锁竞争:互斥锁 、条件变量 、原子变量、信号量、读写锁、自旋锁。 在高性能基础组件优化的时候,为了进一步提高并发性能,可以使用原子变量。 性能:原子变量 > 自旋锁 > 互斥锁 。 操作临界资源的时间较长时使用互斥锁(粒度大) 。 如果只操作单个变量的话,可以使用原子变量(粒度小) 进行优化。 给基础类型或者指针加上一个标记 std::atomic<T> 之后 ,它就是原子变量 ,对这些变量的操作就是原子操作 。原子变量是一种多线程编程中常用的同步机制,它能确保对共享变量的操作在执行时不会被其它线程的操作干扰,从而避免竞态条件。 原子变量具备原子性,也就是要么全部完成,要么全部未完成。 为什么会使用到原子变量 ? 通常某一个变量对应的操作,其 CPU 的指令是大于 1 个指令的,在多线程环境下,可能会引发竞态,在这种线程不安全的情况下,我们需要为这个变量单独设置一个锁安全的标记 std::atomic<T> ,从而实现线程安全 。 多线程环境下,确保对共享变量 的操作在执行时不会被干扰,从而避免竞态条件。 std:: atomic< T>
is_lock_free;
store ( T desired, std:: memory_order order) ;
load ( std:: memory_order order) ;
exchange ( std:: atomic< T> * obj, T desired) ;
compare_exchange_weak ( T& expected, T val, memory_order success, memory_order failure) ;
compare_exchange_strong ( ( T& expected, T val, memory_order success, memory_order failure) ; fetch_add
fetch_sub
fetch_and
fetch_or
fetch_xor
要么都做要么还没做,不会让其它核心看到执行的一个中间状态 。单处理器单核心实现原子性: 只需要保证操作指令不被打断。 屏蔽中断 → 不允许操作指令被打断,不让其它线程看到操作指令的中间状态 。底层硬件自旋锁 → 为了实现线程切换。 多处理器或多核心实现原子性: 除了要保证操作指令不被打断 ,还需要避免其它核心操作相关的内存空间 。 以往的 0x86 lock 指令,锁总线 ,避免所有内存的访问 。 现在的 lock 指令,锁总线 ,只阻止其它核心对相关内存空间的访问,也就是只锁住相关内存空间 。 内存总线:CPU 需要通过内存总线访问内存。 磁盘总线:CPU 需要通过磁盘总线访问磁盘。 存储体系结构
在 CPU 缓存的基础上,CPU 如何读写数据 ? 注意:CPU 缓存中的数据永远比内存中的数据要新 写直达策略 每次写操作既会写到 CPU 缓存中,也会写到内存中,写性能会很低。 写回策略(write-back) (现代 CPU 使用的策略) 尽量避免每次写数据都把数据写到内存中 。写操作 先检查是否命中 CPU 缓存,如果命中了就直接写,并标记为脏数据(CPU 缓存中的数据和内存中的数据不一致) 。 如果没有命中,就需要在 CPU 缓存中找一块区域来存储新数据,也就是定位缓存块 。 如果有可用的缓存块(还没有存储其它数据的缓存块) 就直接使用。 如果没有可用的缓存块了,则采用 LRU 策略去定位缓存块 。 该缓存块存储的数据是脏数据,先把这个缓存块中的数据刷到内存中,然后用这个缓存块去存储新数据,并标记为脏数据 。该缓存块存储的数据不是脏数据,直接将新数据写入到这个缓存块中,并标记为脏数据 。 读操作 先检查是否命中 CPU 缓存,如果命中了就直接返回。 如果没有命中,从内存中读取数据并返回,然后定位缓存块去存储该数据。 如果有可用的缓存块就直接使用。 如果没有可用的缓存块了,则采用 LRU 策略去定位缓存块。 该缓存块存储的数据是脏数据,先把这个缓存块中的数据刷到内存中,然后用这个缓存块去存储刚刚从内存中读取的数据,并标记为非脏数据 。该缓存块存储的数据不是脏数据,直接将刚刚从内存中读取的数据写入到这个缓存块中,并标记为非脏数据 。 为什么会有缓存一致性问题 ? CPU 是多核心的。 基于写回策略将会出现缓存不一致的问题。 数据在核心 0 的 CPU 缓存中,但是还没写到内存中;核心 2 的 CPU 缓存中没有该数据,于是会从内存中读取该数据,但是核心 2 从内存中读到的数据与核心 0 的 CPU 缓存中的数据不一致。 如何解决缓存不一致的问题 ? 写传播:总线嗅探(bus snooping) 监听发布者模式:每一个核心都会监听总线上的写事件,当某个核心写数据的时候,会基于总线进行广播,其它的核心读到了这个事件之后,会自动修改自己的数据。 事务的串行化:锁 + lock 指令 。 多个核心对同一个缓存块进行读写操作的时候,必须要串行执行,否则会带来不确定性。 core0 写 i = 10,锁总线,必须等 i = 10 写操作结束后,core1 才能写 i = 20,这样 core2 读到的 i 就一定等于 20。
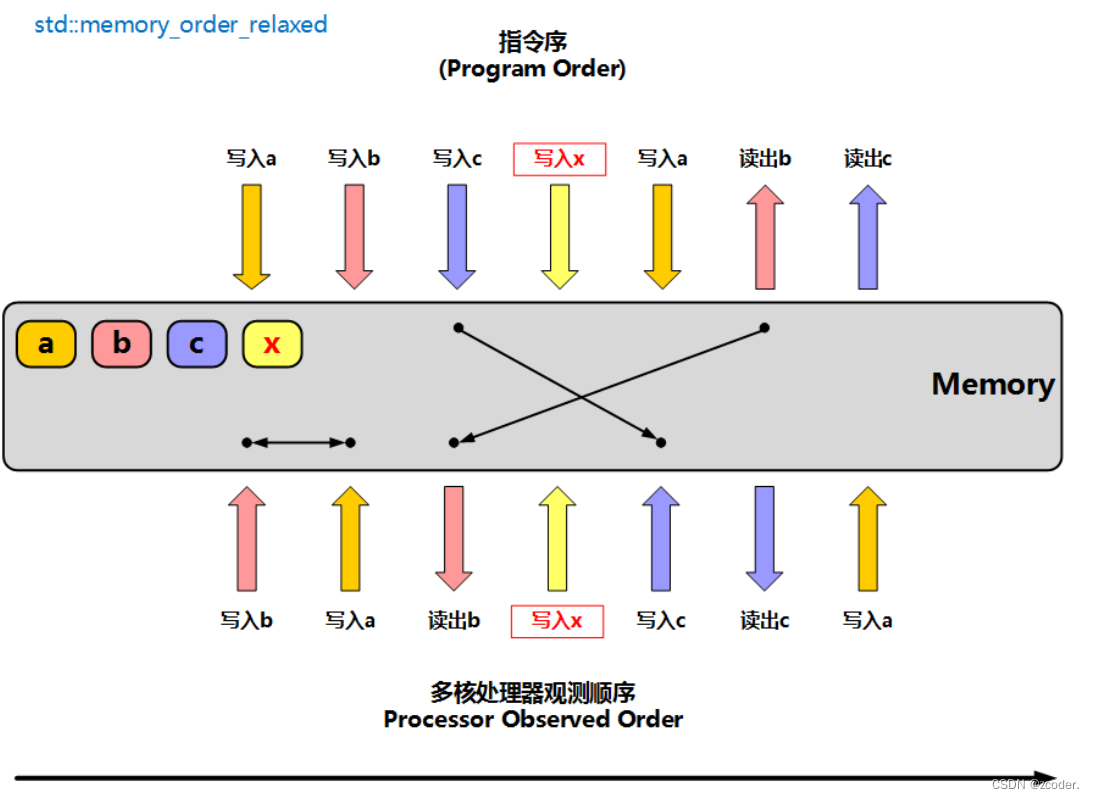
优化:尽量减小写传播给总线带来的带宽压力 。 两个策略: 写传播:如何减少无效的监听,减小总线带宽的压力。 串行化机制:如何锁总线。 MESI 一致性协议 基于总线嗅探机制实现了事务串行化,通过状态机降低总线带宽的压力 。4 个状态 Modified:已修改,某个数据块已修改但是没有同步到内存中。 Exclusive:独占,某个数据块只在某核心的缓存中,并且此时缓存和内存中的数据是一致的。 Shared:共享,某个数据块在多个核心的缓存中,并且此时缓存和内存中的数据是一致的。 Invalidated:已失效,某个数据块在核心中已失效,不是最新的数据。 core0 中的数据:i = 5,core1 中的数据:i = 5,内存中的数据:i = 5;当 core0 写 i = 10 时,会通过总线嗅探,将 core1 中的数据 i = 5 的状态修改为 Invalidated。 锁住 M 和 E 状态(因为 M 和 E 状态是不需要广播的),避免相关内存的访问 。原子性还没有解决避免竞态条件的问题 。为什么会有内存序问题 内存序规定了什么 规定了多个线程访问同一个内存地址时的语义 。 同步性 :某个线程对内存地址的更新何时能被其它线程看见 。顺序性 :某个线程对内存地址访问附近可以做怎么样的优化 。 内存模型 这里所指的内存模型对应缓存一致性模型,作用是对同一时间的读写操作进行排序,在不同的 CPU 架构上,这些模型的具体实现方式可能不同,但是 C++ 11 屏蔽了内部细节,不用考虑内存屏障。可能有时使用的模型粒度比较大,会损耗性能,当然还是使用各平台底层的内存屏障粒度更准确,效率也会更高。 memory_order_relaxed:松散内存序。 只用来保证对原子对象的操作是原子的,在不需要保证顺序时使用。 读操作和写操作都可以使用。 效率最高。
s. load ( std:: memory_order_relaxed) ;
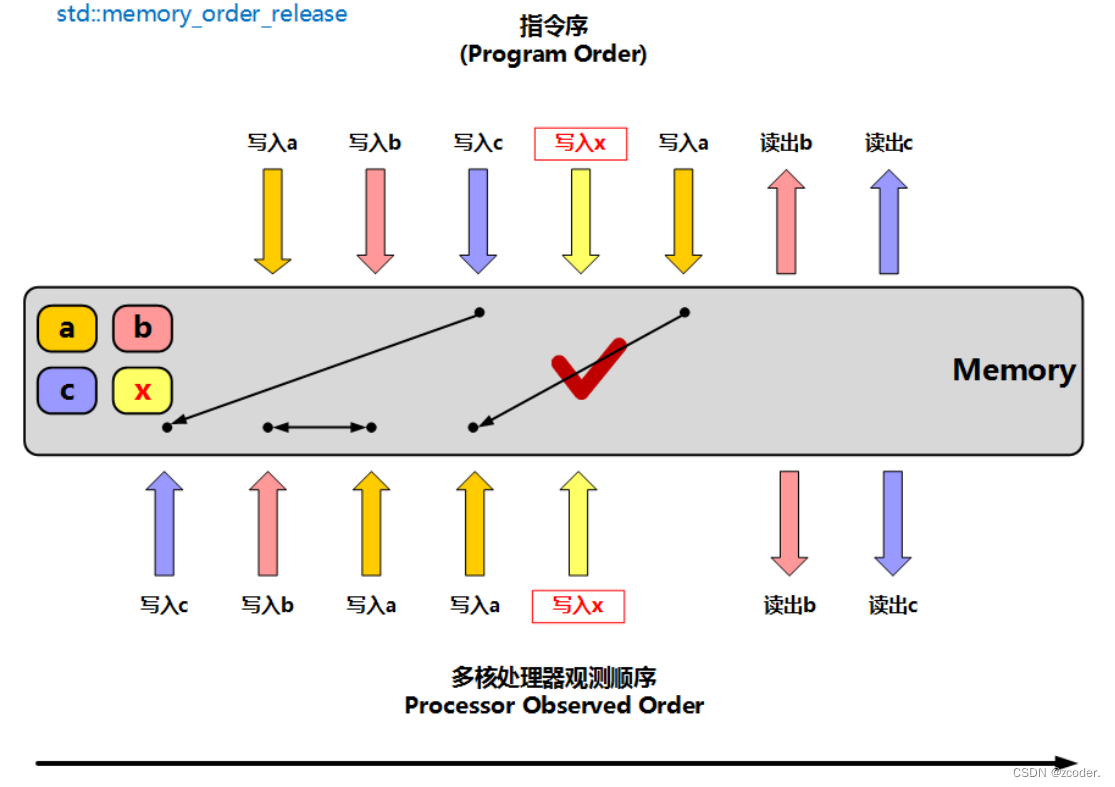
memory_order_release:释放操作。 在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去 ,并且保证其它线程可以读取到该原子对象的最新值 。 通常与 memory_order_acquire 配对使用。 只能在写操作中使用。 依据前面的才写入 。
s. store ( 10 , std:: memory_order_release) ;
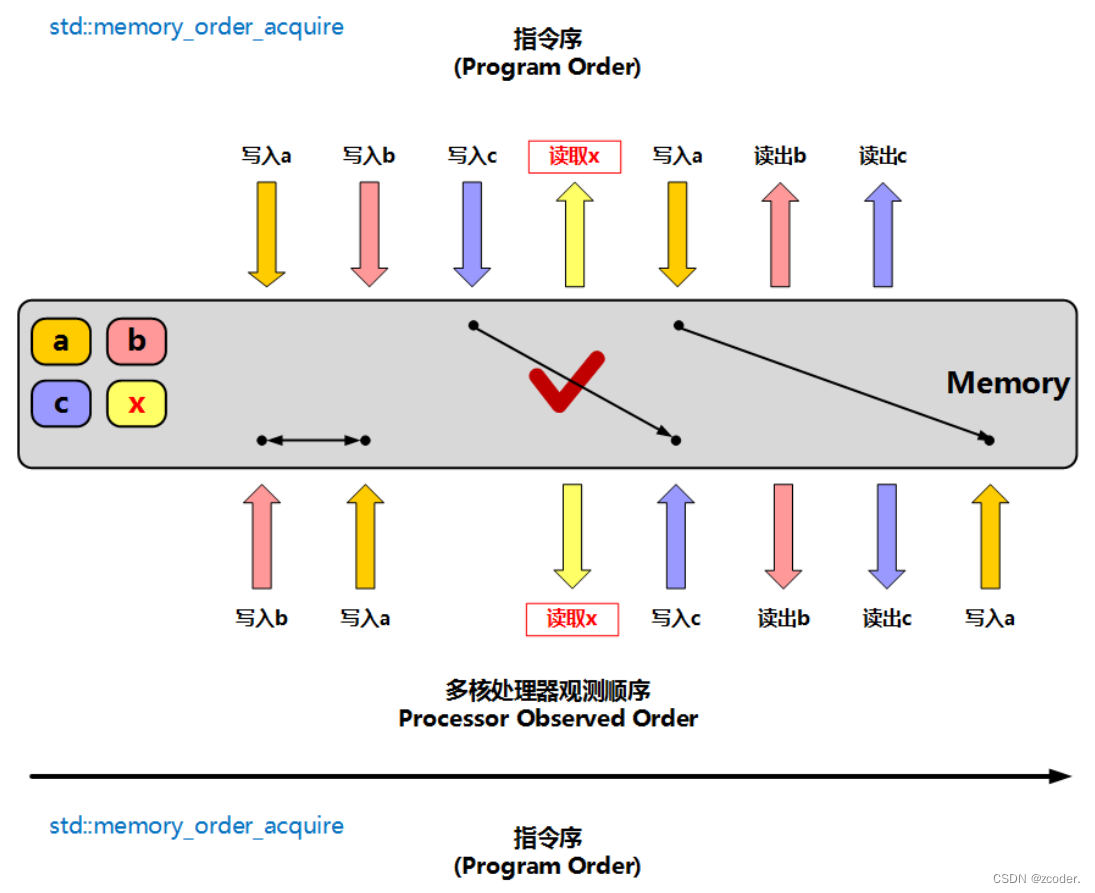
memory_order_acquire:获取操作。 在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去 ,并且保证当前线程可以读取到该原子对象的最新值 。 只能在读操作中使用。 后面的依据读取的 。
s. load ( std:: memory_order_acquire) ;
memory_order_acq_rel:获得释放操作。 一个读 — 修改 — 写 操作,同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且保证其它线程可以读取到该原子对象的最新值、当前线程可以读取到该原子对象的最新值。 memory_order_seq_cst:顺序一致性语义。 对于读操作相当于获得,对于写操作相当于释放,对于读 — 修改 — 写操作相当于获得释放。 是所有原子操作的默认内存序 ,并且会对所有使用此模型的原子操作建立一个全局顺序 ,保证了多个原子变量 的操作在所有线程里观察到的操作顺序相同。效率最低。 # include <atomic> # include <thread> # include <assert.h> # include <iostream> :: atomic< bool > x, y;
std:: atomic< int > z; void write_x_then_y ( )
{ x. store ( true , std:: memory_order_relaxed) ; y. store ( true , std:: memory_order_relaxed) ;
} void read_y_then_x ( )
{ while ( ! y. load ( std:: memory_order_relaxed) ) ; if ( x. load ( std:: memory_order_relaxed) ) ++ z;
}
int main ( )
{ for ( int i = 0 ; i < 100000 ; i++ ) { x = false ; y = false ; z = 0 ; std:: thread b ( read_y_then_x) ; std:: thread a ( write_x_then_y) ; b. join ( ) ; a. join ( ) ; int v = z. load ( std:: memory_order_relaxed) ; if ( v != 1 ) std:: cout << v << std:: endl; } return 0 ;
}
# include <atomic> # include <thread> # include <assert.h> # include <iostream> :: atomic< bool > x, y;
std:: atomic< int > z; void write_x_then_y ( )
{ x. store ( true , std:: memory_order_relaxed) ; y. store ( true , std:: memory_order_release) ;
} void read_y_then_x ( )
{ while ( ! y. load ( std:: memory_order_acquire) ) ; if ( x. load ( std:: memory_order_relaxed) ) ++ z;
}
int main ( )
{ x = false ; y = false ; z = 0 ; std:: thread a ( write_x_then_y) ; std:: thread b ( read_y_then_x) ; a. join ( ) ; b. join ( ) ; std:: cout << z. load ( std:: memory_order_relaxed) << std:: endl; return 0 ;
}
如何实现互斥锁: 互斥锁首先需要做一个内存标记 ,记录的是线程 ID ,因为互斥锁需要进行线程切换。 互斥锁是为了保护临界资源,同时只允许一个线程去访问临界资源,所以会有一个阻塞队列,通过阻塞队列唤醒其它线程去访问临界资源。 要屏蔽中断。 底层硬件自旋锁。 互斥锁的表现: 先在用户态自旋一会儿。 获取失败,把任务挂起(放到阻塞队列中),核心会切换其它线程去执行。 休眠一段时间再次尝试获取锁。