文章目录
- 1 缓存的收益与成本分析
- 1.1 收益
- 1.2 成本
- 2 缓存更新策略的选择和使用场景
- 2.1 LRU/LFU/FIFO算法剔除
- 2.2 超时剔除
- 2.3 主动更新
- 2.4 缓存更新策略对比
- 2.5 最佳实践
- 3 缓存粒度控制方法
- 3.1 缓存全部数据
- 3.2 缓存部分数据
- 3.3 缓存粒度控制方法对比
- 4 缓存穿透问题优化
- 4.1 什么是缓存穿透?
- 4.2 缓存空对象
- 4.3 布隆过滤器拦截
- 4.4 两种方案对比
- 5 无底洞问题优化
- 5.1 什么是无底洞问题?
- 5.2 串行命令
- 5.3 串行IO
- 5.4 并行IO
- 5.5 hash_tag
- 5.5 几种批量操作方案对比
- 6 缓存雪崩问题优化
- 6.1 什么是缓存雪崩问题?
- 6.2 保证缓存层服务高可用性
- 6.3 依赖隔离组件为后端限流并降级
- 6.4 提前演练
- 7 热点key重建问题优化
- 7.1 什么是热点key重建问题?
- 7.2 互斥锁
- 7.3 永远不过期
- 7.4 两种方案比较
为什么要进行缓存设计?
缓存设计能够有效地加速应用读写速度,降低后端负载,对日常应用开发至关重要。但是将缓存加入应用架构后也会带来一些问题,所以针对不同的问题或场景,需要进行相应的缓存设计
1 缓存的收益与成本分析
如图所示,左边是客户端直接调用存储层的架构,右边是典型的缓存层+存储层架构

1.1 收益
- 加速读写:因为缓存通常都是全内存的,而存储层通常读写性能不够强悍(因为需要磁盘IO操作),通过缓存可以有效地加速度下,优化用户体验。
- 降低后端负载:对于一些很复杂的SQL语句,如果在缓存层就命中了结果,可以有效减少后端访问量和复杂计算,在很大程度上降低了后端负载。
1.2 成本
- 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,这个时间窗口的大小根更新策略有关。
- 代码维护成本:加入缓存后,要同时处理缓存层和存储层逻辑,增大了开发者维护代码的成本。
- 运维成本:项目上线后,mysql,redis都需要进行运维。
2 缓存更新策略的选择和使用场景
为什么我们在用Redis进行缓存是通常会加上键的生命周期?
给缓存中的数据通加上生命周期,需要在指定的时间后被删除或更新,这样可以保证缓存空间在一个可控范围内。
既然缓存有生命周期,那为什么要更新缓存?
因为前面成本分析中介绍到,缓存中的数据和存储层中的数据有一段时间窗口的不一致,需要利用某些策略进行更新。
2.1 LRU/LFU/FIFO算法剔除
- 使用场景:剔除算法通常用于缓存使用量超过了预设最大值时候,如何对现有数据进行提出。例如Redis使用maxmemory-policy这个配置作为内存最大值后对数据的提出策略。
- 一致性:要清理哪些数据是由具体算法决定,开发人员只能决定使用哪些算法,所以一致性是最差的
- 维护成本:算法不需要开发人员自己来实现,通常只需要配置最大maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择自己合适的算法即可。
redis maxmemory-policy有哪些?
1、noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。这是默认策略。
2、allkeys-lru:尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
3、volatile-lru:在设置了过期时间的键空间中,尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
4、allkeys-random:回收随机的键,使得新添加的数据有空间存放。
5、volatile-random:在设置了过期时间的键空间中,回收随机的键,使得新添加的数据有空间存放。
6、volatile-ttl:在设置了过期时间的键空间中,有更早过期时间的键将优先被回收。
2.2 超时剔除
- 使用场景:超时剔除通过给缓存设置过期时间,让其在过期时间后自动删除。例如Redis提供的expire命令。如果业务可以容忍一段时间以内,缓存层和存储层的数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。
- 一致性:一段时间窗口内(取决于过期时间的长短)存在一致性问题,即缓存数据和真实数据源不一致。
- 维护成本:维护成本不是很高,只需要设置expire过期时间即可。
2.3 主动更新
- 使用场景:应用方对数据一致性要求很高,需要在真实数据更新后,立即更新缓存数据。例如可以用过消息系统或其他方式通知缓存更新。
- 一致性:一致性最高,但如果主动更新发生了问题,那么这条数据可能长时间不会更新,所以将主动更新策略与超时剔除策略结合起来比较好。
- 维护成本:维护成本较高,开发者需要自己来完成更新,并保证更新操作的正确性。
2.4 缓存更新策略对比
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LFU/FIFO算法剔除 | 最差 | 第 |
| 超时剔除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
2.5 最佳实践
- 低一致性业务:配置最大内存和淘汰策略方式使用。
- 高一致性业务:结合超时剔除和主动更新。
为什么对高一致性业务,建议结合超时剔除和主动更新?
因为主动更新代码是由开发人员编写的,如果发生问题,缓存可能长时间得不到更新,这是缓存层的数据和存储层的数据就长时间不一致,对于高一致性业务是无法容忍的,所以为了避免这个问题,将主动更新策略和超时剔除策略结合起来,如果主动更新发生问题,超时剔除还可以保证缓存数据过期后剔除脏数据。
3 缓存粒度控制方法
什么是缓存粒度?
缓存粒度是缓存系统中存储数据的最小单位。
假设现在有一个用户的信息需要缓存在Redis中
Key, user:id
Value,用户信息
假设用户表有100个列,需要缓存到什么程度呢?可以选择缓存全部列(缓存粒度较大), 也可以选择缓存部分重要列(缓存粒度较小),这就是缓存粒度问题。
3.1 缓存全部数据
将所有列缓存到Redis中。
3.2 缓存部分数据
只缓存部分重要列。
3.3 缓存粒度控制方法对比
| 数据类型 | 通用性 | 占用空间 内存空间+网络带宽+CPU开销 | 代码维护 |
|---|---|---|---|
| 全部数据 | 高 | 大 | 简单 |
| 部分数据 | 低 | 小 | 较为复杂 |
4 缓存穿透问题优化
4.1 什么是缓存穿透?
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。

如图所示,整个缓存穿透的过程分为三步:
- 缓存层不命中。
- 存储层不命中,不将空结果写回缓存。
- 返回空结果。
缓存穿透将导致对不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。可以在程序中分别统计总调用数,缓存命中数、存储层命中数,如果发现大量存储层空命中,可能出现了缓存穿透问题。
造成缓存穿透的基本原因有两个:
- 自身业务代码或数据出现问题。
- 一些恶意攻击、爬虫等造成大量空命中。
4.2 缓存空对象

缓存空对象的解决办法如上图所示,在前面第二步,缓存层发现空命中时,将空对象写入缓存中,之后再访问这个不存在的数据就直接从缓存中获取,这样就保护了后端数据源。
缓存空对象解决办法简单、高效,但是存在两个问题:
- 缓存中有了个更多的键,需要更多的内存空间。如果是攻击造成的缓存穿透,使用该方法会使得问题更严重。比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动删除。
- 缓存层和存储层会有一段时间窗口的不一致,可能会对业务造成一定的影响。例如设置过期时间为5分钟,在这5分钟内,存储层添加了这个不存在的数据,那么就会造成缓存层和存储层数据不一致的问题,此时可以利用消息系统或其他方式主动更新缓存层里面的空对象。
下面是缓存空对象这个方法的流程

4.3 布隆过滤器拦截

在用户访问缓存层和存储层之前,布隆过滤器会将存在的key提前保存起来,做第一层拦截。如果布隆过滤器认为此次请求的数据不存在,就不会访问存储层,在一定程度上保护了存储层。
4.4 两种方案对比
| 决缓存穿透 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | ●数据命中不高 ●数据频繁变化,实时性高 | ●代码维护简单 ●需要过多的缓存空间 ●数据不一致 |
| 布隆过滤器 | ●数据命中不高 ●数据相对固定,实时性低 | ●代码维护复杂 ●缓存空间占用少 |
5 无底洞问题优化
5.1 什么是无底洞问题?
当数据量和访问量增大时,一个Redis节点根本扛不住,所以需要分布式Redis,部署多个Redis节点来缓存数据。

使用分布式技术,部署多个Redis节点可以有效解决单节点Redis压力过大的问题,但是使用批量操作从多个分布式Redis节点获取值时,由于键值对的分配是按照哈希函数,而不是按照业务,所以某个业务的一次批量操作可能需要从多个节点去获取key,这会造成多次网络时间。
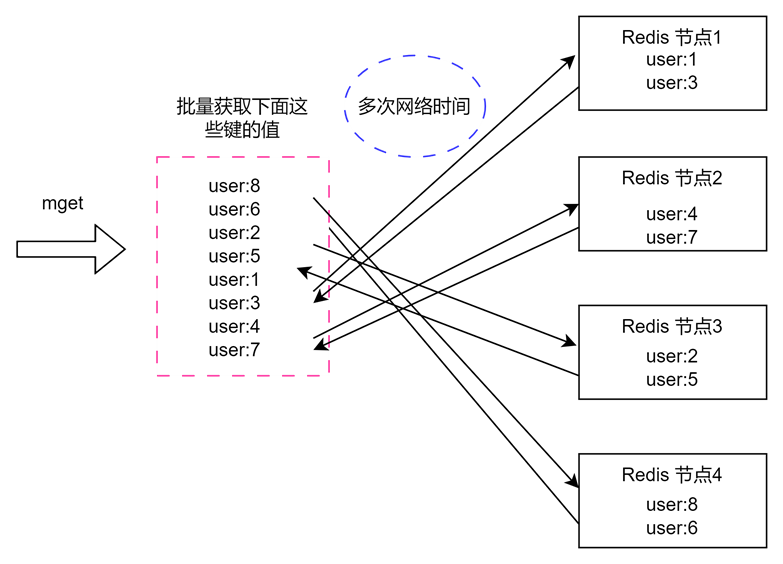
使用单节点Redis,批量操作时只需要一次网络操作。

无底洞问题分析:
- 客户端一次批量操作会涉及多次网络时间,所以一次批量操作会随着节点的增多,耗时会不断增大。
- 网络连接数变多,对节点性能也有一定影响

总结:更多的节点不代表更多的性能,所谓无底洞问题就是说投入越多不一定产出越多。但分布式又是不可避免的,因为访问量和数据量越来越大,一个节点根本扛不住。所以如何高效地在分布式缓存中批量操作是一个难点。
5.2 串行命令
由于n个key是比较均匀地分布在Redis集群的各个节点上,因此无法使用mget命令一次性获取,所以通常来讲,要获取n个key的值,最简单的方法就是逐次执行n个get命令,这种操作时间复杂度较高。
操作时间 = n次网络时间 + n次命令时间

串行命令执行的客户端代码实例如下:
public List<String> serialMGet(List<String> keys) {// 创建一个用于存储结果的列表List<String> values = new ArrayList<>();// 对于输入列表中的每个键,执行get操作,并将结果添加到结果列表中for (String key : keys) {String value = jedisCluster.get(key);values.add(value);}// 返回结果列表return values;
}5.3 串行IO
前面介绍到,分布式部署多个Redis节点时,是将Key输入一个散列函数然后得到这个键值对该存放在哪个Redis节点,而不是根据业务。根据这个原理,我们可以在执行mget keys批量获取多个key时,先主动根据相同的散列函数将keys进行归档,然后同一个node的key放在一起用mget或Pipeline获取,只需要一次网络时间,如果有多个node,总的网路时间就是node的个数次网络时间。
操作时间 = node次网络时间 + n次命令时间

以下是客户端代码示例:
public Map<String, String> serialIOMget(List<String> keys) {// 创建一个用于存储结果的键值对映射Map<String, String> keyValueMap = new HashMap<>();// 创建一个映射,用于存储每个节点的键列表Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<>();// 遍历所有的键for (String key : keys) {// 使用CRC16本地计算每个键的slotint slot = JedisClusterCRC16.getSlot(key);// 通过JedisCluster本地slot->node映射获取slot对应的nodeJedisPool jedisPool = jedisCluster.getConnectionHandler().getJedisPoolFromSlot(slot);// 将键归档到对应的节点if (nodeKeyListMap.containsKey(jedisPool)) {nodeKeyListMap.get(jedisPool).add(key);} else {List<String> list = new ArrayList<>();list.add(key);nodeKeyListMap.put(jedisPool, list);}}// 从每个节点上批量获取值for (Map.Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {JedisPool jedisPool = entry.getKey();List<String> nodeKeyList = entry.getValue();// 将键列表转换为数组String[] nodeKeyArray = nodeKeyList.toArray(new String[0]);// 批量获取值List<String> nodeValueList = jedisPool.getResource().mget(nodeKeyArray);// 将获取到的值归档到结果映射中for (int i = 0; i < nodeKeyList.size(); i++) {keyValueMap.put(nodeKeyList.get(i), nodeValueList.get(i));}}// 返回结果映射return keyValueMap;
}5.4 并行IO
此方案是将串行IO方案的最后一步改为多线程执行,网络次数虽然还是节点个数,但是多线程并行执行,所以网络时间变成O(1)
操作时间 = max_slow(node网络时间) + n次命令时间

下面是客户端操作的示例:
public Map<String, String> serialIOMget(List<String> keys) {// 创建一个用于存储结果的键值对映射Map<String, String> keyValueMap = new ConcurrentHashMap<>();// 创建一个映射,用于存储每个节点的键列表Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<>();// ... 和前面一样// 多线程mget,最终汇总结果。for (Map.Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {// 多线程实现}return keyValueMap;
}
5.5 hash_tag
Redis Cluster默认使用CRC16算法对key进行哈希,然后对16834取模,得出一个哈希槽,每个节点负责一部分哈希槽,这样就可以将数据分散到各个节点上。
但是这种方式业务无关的,也就是同一个业务的key可能会被分散到不同的Redis节点上,为了解决这个问题,可以使用Redis Cluster的{hash_tag}功能。
{hash_tag}的工作原理是,如果一个key中包含{…},那么基于哈希槽的计算只将基于大括号内的字符串。例如,对于key user:{1001}:name和user:{1001}:age,因为1001是相同的,所以这两个key会被映射到同一个节点上。


使用hash_tag功能,可以将多个业务相关的key强制分配到一个节点上。
操作时间 = 1次网络时间 + n次命令时间

客户端代码示例如下:
List<String> hashTagMget (String[ ] hashTagKeys) {return jedisCluster.mget (hashTagKeys) ;
}
5.5 几种批量操作方案对比
| 方案 | 优点 | 缺点 | 网路IO |
|---|---|---|---|
| 串行命令 | 1)编程简单 2)如果少量keys,性能可以满足要求 | 大量keys请求延迟严重 | O(keys) |
| 串行IO | 1)编程简单 2)少量节点,性能满足要求 | 大量node延迟严重 | O(nodes) |
| 并行IO | 利用并行特性,延迟取决于最慢的节点 | 1)编程复杂 2)由于多线程,问题定位可能较难 | O(max_slow(nodes)) |
| hash_tag | 性能最高 | 1)业务维护成本较高 2)容易出现数据倾斜 | O(1) |
6 缓存雪崩问题优化
6.1 什么是缓存雪崩问题?
由于缓存层承载了大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是,所有请求都会到达存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
缓存雪崩就是指缓存层宕掉后,流量像雪崩一样,流向存储层。

6.2 保证缓存层服务高可用性
将缓存层设计成高可用的,即使个别节点、个别机器、甚至机房宕掉,依然可以提供服务。
6.3 依赖隔离组件为后端限流并降级
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。
对于并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞在这个资源上,造成整个系统不可用。
降级机制:例如推荐服务中,如果个性化推荐服务不可用,可以降级为补充热点数据,不至于造成前端页面直接开天窗。
隔离:对重要资源,如Redis,MySQL等都进行隔离,让每种资源单独运行在自己的线程池中,即使个别资源出现了问题,对其它服务没有影响。
6.4 提前演练
在项目上线前,演练缓存层宕掉后,应用以及后端负载情况以及可能出现的问题,在此基础上做一些预案设定。
7 热点key重建问题优化
7.1 什么是热点key重建问题?
开发人员使用 缓存 + 过期时间 的策略可以加速数据读写,又保证数据定期更新,这种模式基本能满足绝大多部分需求。但是两个问题如果同时存在就会带来热点Key重建问题:
- 当前key是一个热点key,并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂的计算。
当这个key失效瞬间,由于其是一个热点key,会有大量线程涌入到缓存层获取该key的value,但是key已经失效,所以需要重建,此时会有大量的线程来重建缓存,造成后端负载加大,甚至可能让整个应用崩掉。

要解决热点key重建问题也不是很复杂,但是不能为了解决这个问题给系统带来更多麻烦,所以需要制定以下目标:
- 减少重建缓存的次数
- 数据尽可能一致
- 较少的潜在危险
7.2 互斥锁
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,然后重新从缓存中获取数据即可。

客户端代码示例:
String get(String key) {// 从 Redis 中获取数据String value = redis.get(key);// 如果 value 为空,则开始重构缓存if (value == null) {// 只允许一个线程重构缓存,使用 nx 并设置过期时间 exString mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写 Redis,并设置过期时间redis.setex(key, timeout, value);// 删除 key mutexredis.delete(mutexKey);} else {// 其他线程休息 50 毫秒后重试Thread.sleep(50);get(key);}}return value;
}为什么 nx 参数可以当作互斥锁?
有两点原因,首先是Redis是单线程架构,意味着任意一个时刻,只有一个命令在执行,如果有多个命令同时要求执行,最终一定是以队列方式排队执行的,其次nx的参数的含义是如果这个key不存在才可以设置值并返回ok,如果key已经存在,就会返回null,当多个线程同时执行set key value nx 时,最终只有一个线程的命令会执行并返回ok,其余线程都会返回null,这就实现了互斥。
7.3 永远不过期
永远不过期包含两层含义:
- 从缓存层来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是物理上的不过期。
- 从功能上看,为每一个value设置一个逻辑过期的时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
该方法有效地杜绝了热点key产生的问题,唯一的缺点就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。

客户端代码示例如下:
String get(final String key) {V v = redis.get(key);String value = v.getValue();// 逻辑过期时间long logicTimeout = v.getLogicTimeout();// 如果逻辑过期时间小于当前时间,开始后台构建if (logicTimeout <= System.currentTimeMillis()) {String mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 重构缓存threadPool.execute(new Runnable() {public void run() {String dbValue = db.get(key);redis.set(key, dbValue, newLogicTimeout);redis.delete(mutexKey);}});}}return value;
}7.4 两种方案比较
作为一个并发量较大的应用,在使用缓存时有三个目标:
- 加快用户访问速度,提高用户体验。
- 降低后端负载,减少潜在的风险,保证系统的平稳。
- 保证数据“进可能”及时更新。
下面就这三个维度来比较互斥锁方案与永远不过期方案:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 简单分布式锁 | ●思路简单 ●保证一致性 | ●代码复杂性增大 ●存在死锁的风险 ●存在线程池阻塞的风险 |
| 永远不过期 | 基本杜绝热点key问题 | ●不保证一致性 ●逻辑过期时间增加代码维护成本和内存成本 |

![IntelliJ IDEA 2024.1安装与激活[破解]](https://img-blog.csdnimg.cn/direct/83568bf7104948a6ad8af14f28e9903d.png)







![[网鼎杯 2020 玄武组]SSRFMe](https://img-blog.csdnimg.cn/img_convert/469e239ae679d5676a8672d61bbbf32f.png)