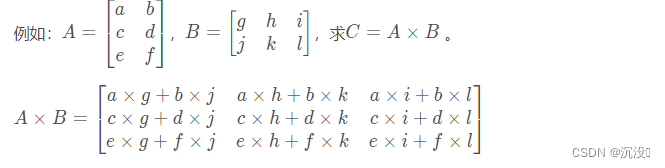前言
存储可分为文件存储和对象存储,常见的文件存储相关技术有:nfs、lvm、raid;常见的对象存储相关技术有:gfs、ceph、fdfs、nas、oss、s3、switch。GlusterFS 归类为文件存储系统,它提供了一种强大的方式来管理和存储海量数据,提供构建高效、可靠的存储解决方案。本文将通过 GlusterFS 分布式文件系统的特点、工作原理以及实际应用展开介绍。
目录
一、GFS 介绍
1. 概述
2. 特点
3. GFS 专业术语
3.1 Brick(存储块)
3.2 Volume(逻辑卷)
3.3 FUSE(本地文件系统)
3.4 VFS(虚拟接口)
3.5 Glusterd(后台管理进程)
4. GFS 架构
5. 工作原理流程
6. 弹性 hash 算法
7. 卷的类型
7.1 分布式卷
7.2 条带卷
7.3 复制卷
7.4 分布式条带卷
7.5 分布式复制卷
7.6 条带复制卷
7.7 分布式条带复制卷
二、本地源部署 GlusterFS
1. 添加磁盘、分区并挂载
2. 安装、启动 GlusterFS
3. 添加节点到存储信任池中
4. 创建卷
4.1 创建分布式卷
4.2 创建条带卷
4.3 创建复制卷
4.4 创建分布式条带卷
4.5 创建分布式复制卷
4.6 查看当前所有卷的列表
5. 部署 Gluster 客户端
5.1 安装客户端软件
5.2 创建挂载目录
5.3 配置 /etc/hosts 文件
5.4 挂载 Gluster 文件系统
6. 客户端测试 Gluster 文件系统
7. 查看文件分布
7.1 查看分布式文件分布
7.2 查看条带卷文件分布
7.3 查看复制卷分布
7.4 查看分布式条带卷分布
7.5 查看分布式复制卷分布
7.6 创建查看分布式复制卷分布(四路复制卷)
8. 破坏性测试
8.1 模拟 node2 节点故障
9. 小结
三、网络源部署 GlusterFS
四、一般故障问题
一、GFS 介绍
1. 概述
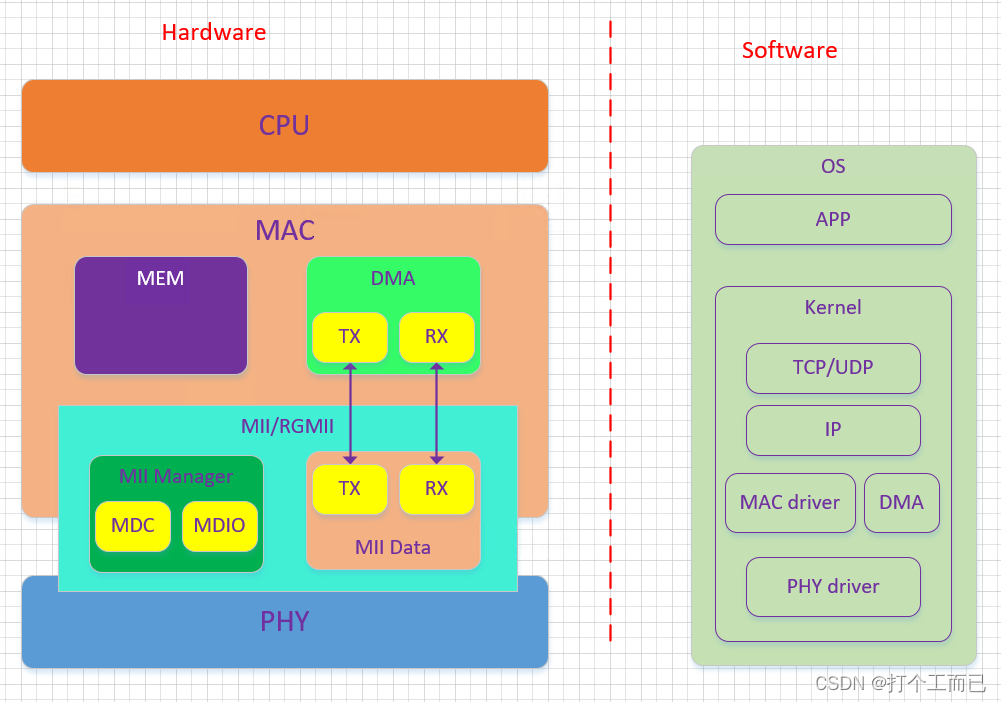
GlusterFS 是一个开源的分布式文件系统,是一个扩展存储容器,提高性能并且可以通过多个互联网络的存储节点进行数据冗余,以确保数据的可用性和一致性。由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成;是无元数服务器(是一种存储系统,保存数据的地方),通过分布式存储元数据信息,提高了系统的可靠性、性能和扩展性,适用于需要高度并行和可靠性的存储环境。
2. 特点
① 扩展性和高性能(分布式的特性)
② 高可用(冗余、有容灾能力,相当于备份)
③ 全局统一命名空间(单独的空间)
④ 弹性卷管理(raid或lvm逻辑卷)
⑤ 基于标准协议,支持一些协议,如:http、ftp、nfs等
3. GFS 专业术语
3.1 Brick(存储块)
每个 Brick 相当于单独的服务器,是 GFS 中的基本存储单元、存储池中服务器上对外提供的存储目录。存储目录的格式由服务器和目录的绝对路径构成,如:192.168.190.100:/directory。客户端可以通过挂载该目录达到访问数据的目的。
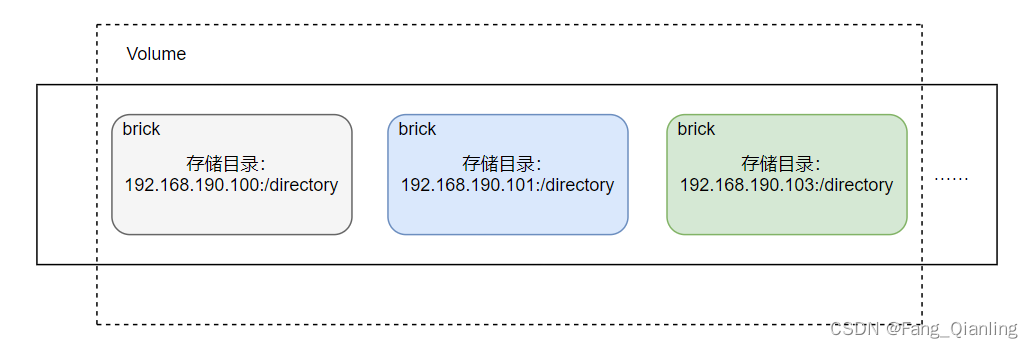
3.2 Volume(逻辑卷)
一个逻辑卷是一组 Brick 的集合,卷是数据存储的逻辑设备,类似于 LVM 中的逻辑卷。
3.3 FUSE(本地文件系统)
通过 GFS 转换,是一个内核模块,允许用户创建自己的文件系统,是一个伪文件系统。在 GFS 中,FUSE 用于将 GFS 卷挂载到用户空间,使其在用户空间可访问。
3.4 VFS(虚拟接口)
内核空间对用户空间提供的访问磁盘的接口。在 GFS 中,VFS 提供了一个统一的接口,使应用程序可以访问和操作 GlusterFS 文件系统。
3.5 Glusterd(后台管理进程)
Glusterd 是 GlusterFS 的管理守护进程,负责管理 GlusterFS 集群的配置、卷的创建和维护等任务。Glusterd 通过与其他 GlusterFS 节点通信来确保集群的正常运行。
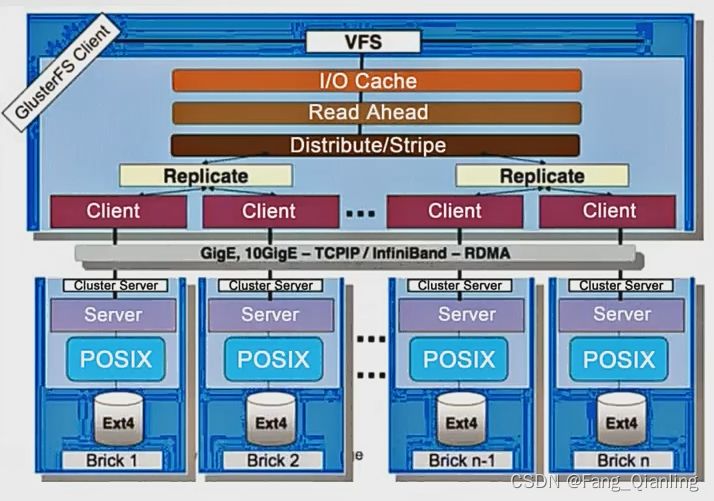
4. GFS 架构
- 模块化、堆栈式的架构
- 通过对模块的组合,实现复杂的功能
5. 工作原理流程
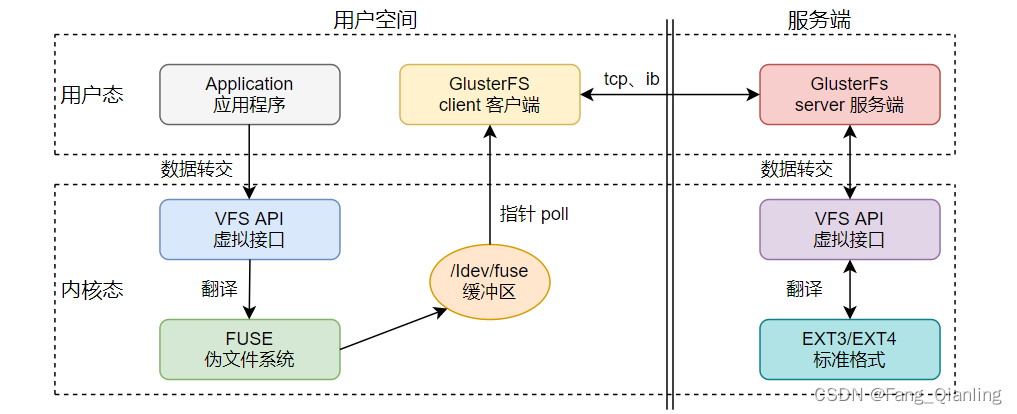
① 客户端或应用程序通过 Glusterfs 的挂载点访问数据,Linux 系统内核通过 VFS API(虚拟接口)收到请求并处理
② VFS 将数据翻译传递给 FUSE(内核文件系统,伪文件系统),FUSE 文件系统将数据通过内存缓冲区 /dev/fuse 传递给 GlusterFS 客户端。注意:FUSE 无法直接传输,需要通过设备文件进行传输
③ 当数据存在内存中,可以通过指针系统调用 poll 指向客户端地址
④ GlusterFS 客户端收到数据后,根据配置文件的配置对数据进行处理
⑤ 然后通过网络协议,如:tcp,传给远端 GlusterFS 服务端,并且将数据写入到存储设备上
⑥ GlusterFS 服务端同样通过 VFS API 将数据翻译成 EXT3 标准文件系统格式,最后存储到相应的目录
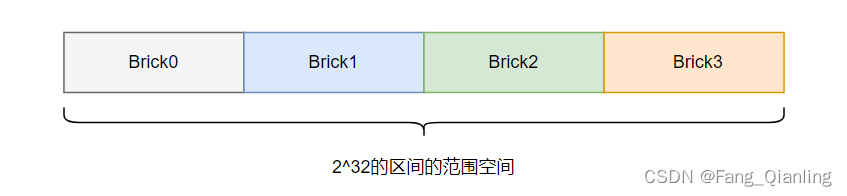
6. 弹性 hash 算法
弹性 HASH 算法是 Davies-Meyer 算法的具体实现,通过 HASH 算法可以得到一个 32 位的整数范围的 hash 值。将逻辑卷划分成 N 个连续的空间(例如一根绳子切割成 N 段),每个空间对应一个 Brick(存储块)。当用户或应用程序访问某一个命名空间时,根据对该命名空间计算 HASH 值所对应的 32 位整数空间定位数据所在的 Brick。
弹性 HASH 算法的优点:
- 保证数据平均分布在每一个 Brick 中
- 解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈
例如将四个 Brick 节点的 GlusterFS 卷,平均分配 2^32 的区间的范围空间:
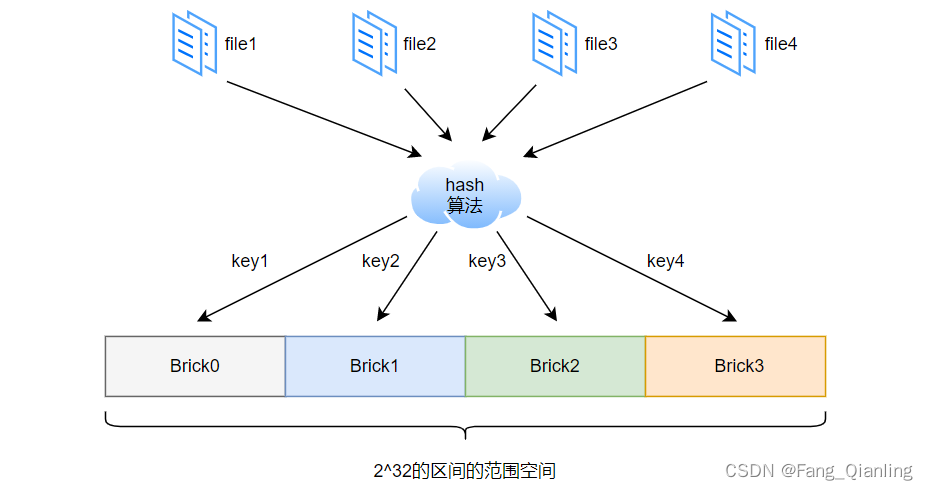
访问文件时,通过计算该文件的 HASH 值,从而对应到 Brick 存储空间:
7. 卷的类型
7.1 分布式卷
文件通过 HASH 算法分布到所有 Brick Server 上,这种卷是 GlusterFS 的默认卷。
- 没有对文件进行分块处理
- 通过扩展文件属性保存HASH值
- 支持的底层文件系统有EXT3、EXT4、ZFS、XFS等
特点:
- 文件分布在不同的服务器,不具备冗余性
- 更容易和廉价地扩展卷的大小
- 单点故障会造成数据丢失
- 依赖底层的数据保护
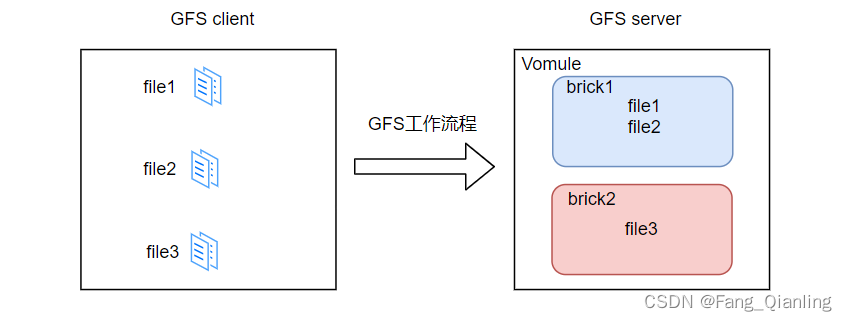
file1 和 file2 存放在 brick1,而 file3 存放在 brick2,文件根据 hash 算法散列存储。 并没有对文件进行分块处理,文件直接存储在某个 Server 节点上,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将不全而丢失。属于文件级的 RAID 0,不具有容错能力。
创建一个名为dis-volume的分布式卷:
文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中:
gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir37.2 条带卷
类似 RAID 0,根据偏移量将文件分成N块(N个条带节点),轮询的存储在每个Brick Server节点,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性。
特点:
- 数据被分割成更小块分布到块服务器群中的不同条带区
- 分布减少了负载且更小的文件加速了存取的速度
- 没有数据冗余

如 file1、file2、file3 分别被分割为两段,第一段放在 brick1,第二段放在 brick2。
创建了一个名为stripe-volume的条带卷:
文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中:
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir27.3 复制卷
将文件同步到多个 Brick 上,使其具备多个文件副本,属于文件级 RAID 1,具有容错能力。因为数据分散在多个 Brick 中,所以读性能得到很大提升,但写性能下降。复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
特点:
- 卷中所有的服务器均保存一个完整的副本
- 卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中 Brick 所包含的存储服务器数
- 至少由两个块服务器或更多服务器
- 具备冗余性
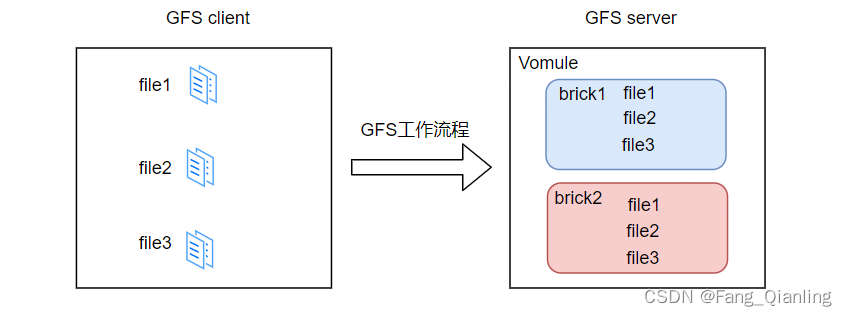
file1、file2、file3同时存在 brick1 和 brick2,相当于 brick2 中的文件是 brick1 中文件的副本。
创建名为rep-volume的复制卷:
文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中:
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir27.4 分布式条带卷
Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。主要用于大文件访问处理,创建一个分布式条带卷最少需要 4 台服务器。
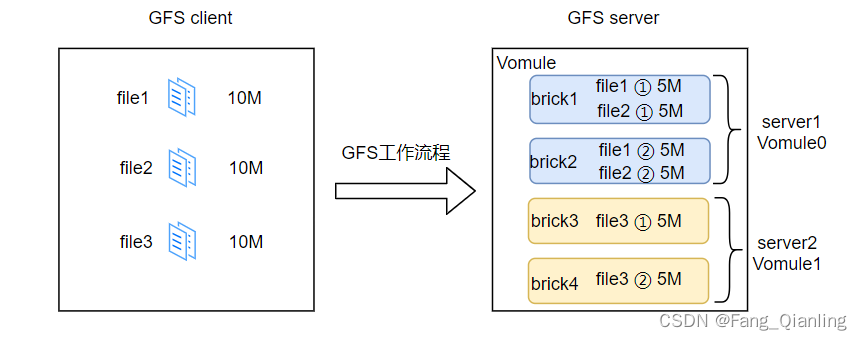
以条带两段为例,file1、file2、file3 通过 hash 算法分布到 Brick Server 上。如 file1、file2 第一段存放在 brick1 中,第二段存放在 brick2 中。同样 file3 第一段存放在 brick3 中,第一段存放在 brick4 中。每段平均分片,但是存储位置需要根据分布式算法分配存储。
创建一个名为dis-stripe的分布式条带卷:
配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick 的数量是 4:(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),条带数为 2(stripe 2)
gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
# 创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷
# 如果存储服务器的数量是条带或复制数的 2 倍甚至更多,那么将创建的是分布式条带卷或分布式复制卷7.5 分布式复制卷
Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点。主要用于需要冗余的情况下。
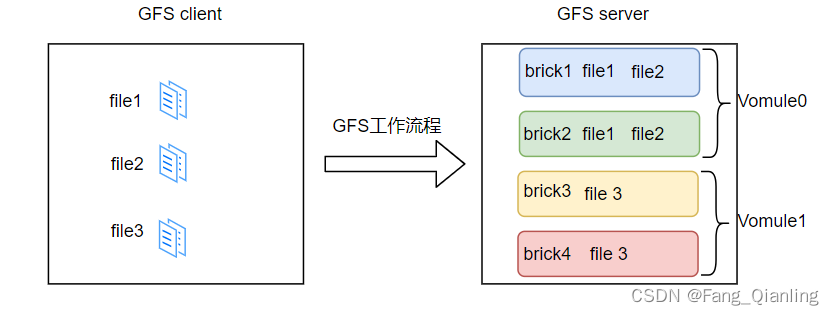
以复制两个不同节点为例。file1、file2、file3 通过 hash 算法分布到 Brick Server 上。如在存放 file1、file2 时,根据复制卷的特性,将存在两个相同的副本,分别是 Vomule0 中的 brick1 和 brick2。在存放 file3 时,根据复制卷的特性,也将存在两个相同的副本,分别是 Vomule1 中的 brick3 和 brick4。
创建一个名为dis-rep的分布式复制卷:
配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick 的数量是 4:(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),复制数为 2(replica 2)
gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir47.6 条带复制卷
类似 RAID 10,同时具有条带卷和复制卷的特点。
7.7 分布式条带复制卷
三种基本卷的复合卷,通常用于类 Map Reduce 应用。
二、本地源部署 GlusterFS
环境准备:关闭防火墙、核心防护
| 节点信息 | 磁盘 | 挂载点 | |
| node1节点 | node1/192.168.190.101 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| node2节点 | node2/192.168.190.102 | ||
| node3节点 | node3/192.168.190.103 | ||
| node4节点 | node4/192.168.190.104 | ||
| 客户端节点 | clinet/192.168.190.100 |
1. 添加磁盘、分区并挂载
① 每个 node 节点分别添加 4 块磁盘

② 重新扫描已存在但尚未被识别的设备
[root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host0/scan # 触发 host0 上的 SCSI 总线扫描
[root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host1/scan # 触发 host1 上的 SCSI 总线扫描
[root@node1 ~]# echo "- - -" > /sys/class/scsi_host/host2/scan # 触发 host2 上的 SCSI 总线扫描
# 在运行时向系统通知有新的 SCSI 设备被添加,或者用于重新扫描已存在但尚未被识别的设备③ 编写脚本进行磁盘分区,并挂载
[root@node1 ~]# vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
# 列出所有的 /dev/sd* 设备,并使用 grep 过滤出字母为 b 到 z 的设备,然后使用 uniq 命令去重,将结果保存在 NEWDEV 变量中
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
# 使用 fdisk 命令对设备进行分区,这里通过输入 n 创建新分区,p 选择主分区,多次回车确认默认选项,最后输入 w 保存并退出mkfs.xfs /dev/${VAR}"1" &> /dev/null
# 使用 mkfs.xfs 命令对新创建的分区进行 XFS 文件系统格式化mkdir -p /data/${VAR}"1" &> /dev/null
# 创建挂载点 /data/${VAR}1echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
# 将新分区信息追加到 /etc/fstab 文件中,实现开机自动挂载
done
[root@node1 ~]# chmod +x /opt/fdisk.sh
[root@node1 ~]# /opt/fdisk.sh
[root@node1 ~]# lsblk # 列出块设备的信息
sdb 8:16 0 1G 0 disk
└─sdb1 8:17 0 1023M 0 part
sdc 8:32 0 1G 0 disk
└─sdc1 8:33 0 1023M 0 part
sdd 8:48 0 1G 0 disk
└─sdd1 8:49 0 1023M 0 part
sde 8:64 0 1G 0 disk
└─sde1 8:65 0 1023M 0 part
[root@node1 ~]# mount -a &> /dev/null # 挂载所有在 /etc/fstab 中定义的文件系统
[root@node1 ~]# df -Th # 显示文件系统的磁盘使用情况
/dev/sdb1 xfs 1020M 33M 988M 4% /data/sdb1
/dev/sdc1 xfs 1020M 33M 988M 4% /data/sdc1
/dev/sdd1 xfs 1020M 33M 988M 4% /data/sdd1
/dev/sde1 xfs 1020M 33M 988M 4% /data/sde1
④ 将脚本传输到其他三台 node 节点,执行相同的操作
[root@node1 ~]# echo "192.168.190.101 node1" >> /etc/hosts
[root@node1 ~]# echo "192.168.190.102 node2" >> /etc/hosts
[root@node1 ~]# echo "192.168.190.103 node3" >> /etc/hosts
[root@node1 ~]# echo "192.168.190.104 node4" >> /etc/hosts
# 分别给每台 node 节点添加域名解析,加快传输速度[root@node1 ~]# scp /opt/fdisk.sh node2:/opt/
[root@node1 ~]# scp /opt/fdisk.sh node3:/opt/
[root@node1 ~]# scp /opt/fdisk.sh node4:/opt/
# 分别执行 scan 命令、脚本 /opt/fdisk.sh,并挂载 mount -a &> /dev/null2. 安装、启动 GlusterFS
① 将 gfsrepo 软件上传到 /opt 目录下 并解压,在所有 node 节点上操作
[root@node1 opt]# ls
fdisk.sh gfsrepo gfsrepo.zip
[root@node1 opt]# unzip gfsrepo.zip
[root@node1 opt]# scp gfsrepo.zip node2:/opt/
[root@node1 opt]# scp gfsrepo.zip node3:/opt/
[root@node1 opt]# scp gfsrepo.zip node4:/opt/② 配置本地 yum 源
[root@node1 ~]# cd /etc/yum.repos.d/
[root@node1 yum.repos.d]# mkdir repo.bak
[root@node1 yum.repos.d]# mv *.repo repo.bak
[root@node1 yum.repos.d]# tee glfs.repo <<eof # 多行重定向
> [glfs]
> name=glfs
> baseurl=file:///opt/gfsrepo
> gpgcheck=0
> enabled=1
> eof
[root@node1 yum.repos.d]# yum clean all # 清理所有仓库的缓存数据,包括软件包和元数据
[root@node1 yum.repos.d]# yum makecache # 重新生成所有已启用仓库的元数据③ 卸载旧版本
[root@node1 yum.repos.d]# yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y
# 移除 GlusterFS 相关的软件包
glusterfs-api.x86_64
# 包含 GlusterFS API 的库和头文件,用于开发 GlusterFS 客户端和服务器的应用程序。
glusterfs-cli.x86_64
# 包含 GlusterFS 命令行管理工具。
glusterfs.x86_64: GlusterFS
# 分布式文件系统的主要软件包。
glusterfs-libs.x86_64
# 包含 GlusterFS 共享库。
glusterfs-client-xlators.x86_64
# 包含 GlusterFS 客户端翻译器。
glusterfs-fuse.x86_64
# 提供了 GlusterFS 的 FUSE 插件,允许将 GlusterFS 挂载为本地文件系统。④ 安装 GlusterFS 及其相关组件
[root@node1 yum.repos.d]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
glusterfs: GlusterFS
# 是一个开源、分布式的文件系统,它可以将多台服务器上的存储资源汇聚起来,提供统一的命名空间和数据复制
glusterfs-server
# 这是 GlusterFS 的服务器端软件包,用于配置和管理 GlusterFS 存储卷。
glusterfs-fuse
# 该软件包提供了 GlusterFS 的 FUSE(Filesystem in Userspace)插件,允许将 GlusterFS 挂载为本地文件系统。
glusterfs-rdma
# 这是 GlusterFS 的 RDMA 支持组件,可用于提高网络性能。⑤ 立刻启动并设置开机启动
[root@node1 yum.repos.d]# systemctl start --now enable glusterd.service
[root@node1 yum.repos.d]# systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system serverLoaded: loaded (/usr/lib/systemd/system/glusterd.service; disabled; vendor preset: disabled)Active: active (running) since 二 2024-04-09 15:19:18 CST; 12s ago
其他节点均重复以上操作。
3. 添加节点到存储信任池中
将节点添加到 GlusterFS 存储信任池中是为了确保数据的一致性和可靠性。在 GlusterFS 中,存储池是由多个存储节点组成的集合。这里只需在 node1 节点上操作即可。
[root@node1 ~]# gluster peer probe node2
# 尝试与 "node2" 建立连接,如果成功,"node2" 将会被添加为 GlusterFS 可信存储池中的一个对等节点
# 在 GlusterFS 中添加一个对等节点允许各个节点相互通信,共享存储资源,并参与数据的复制和分发
[root@node1 ~]# gluster peer probe node3
[root@node1 ~]# gluster peer probe node4在每个 node 节点上查看群集状态:
[root@node1 ~]# gluster peer status
Number of Peers: 3Hostname: node2
Uuid: 6a9c4a75-d4b0-4479-8f80-4d92282b299a
State: Accepted peer request (Connected)Hostname: node3
Uuid: 137314e7-543d-41f8-8336-bada63538a25
State: Accepted peer request (Connected)Hostname: node4
Uuid: 0d2962cb-906c-46f0-b3e7-993c376cbbaf
State: Accepted peer request (Connected)
# 当前节点 "node1" 的对等节点状态,它有三个对等节点,分别是 "node2"、"node3" 和 "node4"。每个对等节点都有一个唯一的 UUID 用于标识4. 创建卷
根据规划创建如下卷:
| 卷名称 | 卷类型 | Brick |
| fenbushi | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| tiaodai | 条带卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| fuzhi | 复制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| fbs-td | 分布式条带卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| fbs-fz | 分布式复制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1) |
4.1 创建分布式卷
创建分布式卷,没有指定类型,默认创建的是分布式卷。
[root@node1 ~]# gluster volume create fenbushi node1:/data/sdb1 node2:/data/sdb1 force
# 在 GlusterFS 中创建一个名为 "fenbushi" 的卷,并将其设置为包含两个节点(node1 和 node2)上的 "/data/sdb1" 路径,"force" 会强制创建卷查看卷列表:
[root@node1 ~]# gluster volume list
fenbushi启动新建分布式卷:
[root@node1 ~]# gluster volume start fenbushi查看创建分布式卷信息:
[root@node1 ~]# gluster volume info fenbushiVolume Name: fenbushi
Type: Distribute
Volume ID: 324b8a6f-985e-4add-8e16-cc880d6ff53d
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
# 创建了一个名为 "fenbushi" 的分布式 GlusterFS 卷
# 该卷包含两个节点(node1 和 node2)上的 "/data/sdb1" 路径,并且当前状态为 "Started"。使用 TCP 作为传输类型4.2 创建条带卷
指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷。
[root@node1 ~]# gluster volume create tiaodai stripe 2 node1:/data/sdc1 node2:/data/sdc1 force[root@node1 ~]# gluster volume start tiaodai[root@node1 ~]# gluster volume info tiaodaiVolume Name: tiaodai
Type: Stripe
Volume ID: 83325709-8fc5-423b-9614-0b231bb8348c
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2 # 表示 volume 由两个存储单元 brick 组成
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdc1
Brick2: node2:/data/sdc1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
# 创建了一个名为 "tiaodai" 的条带化(Stripe)GlusterFS卷
# 该卷包含两个节点(node1 和 node2)上的 "/data/sdc1" 路径,并且当前状态为 "Started"。它使用 TCP 作为传输类型4.3 创建复制卷
指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷。
[root@node1 ~]# gluster volume create fuzhi replica 2 node3:/data/sdb1 node4:/data/sdb1 force[root@node1 ~]# gluster volume start fuzhi[root@node1 ~]# gluster volume info fuzhiVolume Name: fuzhi
Type: Replicate
Volume ID: 3bac2a29-5f10-498f-9bd7-4cc196f7cdb6
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2 # 表示该复制卷由两个存储单元 brick 组成
Transport-type: tcp
Bricks:
Brick1: node3:/data/sdb1
Brick2: node4:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
# 创建了一个名为 "fuzhi" 的复制(Replicate)GlusterFS卷
# 该卷包含两个节点(node3 和 node4)上的 "/data/sdb1" 路径,并且当前状态为 "Started"。它使用 TCP 作为传输类型4.4 创建分布式条带卷
指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷。
[root@node1 ~]# gluster volume create fbs-td stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
# "stripe 2" 意味着数据将会被分割成两份并分布到四个节点的 /data/sdd1 目录上
[root@node1 ~]# gluster volume start fbs-td[root@node1 ~]# gluster volume info fbs-tdVolume Name: fbs-td
Type: Distributed-Stripe
Volume ID: d9eda1ca-a48c-4bfe-9ef8-55d0c409cd8f
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
# 表示会被分割成条带,并且交替的存储在四个 brick 中
# 指卷由两个独立的条带集组成,每个条带集包含2个brick
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdd1
Brick2: node2:/data/sdd1
Brick3: node3:/data/sdd1
Brick4: node4:/data/sdd1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
# 创建了一个名为 "fbs-td" 的分布式条带化(Distributed-Stripe)GlusterFS卷
# 该卷包含四个节点(node1、node2、node3 和 node4)上的 "/data/sdd1" 路径,并且当前状态为 "Started"。它使用 TCP 作为传输类型4.5 创建分布式复制卷
指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷。
[root@node1 ~]# gluster volume create fbs-fz replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
# "replica 2" 表示每个数据块都会被复制到两个不同的节点上
[root@node1 ~]# gluster volume start fbs-fz[root@node1 ~]# gluster volume info fbs-fzVolume Name: fbs-fz
Type: Distributed-Replicate
Volume ID: 7829df2c-8644-467f-a59a-f1e19ce24b05
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4 # 表示每个数据块都会复制到两个存储单元中,有两个这样的组合
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
# 创建了一个名为 "fbs-fz" 的分布式复制(Distributed-Replicate)GlusterFS卷
# 该卷包含四个节点(node1、node2、node3 和 node4)上的 "/data/sde1" 路径,并且当前状态为 "Started"。它使用 TCP 作为传输类型4.6 查看当前所有卷的列表
[root@node1 ~]# gluster volume list
fbs-fz
fbs-td
fenbushi
fuzhi
tiaodai
5. 部署 Gluster 客户端
5.1 安装客户端软件
① 将 gfsrepo 软件上传到 /opt 目下,并解压
[root@client opt]# ls
gfsrepo.zip rh
[root@client opt]# unzip gfsrepo.zip
② 配置本地 yum 源
[root@client opt]# cd /etc/yum.repos.d/
[root@client yum.repos.d]# mkdir repo.bak
[root@client yum.repos.d]# mv *.repo repo.bak
[root@client yum.repos.d]# tee glfs.repo <<eof
> [glfs]
> name=glfs
> baseurl=file:///opt/gfsrepo
> gpgcheck=0
> enabled=1
> eof
[root@client yum.repos.d]# yum clean all && yum makecache③ 安装 GlusterFS 及其 FUSE 用户空间工具
[root@client yum.repos.d]# yum install -y glusterfs glusterfs-fuse5.2 创建挂载目录
[root@client ~]# mkdir -p /test/{fenbushi,tiaodai,fuzhi,fbs-td,fbs-fz}
[root@client ~]# ls /test/
fbs-fz fbs-td fenbushi fuzhi tiaodai
5.3 配置 /etc/hosts 文件
[root@client ~]# echo "192.168.190.101 node1" >> /etc/hosts
[root@client ~]# echo "192.168.190.102 node2" >> /etc/hosts
[root@client ~]# echo "192.168.190.103 node3" >> /etc/hosts
[root@client ~]# echo "192.168.190.104 node4" >> /etc/hosts5.4 挂载 Gluster 文件系统
在 GlusterFS 中,当挂载一个分布式卷时,只需要在其中一个节点上进行挂载。这是因 GlusterFS 是一个分布式文件系统,数据会自动在各个节点之间复制和分布。因此,一旦在任何一个节点上挂载了该卷,就能够访问整个 GlusterFS 文件系统的数据,无论数据实际存储在哪个节点上。
临时挂载:
[root@client ~]# mount.glusterfs node1:fenbushi /test/fenbushi/
[root@client ~]# mount.glusterfs node1:tiaodai /test/tiaodai/
[root@client ~]# mount.glusterfs node1:fuzhi /test/fuzhi/
[root@client ~]# mount.glusterfs node1:fbs-td /test/fbs-td/
[root@client ~]# mount.glusterfs node1:fbs-fz /test/fbs-fz/
[root@client ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
node1:fenbushi fuse.glusterfs 2.0G 65M 2.0G 4% /test/fenbushi
node1:tiaodai fuse.glusterfs 2.0G 65M 2.0G 4% /test/tiaodai
node1:fuzhi fuse.glusterfs 1020M 33M 988M 4% /test/fuzhi
node1:fbs-td fuse.glusterfs 4.0G 130M 3.9G 4% /test/fbs-td
node1:fbs-fz fuse.glusterfs 2.0G 65M 2.0G 4% /test/fbs-fz#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
# 当在 /etc/fstab 中指定 _netdev 时,它告诉系统这是一个网络文件系统,并且应该在网络连接可用时进行挂载。这样可以确保系统在启动时不会因为尝试挂载网络文件系统而出现延迟。
mount -a6. 客户端测试 Gluster 文件系统
[root@client ~]# cd /opt
生成文件:
[root@client opt]# dd if=/dev/zero of=/opt/demo1.log bs=1M count=4
[root@client opt]# dd if=/dev/zero of=/opt/demo2.log bs=1M count=4
[root@client opt]# dd if=/dev/zero of=/opt/demo3.log bs=1M count=4
[root@client opt]# dd if=/dev/zero of=/opt/demo4.log bs=1M count=4
[root@client opt]# dd if=/dev/zero of=/opt/demo5.log bs=1M count=4
# 使用 dd 工具从 /dev/zero 设备创建了一个名为 demo1.log 的文件,文件大小为 4MB
# bs=1M 指定每次读写的块大小为 1MB,count=4 指定要复制的块数[root@client opt]# ll -h /opt
-rw-r--r--. 1 root root 4.0M 4月 9 17:13 demo1.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:13 demo2.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:13 demo3.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:13 demo4.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:13 demo5.log复制文件至挂载点:
[root@client opt]# cp /opt/demo* /test/fenbushi/
[root@client opt]# cp /opt/demo* /test/tiaodai/
[root@client opt]# cp /opt/demo* /test/fuzhi/
[root@client opt]# cp /opt/demo* /test/fbs-td/
[root@client opt]# cp /opt/demo* /test/fbs-fz/
7. 查看文件分布
7.1 查看分布式文件分布
[root@node1 ~]# ll -h /data/sdb1
总用量 16M
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo4.log
[root@node2 ~]# ll -h /data/sdb1
总用量 4.0M
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo5.log
# 数据没有被分片,根据 hash 存放7.2 查看条带卷文件分布
[root@node1 ~]# ll -h /data/sdc1
总用量 10M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo4.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo5.log
# 数据被分片 50% 没副本 没冗余
[root@node2 ~]# ll -h /data/sdc1
总用量 10M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo4.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo5.log
# 数据被分片 50% 没副本 没冗余7.3 查看复制卷分布
[root@node3 ~]# ll -h /data/sdb1
总用量 20M
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo4.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo5.log
# 数据没有被分片 有副本 有冗余
[root@node4 ~]# ll -h /data/sdb1
总用量 20M
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo4.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:24 demo5.log
# 数据没有被分片 有副本 有冗余7.4 查看分布式条带卷分布
[root@node1 ~]# ll -h /data/sdd1
总用量 8.0M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo4.log
[root@node2 ~]# ll -h /data/sdd1
总用量 8.0M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo1.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo2.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo3.log
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo4.log
[root@node3 ~]# ll -h /data/sdd1
总用量 2.0M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo5.log
[root@node4 ~]# ll -h /data/sdd1
总用量 2.0M
-rw-r--r--. 2 root root 2.0M 4月 9 17:24 demo5.log
# 数据被分片 50% 没副本 没冗余,根据 hash 存放如果创建分布式条带卷,指定类型为 stripe,数值为 4,而且后面跟了 4 个 Brick Server,即:Number of Bricks: 1 x 4 = 4。查看的卷分布情况就会为:每个 brick 中都会存放每个文件的1/4块数据。如 node1 文件分部情况(其他几个一样):
[root@node2 ~]# ll -h /data/sdd1
总用量 5.0M
-rw-r--r--. 2 root root 1.0M 4月 10 13:07 demo1.log
-rw-r--r--. 2 root root 1.0M 4月 10 13:07 demo2.log
-rw-r--r--. 2 root root 1.0M 4月 10 13:07 demo3.log
-rw-r--r--. 2 root root 1.0M 4月 10 13:07 demo4.log
-rw-r--r--. 2 root root 1.0M 4月 10 13:07 demo5.log
7.5 查看分布式复制卷分布
[root@node1 ~]# ll -h /data/sde1
总用量 16M
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo4.log
[root@node2 ~]# ll -h /data/sde1
总用量 16M
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo4.log
[root@node3 ~]# ll -h /data/sde1
总用量 4.0M
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo5.log
[root@node4 ~]# ll -h /data/sde1
总用量 4.0M
-rw-r--r--. 2 root root 4.0M 4月 9 17:25 demo5.log
# 数据没有被分片 有副本 有冗余,根据 hash 存放7.6 创建查看分布式复制卷分布(四路复制卷)
如果创建分布式复制卷,指定类型为 replica,数值为 4,而且后面跟了 4 个 Brick Server,即:Number of Bricks: 1 x 4 = 4。查看的卷分布情况就会为:复制级别为4,这意味着将在提供的节点上创建一个四路复制卷,所有写入的数据都会在四个brick(节点上的指定目录)上保持一致。
[root@node1 ~]# gluster volume stop fbs-fz # 停止卷
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: fbs-fz: success
[root@node1 ~]# gluster volume delete fbs-fz # 删除卷
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: fbs-fz: success[root@node1 ~]# gluster volume create fbs-fz replica 4 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
# 指定卷的类型为"replica",并且设置复制级别为4。这意味着将在提供的节点上创建一个四路复制卷,所有写入的数据都会在四个brick(节点上的指定目录)上保持一致[root@node1 ~]# gluster volume info fbs-fz # 查看卷信息
Volume Name: fbs-fz
Type: Replicate
Volume ID: 4001ffb1-0d68-41dd-b59a-67a5d2ebdb7e
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 4 = 4
# 表示卷被配置为一个具有4个brick的复制集。虽然通常在描述条带卷时使用这种格式,但在复制卷中,这意味着这4个brick形成了一个完整的复制组,数据在所有brick上都有完全相同的副本。
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on客户端重新挂载、重新复制文件:
[root@localhost ~]# umount /test/fbs-fz/
[root@localhost ~]# mount.glusterfs node1:fbs-fz /test/fbs-fz/
[root@localhost ~]# cp /opt/demo* /test/fbs-fz/
cp:是否覆盖"/test/fbs-fz/demo1.log"? y
cp:是否覆盖"/test/fbs-fz/demo2.log"? y
cp:是否覆盖"/test/fbs-fz/demo3.log"? y
cp:是否覆盖"/test/fbs-fz/demo4.log"? y
cp:是否覆盖"/test/fbs-fz/demo5.log"? y再次查看4台node节点文件分布情况,可以看到四个brick(节点上的指定目录)上数据保持一致,以node1为例:
[root@node1 ~]# ll -h /data/sde1
总用量 21M
-rw-r--r--. 2 root root 4.0M 4月 10 13:35 demo1.log
-rw-r--r--. 2 root root 4.0M 4月 10 13:35 demo2.log
-rw-r--r--. 2 root root 4.0M 4月 10 13:35 demo3.log
-rw-r--r--. 2 root root 4.0M 4月 10 13:35 demo4.log
-rw-r--r--. 2 root root 4.0M 4月 10 13:35 demo5.log
8. 破坏性测试
8.1 模拟 node2 节点故障
挂起 node2 节点来模拟故障,在客户端上查看文件是否正常:
注意:即使关闭了 GlusterFS 服务器上的 glusterd 服务,客户端仍然可以访问文件,这是因为 GlusterFS 是一个分布式文件系统。一旦文件被存储在 GlusterFS 卷中,它们就会被复制到多个节点上。因此,即使其中一个节点上的服务停止运行,其他节点上的服务仍然可以提供文件访问和读取功能。
① 分布式卷数据查看
[root@client ~]# ll /test/fenbushi/
总用量 16384
-rw-r--r--. 1 root root 4194304 4月 9 17:24 demo1.log
-rw-r--r--. 1 root root 4194304 4月 9 17:24 demo2.log
-rw-r--r--. 1 root root 4194304 4月 9 17:24 demo3.log
-rw-r--r--. 1 root root 4194304 4月 9 17:24 demo4.log
# 少了demo5.log文件,这个是在 node2 上的② 条带卷数据查看
[root@client ~]# ll /test/tiaodai/
总用量 0
# 无法访问,条带卷不具备冗余性③ 分布式复制卷数据查看
[root@client ~]# ll /test/fbs-fz/
总用量 20480
-rw-r--r--. 1 root root 4194304 4月 9 17:25 demo1.log
-rw-r--r--. 1 root root 4194304 4月 9 17:25 demo2.log
-rw-r--r--. 1 root root 4194304 4月 9 17:25 demo3.log
-rw-r--r--. 1 root root 4194304 4月 9 17:25 demo4.log
-rw-r--r--. 1 root root 4194304 4月 9 17:25 demo5.log
# 可以访问,分布式复制卷具备冗余性④ 分布式条带卷数据查看
[root@client ~]# ll /test/fbs-td/
总用量 4096
-rw-r--r--. 1 root root 4194304 4月 9 17:24 demo5.log
# 无法访问,分布条带卷不具备冗余性挂起 node2 和 node4 节点,在客户端上查看文件是否正常:
① 复制卷数据查看
[root@client ~]# ll -h /test/fuzhi/
总用量 20M
-rw-r--r--. 1 root root 4.0M 4月 9 17:24 demo1.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:24 demo2.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:24 demo3.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:24 demo4.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:24 demo5.log
# 在客户机上测试正常 数据有② 分布式条带卷数据查看
[root@client ~]# ll -h /test/fbs-td/
总用量 0
# 在客户机上测试没有数据 ③ 分布式复制卷
[root@client ~]# ll -h /test/fbs-fz/
总用量 20M
-rw-r--r--. 1 root root 4.0M 4月 9 17:25 demo1.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:25 demo2.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:25 demo3.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:25 demo4.log
-rw-r--r--. 1 root root 4.0M 4月 9 17:25 demo5.log
# 在客户机上测试正常 有数据9. 小结
综上:凡是带复制数据,相比而言,数据比较安全。
其他的维护命令:
gluster volume list # 查看GlusterFS卷
gluster volume info # 查看所有卷的信息
gluster volume status # 查看所有卷的状态
gluster volume stop dis-stripe # 停止一个卷
gluster volume delete dis-stripe # 删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功设置卷的访问控制
gluster volume set dis-rep auth.deny 192.168.190.100 #仅拒绝
gluster volume set dis-rep auth.allow 192.168.190.* #仅允许,设置192.168.190.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)三、网络源部署 GlusterFS
GlusterFS 9.6 版本相对于之前的版本存在些许差异:
- 6.0版本后已取消条带卷;分布式条带卷也被取消
- 不需要分区
网络源部署除了安装步骤与本地源存在区别,其他步骤大致一致:
在node01、node02、node03、node04分别安装gfs server端(用yum安装即可)
安装官网源:yum -y install centos-release-gluster
安装服务:yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
如果有报错可能是低版本不能兼容高版本:
yum -y remove glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma四、一般故障问题
主机映射
时间不同步 内网ntp 外网ntpdate
防火墙/增强功能
/etc/hosts 没有同时配置