前言
这也是最近帮一个朋友看问题 遇到的一个问题
然后 引发了一下 对于 flink-sql 里面的一些 常规处理的思考, 理解
原始问题主要是 在测试库可以使用 flink-sql 可以正常同步, 但是 在生产环境 无法正常同步数据
这个问题 我们后面单独 记录一篇文章

测试用例
下载 flink-1.13.6, 首先启动一个 standalone 的集群
master:flink-1.13.6 jerry$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host master.
启动 flink sql-client
master:flink-1.13.6 jerry$ ./bin/sql-client.sh
Listening for transport dt_socket at address: 5007
No default environment specified.
Searching for '/Users/jerry/Downloads/flink-1.13.6/conf/sql-client-defaults.yaml'...not found.
Command history file path: /Users/jerry/.flink-sql-history▒▓██▓██▒▓████▒▒█▓▒▓███▓▒▓███▓░░ ▒▒▒▓██▒ ▒░██▒ ▒▒▓▓█▓▓▒░ ▒██████▒ ░▒▓███▒ ▒█▒█▒░▓█ ███ ▓░▒██▓█ ▒▒▒▒▒▓██▓░▒░▓▓██░ █ ▒▒░ ███▓▓█ ▒█▒▒▒████░ ▒▓█▓ ██▒▒▒ ▓███▒░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓███▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒▓█ ▒█▓ ░ █░ ▒█ █▓█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒███ ▓█▓░ ▒ ░▒█▒██▒ ▓▓▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓░▓██▒ ▓░ ▒█▓█ ░░▒▒▒▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░______ _ _ _ _____ ____ _ _____ _ _ _ BETA | ____| (_) | | / ____|/ __ \| | / ____| (_) | | | |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_ | __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_ |_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
创建 flink-sql 的表结构
CREATE TABLE test_user (
`name` string,
`age` string,
PRIMARY KEY (`name`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = 'postgres',
'database-name' = 'test',
'table-name' = 'test_user'
);
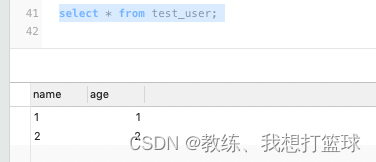
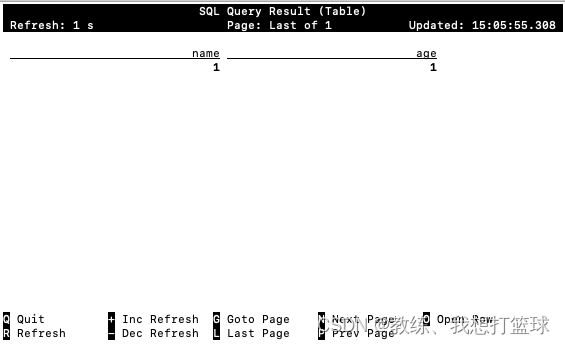
源表数据如下
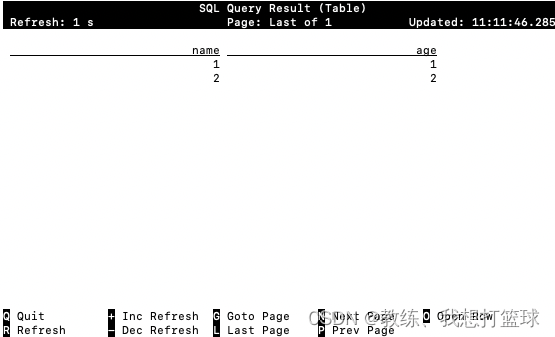
然后 flink-sql 这边查询 结果如下
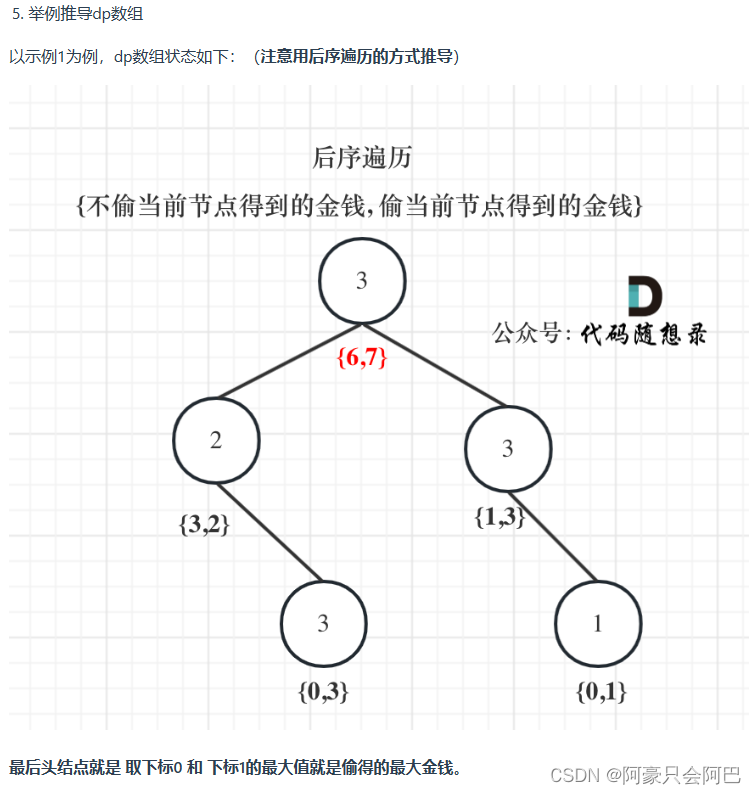
然后 我们来看一下 这里的整个处理流程
flink-sql 中 select * from test_user 获取全量数据的调试
首先这里交互的角色抽象的可以理解为两个, 一个是 flink 集群, 一个是 flink sql-client
然后 flink sql-client 这边组合查询, 相关业务, 然后创建一个 flink 任务, 抛给 flink 集群
然后 两者进行交互, 首先是拿到 test_user 的快照全量数据, 然后 flink sql-client 这边做业务展示
然后 test_user 的之后的增删改查, 的处理是基于 mysql binlog 这边来做增量处理
我们这里 仅仅演示 test_user 的快照数据获取 以及 在 test_user 中增加一条记录, 然后 flink sql-client 这边是 怎么获取到的这个整个流程
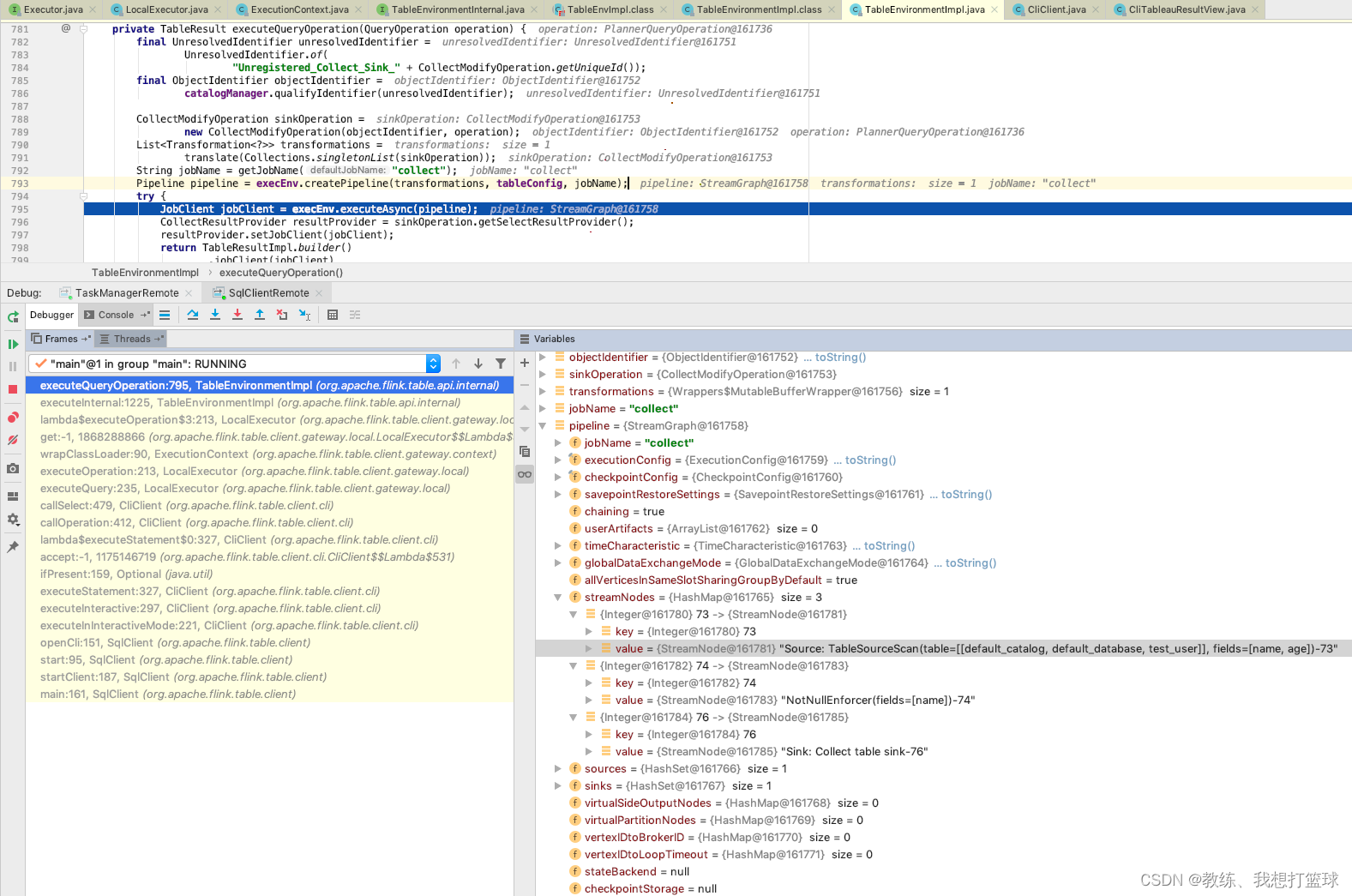
如下这里是 flink sql-client 这边将用户输入的 " select * from test_user " 转换为 flink sql 上下文的 operations, 然后封装成 pipeline, 提交给 flink 集群
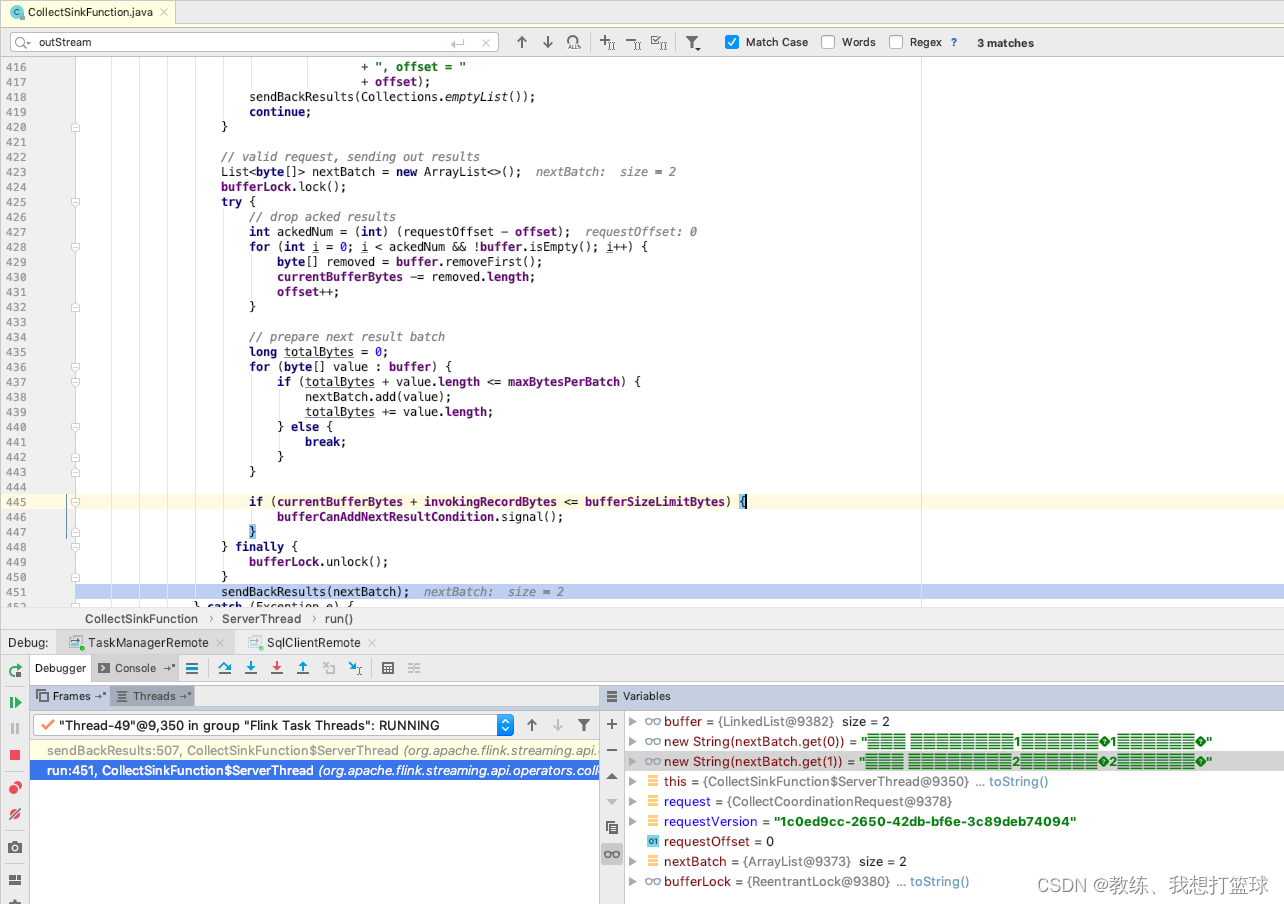
看一下 flink 集群这边任务的执行, 首先是 第一次的全量数据的快照
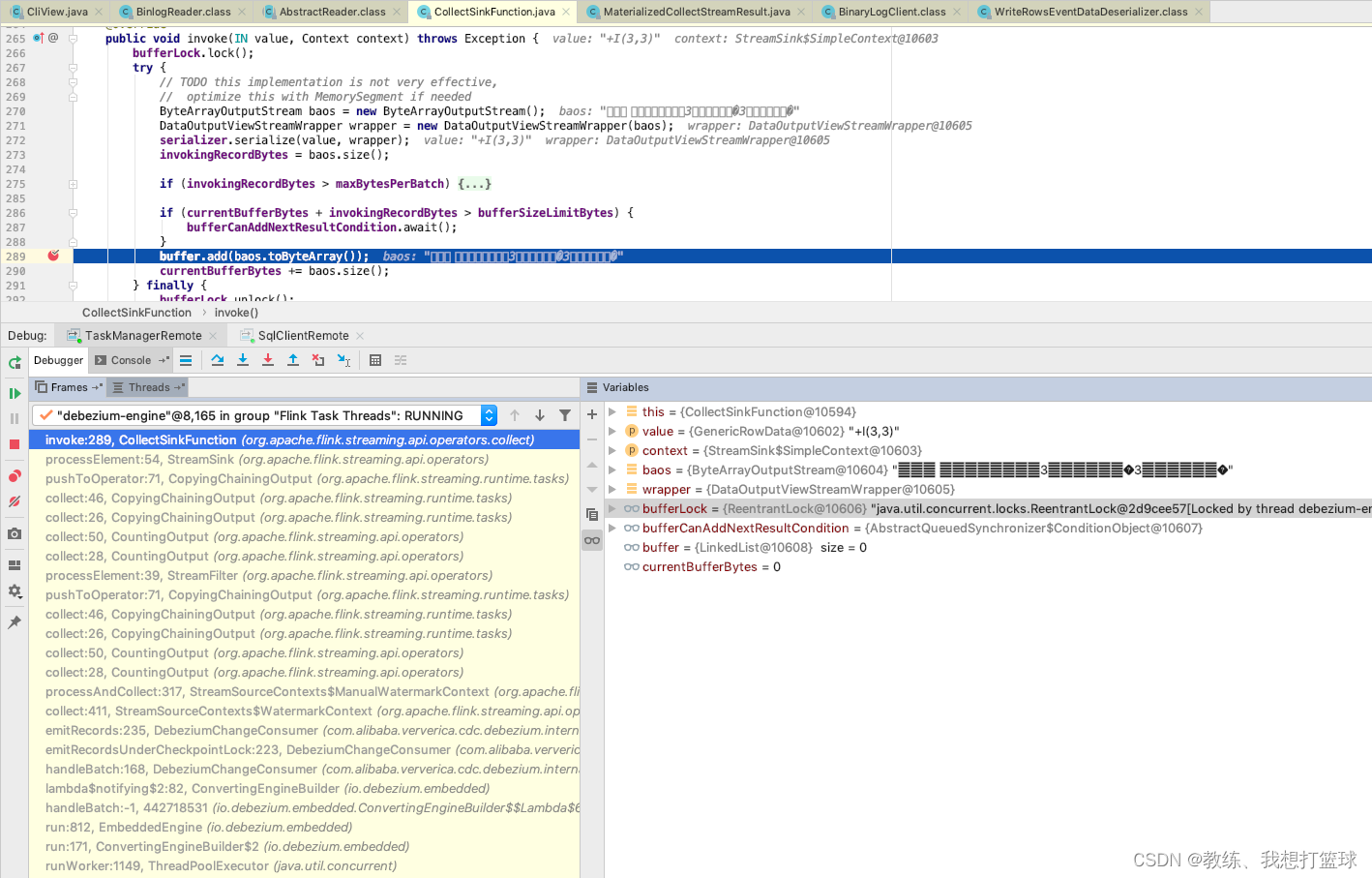
从 CollectSinkFunction 这边从 buffer 中获取到两条记录, 大致可以看出是 第一条记录 和 第二条记录, 然后 sendBackResults 通过 tcp交互, 将这两条数据对应的 StreamRecord 传输回 flink sql-client
往前回溯, 看一下 真正执行查询的地方, 执行的是 "select * from test_user;"
然后这里迭代会将 查询的记录封装成为 SourceRecord, 然后添加到 recorderMarker 的 bufferedRecordQueue 中
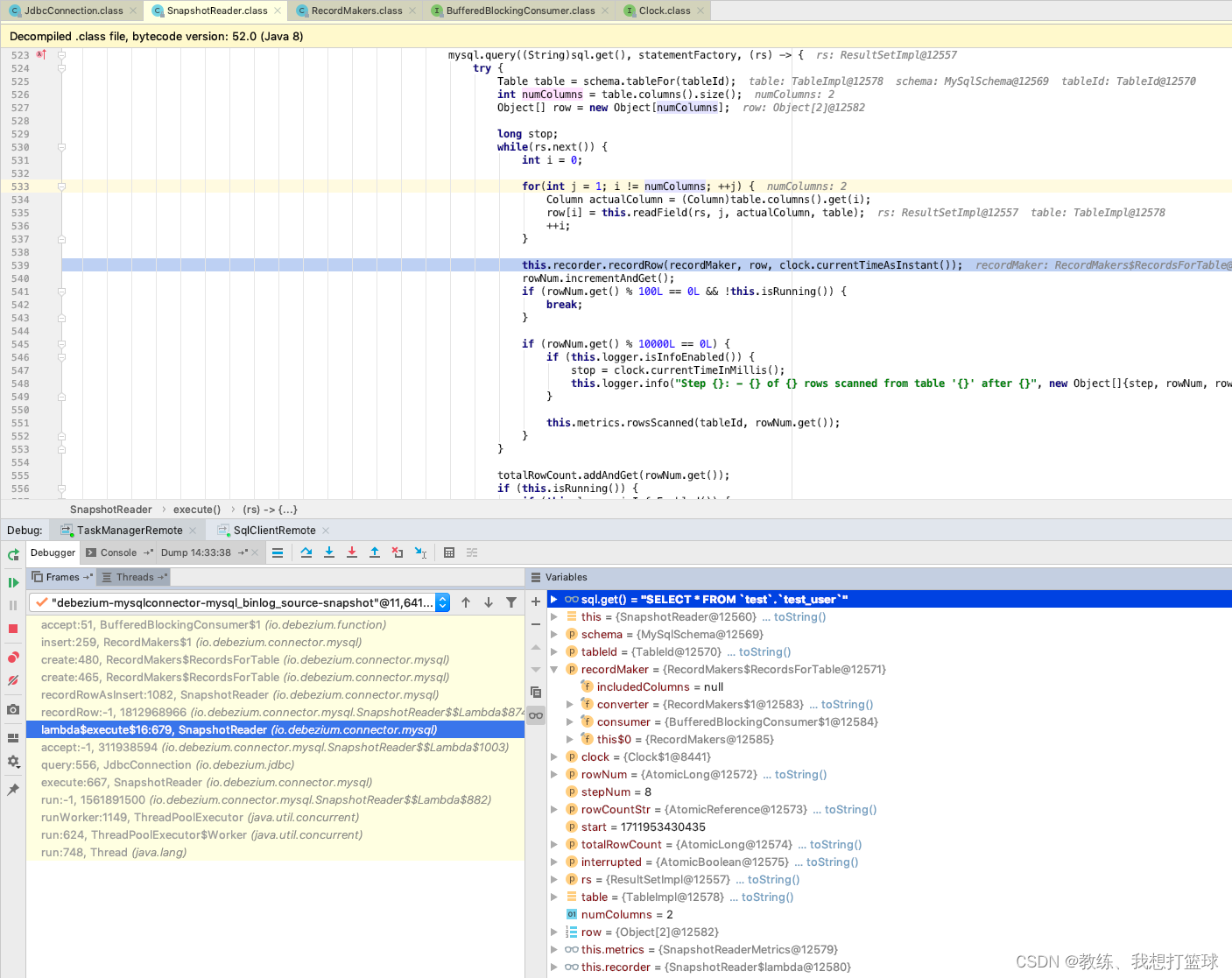
然后这个 bufferedRecordQueue 是一个队列, 会将消耗的元素调用 enqueueRecord 将数据放入到 records 中
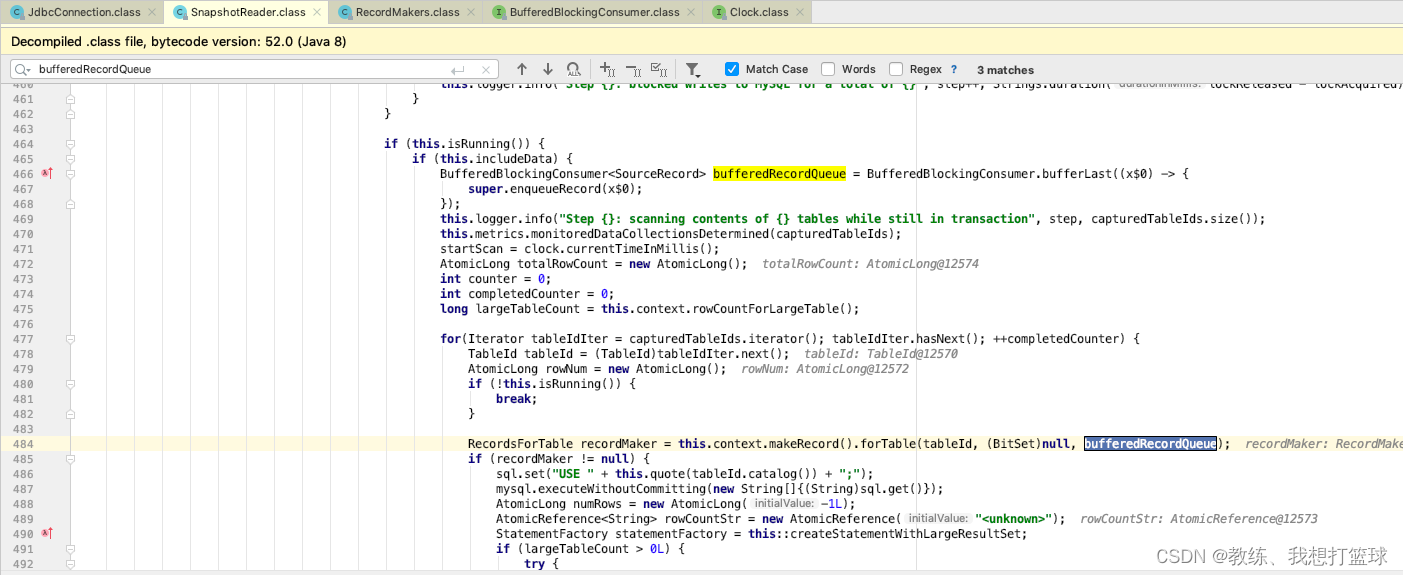
这里是更细节的 enqueueRecord 的执行流程, 比如这里 迭代的事 第一条记录
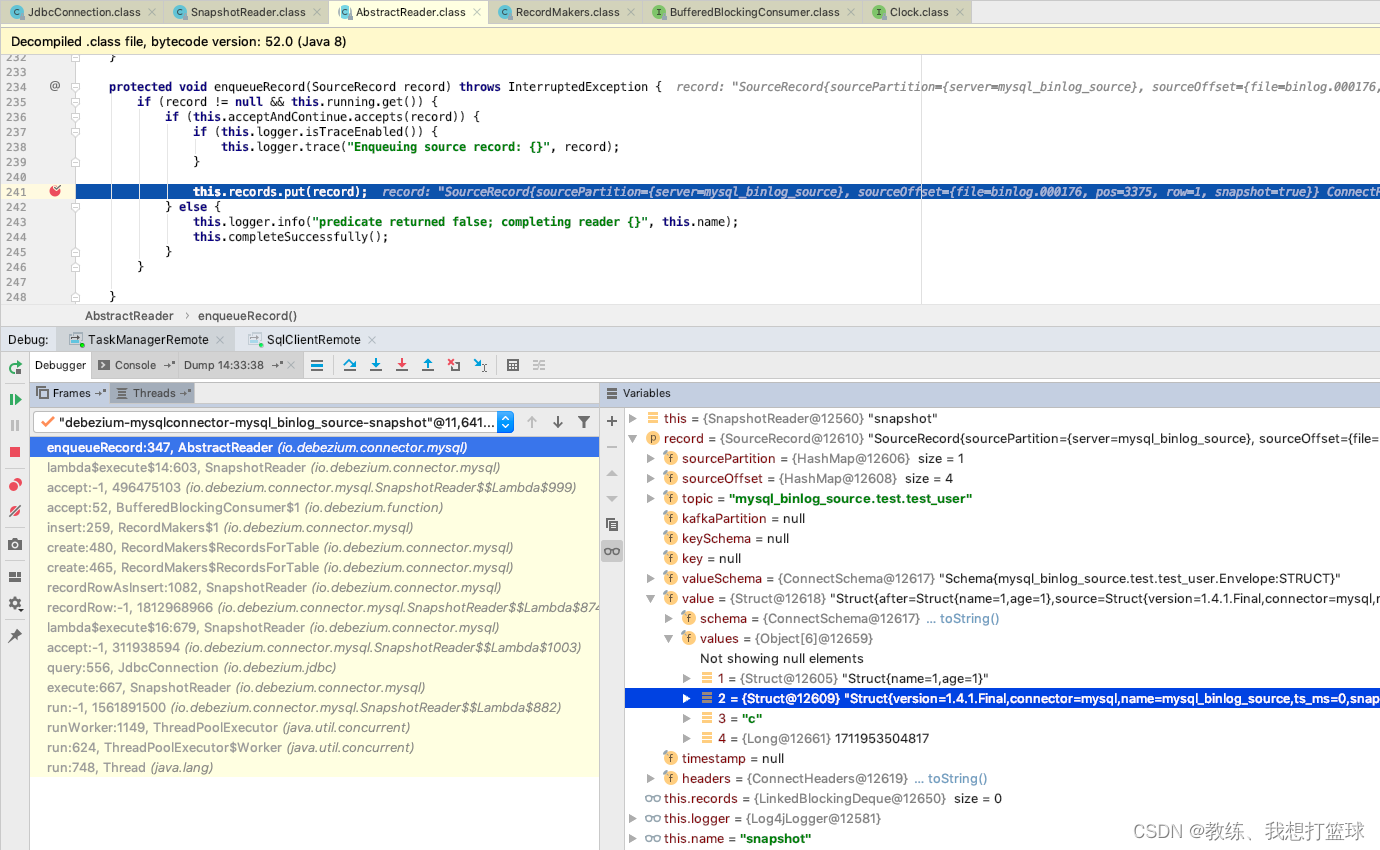
然后接着是 更上一层 Engine 的业务流程, 他会将 SnapshotReader 这边读取的记录更新到 batch 中
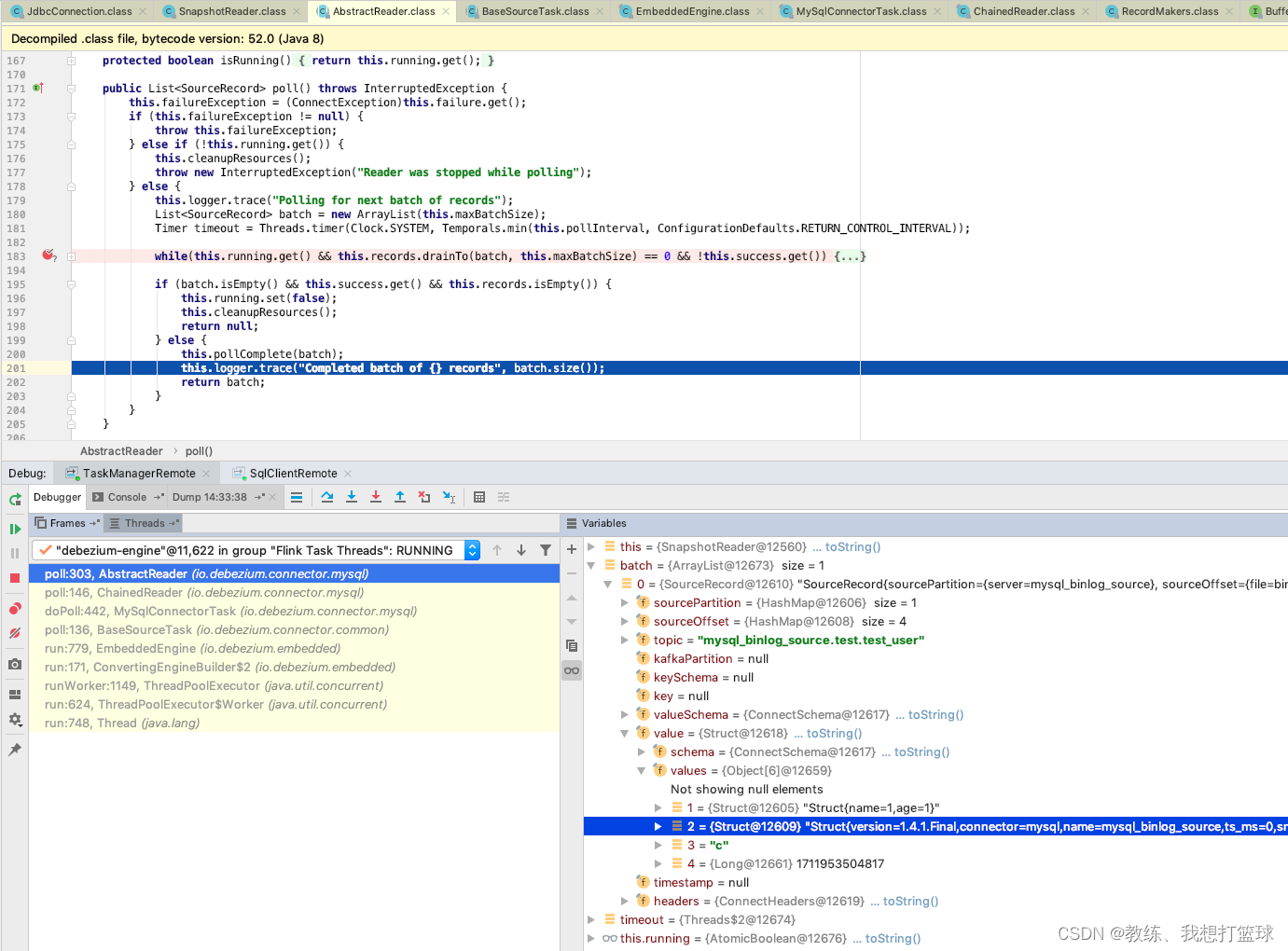
然后就是 Engine 这边的任务的执行, 将数据经过 map, filter, NotNull, 等等相关处理
最终到达 CollectSinkFunction 这边
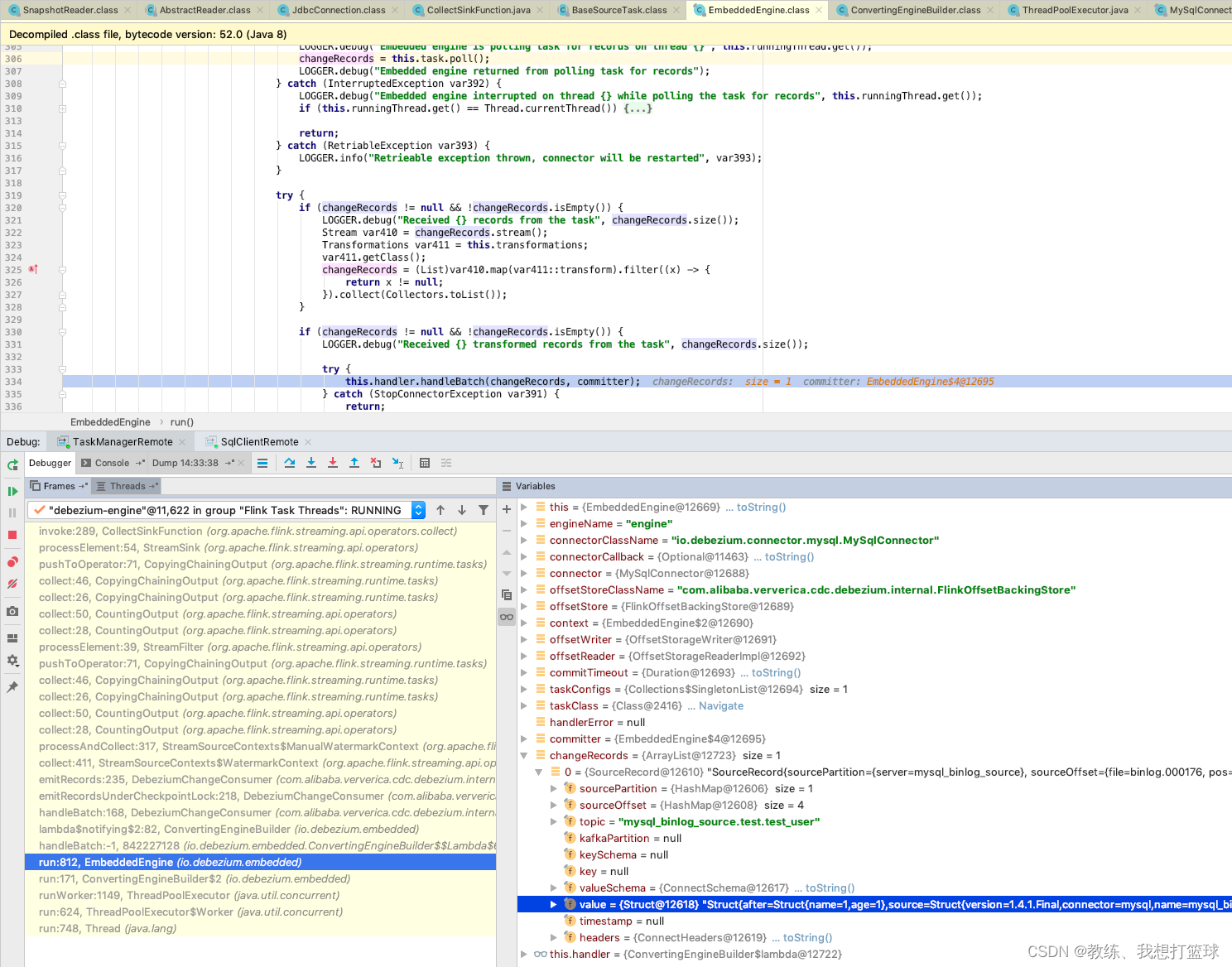
然后 CollectSinkFunction 这边将数据封装成 GenericRowData, 然后序列化, 放入 buffer 队列
然后 最终就是 CollectSinkFunction 上面的流程, 将序列化之后的数据通过 CollectCoordinationResponse 回传给 flink sql-client
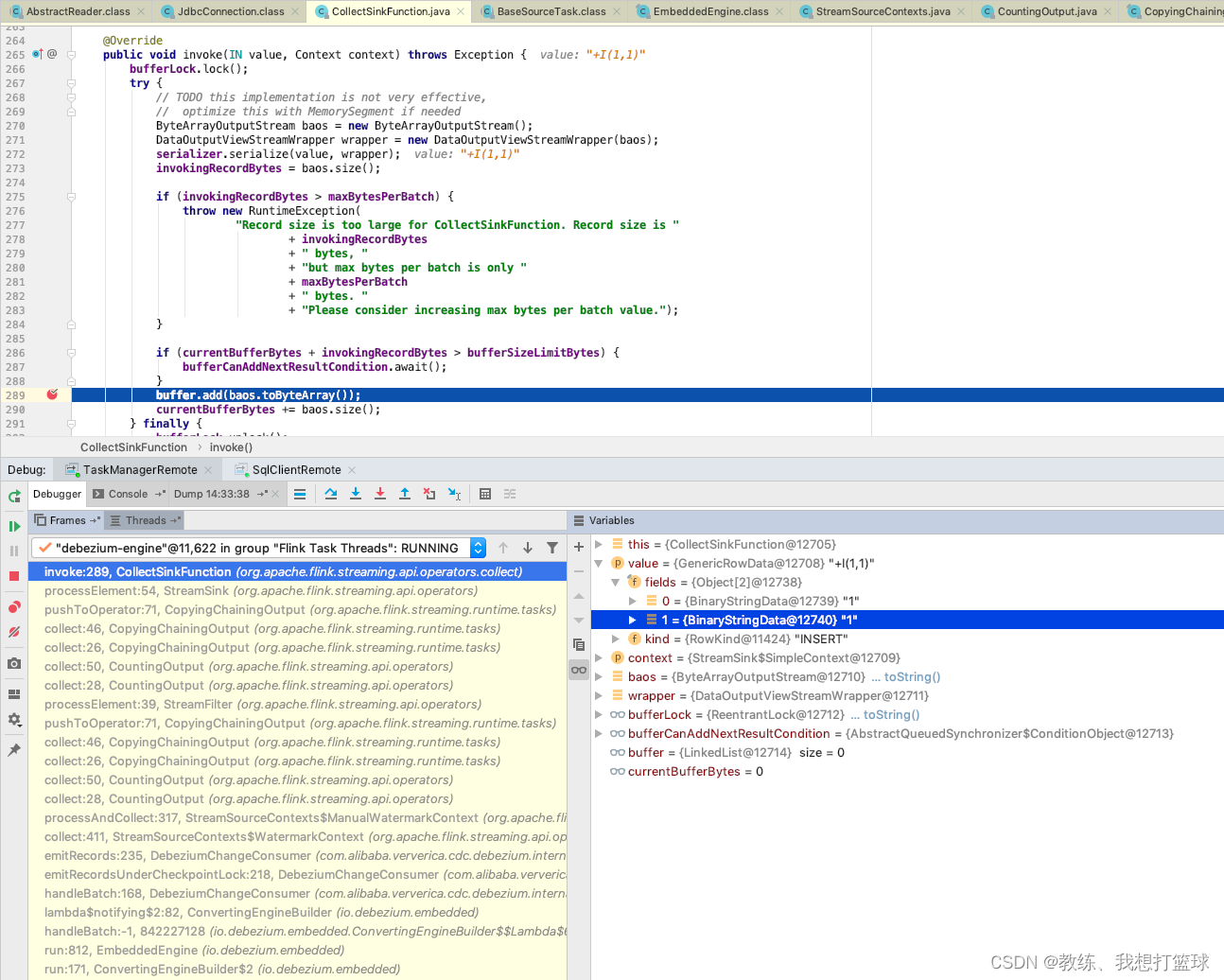
然后 flink sql-client 这边的处理如下
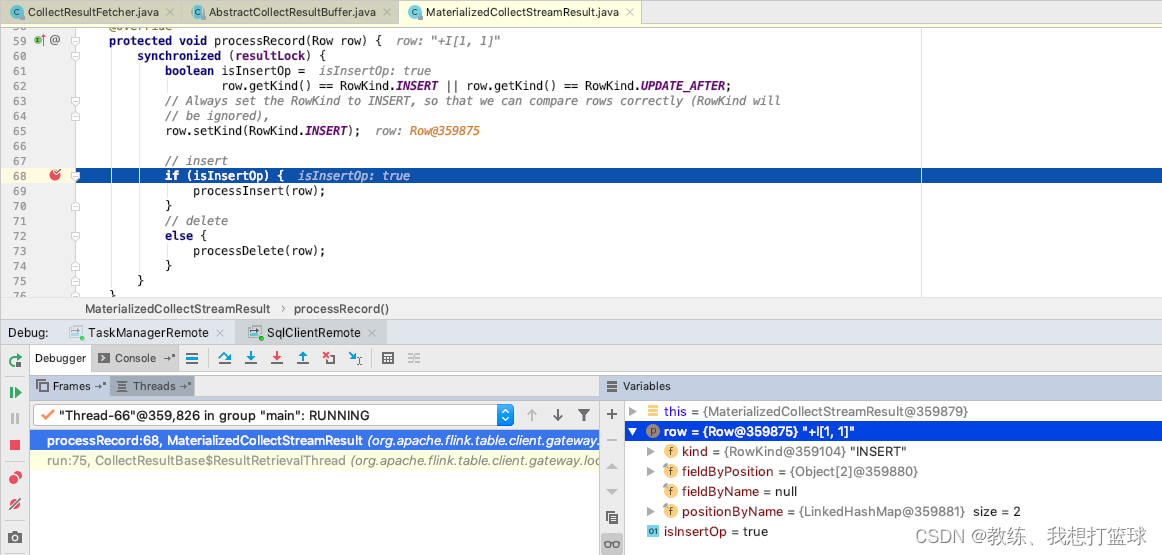
将拿到的数据, 添加到 buffer 队列
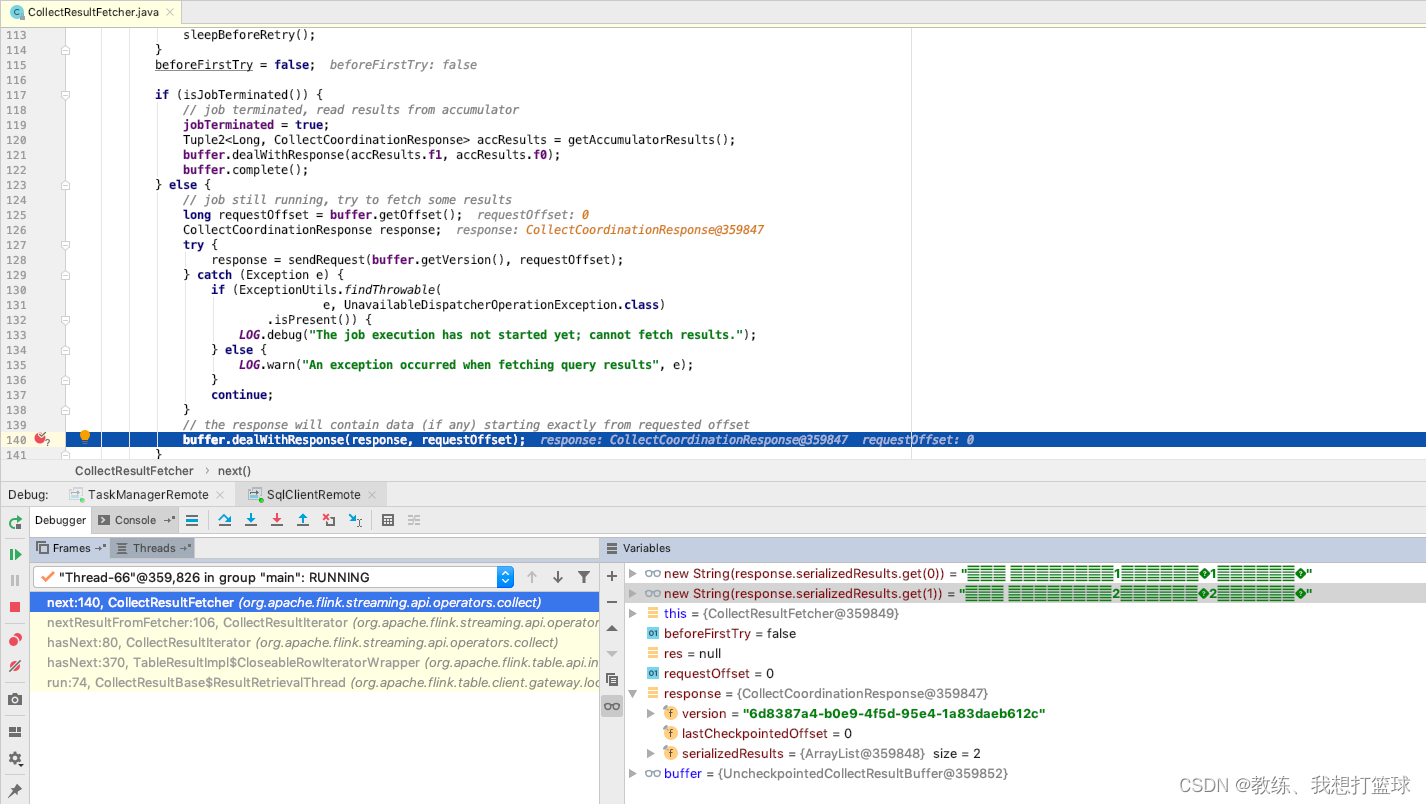
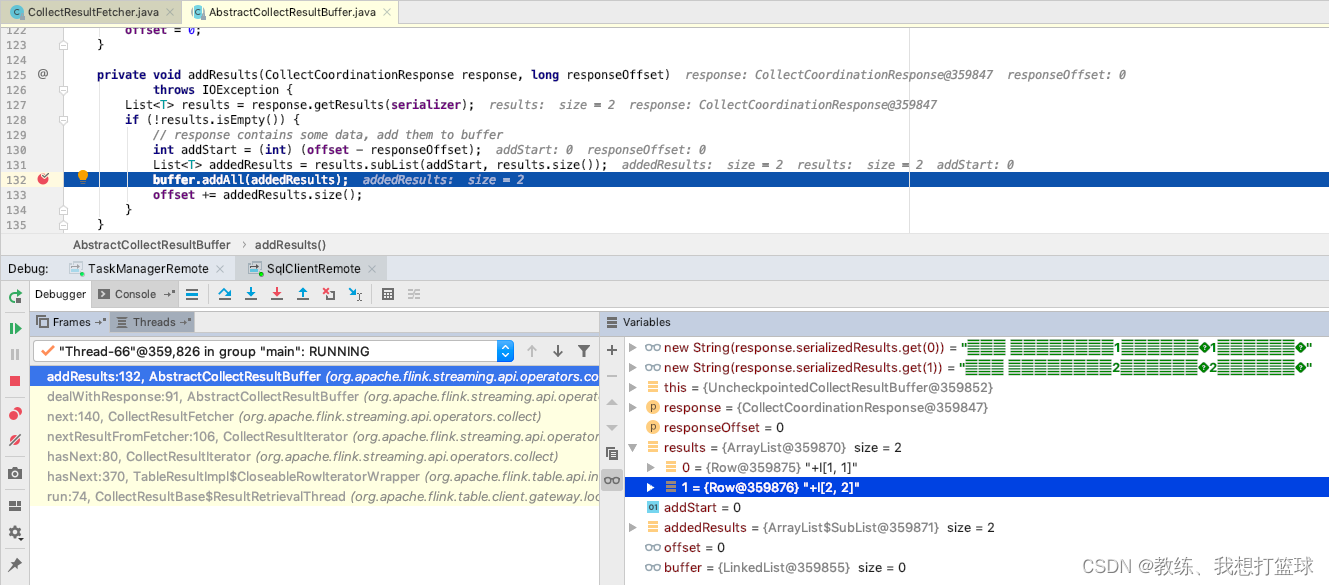
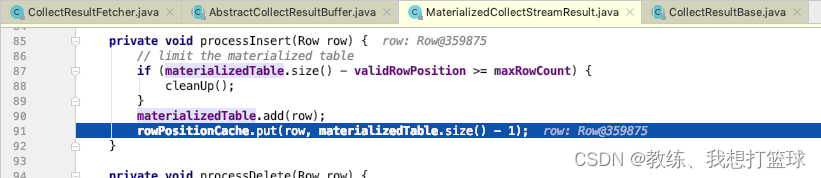
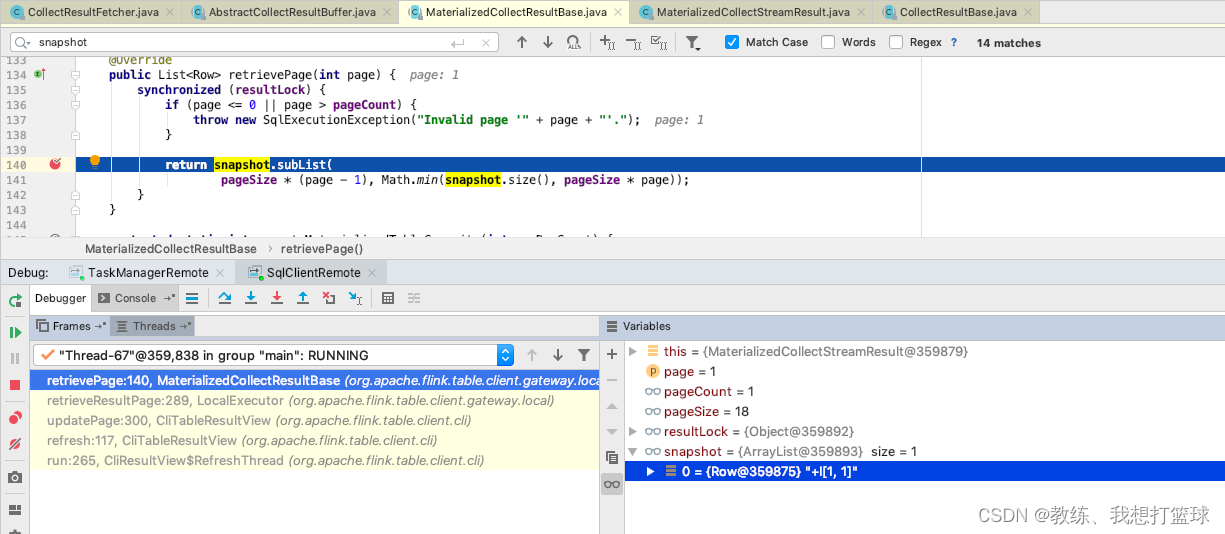
然后就是 flink sql-client 这边的主线程的处理了, 从 buffer 中迭代 记录出来, 然后 放到 materializedTable, 然后 之后 cli 这边获取表格数据的时候, 将其传输到 snapshot 中
flink sql-client 这边的展示流程如下
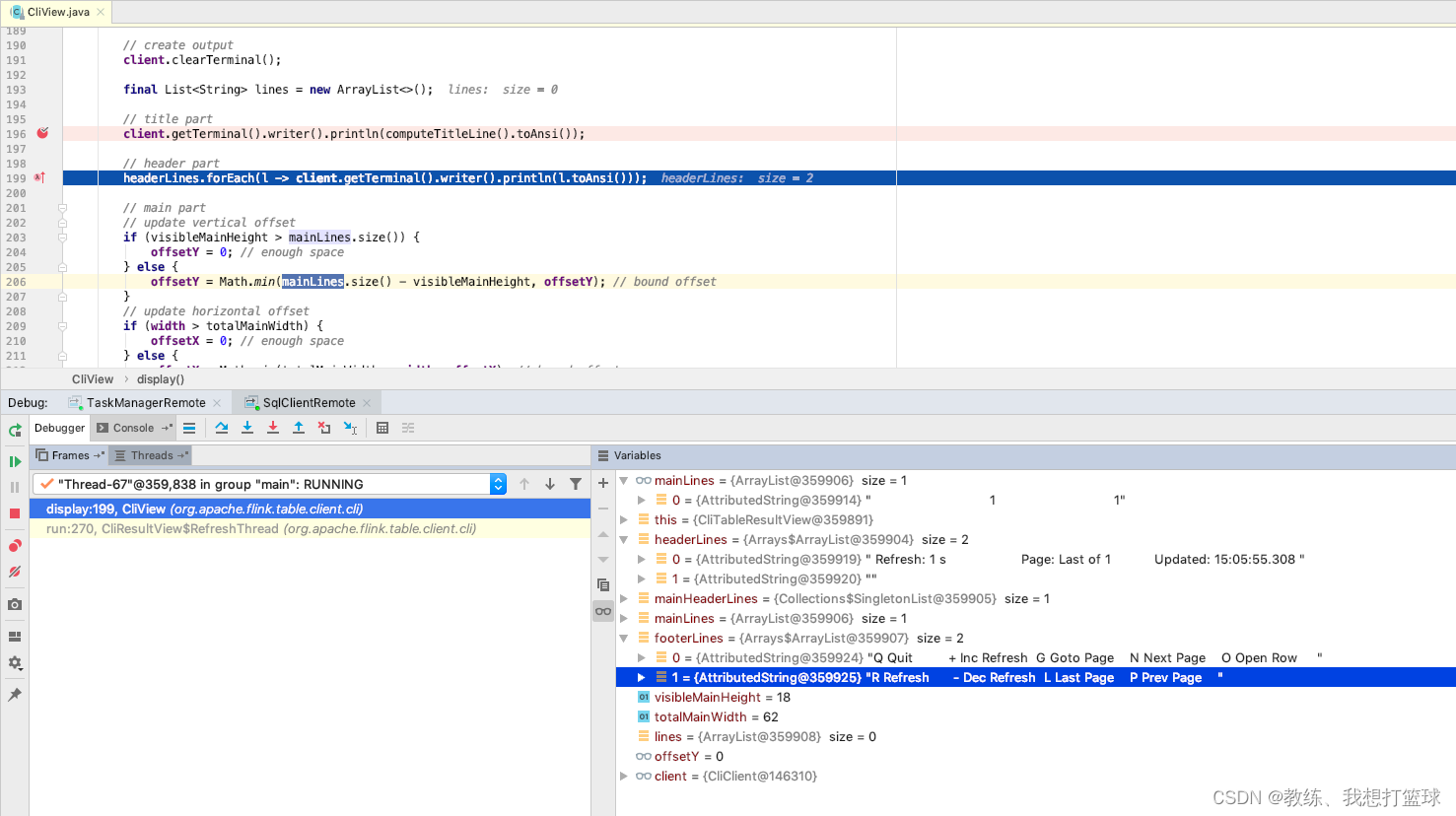
然后 做具体的展示, 展示结果如下, 然后 随着之后的迭代 能够获取完整当前页的数据, 展示在 cli 中
flink-sql 中 select * from test_user 获取增量数据的调试
增量数据的获取, 来自于 BinlogClient 这边的获取, 连接 mysql 的服务
发送获取 binlog 的命令, 然后 之后 mysql 这边有 binlog 的事件之后, 会将相关 事件传递到 BinlogClient 这边
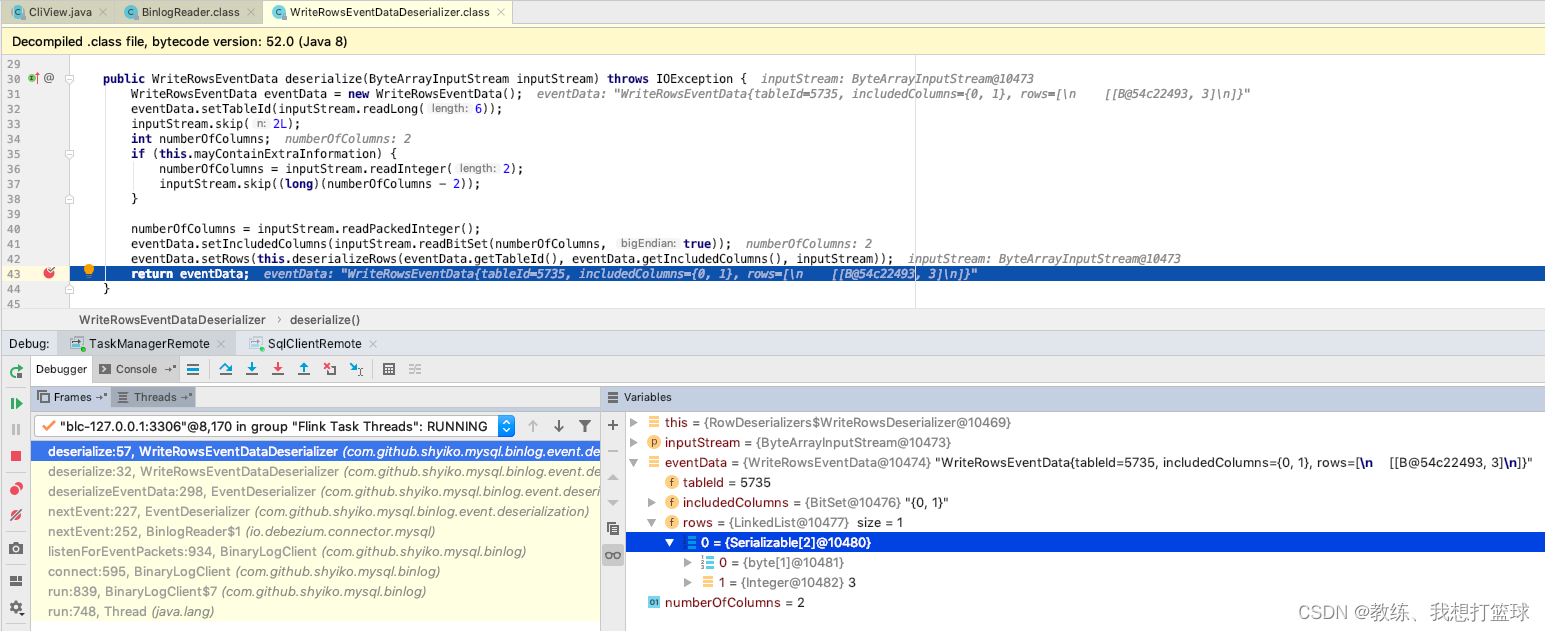
比如这里 执行了一个 ”insert into test_user (`name`, age) select max(age)+1, max(age+1) from test_user;”, 增加了一条记录 (3, 3)
然后这边 反序列化之后, 读取到 WriteRowsEvent 数据为 (3, 3)
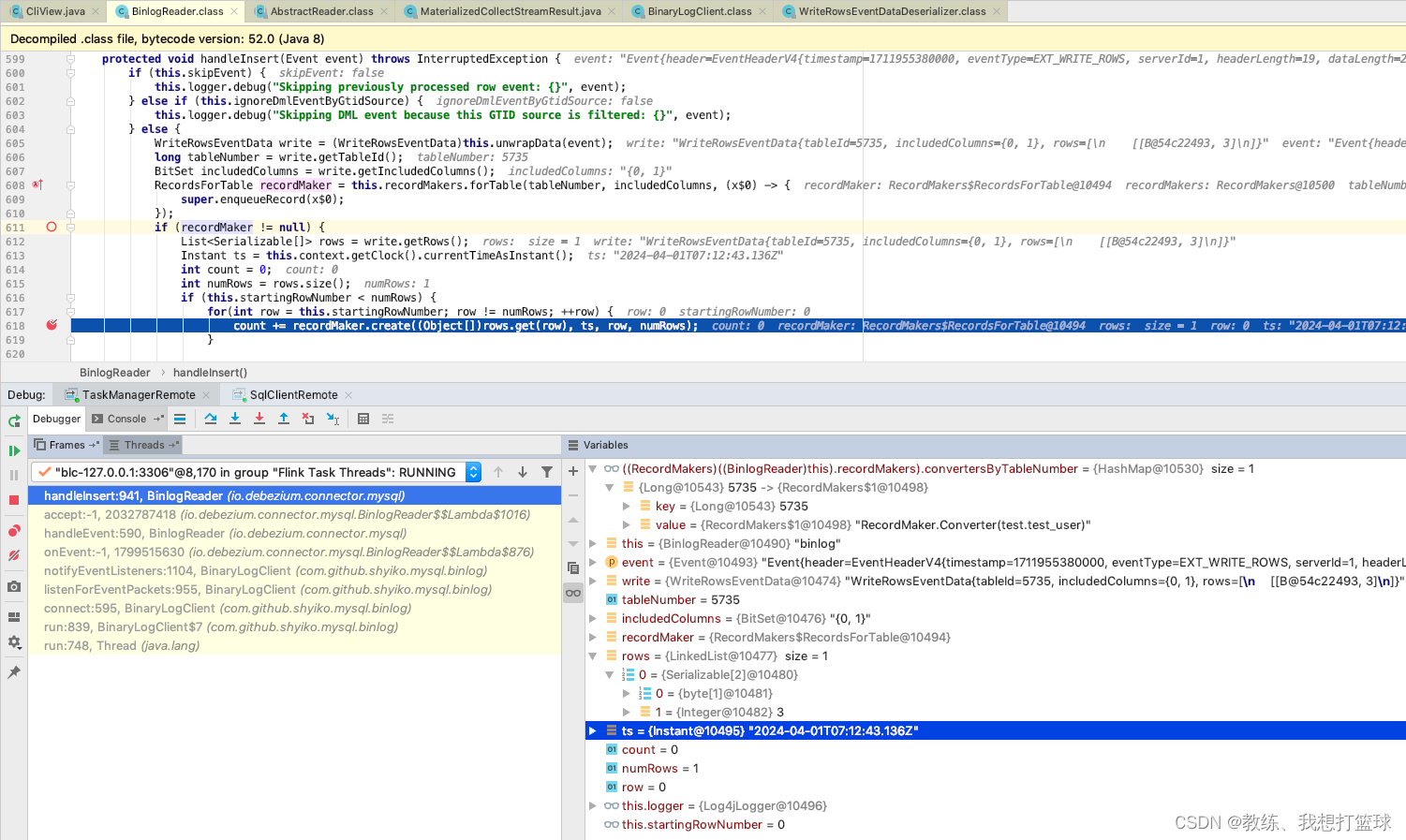
然后就是 BinlogClient 的后续流程, 将数据使用 recordMarker 记录
和上面 SnapshotReader 这边处理一样, recorderMarker 会将 SourceRecord记录 添加到 records 列表, 由外层 Engine 层轮询 records 将其进行任务的执行, 到后面的 CollectSinkFunction 传输给 flink sql-client 这边做数据增删改查, 以及展示
为记录 (3, 3) 生成 SourceRecord 并放到 records 队列
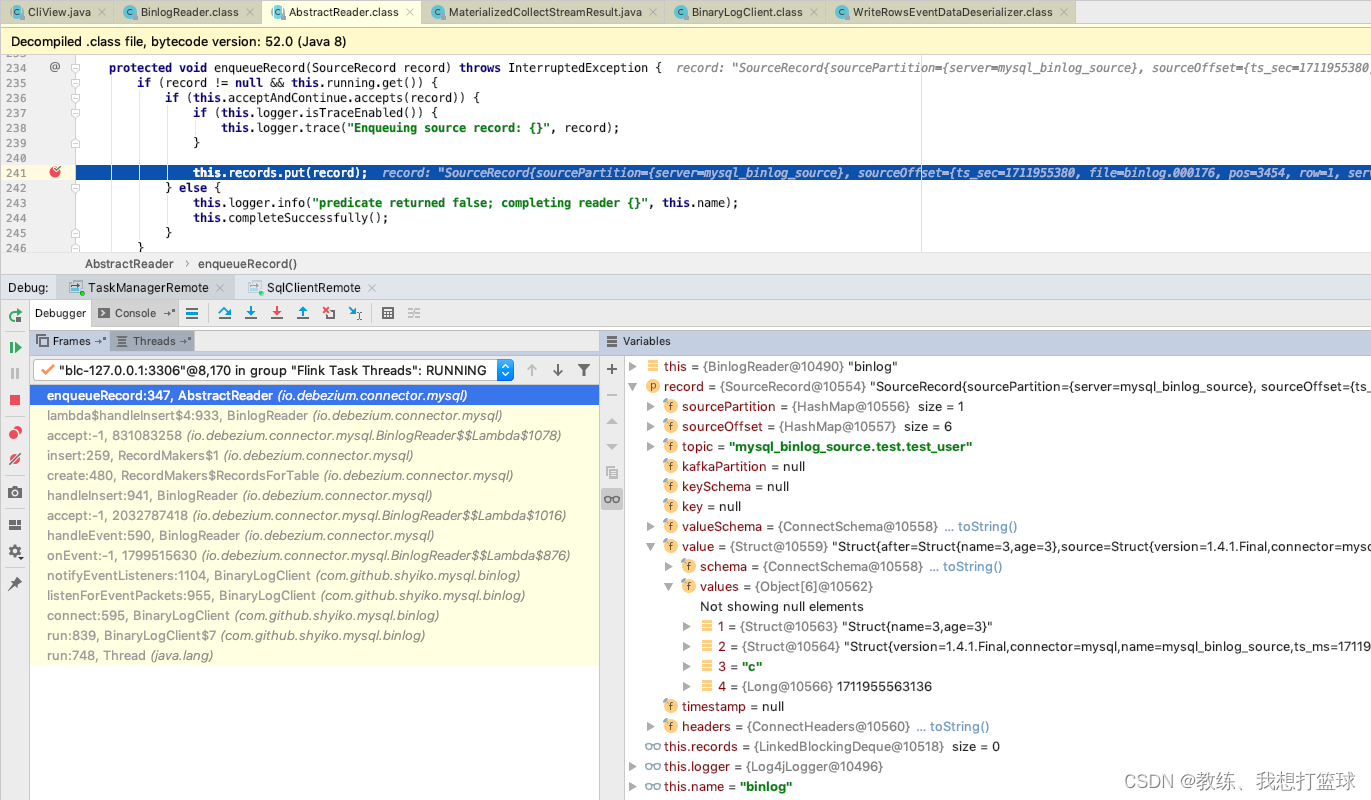
Engine 层的处理, 其他的这里就不细化了
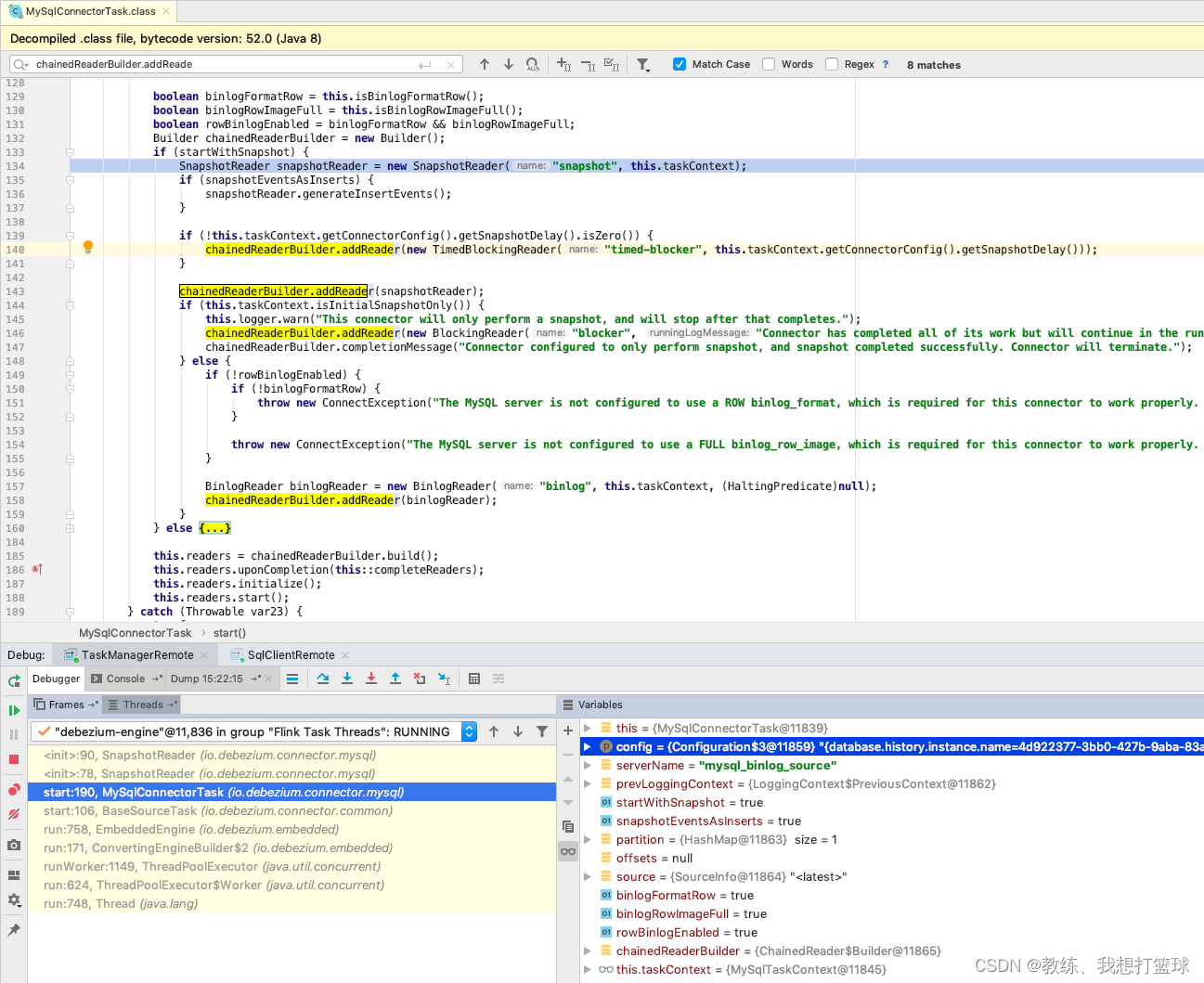
flink mysql-cdc MysqlConnectorTask 的处理
我们可以看到上面 全量读取使用了 快照读, 然后增量的部分使用基于 binlog 来进行处理
那么这个 处理流程是在这里呢?
完