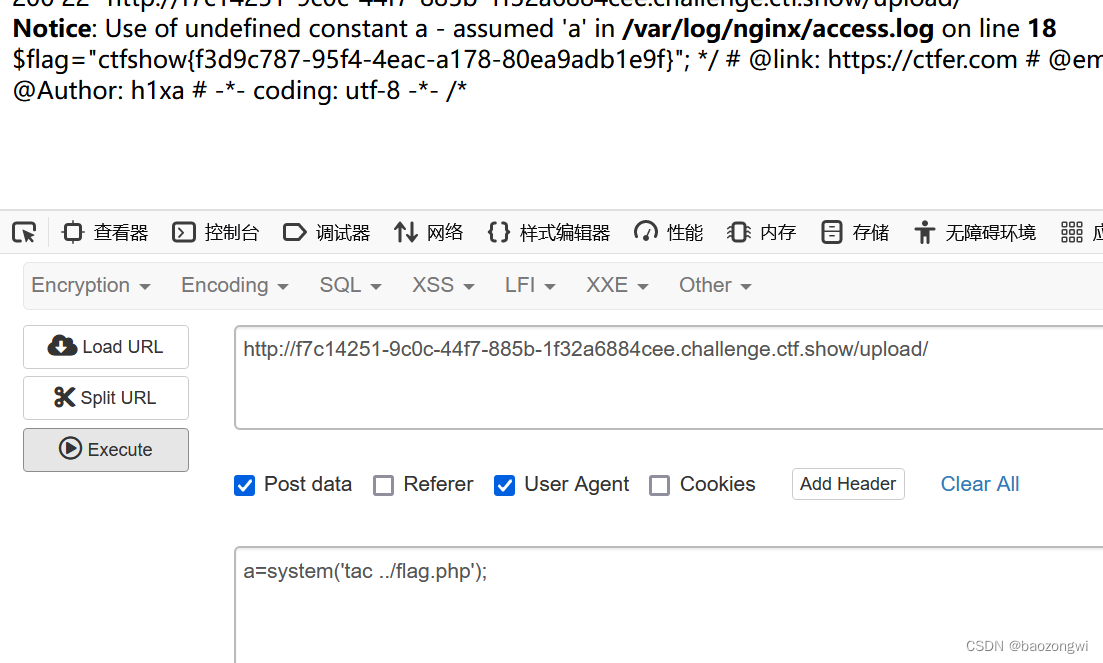
由于篇幅原因,本文分为上下两篇,上篇主要讲解上下文窗口的概念、在LLM中的重要性,下篇主要讲解长文本能否成为LLM的护城河、国外大厂对长文本的态度。
3、长文本是护城河吗?
毫无疑问,Kimi从一开始就用“长文本”占领了用户心智,它能否像去年的Claude 一样,凭借着上下文长度形成一条稳定的护城河?在去年,这个答案也许是肯定的,但进入2024年,这项技术本身已经很难说的上是护城河了。当下,已经有越来越多成熟的手段去处理上下文的问题。
上下文扩展的问题之所以这么难解决,主要原因还是Transformer这个基础框架本身。
它最核心的问题有三个:
1)对文本长度记忆非常死板,超过训练集最大长度就无法处理:Transformer为输入序列的每个token的位置都映射了一个固定长度的向量。这是一个绝对的位置信息,导致模型对文本长度的记忆非常死板。一旦你给了模型超出训练集最大长度的信息时,这些超出的位置他就定位不了,也就读取和理解不了。很可惜的是,根据Sevice Now的研究员Harm de Vries的技术博客分析,现在模型训练用的主要素材之一公开可用的互联网抓取数据集CommonCrawl中,95%以上的语料数据文件的token数少于2k,并且实际上其中绝大多数的区间在1k以下。也就是说,它在训练这个过程中就是很难拓展到2k以上的文本长度。
2)注意力机制占据资源,耗费算力:因为自注意力机制需要计算每个token与其他所有token之间的相对注意力权重,所以token越长,计算量就越大,耗时越长。而且算出来的结果,还要储存成注意力得分矩阵,大量矩阵会占据巨大的存储空间,快速存储能力不足也不行。而且大部分 token之间其实就没啥关系,非要这么来回算一遍纯粹浪费资源。
3)不擅长处理远端信息:深度学习的基本逻辑之一是梯度下降,它通过不断地调整模型参数来最小化与结果差异的损失函数,从而使模型的预测能力得到提高。另一个逻辑就是反向传播,将梯度传播到更高的神经网络层级中,从而使模型能识别更复杂的模式和特征。当序列较长时,梯度在反向传播过程中可能变得非常小(梯度消失)或非常大(梯度爆炸),这导致模型无法学习到长距离的依赖关系。而且注意力机制本身就倾向于近距离词汇,远距离依赖关系对它来说优先级不高。
这三大难题其实已经有非常多的手段去规避。学界把增加上下文的方法主要归类为外推(Extrapolation)和内插(Interpolation)。一般都会并行使用。
外推负责解决训练外资料无法编码的问题,并保证长文本处理的能力。用通俗的语言来解释我们有一个巨大的语言模型,就像一个超级大脑,它通过阅读大量的书籍和文章来学习理解人类的语言和知识。但是,如果给它一段新的长文本,它可能会遇到一些之前没有接触过的内容,这时候它就需要一种特殊的能力来理解这些新信息。这种能力就是所谓的“外推”。
为了让这个语言模型能够处理超长的文章,我们需要给它一种特殊的编码方式,就像给这个超级大脑安装了一副可以看得更远的眼镜。这副眼镜就是“位置编码”,比如ALiBi和RoPE这样的编码方式,它们帮助语言模型理解更长的文本。
但是,长文本不仅长,还很复杂,需要语言模型快速而且准确地理解。为了解决这个问题,我们发明了一种叫做“稀疏注意力”的技术,它就像是给这个超级大脑装了一个高效的信息处理系统,让它可以快速聚焦在重要的信息上,而不是被无关的细节分散注意力。
还有一个问题,就是语言模型的“记忆”问题。就像电脑如果开太多程序会卡顿一样,语言模型处理太多信息也会遇到问题。这时候,我们有了像Transformer-XL这样的技术,它就像是给语言模型加了一个超级大的内存,让它可以记住更多的东西。而环注意力(Ring Attention)这个新技术,就像是给语言模型的大脑做了一个升级,让它在处理信息的时候更加高效,不会忘记重要的事情。
除了处理长文本,我们还需要让语言模型能够更好地理解它已经学过的内容,这就是“内插”。我们通过调整它的注意力机制,让它可以更轻松地找到信息之间的联系,就像是给这个超级大脑装了一个更聪明的搜索系统。
通过这些技术的提升,我们的语言模型变得越来越强大,虽然还不是完美无缺,但已经能够处理很多复杂的问题了。最近,微软的研究人员还发明了一种新的方法,叫做LongRoPE,它就像是给这个超级大脑的超能力做了一个升级,让它可以处理更多的信息,而且不需要重新训练或者更多的硬件支持。
本身这个方法略微复杂,会使用到1000步微调,但效果绝对值得这么大费周章。直接连重新训练和额外的硬件支持都不需要就可以把上下文窗口拓展到200万水平。从学术的角度看,上下文似乎已经有了较为明确的突破路径。而业界头部公司模型的进化也说明了这一点。
4、长文本难担大模型的下一步?
早在Kimi引发国内大模型“长文本马拉松竞赛”的4个月前,美国大模型界就已经赛过一轮了。参赛的两名选手是OpenAI的GPT4-Turbo和Antrophric的Claude。在去年11月,OpenAI在Dev Day上发布了GPT4-Turbo, 最高支持128k上下文长度的输入,这一下打到了Claude的命门。在能力全面落后GPT4的基础上,唯一的优势也被超越,Antrophric顿时陷入了危机。在14天后,Antrophric紧急发布Claude 2.1,在其他能力没有显著增强的情况下,仅把上下文支持从100k提升到了200k来应对挑战。而在今年2月发布的Geminni 1.5更是直接把上下文窗口推到了100万的水位,这基本上是哈利波特全集的长度和1小时视频的量级。
这说明全球第一梯队的三个大模型,在去年都突破了长文本的限制。
这其中还有一个小插曲,Claude 2.1发布后,完全没想到行业人士这么快就对它进行了探针测试,可以用简单的概念来理解,就是大海捞针。
探针测试的逻辑是向长文章的不同位置中注入一些和文章完全不相关的话语,看它能不能找出来。能就说明它真的懂了,不能就说明它只是支持了这样的长度,但并没有记住。Claude 2.1探针综合召回率只有20%,可以说基本没记住,而对比GPT4 Turbo放出的论文中,128k长文本的召回率足有97%。
在这场公关战中落于下风的Claude紧急打了补丁,在12月6日放出更新,探针召回率大幅提升,而且按Antrophic官方的说法,他们只是加了个Prompt就解决了这个问题。


一个Prompt就能解决上下文拓展中出现的严重问题。如果不是Claude 本身在故意隐藏底牌,只能说到了去年12月份,这个护城河已经略浅了。而到了今年3月份,中文大模型的这场最新版本的长文本战争时,其他厂商的快速跟上,更为“护城河略浅”加了些注脚。
5、国外为什么不卷长文本了?
全球三大模型的长文本之战最终“高开低走”。GPT4-Turbo 128k直到今天仍然仅对API用户(主要是专业开发者及公司)开放,一般用户只能用32 k的GPT4版本。在今年3月发布的号称超越GPT4的Claude 3依然只支持到200K的上下文限制。
突然他们都不卷了。这是为什么?
首先是因为不划算。在上文提及注意力机制的时候,我们讲到因为其内生的运作逻辑,上下文越长需要计算的量级越大。上下文增加32倍时,计算量实际会增长大约1000倍。虽然靠着稀疏注意力等减负措施,时机运算量并没有那么巨大,但对模型来讲依然是非常大的负担。这从大模型的反应时间可以一窥:根据目前的测试反馈,Gemini在回答36万个上下文时需要约30秒,并且查询时间随着token数量呈非线性上升。而当在Claude 3 Opus中使用较长文本的上下文时,反应时间也会加长。其间Claude还会弹出提示,表示在长上下文的情况下,应答时间会显著变长,希望你耐心等待。
较大的计算量就意味着大量的算力和相应的成本。
GPT-4 128k版本之所以开放给API用户,是因为他们按输入token数量结算,自己承担这部分算力成本。对于20美元一个月的一般用户而言,这个并不划算。Claude 3 会员版本最近也开始限制同一时间段内的输入次数,预计也是在成本上有所承压。虽然未来算力和模型速度都会变得越来越快,成本和用户体感都会进一步上升。但现在,如果长上下文的需求能够在当下支持框架下获得满足,大模型提供商何必“再卷一步”呢?
其次,长上下文的扩充在一定限度以后对模型整体能力的提升有限。前文提到,上下文对模型能力会有一定提升,尤其是处理长内容的连贯能力和推理能力上有所提升。在早期谷歌进行的较弱模型实验中,我们确实可以看到这样的明显正向关系。
但我们现在评价模型的角度实际上更综合,核心还是希望它能有更好的常识能力和推理能力。GPT4一直都不是支持上下文长度最长的模型,但其综合能力一直一骑绝尘了半年多时间。当上下文够用后,把时间花在优化模型的其他方面似乎更为合理。
在Langchain最近的研究中,他们设置了多个探针后发现,即使是支持长上下文的模型,在探针越多的情况下,其正确召回率仍然会衰退,而且对探针的推理能力衰退的更明显。所以,当前的方法下大模型可能能记住很长上下文,但懂多少,能用多少还是存疑的。

最后,有更便宜的,更有拓展性的解决方法,为什么死磕这条路?
在杨植麟过往的采访中,他曾经指出一种拓展上下文的模式是蜜蜂模式,属于一种走捷径的模式,不能真正的影响到模型的能力。这种模式就是RAG,也就是检索增强生成(RAG)。其基本逻辑就是在模型外部设置一个存储器,通过切片方法将我们输入给模型的长文本切成模型有能力识别的短文本小块,在取用时通过索引让大模型找到具体的分块。它和蜂巢一样一块块的所以被称作蜜蜂模式。
通过RAG,大模型可以考仅处理索引涉及到的小段落就可以,所以反馈速度很快,也更便宜。但它的问题正如杨植麟所说,因为是分块的,只能窥一斑难见长文本的一豹。
GPT4用的就是这样的模式,所以在32k的长度下也可以接受更大的文本进行阅读,但问题确实很多,它会经常返回说明明在文章里有的东西它找不到。
但这个问题最近也被攻破了。今年2月发布BGE Landmark embedding的论文也阐述了一种利用长上下文解决信息不完整检索的方法。通过引入无分块的检索方法,Landmark embedding能够更好地保证上下文的连贯性,并通过在训练时引入位置感知函数来有限感知连续信息段中最后一个句子,保证嵌入依然具备与Sentence Embedding相近的细节。这种方法大幅提升了长上下文RAG的精度。
另外,就像当下的数据库一样,因为我们日常生活工作中真正用到的上下文不仅包含了长文本、图片等非结构化数据,更包含了复杂的结构化数据,比如时间序列数据、图数据、代码的变更历史等等,处理这些数据依然需要足够高效的数据结构和检索算法。
100万token这个上下文长度,在文本,代码为主的场景下,已经足够满足99%我们当下的上下文用例了。再卷,对用户而言毫无价值。当然,因为看一个五分钟的视频可能就需要10万以上的token,在多模态模型实装时代中,各个模型供应商还是有再往上卷的理由。但在当下的算力成本之下,它的大规模应用应该还很难。
关于长文本本身有多大可扩展空间,杨植麟的回答是:“非常大。一方面是本身窗口的提升,有很长路要走,会有几个数量级。另一方面是,你不能只提升窗口,不能只看数字,今天是几百万还是多少亿的窗口没有意义。你要看它在这个窗口下能实现的推理能力、the faithfulness的能力(对原始信息的忠实度)、the instruction following的能力(遵循指令的能力)——不应该只追求单一指标,而是结合指标和能力。”
如果这两个维度持续提升,人类下达一个几万字、几十万字的复杂指令,大模型都能很好地、准确地执行,这确实是巨大的想象空间。到了那个时候,可能没有人会纠结,这家公司的核心竞争力究竟是长文本,还是别的什么。