文章目录
- 第7章 用户画像
- 7.1 什么是用户画像
- 7.2 标签系统
- 7.2.1 标签分类方式
- 7.2.2 多渠道获取标签
- 7.2.3 标签体系框架
- 7.3 用户画像数据特征
- 7.3.1 常见的数据形式
- 7.3.2 文本挖掘算法
- 7.3.3 神奇的嵌入表示
- 7.3.4 相似度计算方法
- 7.4 用户画像的应用
- 7.4.1 用户分析
- 7.4.2 精准营销
- 7.4.3 风控领域
- 7.5 思考练习
这本书写的挺好,干货满满。除了课后题,有必要对内容做一下总结。
与文章框架保持一致,基本在抄书……学渣的我……
第7章 用户画像
7.1 什么是用户画像
机器学习中提到的用户画像,通常是基于给定的数据对用户属性、行为进行描述,然后提取个性化指标,再以此分析可能存在的群体共性,并落地应用到各种业务场景中。

7.2 标签系统
用户画像核心:“打标签”,即标签化用户的行为特征。
企业通过标签,分析用户(社会属性、生活习惯、消费行为)===>商业应用
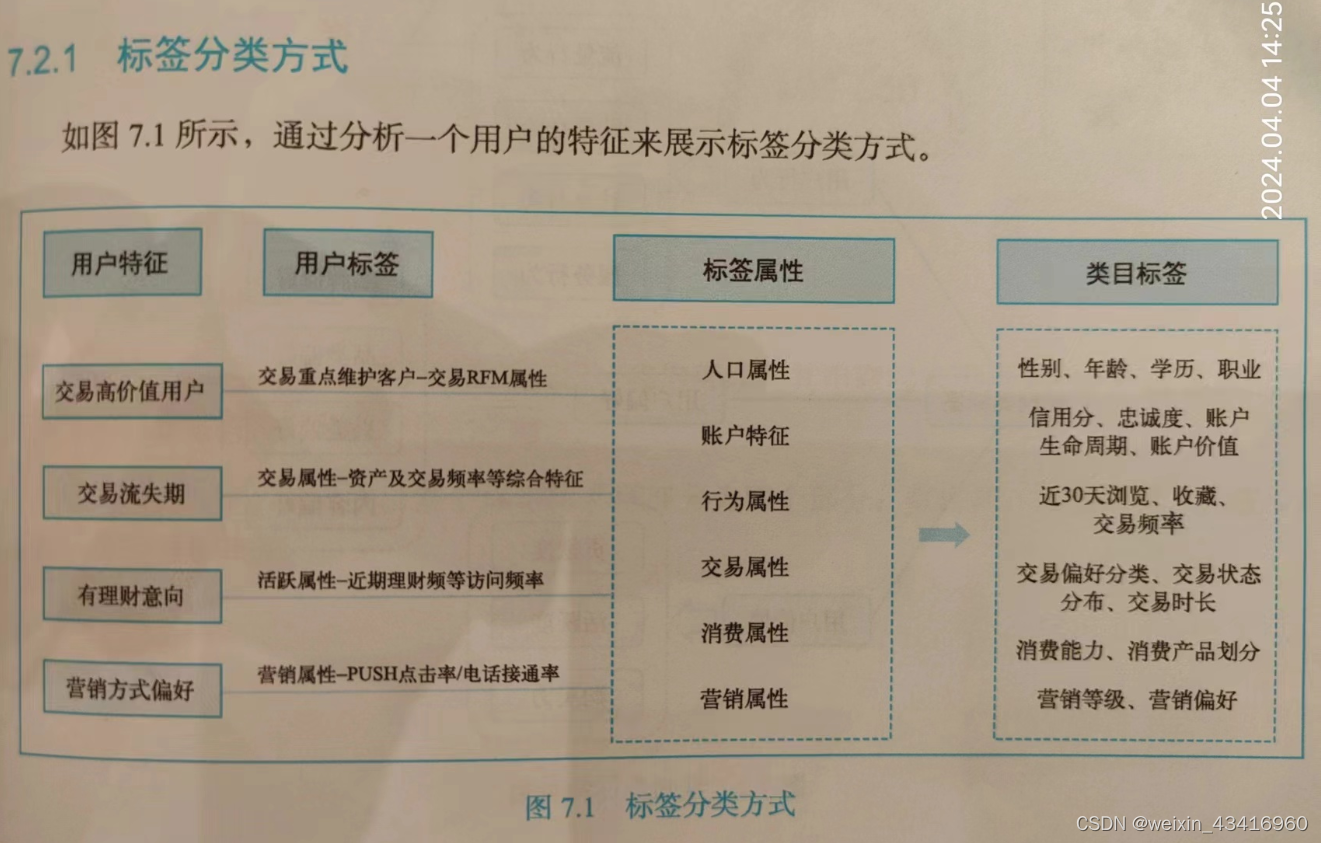
7.2.1 标签分类方式
直接拍了张照片,因为我觉得我画的不如人家的好看,而且还浪费时间。凑合看下,了解即可:
7.2.2 多渠道获取标签
获取标签的渠道主要有三种:事实类标签、规则类标签、模型类标签。
- 事实类标签
来源于:①原始数据:性别、年龄、会员等级。
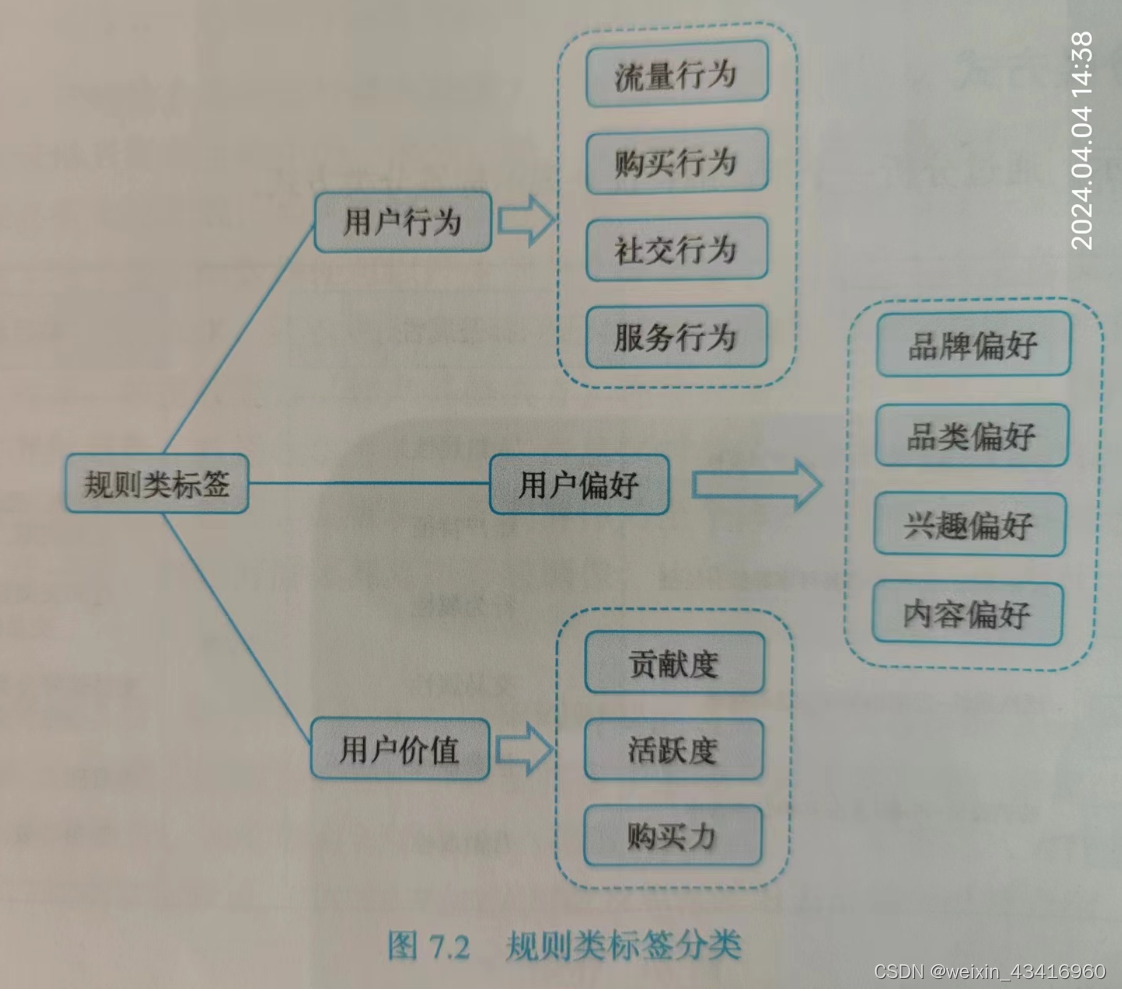
②统计数据:用户行为次数、消费总额。 - 规则类标签
依据是设置的规则。
举例:地域所属、家庭类型、年龄层
比如,所在地在山东,业务规则可以划分为“华北”,也可以是”东部“,也可以是“北方”。根据具体的业务规则会有不同的结 果标签,这就是规则类标签。
规则类标签用到的主要技能是数理统计类知识:基础统计、数值分层、概率分布、均值分析、方差分析等。
- 模型类标签
模型类标签是经过机器学习和深度学习等模型处理后,二次加工生成的洞察性标签。
举例:预测用户状态、预测用户信用分、划分兴趣人群和对评论文本进行分类等。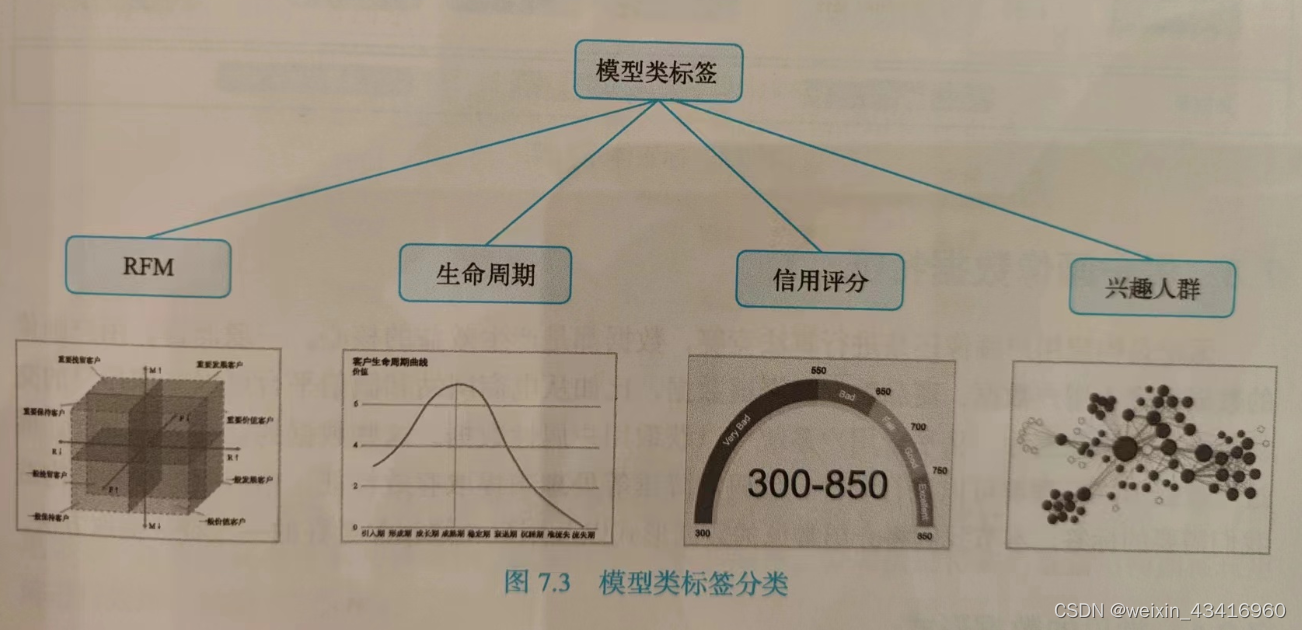
【总结】我的理解
规则类标签,是基于用户历史行为,对用户的行为、偏好、价值做出判断,可以看作依然属于历史范畴。
模型类标签,主要是对用户进行预测,或者文本分类。可以认为是对未来、或者深层次的信息进行加工。===>两个方向:未来、深度。
7.2.3 标签体系框架
包含四个部分:数据源、标签管理、标签层级分类、标签服务赋能。
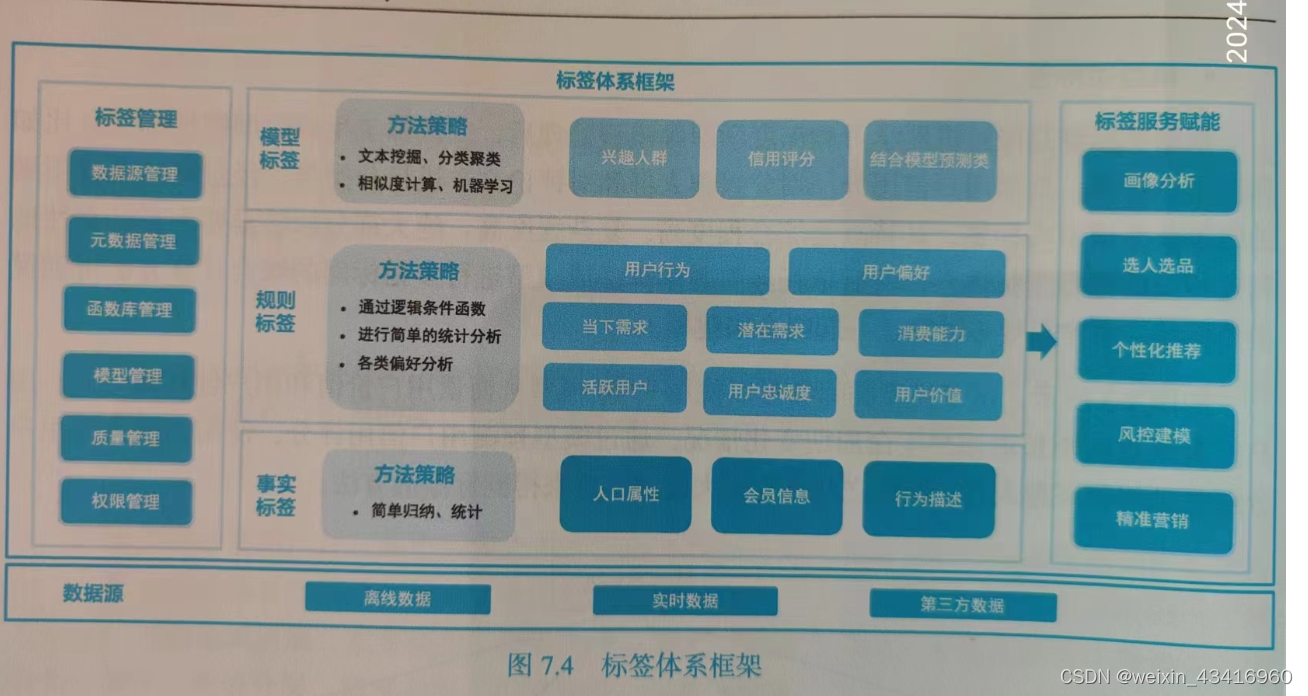
- 数据源:离线、实时、第三方
- 标签管理
- 标签层级分类:上面提到的三种标签,事实类、规则类、模型类。
- 标签服务赋能:画像分析、选人选品、个性化推荐、风控建模、精准营销===>商业落地
7.3 用户画像数据特征
用户画像的数据来源主要有三种:用户数据、商品数据、渠道数据。
可以通过统计、编码、降维提取有效特征===>构造标签
7.3.1 常见的数据形式
四种:数值型变量、类别型变量、多值型变量、文本型变量。
- 数值型变量:年龄、身高、体重、消费金额、流量累计。
- 类别型变量:性别、籍贯、所在城市===>一个用户对应一个结果,结果非数值
- 多值型变量:兴趣爱好、穿衣风格、看过的电影===>一个用户对应多个结果
- 文本型变量:购物评论
7.3.2 文本挖掘算法
对原始数据出现的用户标签集合、购物评价,做基于文本的特征提取,同时预处理、清洗。
用到的文本挖掘算法:LSA、PLSA、LDA。===>无监督学习
- LSA(潜在语义分析)
非概率主题模型
与词向量有关
主要用于文本的话题分析
核心:通过矩阵分解,发现文档与词之间基于话题的语义关系。 - PLSA(概率潜在语义分析)
为克服LSA潜在缺点而提出,通过一个生成模型为LSA赋予概率意义上的解释。
有个假设。 - LDA(潜在狄利克雷分布)
概率主题模型
与词向量无关
典型的词袋模型
7.3.3 神奇的嵌入表示
嵌入表示可以将高维系数特征向量转换成低维稠密特征向量来表示。
- 词嵌入Word2Vec
原理:Word2Vec根据上下文之间的关系训练词向量。
有两种训练模式:Skip-Gram(跳字模型)和CBOW(连续词袋模型)。区别:输入层、输出层不同。
Skip-Gram(跳字模型):输入一个词,预测上下文。
CBOW(连续词袋模型):用一个词的上下文作为输入,预测这个词语本身。 - 图嵌入DeepWalk
包括三个部分:①根据某种序列,把商品关联起来(商品是点,关联是线),
②然后随机游走(random wal),生成商品序列,
③将序列输入到Skip-Gram进行词向量训练。
【总结】我的理解
是否可以理解为,Word2Vec只能做一层Skip-Gram词向量训练,而DeepWalk可以做多层词向量训练。或者说,Word2Vec只能基于一个词,而DeepWalk可以做多个词?
总之它的作用大概就是去掉一些没有用的信息,理解为降维或者浓缩信息。
7.3.4 相似度计算方法
获取用户和商品的嵌入表示、文本的分词表示即各类稀疏表示后,就可以对这些向量表示进行相似度计算了。
基于相似度计算的特征提取方法有:欧氏距离、余弦相似度、Jaccard相似度等===>提取用户、商品、文本的相似度。
广泛应用场景:用户分层聚类、个性化推荐或广告投放。
- 欧氏距离
- 余弦相似度
衡量样本之间的差异。夹角越小,余弦值越接近于1,反之则趋近于-1. - Jaccard相似度
度量两个集合之间的差异大小。
思想:共有元素越多越相似。
7.4 用户画像的应用

7.4.1 用户分析
产品上线之初对目标用户群已有一些定位,但上线之后情况与预期或历史或许存在偏差,需要对拉新、促活、留存、新增用户特征、核心用户属性做分析研究,提炼人群特征,然后不断优化产品性能、UI交互。
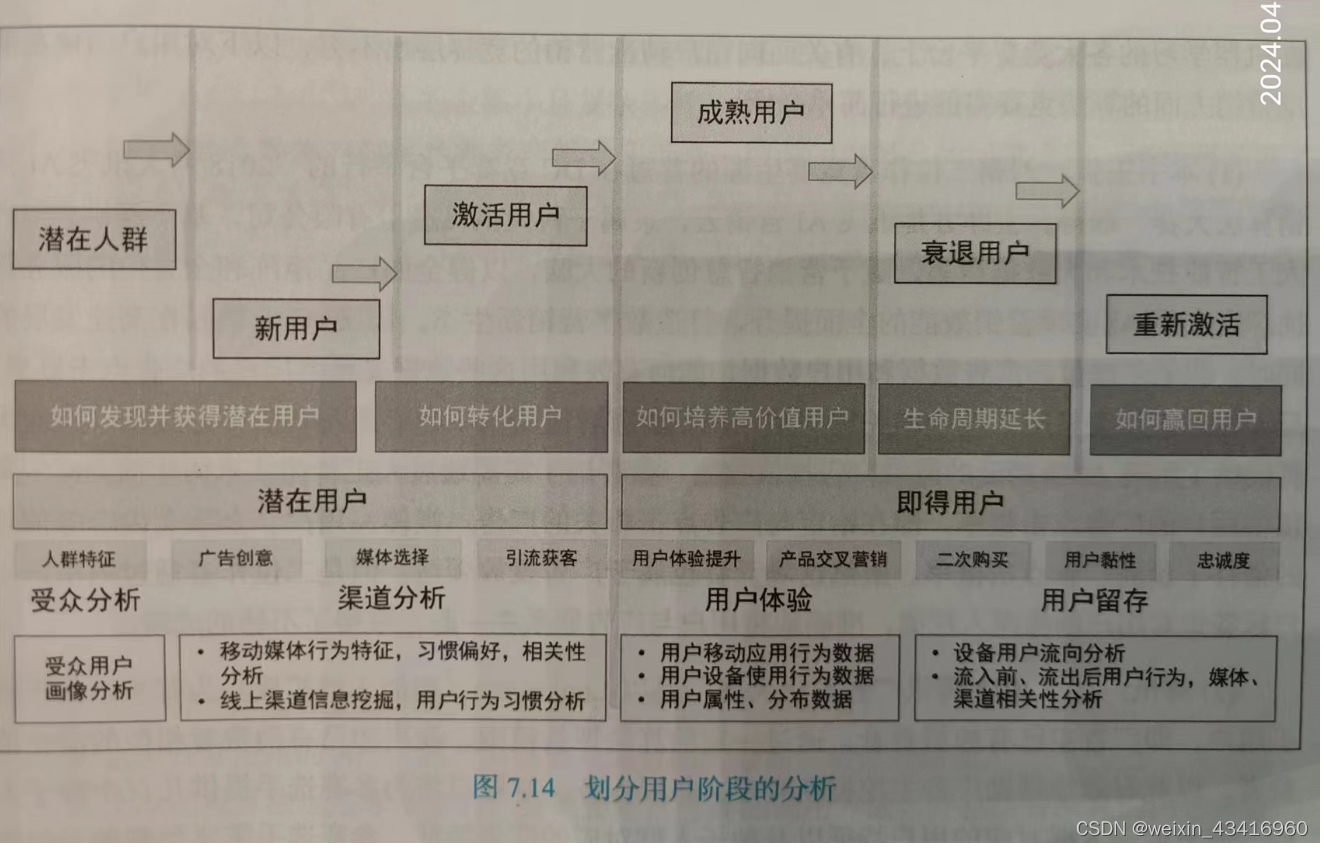 【总结】
【总结】
在用户生命周期的各个阶段,对用户行为属性、群体特点进行研究===>提升产品,压榨用户价值
7.4.2 精准营销
范畴内:推荐系统、广告投放
基于用户历史消费行为,为电商找到种子用户。
7.4.3 风控领域
风控领域的特点:
①解释性高,时效性
②业务关联度高
③负样本占比极少,是均衡学习算法的主战场之一。
【题外话】
金融信贷领域,客户的风险主要来自两方面:还款能力和还款意愿。
还款能力主要考察客户是否有足够的资金,并且按时还款,这就涉及到客户的工资日,工作、学历什么的。
还款意愿,一个是突发因素还不了了,比如失业了,另外一个就是本来贷款的时候就没想过要还,这就涉及到金融领域的反欺诈。
本来之前看了一本书是关于金融风控的,但是那个作者比较缺德的是,没有数据集,书里面只有代码,直接就导入了不知道什么数据集,这怎么搞啊。过分。
7.5 思考练习
见【机器学习】《机器学习算法竞赛实战》思考练习(更新中……)
以上。








![[蓝桥杯 2018 国 C] 迷宫与陷阱](https://img-blog.csdnimg.cn/direct/f9c36066a6754860a49367605dc347b3.png)