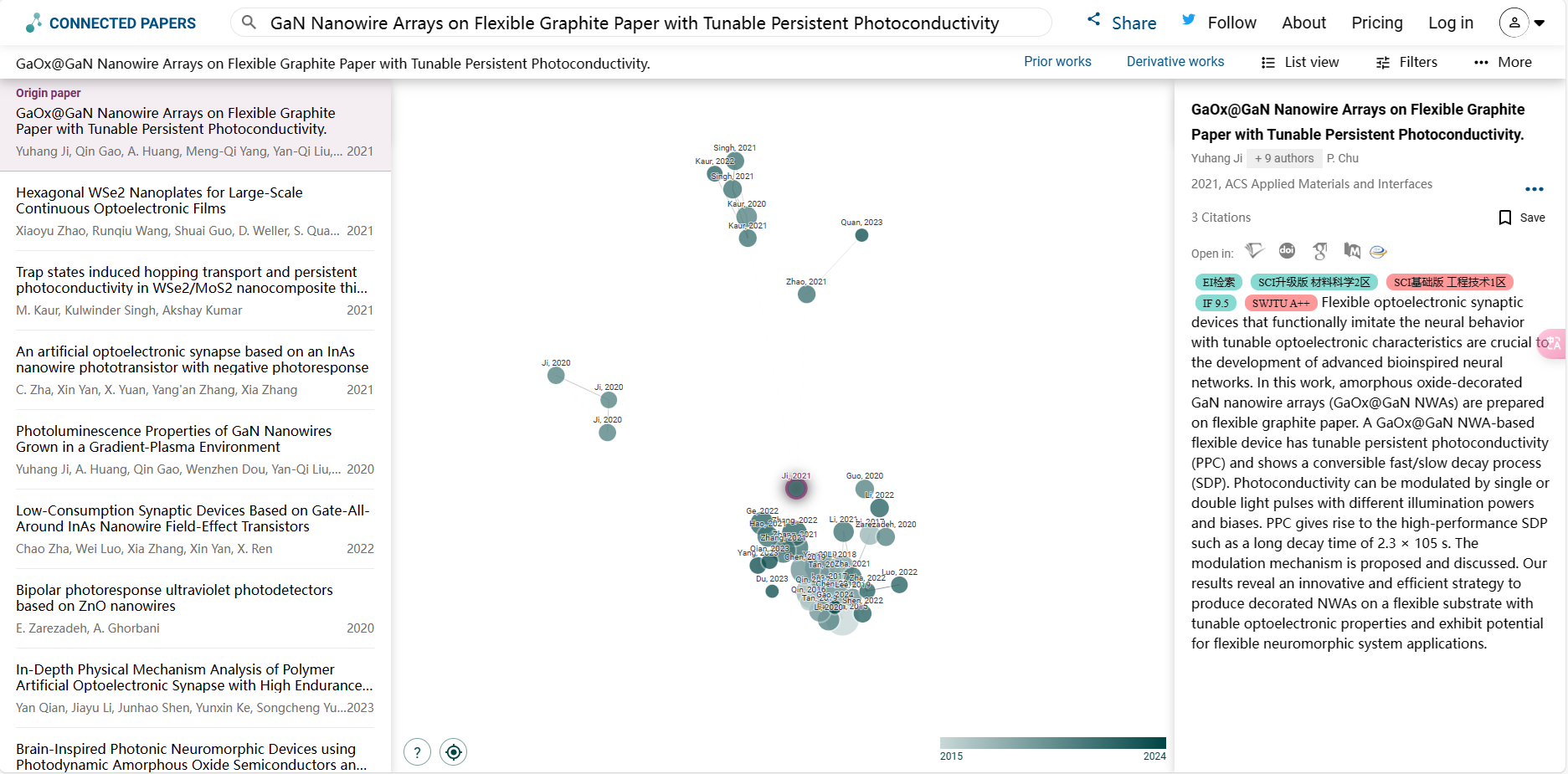
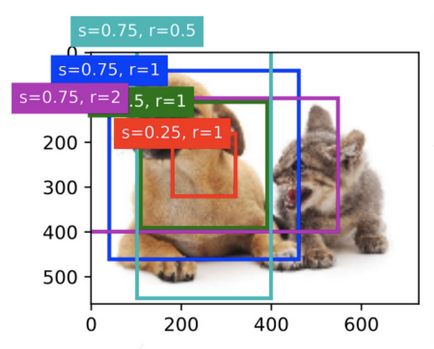
目标检测算法通常会在输入图像中抽样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界,从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型所使用的区域抽样方法可能不同。这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比不同的边界框,这些边界框被称为锚框(anchor box)。
1. 生成多个锚框
假设输入图像的高度为h,宽度为w。我们以图像的每个像素为中心生成不同形状的锚框:缩放比(scale)为,宽高比(aspect ratio)为r>0。那么锚框的宽度和高度分别为
和
。注意,当中心位置给定时,宽度和高度已知的锚框是确定的。
要生成多个不同形状的锚框,我们设置许多缩放比取值和许多宽高比取值
。以每个像素为中心使用这些缩放比和宽高比的所有组合时,输入图像将总共有w·h·n·m个锚框。尽管这些锚框可能会覆盖所有真实边界框,但计算复杂性很容易过高。在实践中,我们只考虑包含s1或r1的组合:
也就是说,以同一像素为中心的锚框的数量是n+m-1。对于整个输入图像,将共生成wh(n+m-1)个锚框。
上述生成锚框的方法在下面的multibox_prior 函数中实现。我们指定输入图像、缩放比列表和宽高比列表,然后此函数将返回所有的锚框。
2. 交并比(IoU)
我们刚才提到某个锚框“较好地”覆盖了图像中的狗。如果已知目标的真实边界框,那么这里的“好”该如何量化呢?直观地说,就是可以度量锚框和真实边界框之间的相似性。杰卡德指数(Jaccard index),也称杰卡德相似系数(Jaccard similarity coefficient)可以度量两组的相似性。给定集合A和B,它们的杰卡德指数是它们交集的大小除以它们并集的大小:

事实上,我们可以将任何边界框的像素区域视为一组像素。通过这种方式,我们可以通过其像素集的杰卡德指数来度量两个边界框的相似性。对于两个边界框,它们的杰卡德指数通常称为交并比(intersection over union,IoU),即两个边界框相交面积与相并面积之比,如图所示。交并比的取值范围在0和1之间,0表示两个边界框无重合像素,1表示两个边界框完全重合。接下来将使用交并比来度量锚框和真实边界框之间,以及不同锚框之间的相似性。给定两个锚框或边界框的列表,以下box_iou函数将对于这两个列表计算它们成对的交并比。
3. 在训练数据中标注锚框
在训练集中,我们将每个锚框视为一个训练样本。为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(ofiset)标签,其中前者是与锚框相关的目标的类别,后者是真实边界框相对于锚框的偏移量。在预测时,我们为每张图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
目标检测训练集带有真实边界框的位置及其包围目标的类别的标签。要标注任何生成的锚框,我们可以参考分配到的最接近此锚框的真实边界框的位置和类别标签。下面将介绍一个算法,它能够把最接近的真实边界框分配给锚框。
3.1. 将真实边界框分配给锚框
给定图像,假设锚框是,真实边界框是
,其中
。我们定义一个矩阵
,其中第i行、第j列的元素
,是锚框A,和真实边界框
,的IoU。该算法包含以下步骤。
(1)在矩阵X中找到最大的元素,并将它的行索引和列索引分别表示为和
。然后将真实边界框
,分配给锚框
。这很直观,因为
和
,是所有锚框中与真实边界框最相近的。在第一个分配完成后,丢弃矩阵中第行和第列中的所有元素。
(2)在矩阵X中找到剩余元素中的最大元素,并将它的行素引和列索引分别表示为和
。我们将真实边界框
分配给锚框
,并丢弃矩阵中第
行和第
列中的所有元素。
(3)此时,矩阵X中两行和两列中的元素已被丢弃。我们继续,直到丢弃矩阵X中列中的所有元素。此时已经为这
个锚框各自分配了一个真实边界框。
(4)只遍历剩余的个锚框。例如,给定任何锚框
,在矩阵X的第i行中找到与
的IoU最大的真实边界框
,只有当此IoU大于预定义的阈值时,才将
分配给
。
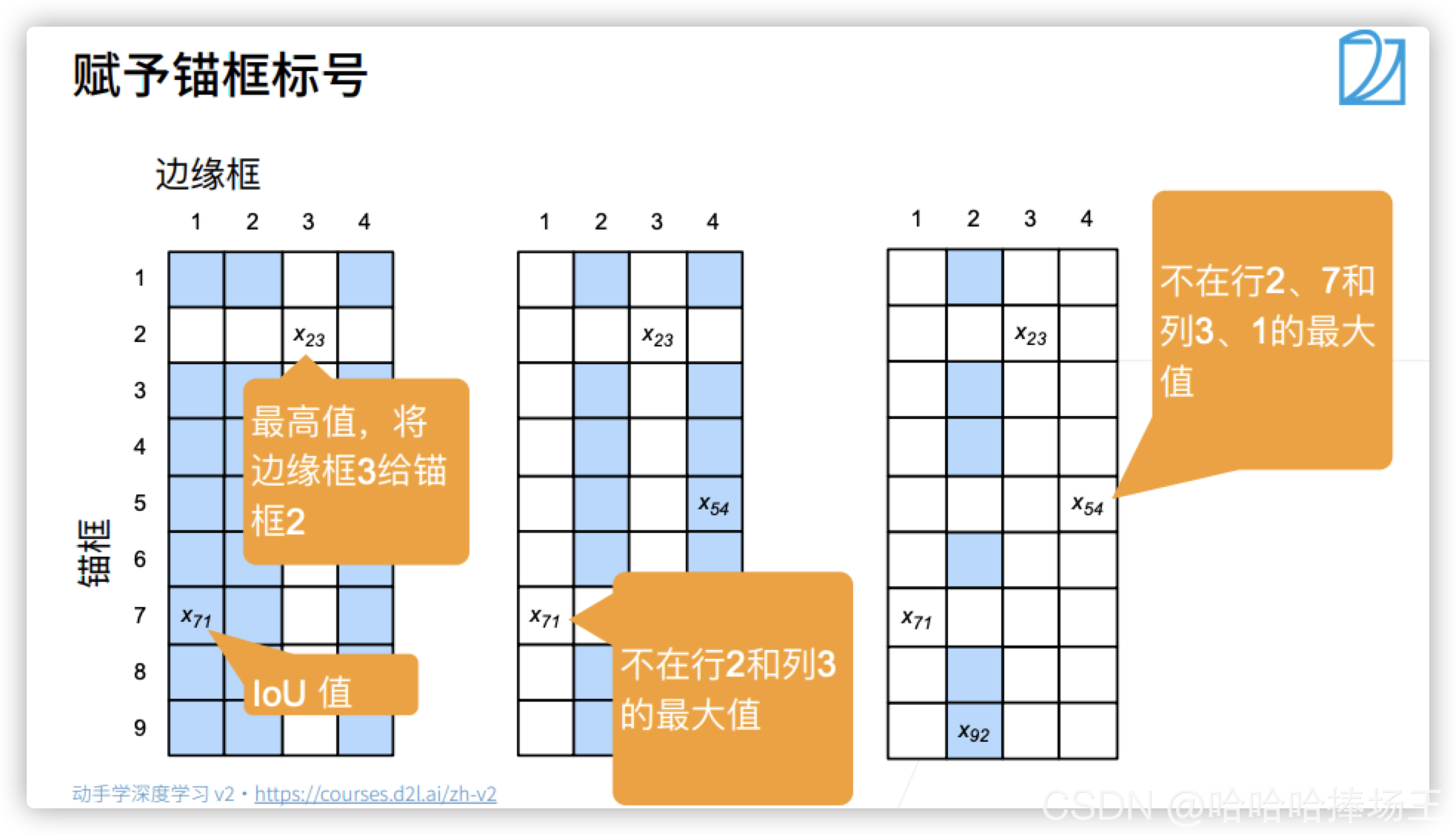
下面用一个具体的例子来说明上述算法。首先,如图(a)所示,假设矩阵X中的最大值为,我们将真实边界框
分配给锚框
。丢弃矩阵第2行和第3列中的所有元素,在剩余元素(阴影区域)中找到最大的元素
,将真实边界框
分配给锚框
。接下来,如图(b)所示,丢弃矩阵第7行和第1列中的所有元素,在剩余元素(阴影区域)中找到最大的元素
,将真实边界框
分配给锚框
。最后,如图(c)所示,丢弃矩阵第5行和第4列中的所有元素,在剩余元素(阴影区域)中找到最大的元素
,将真实边界框
分配给锚框
。之后,我们只需要遍历剩余的锚框 A1、A3、A4、A6、A8,然后根据阈值确定是否为它们分配真实边界框。
3.2. 标注类别和偏移量
现在我们可以为每个锚框标注类别和偏移量了。假设一个锚框A 被分配了一个真实边界框B。一方面,锚框A 的类别将被标注为与B相同。另一方面,锚框 A 的偏移量将根据B和A中心坐标的相对位置以及这两个框的相对大小进行标注。鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。这里介绍一种常见的转换。给定框A和B,中心坐标分别为和
,宽度分别为
和
,高度分别为
和
,可以将A的偏移量标注为

其中,常量的默认值为,
,
。
如果一个锚框没有被分配真实边界框,我们只需将锚框的类别标注为背景(background)。背景类别的锚框通常被称为负类锚框,其余的锚框被称为正类锚框。我们使用真实边界框(labels参数)实现以下multibox_target 函数,来标注锚框的类别和偏移量(anchors参数)。此函数将背景类别的索引设置为零,然后将新类别的整数索引递增一。
4. 使用非极大值抑制预测边界框
在预测时,我们先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。一个预测好的边界框则根据其中某个带有预测偏移量的锚框而生成。下面我们实现offset_inverse函数,该函数将锚框和偏移量预测作为输入,并应用逆偏移变换来返回预测的边界框坐标。
当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,它们都围绕着同一目标。为了简化输出,我们可以使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的相似的预测边界框。 以下是非极大值抑制的工作原理。对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。具体来说,我们将p称为预测边界框B的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度按降序排序,以生成列表L。然后我们通过以下步骤的操作排序列表L。(1)从工中选取置信度最高的预测边界框B作为基准,然后将所有与的IoU超过预定阀值
的非基准预测边界框从L中移除。这时,L保留了置信度最高的预测边界框,移除了与其过于相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
(2)从L中选取置信度次高的预测边界框作为又一个基准,然后将所有与
的IoU大于
的非基准预测边界框从L中移除。
(3)重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预 测边界框的IoU都小于阈值,因此,没有一对边界框过于相似。
(4)输出列表L中的所有预测边界框。

参考文献
动手学深度学习之锚框-CSDN博客
42 锚框【动手学深度学习v2】_哔哩哔哩_bilibili
动手学深度学习PyTorch版



![[react优化] 避免组件或数据多次渲染/计算](https://img-blog.csdnimg.cn/direct/d9a9a27548814ac68c3628f910e3f37f.png)