1.8.4 卷积神经网络近年来在结构设计上的主要发展和变迁——Inception-v2 和Inception-v3
前情回顾:
1.8.1 卷积神经网络近年来在结构设计上的主要发展和变迁——AlexNet
1.8.2 卷积神经网络近年来在结构设计上的主要发展和变迁——VGGNet
1.8.3 卷积神经网络近年来在结构设计上的主要发展和变迁——GoogleNet/inception-v1
lnception-v2/v3 是在同一篇论文里提出的。
论文:Rethinking the inception architecture for computer vision
提出了4点关于网络结构设计的准则。
- 避免表达瓶颈(representational bottleneck),尤其是在网络的前几层。具体来说,将整个网络看作由输入到输出的信息流,我们需要尽量让网络从前到后各个层的信息表征能力逐渐降低,而不能突然剧烈下降或是在中间某些节点出现瓶颈。
- 特征图通道越多,能表达的解耦信息就越多,从而更容易进行局部处理,最终加速网络的训练过程。
- 如果要在特征图上做空间域的聚合操作(如3×3卷积),可以在此之前先对特征图的通道进行压缩,这通常不会导致表达能力的损失。
- 在限定总计算量的情况下,网络结构在深度和宽度上需要平衡。
文中采用了与VGGNet类似的卷积分解的思路,将5×5卷积核分解为两个3×3卷积核,
或者更一般地,将 (2k+1)(2k+1) 卷积核分解为k个3×3卷积核。
此外,文中还提出了另一种卷积分解思路:将k×k卷积分解为1×k卷积与k×1卷积的串联;
当然也可以进一步将1×k卷积和k×1卷积的组织方式由串联改成并联。
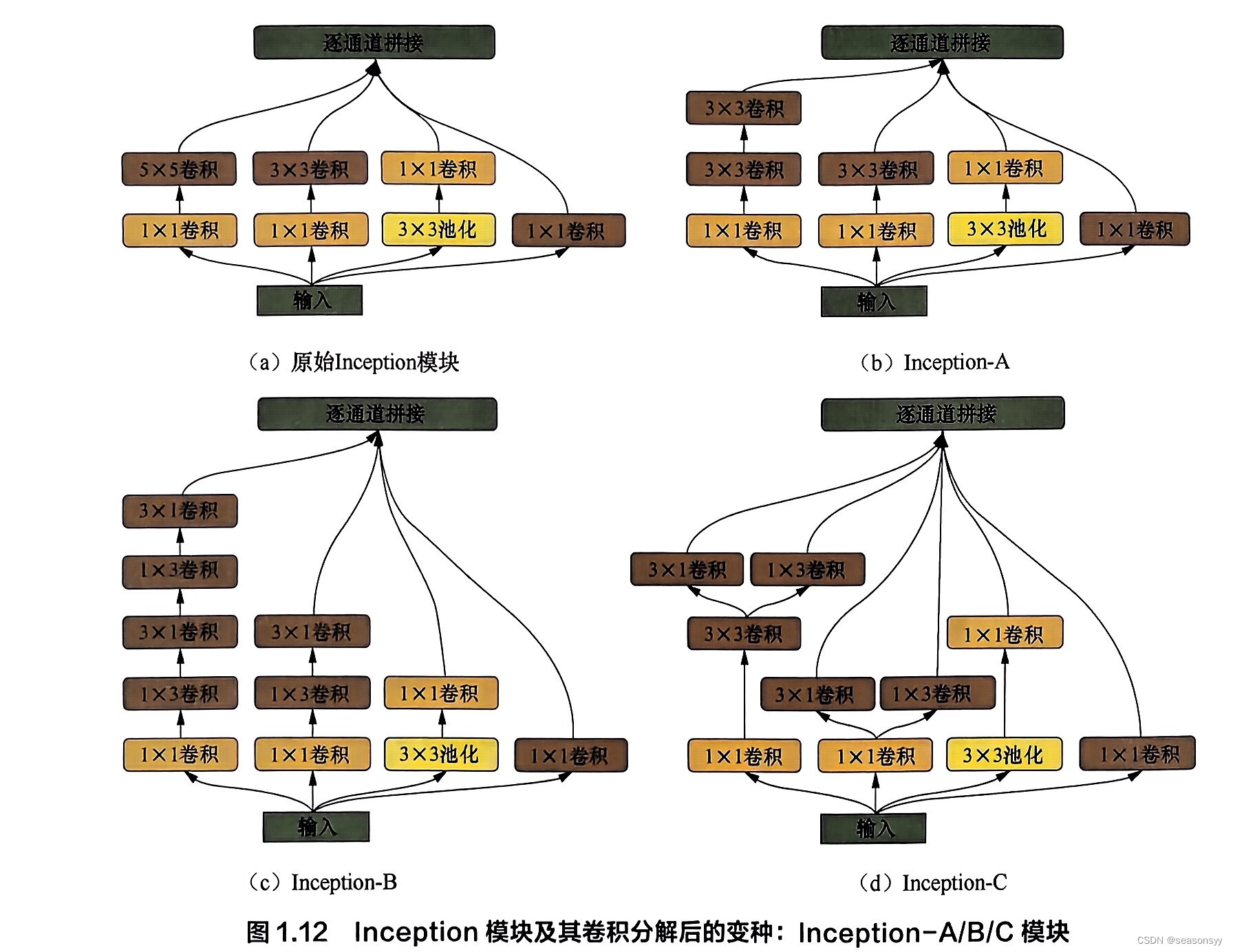
图1.12展示了各版本Inception模块的结构示意图,
-
图1.12(a)是Inception-v1中使用的原始Inception模块;
-
图1.12(b)、图1.12©、图1.12(d)是Inception-v2/v3中使用的、经过卷积分解的Inception模块,
- 图1.12(b):Inception-A(将大卷积核分解为小卷积核)
- 图1.12©:Inception-B(串联1×k和k×1卷积)
- 图1.12(d):Inception-C(并联1×k和k×1卷积)
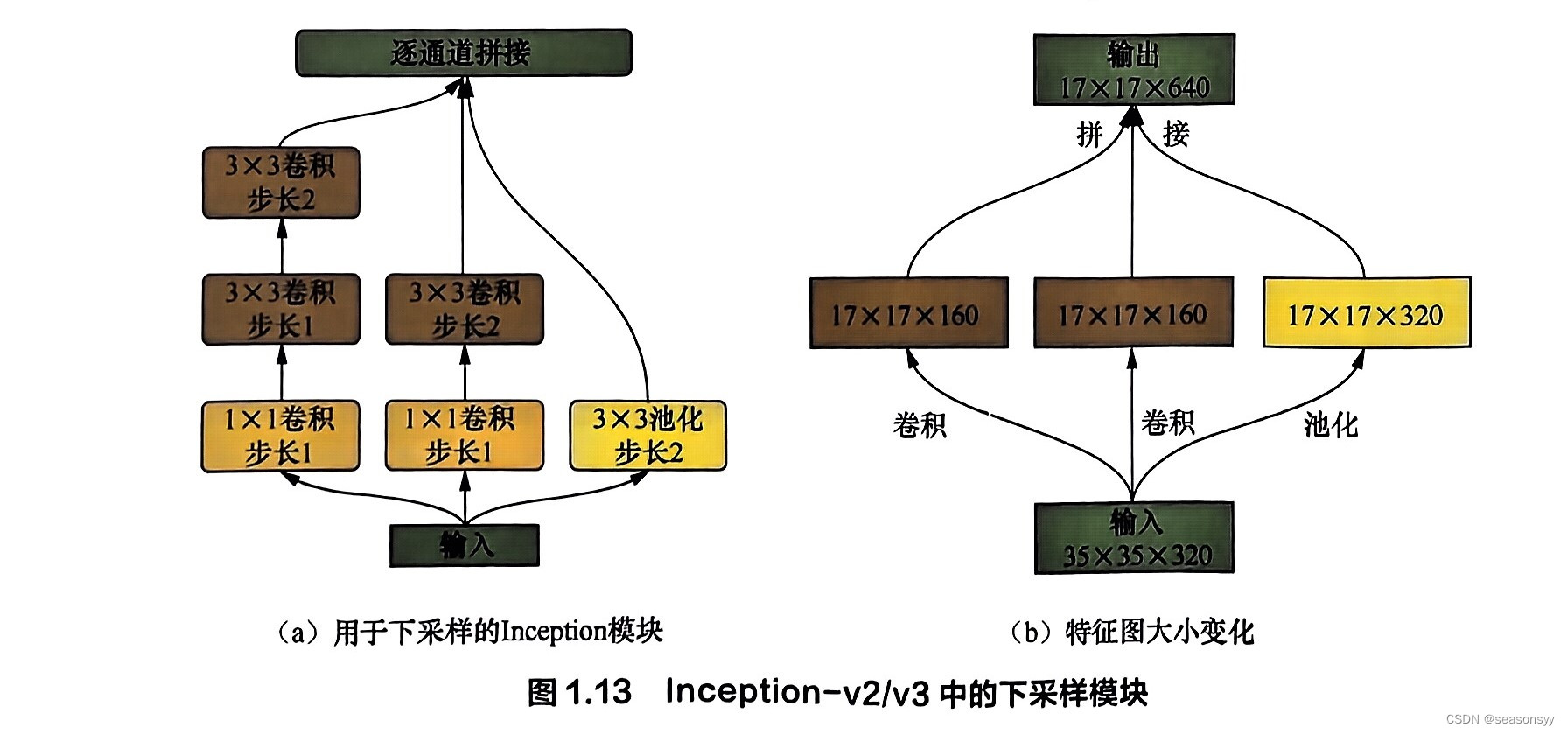
为了缓解单纯使用池化层进行下采样带来的表达瓶颈问题,文中还提出了一种下采样模块:在原始Inception模块的基础上略微修改,并将每条支路最后一层的步长改为2,如图1.13所示。
此外,论文中尝试给从网络中间层拉出的辅助分类器的全连接层加上批归一化和Dropout,实验表明这能**提升最终的分类效果。**同时,文中还将输入图片尺寸由 224×224 扩大为 299×299 。
最终,Inception-v3在ImageNet 2012数据集的图像分类任务上,单模型能使Top-5错误率降到4.20%;如果采用标签平滑、多模型集成等辅助训练措施,则能进一步将错误率降至3.50%,具体参见该论文中的讨论。
Inception-v2 与Inception-v3 的具体区别?
有人认为 Inception-v2是Inception-v3在不使用辅助训练措施下的版本
也有人根据Google的示例代码认为Inception-v2仅为Inception-v1加上批归一化并使用Inception-A模块的简单改进版本,这里我们不再具体细分。
参考文献:
《百面深度学习》 诸葛越 江云胜主编
出版社:人民邮电出版社(北京)
ISBN:978-7-115-53097-4
2020年7月第1版(2020年7月北京第二次印刷)
推荐阅读:
//好用小工具↓
分享一个免费的chat工具
分享一个好用的读论文的网站
// 深度学习经典网络↓
LeNet网络(1989年提出,1998年改进)
AlexNet网络(2012年提出)
VGGNet网络(2014年提出)
LeNet、AlexNet、VGGNet总结
GoogLeNet网络(2014年提出)
ResNet网络(2015年提出)