无随机,上限不包括值本身。* @since 5.8.0*/public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock, long timeOffset, long randomSequenceLimit) {this.twepoch = (null != epochDate) ? epochDate.getTime() : DEFAULT_TWEPOCH;this.workerId = Assert.checkBetween(workerId, 0, MAX_WORKER_ID);this.dataCenterId = Assert.checkBetween(dataCenterId, 0, MAX_DATA_CENTER_ID);this.useSystemClock = isUseSystemClock;this.timeOffset = timeOffset;this.randomSequenceLimit = Assert.checkBetween(randomSequenceLimit, 0, SEQUENCE_MASK);}/*** 根据Snowflake的ID,获取机器id** @param id snowflake算法生成的id* @return 所属机器的id*/public long getWorkerId(long id) {return id >> WORKER_ID_SHIFT & ~(-1L << WORKER_ID_BITS);}/*** 根据Snowflake的ID,获取数据中心id** @param id snowflake算法生成的id* @return 所属数据中心*/public long getDataCenterId(long id) {return id >> DATA_CENTER_ID_SHIFT & ~(-1L << DATA_CENTER_ID_BITS);}/*** 根据Snowflake的ID,获取生成时间** @param id snowflake算法生成的id* @return 生成的时间*/public long getGenerateDateTime(long id) {return (id >> TIMESTAMP_LEFT_SHIFT & ~(-1L << 41L)) + twepoch;}/*** 下一个ID** @return ID*/@Overridepublic synchronized long nextId() {long timestamp = genTime();if (timestamp < this.lastTimestamp) {if (this.lastTimestamp - timestamp < timeOffset) {// 容忍指定的回拨,避免NTP校时造成的异常timestamp = lastTimestamp;} else {// 如果服务器时间有问题(时钟后退) 报错。throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));}}if (timestamp == this.lastTimestamp) {final long sequence = (this.sequence + 1) & SEQUENCE_MASK;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}this.sequence = sequence;} else {// issue#I51EJYif (randomSequenceLimit > 1) {sequence = RandomUtil.randomLong(randomSequenceLimit);} else {sequence = 0L;}}lastTimestamp = timestamp;return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT) | (dataCenterId << DATA_CENTER_ID_SHIFT) | (workerId << WORKER_ID_SHIFT) | sequence;}/*** 下一个ID(字符串形式)** @return ID 字符串形式*/@Overridepublic String nextIdStr() {return Long.toString(nextId());}// ------------------------------------------------------------------------------------------------------------------------------------ Private method start/*** 循环等待下一个时间** @param lastTimestamp 上次记录的时间* @return 下一个时间*/private long tilNextMillis(long lastTimestamp) {long timestamp = genTime();// 循环直到操作系统时间戳变化while (timestamp == lastTimestamp) {timestamp = genTime();}if (timestamp < lastTimestamp) {// 如果发现新的时间戳比上次记录的时间戳数值小,说明操作系统时间发生了倒退,报错throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));}return timestamp;}/*** 生成时间戳** @return 时间戳*/private long genTime() {return this.useSystemClock ? SystemClock.now() : System.currentTimeMillis();}/*** 解析雪花算法生成的 ID 为对象** @param snowflakeId 雪花算法 ID* @return*/public SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {SnowflakeIdInfo snowflakeIdInfo = SnowflakeIdInfo.builder().sequence((int) (snowflakeId & ~(-1L << SEQUENCE_BITS))).workerId((int) ((snowflakeId >> WORKER_ID_SHIFT)& ~(-1L << WORKER_ID_BITS))).dataCenterId((int) ((snowflakeId >> DATA_CENTER_ID_SHIFT)& ~(-1L << DATA_CENTER_ID_BITS))).timestamp((snowflakeId >> TIMESTAMP_LEFT_SHIFT) + twepoch).build();return snowflakeIdInfo;}
}
配置类
根据项目是否配置Redis进而判断选择注入LocalRedisWorkIdChoose还是RandomWorkIdChoose。若项目有Redis,则注入LocalRedisWorkIdChoose,反之,注入RandomWorkIdChoose
package com.dam.config;import com.dam.ApplicationContextHolder;
import com.dam.core.snowflake.LocalRedisWorkIdChoose;
import com.dam.core.snowflake.RandomWorkIdChoose;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;/*** 分布式 ID 自动装配**/
@Import(ApplicationContextHolder.class)
@Configuration
public class DistributedIdAutoConfiguration {/*** 本地 Redis 构建雪花 WorkId 选择器*/@Beanpublic LocalRedisWorkIdChoose redisWorkIdChoose() {return new LocalRedisWorkIdChoose();}/*** 随机数构建雪花 WorkId 选择器。如果项目未使用 Redis,使用该选择器*/@Bean@ConditionalOnMissingBean(LocalRedisWorkIdChoose.class)public RandomWorkIdChoose randomWorkIdChoose() {return new RandomWorkIdChoose();}
}雪花算法工具类
注意,SNOWFLAKE是一个静态变量,在AbstractWorkIdChooseTemplate抽象类的chooseAndInit方法中被初始化
package com.dam.toolkit;import com.dam.core.snowflake.Snowflake;
import com.dam.core.snowflake.entity.SnowflakeIdInfo;/*** 分布式雪花 ID 生成器**/
public final class SnowflakeIdUtil {/*** 雪花算法对象*/private static Snowflake SNOWFLAKE;/*** 初始化雪花算法*/public static void initSnowflake(Snowflake snowflake) {SnowflakeIdUtil.SNOWFLAKE = snowflake;}/*** 获取雪花算法实例*/public static Snowflake getInstance() {return SNOWFLAKE;}/*** 获取雪花算法下一个 ID*/public static long nextId() {return SNOWFLAKE.nextId();}/*** 获取雪花算法下一个字符串类型 ID*/public static String nextIdStr() {return Long.toString(nextId());}/*** 解析雪花算法生成的 ID 为对象*/public static SnowflakeIdInfo parseSnowflakeId(String snowflakeId) {return SNOWFLAKE.parseSnowflakeId(Long.parseLong(snowflakeId));}/*** 解析雪花算法生成的 ID 为对象*/public static SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {return SNOWFLAKE.parseSnowflakeId(snowflakeId);}}说明
本文代码来源于马哥 12306 的代码,本人只是根据自己的理解进行少量修改并应用到智能排班系统中。代码仓库为12306,该项目含金量较高,有兴趣的朋友们建议去学习一下。