LongVLM:让大模型解读长视频 SOTA 的方法
- 使用LongVLM处理长视频的步骤
- LongVLM 方法
- 3.1 总体架构
- 3.2 局部特征聚合
- 3.3 全局语义整合
- 效果
- 4.1 实验设置
- 4.2 主要结果
- 4.3 消融研究
- 4.4 定性结果
论文:https://arxiv.org/pdf/2404.03384.pdf
代码:https://github.com/ziplab/LongVLM
LongVLM是一种高效的长视频理解方法,它通过大型语言模型(LLMs)来增强对长视频的理解。
针对现有VideoLLM在处理长视频时因无法精细理解而面临的挑战,LongVLM采用了一种简单有效的方法,提出了以下解决方案:
具体问题与解法
-
问题1: 处理长视频需要模型能够处理大量的视觉令牌,导致计算成本高昂。
- 解法: 通过预先压缩视觉令牌和利用池化操作或查询聚合来提取视频表示,减少了需要处理的视觉令牌数量。
-
问题2: 现有模型无法精确识别长视频中的细节信息,如特定颜色或正在修理的具体部件。
- 解法: LongVLM通过将长视频分解为多个短期片段,并针对每个片段提取局部特征,以维持故事线的连续性和时间结构。
解法拆解
-
子解法1:均匀采样视频帧和特征提取 使用预训练的视觉编码器(如CLIP-ViT-L/14)提取每帧的视觉特征,包括[CLS]令牌和最后第二层的补丁特征。
- 之所以使用均匀采样和特征提取,是因为这可以有效地从长视频中捕获关键视觉信息,同时降低处理长视频的复杂性。
-
子解法2:局部特征聚合和时间序列维护 通过令牌合并模块将每个短期片段内的补丁特征聚合成一组紧凑的令牌,以获得每个片段的局部特征,并将这些特征按时间顺序连接。
- 之所以采用局部特征聚合和时间序列维护,是因为它们有助于保留长视频中各个短期片段的时间结构,从而实现对视频内容更细致的理解。
-
子解法3:全局语义信息整合 将来自视频帧的[CLS]令牌平均化以代表整个视频的全局语义信息,并将这些全局信息与每个短期片段的特征结合,然后输入到LLM中。
- 之所以整合全局语义信息,是因为它可以丰富对每个短期片段的上下文理解,增强模型对长视频内容的整体把握能力。
主要贡献
- 提出了LongVLM:一种针对长视频内容进行精细级别理解的简单而有效的VideoLLM,同时保持计算成本在可接受范围内。
- 短期片段分解和特征提取:通过将长视频分解为短期片段并提取每个片段的局部特征,LongVLM能够保持这些片段的时间顺序,通过层次化的令牌合并模块聚合视觉令牌,同时将全局语义信息整合到每个片段中,以增强对上下文的理解。
- 在实验中取得显著进展:在VideoChatGPT基准测试和零样本视频问答数据集上的实验结果显示,LongVLM在细粒度水平上为长视频生成的响应比先前的最先进方法更为精确和准确。
LongVLM的提出有效地解决了长视频理解的挑战,其结合局部和全局信息的策略为视频内容理解领域提供了新的视角和方法。
例子背景:假设我们有一个5分钟长的视频,记录了一个手工艺人在工作坊中从头到尾制作一个木制桌子的过程。
这个视频涵盖了多个关键活动,包括选择木材、切割、打磨和组装等。
使用LongVLM处理长视频的步骤
-
均匀采样和特征提取:
- LongVLM首先均匀地从整个视频中采样视频帧。例如,它可能从这5分钟视频中每隔10秒提取一个帧,然后使用预训练的视觉编码器(如CLIP-ViT-L/14)来提取每帧的视觉特征。
- 这样做能够捕获从选择木材到最终组装各个阶段的关键视觉信息,同时避免处理整个视频中的每一帧,从而降低复杂性和计算成本。
-
局部特征聚合和时间序列维护:
- 接下来,LongVLM将视频划分为若干短期片段,每个片段可能代表一个关键活动,如切割木材或打磨边缘。通过令牌合并模块,模型聚合每个短期片段内的补丁特征,生成每个活动的紧凑表示。
- 通过按照这些活动发生的时间顺序连接这些表示,LongVLM能够保持视频故事的连贯性,使得最终的视频理解能够反映出手工艺人工作的实际流程。
-
全局语义信息整合:
- 同时,模型计算整个视频范围内[CLS]令牌的平均值,代表整个视频的全局语义信息。然后,将这些全局信息与每个短期片段的特征结合,确保在理解每个具体活动时也考虑到整个视频的上下文。
- 例如,在解释打磨过程的具体细节时,模型也能考虑到这一步骤在整个桌子制作流程中的位置和重要性。
LongVLM 方法
LongVLM的方法,包括其总体架构、局部特征聚合过程和全局语义信息整合方式。
通过细化各个组成部分的作用和逻辑,我们可以更清晰地理解LongVLM如何实现对长视频的细粒度理解。
3.1 总体架构
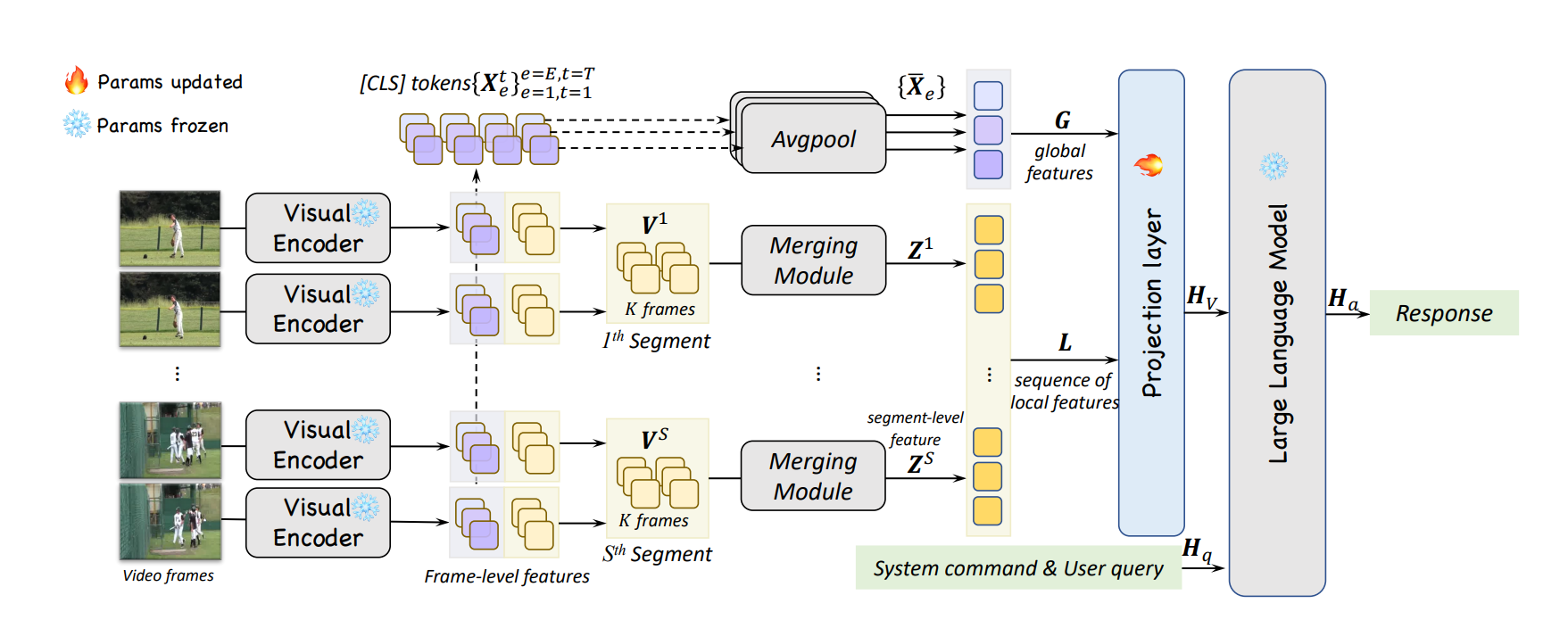
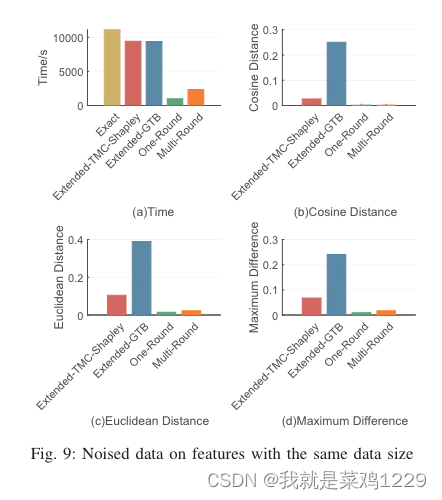
图展示了所提出的LongVLM(长视频理解的大型语言模型)的总体架构。
从图中可以看出,LongVLM的流程包括以下几个主要步骤:
-
均匀采样视频帧:首先从视频中均匀采样T帧。
-
视觉编码器:对采样出的每帧视频独立地使用视觉编码器提取帧级特征。
-
视频划分:将输入视频划分成S个片段,每个片段包含K帧。
-
局部特征的聚合:在每个片段内应用层次化的令牌合并模块来获取紧凑的局部特征。
-
序列连接:将片段级特征顺序连接起来,显式地保留了长视频中多个短期片段的时间顺序。
-
全局语义特征的整合:收集[CLS]令牌并通过平均池化来聚合全局语义特征。
-
特征融合:将全局特征与局部特征序列连接起来形成视频表示。
-
投影层:投影层将视频表示转换为适合LLM处理的格式。
-
大型语言模型(LLM):最终,将投影后的视觉特征与标记化的系统指令和用户查询结合,并输入到LLM以生成响应。
此图还显示了模型中不同组件的参数更新状态,标识为冰雪晶体的部分表示参数在此过程中是冻结的,而火焰图标的部分表示参数在训练过程中会更新。
这表明LongVLM在不同阶段利用了不同的训练策略。
此外,通过图示的步骤性描述,我们可以了解到该模型如何从输入视频中提取关键信息,并最终生成对用户查询的响应。
-
子解法1:视觉编码器 用于独立地提取每个视频帧的帧级特征,包括补丁特征和[CLS]令牌。
- 之所以使用视觉编码器,是因为它能够从视频帧中提取丰富的视觉信息,为后续的特征聚合和语义理解提供基础。
-
子解法2:局部特征序列的创建 将长视频分解为短期片段,对每个片段应用令牌合并模块,生成紧凑的片段级特征,这些特征按顺序连接,显式保留短期片段在长视频中的时间顺序。
- 之所以这样做,是为了捕获视频中的局部信息,并保持短期事件或动作的时间结构,有助于理解视频的序列性质。
-
子解法3:全局语义特征的整合 通过汇集和平均每个帧的[CLS]令牌,形成代表整个视频全局语义的特征,与局部特征序列一起输入到LLM。
- 之所以整合全局语义信息,是为了丰富局部特征序列的上下文信息,帮助模型在整个视频范围内生成合理的响应。
3.2 局部特征聚合
- 子解法1:分段和令牌合并 对每个短期片段应用层次化的令牌合并模块,通过软匹配方法逐步合并视觉令牌,以减少视觉令牌的数量并生成紧凑的局部特征。
- 之所以采用层次化的令牌合并,是因为视频具有高度的时空冗余,直接考虑所有补丁特征会导致冗余的计算成本。
3.3 全局语义整合
- 子解法1:全局特征的提取和整合 通过从每个帧的编码器层收集[CLS]令牌,并在时间维度上进行平均,生成代表整个视频的全局语义特征。
- 之所以重视全局语义特征,是因为它为模型提供了视频的整体上下文信息,有助于理解不同片段之间的关系,从而在整个视频上生成合理的响应。
LongVLM通过将长视频分解为多个短期片段并聚合每个片段的局部空间-时间特征,同时通过整合全局语义信息,提出了一种既能捕获细粒度局部信息又能保留视频整体上下文的方法。
这种结合局部和全局信息的策略,使得LongVLM能够实现对长视频内容的精细理解和响应生成,克服了现有方法在处理长视频时细节理解不足的问题。
不同于依赖全局语义进行长视频理解的传统方法,LongVLM提供了一种直接且有效的方法,用于实现长期视频中的精细级别理解。
效果
这部分文本描述了LongVLM模型的实验设置、主要结果、消融研究和定性结果。以下是各个部分的中文概述和针对问题与解法的精细化分析。
4.1 实验设置
-
数据集和评估指标:使用VideoChatGPT基准和ANET-QA等数据集对模型进行量化评估。涵盖了多个评估方面如正确性信息、细节取向、上下文理解等。
-
实现细节:使用CLIP-ViT-L/14作为视觉编码器,Vicuna-7B-v1.1作为LLM,并在VideoChatGPT-100K数据集上微调。
4.2 主要结果
-
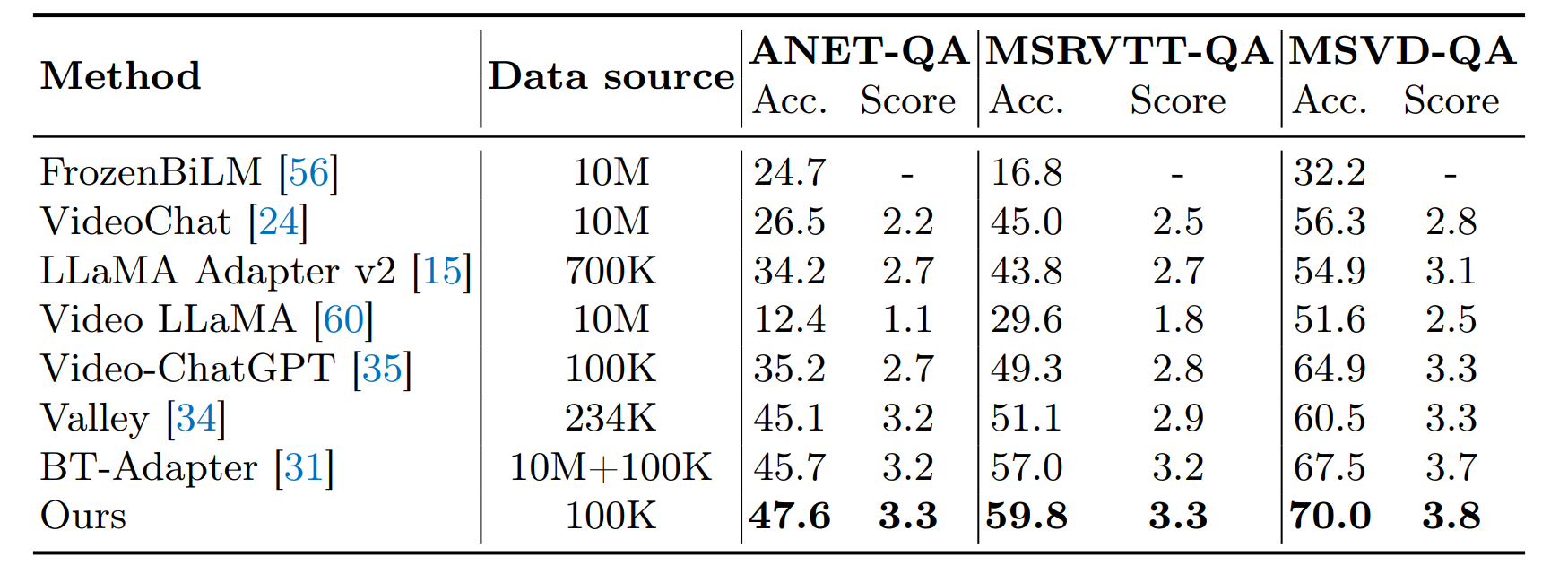
基于视频的生成基准:LongVLM在细节取向和一致性方面相较于现有模型有显著提升。
-
零样本视频问答:在三个零样本视频QA数据集上均达到了最高准确率。
4.3 消融研究
-
局部特征聚合的影响:
- 子解法1:引入短期片段级特征,保留局部信息和时间结构。
- 理由:与全局语义特征相比,局部特征更能够提高对视频的细粒度理解。
- 子解法1:引入短期片段级特征,保留局部信息和时间结构。
-
全局语义整合的影响:
- 子解法1:将全局语义特征融入局部特征。
- 理由:全局语义的加入显著提升了上下文理解和一致性的评分。
- 子解法1:将全局语义特征融入局部特征。
-
M的影响:
- 子解法1:选定M值,平衡内存成本和性能。
- 理由:适当长度的视觉令牌能够提高模型性能。
- 子解法1:选定M值,平衡内存成本和性能。
-
E的影响:
- 子解法1:选取不同的[CLS]令牌数量,以选择最佳的E值。
- 理由:适当数量的全局语义令牌能够提高生成质量分数。
- 子解法1:选取不同的[CLS]令牌数量,以选择最佳的E值。
4.4 定性结果
- 精细理解的展示:模型能够捕捉细节信息,如准确识别正在修理的是链条而非车轮。
- 例子:与Video-ChatGPT相比,LongVLM能够更准确地识别视频内容中的细节信息。