import pandas as pd
import numpy as np
#efinance是金融数据包,可免费爬取东方财富交易数据
#直接使用pip install efinance安装
import efinance as ef
import matplotlib.pyplot as plt
#seaborn、plotly可视化包
import seaborn as sns
import plotly_express as px
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False#使用efinance包获取2014年至2022年8月5日数据
board_data=ef.stock.get_daily_billboard(start_date='2014-01-01',end_date='2022-08-05')
#保留需要的数据特征
cols=['股票代码','股票名称','上榜日期','收盘价','涨跌幅','换手率','龙虎榜净买额','流通市值','上榜原因','解读']
#有些股票可能因不同原因上榜,剔除重复记录样本
board_data=board_data[cols].drop_duplicates(['股票代码','上榜日期'])
board_data.head()#剔除退市、B股和新股N
s1=board_data['股票名称'].str.contains('退')
s2=board_data['股票名称'].str.contains('B')
s3=board_data['股票名称'].str.contains('N')
s=s1|s2|s3
final_data=board_data[-(s)]
final_data.describe()d1=pd.DataFrame(counts).rename(columns={'股票代码':'上榜次数'}).reset_index()
d2=final_data[['股票代码','股票名称']].drop_duplicates()
dd=pd.merge(d1,d2,how='inner').drop_duplicates('股票代码').reset_index(drop=True)
sns.displot(dd['上榜次数'],kde=True); 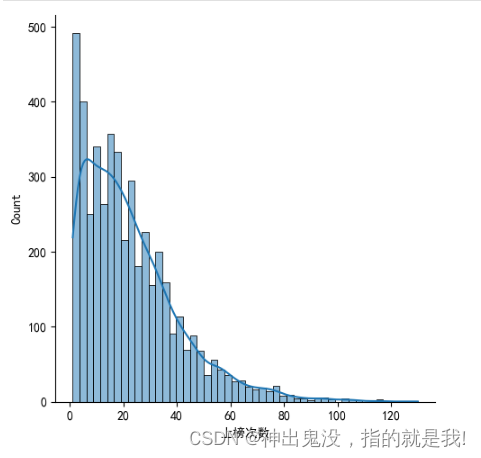
fig = px.treemap(dd[:100], path=['股票名称'],values='上榜次数', color='上榜次数',color_continuous_scale=['Green','Red',"#8b0000"])
fig.data[0].texttemplate = "%{label}<br>%{customdata}"
fig.update_traces(textposition="middle center", selector=dict(type='treemap'))fig.update_layout(margin = dict(t=30, l=10, r=10, b=10))
fig.update(layout_coloraxis_showscale=False)
fig.show()