2024Mathorcup数学建模挑战赛(妈妈杯)C题保姆级分析完整思路+代码+数据教学
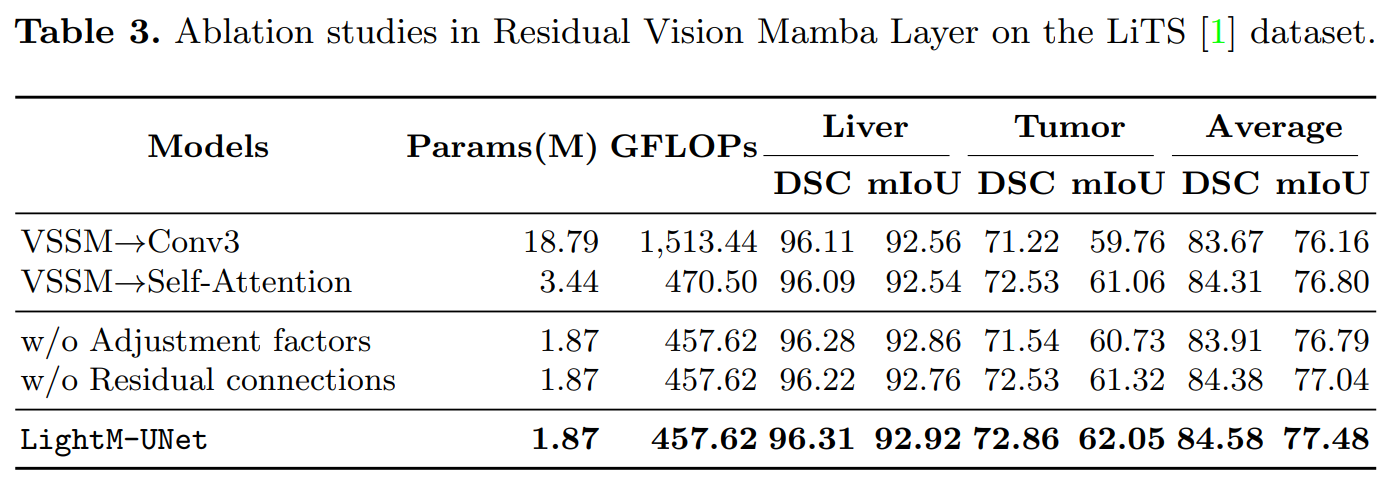
C题题目:物流网络分拣中心货量预测及人员排班
接下来我们将按照题目总体分析-背景分析-各小问分析的形式来
总体分析:题目要求我们处理的是一个关于物流网络分拣中心的货量预测及人员排班的问题。具体分析和解决这个问题,我们需要考虑以下几个步骤:
1 数据理解:首先,我们需要理解各个附件数据(附件1到附件4)。这些数据可能包括历史货量、人员工作时间、工作效率等。
2 问题定义:首先需要对货量进行预测,用来预测未来一段时间内各分拣中心的货物量。并且还需要对人员排班,来判断基于预测的货量,合理安排人员的工作时间,确保高效分拣。
3 方法选择的大致建议:
l 时间序列分析:适用于货量预测。可以使用ARIMA模型、季节性分解、一些机器学习方法(比如随机森林、xgboost)等。
l 优化算法:用于人员排班问题,可能包括线性规划、遗传算法、模拟退火算法等。
l 模型开发:根据选择的方法开发具体的预测和优化模型,这里我比较推荐自己来开发一套特定的方法,大家可能都使用时序分析的算法,如果自己开发一个定制的模型来进行预测,肯定会提高获奖率
4 结果验证:通过交叉验证、历史数据测试等方法验证模型的有效性。
背景分析:对于题目给出的问题背景,我们可以从以下四个角度来分析,将有助于在解决模型当中用到:
1 业务背景:
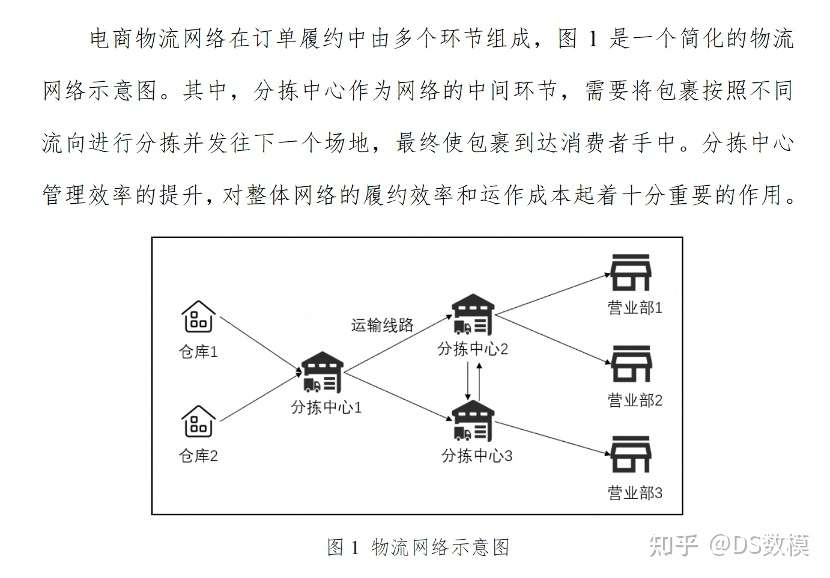
物流分拣中心的角色:分拣中心作为物流网络的关键节点,负责货物的接收、分类、再配送。高效的分拣操作可以显著提高物流效率,降低成本。
货量波动:货物量可能因节假日、促销活动、季节变化等因素而波动。预测这些波动对于资源配置和人员安排至关重要。
技术背景:
2 时间序列预测:货量数据通常呈现时间序列特性,利用历史数据预测未来趋势是常见方法。这可能涉及传统统计方法或现代机器学习技术。
人员排班优化:这是一个典型的运筹学问题,目标是在满足一定条件(如人员成本、工作时间规定等)下,最优化人员的工作排班。
3 问题的复杂性:
多因素影响:货量和人员需求受多种因素影响,如货物类型、处理时间、客户需求等。
动态调整:物流中心的运营状况可能需要根据实时情况进行调整,如应对突发的货物增加或人员缺失。
4 模型应用的目标:
提高预测准确性:准确的货量预测可以帮助提前做好准备,避免资源浪费或短缺。
优化人员利用率:合理的排班计划可以提高员工满意度,降低过度劳累或闲置情况,同时保持或提升工作效率。
这里尤其要注意第3、4点,比如在优化人员利用率中,涉及到确保有足够的员工来处理预期的工作量,同时避免过度人力资源配置或不足。所以可以使用以下方法:
1 整数规划(Integer Programming)
当排班问题需要决策变量为整数时(如人数),整数规划成为一种适用的方法。这比一般的线性规划更难求解,因为它要求解空间是离散的,但它更适合处理排班这种自然要求分配整数资源的问题。
在本题中,可以这样:
在整数规划模型中,每个变量代表特定时间段内分配给特定任务的员工数。目标是最小化总人数或总工时,同时满足类似于员工技能、工作需求和法定工作时间的约束。
2 网络流问题(Network Flow)
网络流问题可以用来解决任务分配问题,其中资源(如人员)必须从一个节点(如时间段或任务类型)流动到另一个节点,而不违反流量守恒规则。
在本题中,可以这样:
通过构建一个网络,其中节点代表工作需求,边代表可以分配的员工流。求解这个网络流问题可以确定如何在满足所有工作需求的同时,最有效地使用员工。
3 遗传算法(Genetic Algorithms)
遗传算法是一种启发式搜索算法,用于解决优化和搜索问题。它模仿自然选择过程,适合解决复杂的优化问题,尤其是当传统的优化方法难以应用或者效果不佳时。
在本题中,可以这样:
定义一个适应度函数来评估排班方案的优劣,如考虑员工满意度、成本和覆盖率等。通过模拟交叉、变异和选择的遗传过程,找到最优或近似最优的排班方案。
4 模拟退火(Simulated Annealing)
模拟退火是另一种启发式搜索技术,通过模拟物理过程中的退火过程来解决优化问题。它允许在搜索过程中做出一定的劣化移动,从而有助于跳出局部最优解,寻找全局最优解。
在本题中,可以这样:
从一个初始解开始,逐渐改变解的结构(如交换员工的班次),在每一步都可能接受一个更差的解,以一定的概率避免陷入局部最优,直至达到系统的“冷却”状态,此时的解接近全局最优。
问题一分析:
针对问题一,也就是建立一套货量预测模型,这里根据前面说的,使用时间序列算法或者自己创建一套模型都是可以的,下面来说一下用时间序列算法该如何做:
现有的时间序列方法分为两种,第一种是传统的统计学方法,第二种是机器学习方法。统计学方法有:(这里要注意的是,如果你一定要用现有的方法,建议使用机器学习方法)
l 移动平均(MA):使用一定数量的历史数据点的平均值来预测未来值。这种方法适用于较为平稳的时间序列。
l 自回归模型(AR):该模型预测未来的值是基于其自身之前的值的线性组合。它假定过去的值对未来值有预测作用。
l 自回归移动平均模型(ARMA):结合自回归和移动平均的特点,适用于平稳的时间序列。
l 自回归积分移动平均模型(ARIMA):适用于非季节性的非平稳时间序列,通过差分将非平稳时间序列转换为平稳时间序列。
l 季节性自回归积分移动平均模型(SARIMA):在ARIMA的基础上加入季节性因素,适用于具有季节性波动的时间序列。
l 指数平滑(Exponential Smoothing):一种权重递减的平滑方法,较新的观察结果比旧的观察结果有更大的权重。Holt-Winters 是这类方法中考虑了趋势和季节性的扩展版本。
机器学习方法有:
l 随机森林(Random Forests):一个集成学习方法,使用多个决策树对时间序列数据进行预测,适用于处理非线性关系。
l 支持向量机(SVM):可用于回归问题(称为SVR),通过映射数据到高维空间来找到最优超平面。
l 神经网络:特别是循环神经网络(RNN)和其变体如长短期记忆网络(LSTM)和门控循环单元(GRU),这些网络特别适用于序列数据,可以捕捉时间序列数据中的长期依赖关系。
l 深度学习方法:如卷积神经网络(CNN)在处理时间序列数据方面也显示出了潜力,特别是在组合使用时(如CNN-LSTM)。
l 集成方法:将多种预测模型的结果组合起来,例如使用随机森林与神经网络的组合,可以提高预测的准确性和鲁棒性。这里推荐xgboost,准确率是比较高的
l 时间序列分解:使用机器学习方法分解时间序列为趋势、季节性和随机成分,然后分别建模预测。
问题二分析:
因为涉及到优化人员排班问题,所以需要更具体地定义问题的参数、目标和约束。根据物流网络分拣中心的背景,我们可以建立一个基于整数规划或其他优化方法的模型:(这里建议大家也可以考虑运筹学中的最小费用流问题)
步骤1: 定义目标
如最小化总成本、最大化覆盖率、或平衡工作负载。
步骤2: 建立数学模型
决策变量:定义表示员工在特定时间段是否工作的变量,通常这些变量为二进制(0或1)。
目标函数:根据问题的目标(如成本最小化),形式化目标函数。
约束条件:
l 需求约束:确保每个时间段的人员数量能满足工作需求。
l 可用性约束:员工的工作时间不能超过其可用时间。
l 合法性约束:遵守相关法律法规,如工作时间和休息时间的规定。
步骤3: 选择适当的求解方法
l 线性/整数规划求解器:如果问题是线性的或可以适当线性化,可以使用如CPLEX、Gurobi等商业求解器。
l 启发式方法:对于规模较大或非线性的复杂问题,可以使用遗传算法、模拟退火、粒子群优化等方法。
步骤4: 实现和求解
编写代码:使用Python、MATLAB或其他编程语言根据选择的算法实现模型。
运行求解程序:输入实际数据,运行求解程序,获取初步解。
验证和调整:检查解的可行性和有效性,必要时调整模型或求解参数。
步骤5: 分析和报告结果
分析优化结果:分析排班计划的效果,将结果填入结果表中。
下面来给大家模拟退火算法做第二问的python代码示例:
概念:模拟退火算法是一种启发式搜索方法,它借鉴了固体物理学中金属退火的过程。通过在搜索过程中引入一定的随机性,模拟退火算法能够在一定程度上避免陷入局部最优解,是解决优化问题,尤其是排班问题的一个有效工具。
第二问Python:
在开始之前,我们需要设置一些基本的参数,如员工列表、班次需求等:
import numpy as np
import random# 设置随机种子以确保结果的可重复性
random.seed(42)
np.random.seed(42)# 定义员工数量和班次需求
num_employees = 10
num_shifts = 3 # 例如:早班、中班、晚班
shifts_requirements = [2, 3, 1] # 每个班次所需的最少员工数# 生成初始解:随机分配员工到各个班次
def generate_initial_solution():solution = np.zeros((num_employees, num_shifts), dtype=int)for i in range(num_employees):shift = random.randint(0, num_shifts-1)solution[i, shift] = 1
return solution目标函数:
def calculate_cost(solution):cost = 0for j in range(num_shifts):# 计算每个班次的人数num_people_in_shift = sum(solution[:, j])# 如果人数少于需求,增加成本if num_people_in_shift < shifts_requirements[j]:cost += (shifts_requirements[j] - num_people_in_shift) ** 2
return cost模拟退火过程:
def simulated_annealing(max_iterations, initial_temp, cooling_rate):current_solution = generate_initial_solution()current_cost = calculate_cost(current_solution)best_solution = current_solutionbest_cost = current_costtemperature = initial_tempfor i in range(max_iterations):for _ in range(100): # 在每个温度下尝试100次不同的邻域解new_solution = np.copy(current_solution)# 随机选择一个员工和一个班次进行调整emp = random.randint(0, num_employees - 1)new_shift = random.randint(0, num_shifts - 1)new_solution[emp, :] = 0new_solution[emp, new_shift] = 1new_cost = calculate_cost(new_solution)cost_diff = new_cost - current_cost# 接受更好的解或者以一定概率接受更差的解if cost_diff < 0 or random.random() < np.exp(-cost_diff / temperature):current_solution = new_solutioncurrent_cost = new_costif current_cost < best_cost:best_solution = current_solutionbest_cost = current_cost# 降低温度temperature *= cooling_ratereturn best_solution, best_cost# 运行模拟退火算法
best_solution, best_cost = simulated_annealing(1000, 100, 0.99)
print("Best Cost:", best_cost)
print("Best Solution:\n", best_solution)问题三、四的思路、代码、成品论文等后续更新,看文末的文章

其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!