0x00 博主pth转化onnx时
import torch
from basicsr.models import create_model
from basicsr.train import parse_options
from basicsr.utils import FileClient, imfrombytes, img2tensor, padding, tensor2img, imwrite
import osdef pth_to_onnx(input, onnx_path, input_names=['input'], output_names=['output']):if not onnx_path.endswith('.onnx'):print('Warning! The onnx model name is not correct,\please give a name that ends with \'.onnx\'!')return 0opt = parse_options(is_train=False)opt['dist'] = Falsemodel = create_model(opt)model.net_g.cuda()model.net_g.eval()with torch.no_grad():torch.onnx.export(model.net_g, input, onnx_path, opset_version=11, verbose=False,input_names=input_names, output_names=output_names, do_constant_folding=True)# torch.onnx.export(model.net_g, input, onnx_path,opset_version=13, verbose=True,# input_names=input_names, output_names=output_names,operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK)if __name__ == '__main__':device = torch.device('cuda')onnx_path = './naf16net11_div.onnx'# input = torch.randn(1, 3, 480, 640, device="cuda")image_path = "left_194.jpg"file_client = FileClient('disk')img_bytes = file_client.get(image_path, None)try:img = imfrombytes(img_bytes, float32=True)except:raise Exception("path {} not working".format(image_path))img = img2tensor(img, bgr2rgb=True, float32=True)input = img.unsqueeze(dim=0).to(device)pth_to_onnx(input, onnx_path)
当时出现了未定义的算子问题,查看代码发现是自定义了函数:class LayerNormFunction(torch.autograd.Function):函数

根据LayerNormFunction函数的forward函数编写了symbolic函数
具体代码如下:
class LayerNormFunction(torch.autograd.Function):@staticmethoddef symbolic(g, x, weight, bias, eps):# because forward function return 1 outputs, so this func also have to return 1 outputs# this is my expriment result, I didn't find any docs# Calculate y = (x - mu) / sqrt(var + eps)x_minus_mu = g.op("Sub", x, g.op("ReduceMean", x, axes_i=[1]))var = g.op("ReduceMean", g.op("Mul", x_minus_mu, x_minus_mu), axes_i=[1])sqrt_var_plus_eps = g.op("Add", var, g.op("Constant", value_t=torch.tensor(1e-6, dtype=torch.float)))rsqrt_var_plus_eps = g.op("Sqrt", sqrt_var_plus_eps)y = g.op("Div", x_minus_mu, rsqrt_var_plus_eps)weight = g.op("Unsqueeze", weight, axes_i=[0, 2, 3]) # Expand weight to match y's shape# weight = g.op("Unsqueeze", weight, g.op("Constant", value_t=torch.tensor([0, 2, 3], dtype=torch.long)))y = g.op("Mul", y, weight)bias = g.op("Unsqueeze", bias, axes_i=[0, 2, 3]) # Expand bias to match y's shape# bias = g.op("Unsqueeze", bias, g.op("Constant", value_t=torch.tensor([0, 2, 3], dtype=torch.long))) # Expand bias to match y's shapey = g.op("Add", y, bias)return y@staticmethoddef forward(ctx, x, weight, bias, eps=1e-6):ctx.eps = epsN, C, H, W = x.size()mu = x.mean(1, keepdim=True)var = (x - mu).pow(2).mean(1, keepdim=True)y = (x - mu) / (var + eps).sqrt()ctx.save_for_backward(y, var, weight)y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)return y@staticmethoddef backward(ctx, grad_output):eps = ctx.epsN, C, H, W = grad_output.size()y, var, weight = ctx.saved_variablesg = grad_output * weight.view(1, C, 1, 1)mean_g = g.mean(dim=1, keepdim=True)mean_gy = (g * y).mean(dim=1, keepdim=True)gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(dim=0), None
下面的symbolic函数可以通过chartgpt提交forward函数辅助编写symbolic。
@staticmethod
def symbolic(g, x, weight, bias, eps):# because forward function return 1 outputs, so this func also have to return 1 outputs# this is my expriment result, I didn't find any docs# Calculate y = (x - mu) / sqrt(var + eps)x_minus_mu = g.op("Sub", x, g.op("ReduceMean", x, axes_i=[1]))var = g.op("ReduceMean", g.op("Mul", x_minus_mu, x_minus_mu), axes_i=[1])sqrt_var_plus_eps = g.op("Add", var, g.op("Constant", value_t=torch.tensor(1e-6, dtype=torch.float)))rsqrt_var_plus_eps = g.op("Sqrt", sqrt_var_plus_eps)y = g.op("Div", x_minus_mu, rsqrt_var_plus_eps)weight = g.op("Unsqueeze", weight, axes_i=[0, 2, 3]) # Expand weight to match y's shape# weight = g.op("Unsqueeze", weight, g.op("Constant", value_t=torch.tensor([0, 2, 3], dtype=torch.long)))y = g.op("Mul", y, weight)bias = g.op("Unsqueeze", bias, axes_i=[0, 2, 3]) # Expand bias to match y's shape# bias = g.op("Unsqueeze", bias, g.op("Constant", value_t=torch.tensor([0, 2, 3], dtype=torch.long))) # Expand bias to match y's shapey = g.op("Add", y, bias)return y
参考博客:
模型部署入门教程(四):在 PyTorch 中支持更多 ONNX 算子
pytorch模型转onnx格式,编写符号函数实现torch算子接口和onnx算子的映射,新建简单算子–模型部署记录整理

0x01 博主onnx转化为tensorrt时,使用了
trtexec --onnx=naf16net11_onnxsim.onnx --saveEngine=naf16net11_onnxsim.trt --fp16 --verbose
trtexec在NX板上有预装,windows上自己下载安装,目录D:\TensorRT-8.5.1.7\bin同样有 trtexec.exe,直接目录下运行指令就行。
NX板子中tensorrt如果想在conda环境下运行,因为NX板有预装,参考博客:Jetson NX实现TensorRT加速部署YOLOv8

从该处开始看。
遇到错误:
0. trtexec --onnx=naf16net11_onnxsim.onnx --saveEngine=naf16net11_onnxsim.trt --int8 --verbose
转为int8和fp16时,打印输出都为NAN,为了查找哪一层导致网络出现的NAN,使用了Polygraphy工具下载CLI或者API进行逐层的转化查找报错问题。
参考博客:
Polygraphy逐层对比onnx和tensorrt模型的输出
TensorRT部署YOLOv5出现精度问题的调查
使用指令:
polygraphy run naf16net11_onnxsim.onnx --onnxrt --onnx-outputs mark all --save-results=onnx_out.json
polygraphy run naf16net11_onnxsim.onnx --trt --trt-outputs mark all --save-results=trt_out.json --validate --fp16
polygraphy run naf16net11_onnxsim.onnx --trt --trt-outputs mark all --save-results=trt_out_8vv.json --validate --int8 -vv
--validate是为了检查每层的输出是否有Inf或者NAN
(0) 运行polygraphy run时尤其是–trt时转化为fp16和int8时报错Error loading “D:\ProgramData\Anaconda3\envs\yolov8\lib\site-packages\torch\lib\cudnn_cnn_infer64_8.dll” or one of its dependencies.
conda环境下下载了cudatoolkit、cudnn、pytorch,更换了好几个cudatoolkit和pytorch版本,依旧存在报错问题,博主尝试了将目录D:\ProgramData\Anaconda3\envs\yolov8\Library\bin下的
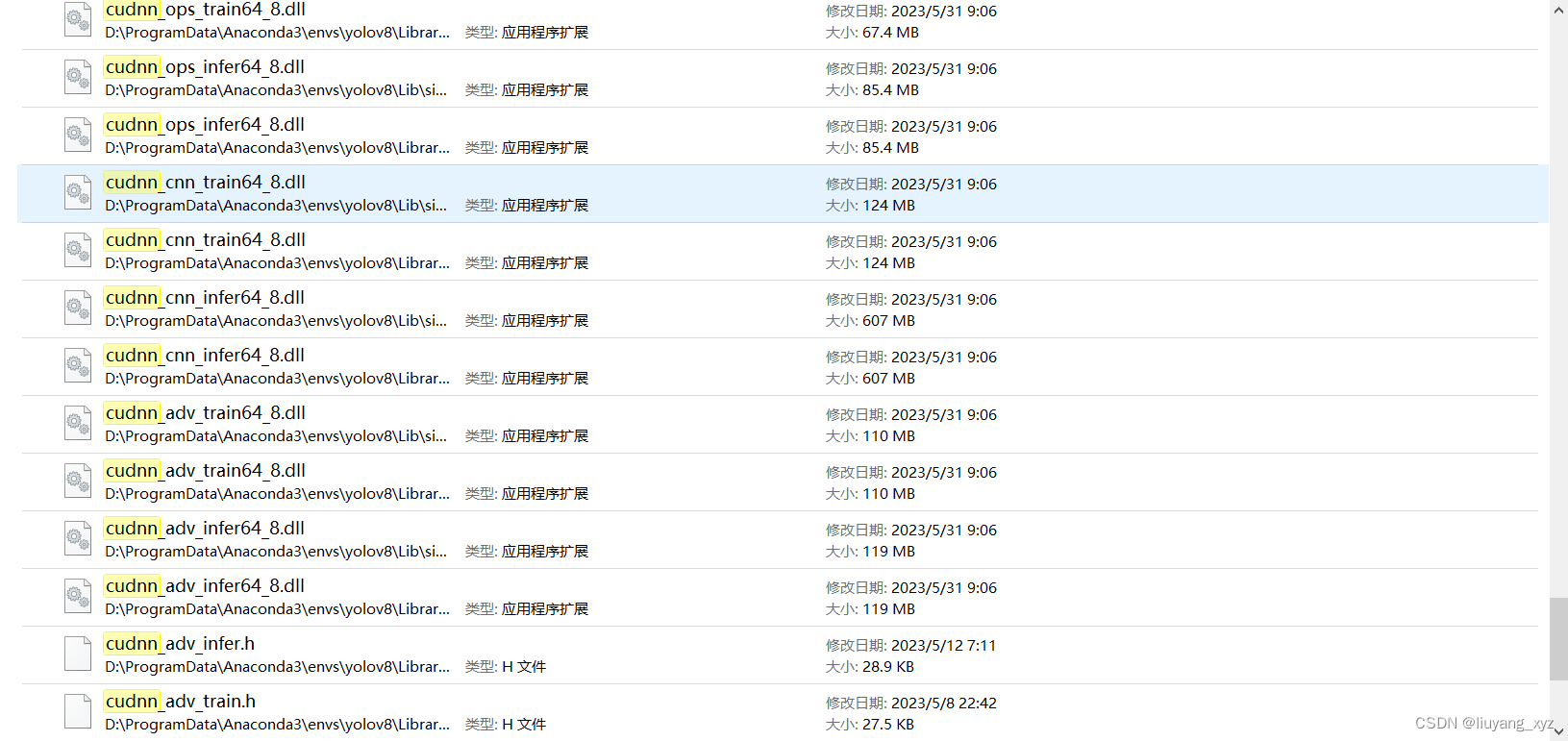
都粘贴到D:\ProgramData\Anaconda3\envs\yolov8\lib\site-packages\torch\lib\目录下,然后就不报错了,应该是安装的cudnn包需要替换torch下的对应包,切记先把orch下的对应包备份再覆盖。内网未找到解决方案其他解决方案。
(1)回归正题,通过polygraphy run naf16net11_onnxsim.onnx --trt --trt-outputs mark all --save-results=trt_out.json --validate --fp16的逐层打印,我们发现了对应层的问题:
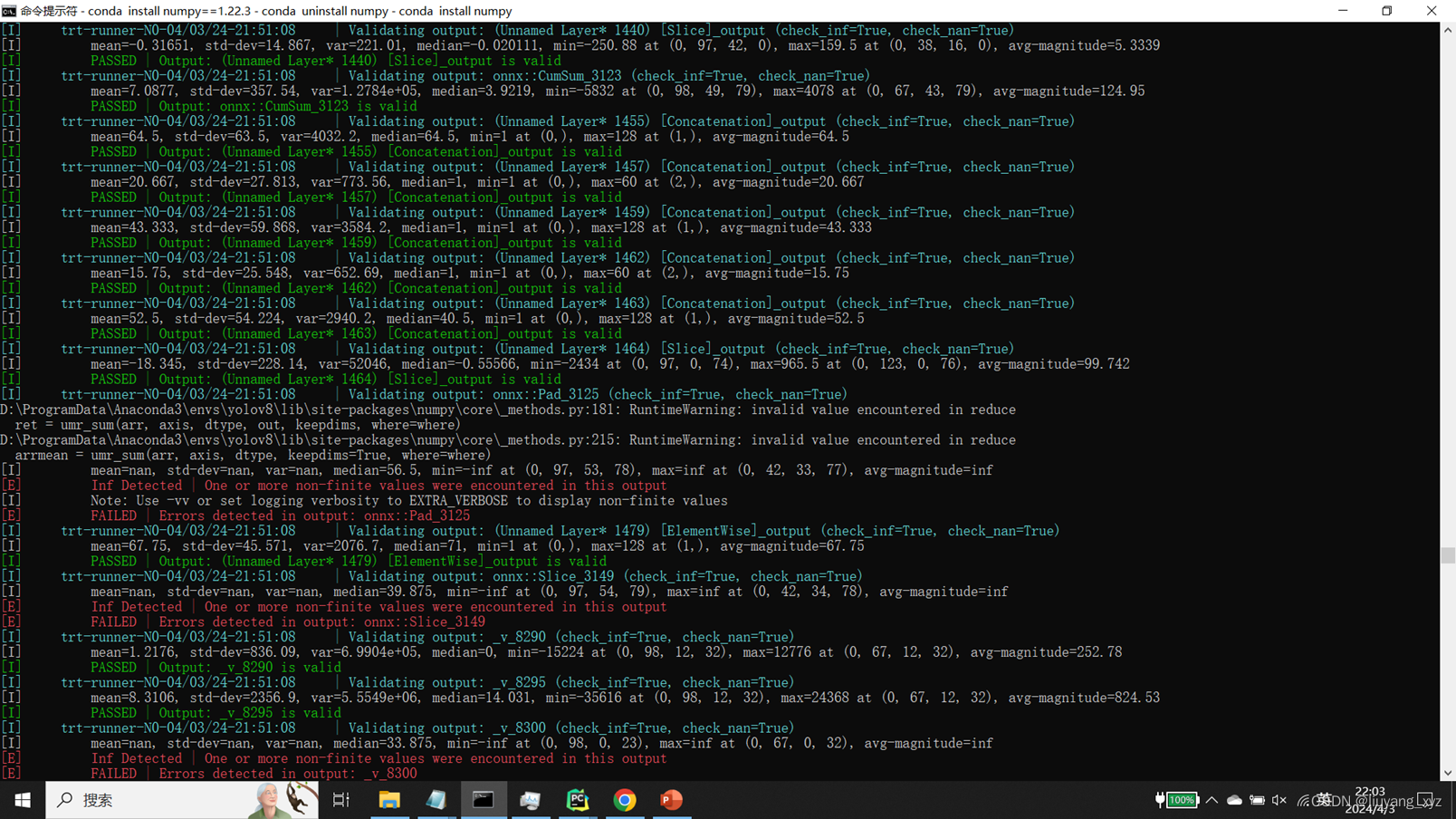
例如:

例如层:s.15存在问题,使用netron工具打开对应onnx,再结合源代码,考虑溢出问题,根据原代码进行修改,缩放和限制区间的方法:例如问题出现在s = x.cumsum(dim=-1).cumsum_(dim=-2)
self.fp16_div = 1e6
self.fp16_mul = 5e5
..........
n, c, h, w = x.shape
x = x/self.fp16_div # 缩放
x = torch.clamp(x, min=-100, max=100) # 限制值的空间
s = x.cumsum(dim=-1).cumsum_(dim=-2)
s = s*self.fp16_mul
参考博客:TensorRT debug及FP16浮点数溢出问题分析