【1】字典的创建与价值
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构。元素由键和对应的值组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。在 Python 中,字典使用大括号{}来表示,键和值之间使用冒号:进行分隔,多个键值对之间使用逗号,分隔。
列表与字典的表达方式:
# 列表
info_list = ["feiyi", 99, 188, 86]
# 字典: {key : value}
info_dict = {"name": "feiyi", "age": 99, "height": 188, "weight": 86}
print(type(info_dict)) # <class 'dict'>字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。
fei : 飞
yi : 燚
字典的灵魂:
字典是由一个一个的 key-value 构成的,字典通过键而不是通过索引来管理元素。字典的操作都是通过 key 来完成的。
info_dict = {"name": "feiyi", "age": 99, "height": 188, "weight": 86}
print(info_dict["name"])# feiyi【2】字典的存储与特点
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置。
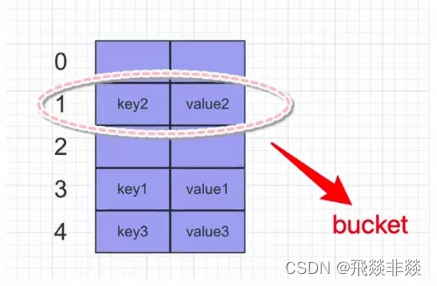
将一对键值放入字典的过程:
先定义一个字典,再写入值:
d = {}
d["name"] = "fei"在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制:
print(bin(hash("name")))结果为:
-0b100000111110010100000010010010010101100010000011001000011010假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即010,十进制是数字2,我们查看偏移量为2对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量011,十进制是数字3,再查看偏移量3的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理。
当进行字典的查询时:
d["name"]
d.get("name") 第一步与存储一样,先计算键的散列值,取出后三位010,十进制为2的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None。
此外,
print(bin(hash("name")))每次执行结果不同:
这是因为 Python 在每次启动时,使用的哈希种子(hash seed)是随机选择的。哈希种子的随机选择是为了增加哈希函数的安全性和防止潜在的哈希碰撞攻击。
字典的特点:
- 无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。通过键来访问和操作字典中的值。
- 键是唯一的且不可变类型对象,用于标识值。值可以是任意类型的对象,如整数、字符串、列表、元组等。
- 可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。