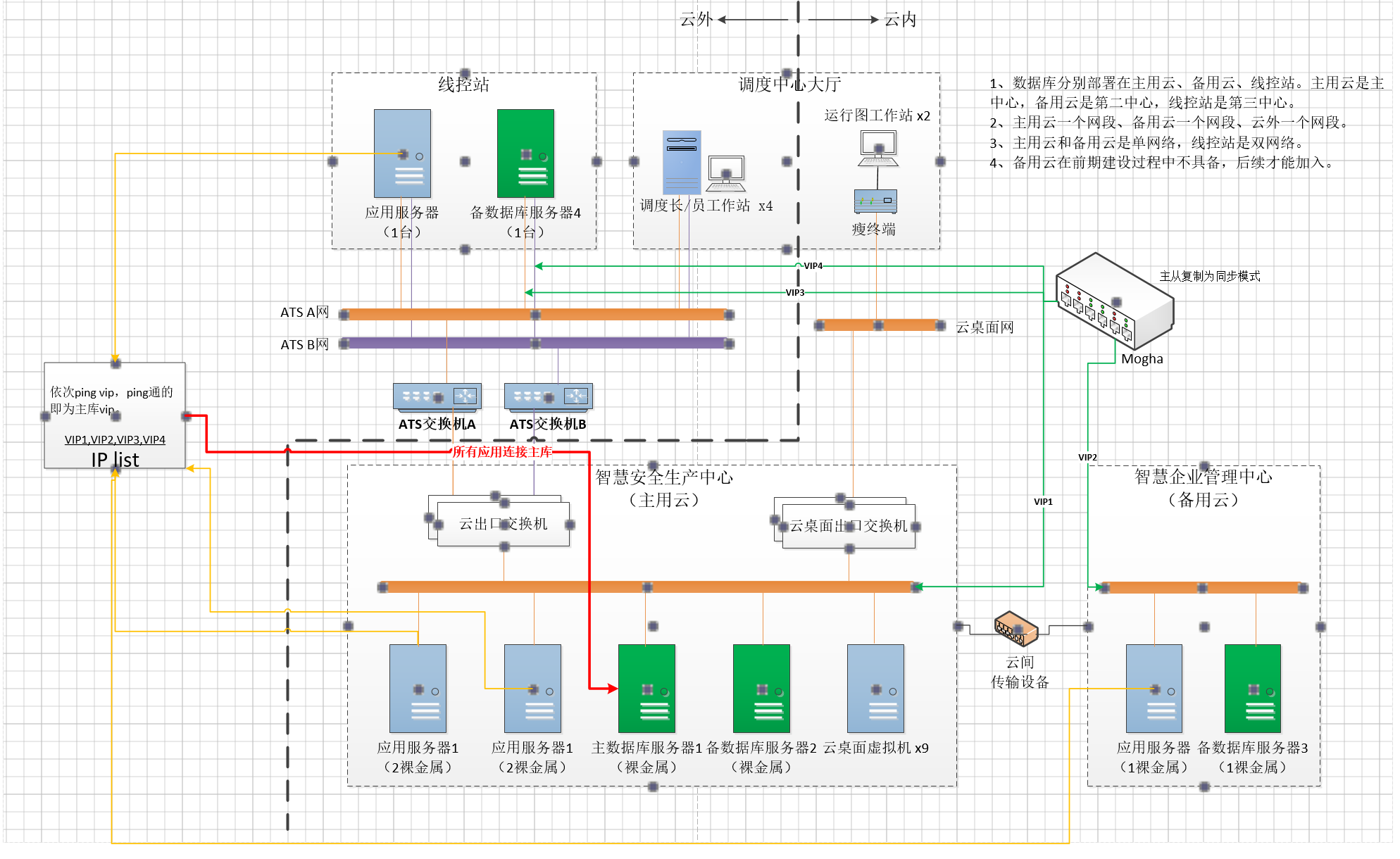
硬件要求:
- 配备至少8GB VRAM的GPU,如果你的电脑只有CPU,请看到最后。
- 根据部署规模,需要足够的CPU和RAM。
软件要求:
- Python 3.7或更高版本。
- 支持NVIDIA GPU的PyTorch。
- Hugging Face的Diffusers库。
- Hugging Face的Transformers库。
步骤:
1. 设置Python环境
安装Python并创建一个虚拟环境:
python -m venv stable-env
source stable-env/bin/activate # 在Windows上使用 `stable-env\Scripts\activate`
2. 安装依赖
安装CUDA支持的PyTorch:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cuda113
安装diffusers和transformers:
pip install diffusers transformers
3. 下载和加载模型
使用Hugging Face模型库下载Stable Diffusion:
from diffusers import StableDiffusionPipeline
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token="YOUR_HUGGINGFACE_TOKEN")
model.to("cuda")
4. 运行模型:
根据提示生成图像:
prompt = "A girl who is play cello at a Church"
image = model(prompt)["sample"][0]
image.save("output.png")
生成的图片长这样:

如果您没有GPU,仍然可以部署并使用Stable Diffusion,但您需要为处理时间显著变慢做好准备,尤其是对于像图像生成这样的计算密集型任务。以下是如何在没有GPU的系统上管理和优化Stable Diffusion的使用方法:
当只使用CPU时,关键是要合理设定性能预期。在GPU上可能需要几秒钟的图像生成任务,在CPU上可能需要几分钟。
在CPU上运行的步骤,和GPU类似:
- 修改您的设置以确保它在CPU上运行,通过在代码中明确指定设备。例如,如果您使用的是
diffusers库,可以按以下方式调整您的管道设置:
from diffusers import StableDiffusionPipeline# 加载模型,设置设备为CPU
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
model.to("cpu")
大家有任何问题可以在留言区讨论。