这篇论文提出了一种名为Polyp-PVT的新型息肉分割框架,该框架采用金字塔视觉变换器(Pyramid Vision Transformer, PVT)作为编码器,以显式提取更强大的特征。本模型中使用到的关键技术有三个:渐进式特征融合、通道和空间注意力、自注意力。
1,模型整体结构

Polyp-PVT通过引入三个简单的组件——级联融合模块(Cascaded Fusion Module, CFM)、伪装识别模块(Camouflage Identification Module, CIM)和相似性聚合模块(Similarity Aggregation Module, SAM),有效地提取了高级和低级线索,并将它们有效地融合以输出最终结果。这些模块有助于从不同维度捕获息肉的细节信息,包括纹理、颜色和边缘,并通过全局注意力机制将详细的外观特征注入到高级语义特征中。
2,编码器
作为模型的骨干网络,PVT用于从输入图像中提取多尺度长距离依赖特征。PVT采用金字塔结构,通过空间缩减注意力操作计算其表示,从而减少资源消耗。
3,CFM
CFM用于收集高级特征中的语义线索,并通过渐进式集成来定位息肉。它由两个级联部分组成,通过一系列的卷积单元和Hadamard乘积操作,将不同层次的特征图进行融合,生成一个特征图T1。
4,CIM
CIM旨在从低级特征图中捕获息肉的细节信息,如纹理、颜色和边缘。CIM包含通道注意力和空间注意力操作,通过这些注意力机制,可以从大量冗余信息中识别出息肉的细节和边缘信息。
5,SAM
SAM通过全局自注意力机制将T1和T2的特征图进行融合,有效地将像素级息肉区域的特征与整个息肉区域的高级语义位置信息结合起来。
SAM具体结构如下
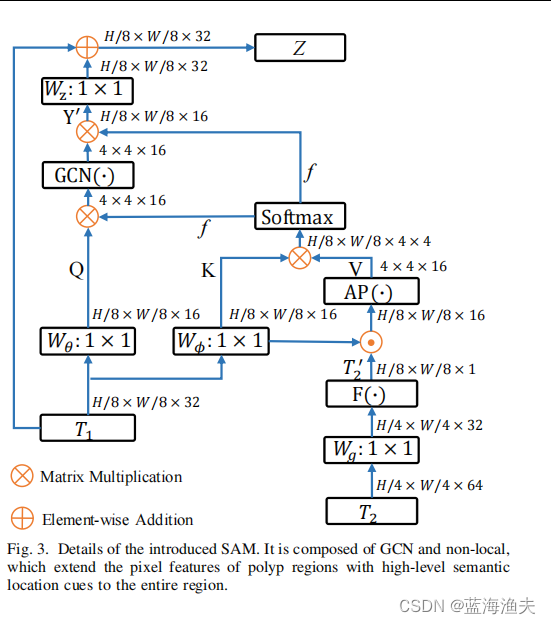
其中T1(包含高级语义信息)和T2(包含丰富的外观细节,如纹理和边缘信息)是两个输入特征。
W是线性映射。
AP代表的是自适应池化(Adaptive Pooling)操作。自适应池化是一种操作,它根据输入特征图的尺寸动态调整池化区域的大小,以便在不同分辨率的输入特征图上保持一致的输出尺寸。
GCN是图卷积层,GCN通常用于捕捉图像中不同区域之间的复杂关系和结构信息。
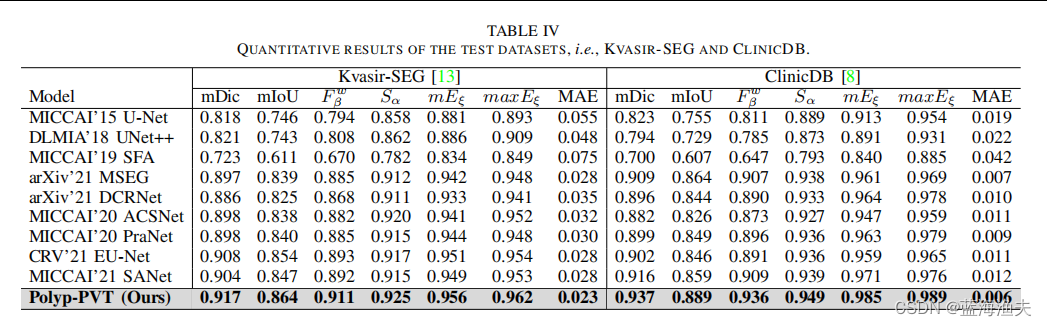
6,实验结果