REINFORCE
-
总结
估计VALUE-methods没有在理论上证明收敛,而policy-methods不需要估计value function。
本算法总结了过去的算法,将过去算法作为特例看待,证明了即使是结合函数估计和实际采样的value梯度都可以无偏估计,证明了某种梯度迭代可以收敛到局部最优值。
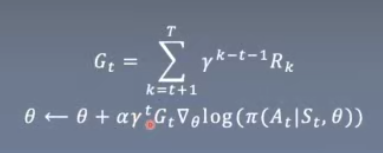
拓展:加入baseline,可以由任何方式得到,但不依赖于具体action和θ,可以减少variance
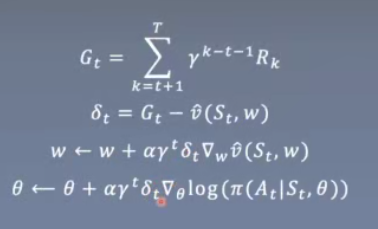
具体计算时需要t从T开始,不断减小,累计梯度,最后更新θ和w;
进一步改进:使用TD方法来估计Gt。
比MC方法学习更迅速,不需要等待整个episode完结。
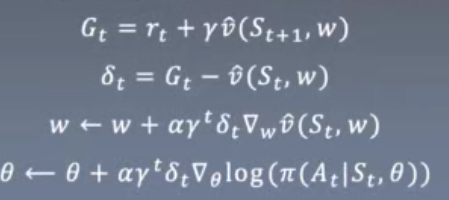
-
定理1 得到了一个简便容易的policy梯度
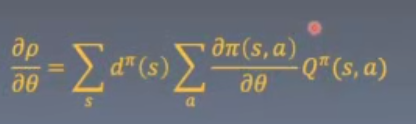
每一时刻在矩阵分布是之前状态乘以状态转移矩阵
所有状态连成一片,那么将会得到一个station distribution,只要t足够大,极限与s0无关
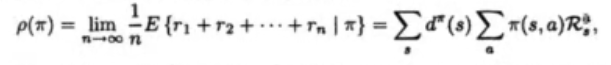
证明了以下定理
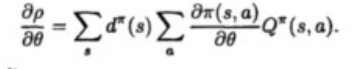

-
定理2 value function和baseline

提供了一种设计value function思路
提及了关于baseline的思想
-
定理3 SGD的直接应用
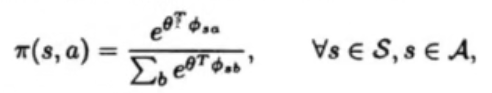
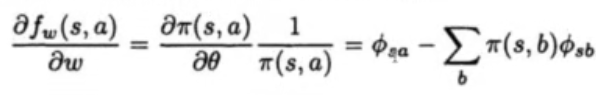
得到fw的简单形式
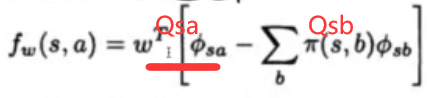
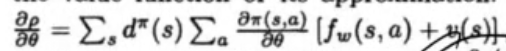
-
算法核心
Gt为future reward
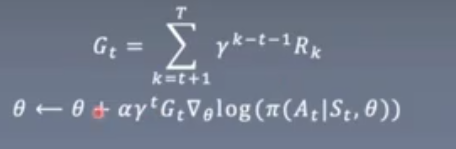
Gt越大,则action概率大。
定理1是在γ = 1的情况下证明的。引入γ会带来额外的好处。
首先将QΠ替换为估计值G
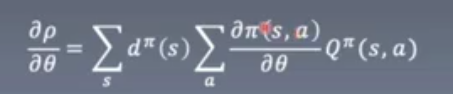
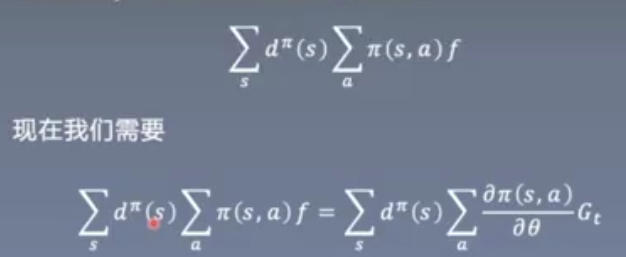
-
REINFORCE进阶
最严重问题:梯度方差太大。这会导致不同sample的梯度互相抵消从而使学习非常低效。
时间距离越远,sample会拥有越大的varience,而γ^t可以有效控制它。
在Gt的基础上增加一个与行动At无关的值b

-
方法1 moving average
思路:
action概率增减,由其得到的reward正负决定
当由多个action和多个reward,影响可能相互抵消,更强的信号会减弱,其余的消失。
我们使强的信号变弱,弱的信号(小的增长)变成反向的(减少)。取baseline为当前的历史信息的平均值,而不仅仅是此次更新所利用的信息。
同样的,过去的信息也可能太老旧而没有价值。也可以选取一个固定的window size计算平均值。
-
方法2 state value function
varience来自于不同state的G,所以moving average可以细分到每个state
→对每个state求moving average,但更简单的改进是估计每个state的平均值,即state value function

-
Anather Improvement-Actor Critic
MC-monte carlo方法得到的估计值虽然是五篇估计,但是有很大方差,Gt本身也不稳定。
TD-Temporal difference方法虽然有偏差,但是可以极大减小方差
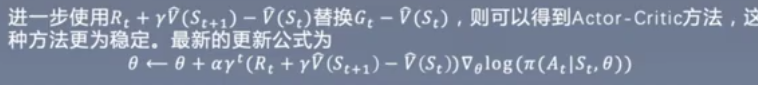
-
-
算法核心证明
-
网络结构设计
1 构建ACTOR网络并抽样
1)区别
value-base策略:Q-learning算法基本流程是计算每个action的Q(s,a),以概率e随机选取action,1-e概率greedy选取Q(s,a)最大值的action
policy-base策略:直接学习不同action的概率,使用network表示actor,最终输出是一个概率分布,且我们要根据该概率分布抽样得到action。
2)基本结构
distribution RL→F.log_sftmax可以学习得到一个分布,即得到一个在N个点上的概率分布,每个action可以看作一个点。
F.log_softmax与F.softmax推荐明确指定对哪一个维度进行计算。
设计网络时,每个维度的意义必须明确,意味着输入和输出的维度是固定的。同时,nn.Linear对属于维度没有严格限制,只要求最后一个维度和一开始定义的输入维度相同。如果在F.log_sftmax报错,很可能是nn.Linear的输入输出不是设想的形状。
log_probs = F.log_softmax(self.fc2(x),**dim = 1**)3)抽样
1.将概率从torch.tensor转变为numpy.array,然后用np.random.choice抽样。一次只对一个概率分布进行采样。
2.使用torch.distributions.Categorical进行抽样。这种方法更为灵活,可以对多个概率同时采样。再使用.log_prob可以得到每个采样的log probability,且带有导数。
2 构建critic网络
是简化版的Q网络,只需要输出一个值。
nn.ModuleList()# 较方便的进行抽样3 合并Actor Critic
Deep Neural Network的前几层可能是相同的,都是对于原始输入的特征提取,可能是CNN多应用与图像,RNN多应用于文字,Transformer都有应用。
最后一俩层则是具体惹怒的学习和处理,所以对于相同environment,学习actor和critic需要的特征可能一直,所以可以将他们合并在一个网络中,也可以理解成一种多任务学习。
优点:多个任务同时反馈信息,能帮助底层更快更好地学习需要的feature
缺点:需要谨慎平衡多个任务的loss,否则可能因为某任务loss比重大,导致其他任务学习效果变差。
-
数据处理
1 MC方法(无偏,接受较大vaivence,所有episode结束才能计算)
Gt必须从今后向前计算,简单思路:计算每一个Gt再乘上γ^t
简化:使用np.cumsum计算当前叠加和,直接对rt乘γ^t后求和,而不是先计算Gt。
2 TD方法(与MC方法对立)
Q_learning多使用它,只有vs,而不需要提取Qsa,只需要用Critic计算出所有state values后和获得的reward相加。
-
主体循环
在Q-learning种将所有transition存入replay buffer并后续进行抽样学习,这是因为Q-learning的Q(s,a)可以进行offline learning,但是在REINFORCE中,未得到导数的无偏估计,Π改变后所有的transition将不服从当前policy分布
training loop存在的意义是:所有transition必须在当前policy下得到,如果policy改变,则必须丢弃之前的所有transition记录
Replay Buffer
每一次更新,为了使样本使用效率最大化,我们应该使用全部当前policy得到的样本,即使用一个临时的replay buffer来存储policy得到的所有样本。
为了方便,使用list数据结构(也可以创建更复杂的类),在每个episode开始时,将这些临时replay buffer初始化。
由于repaly buffer容量不会很大,且之后会对整个buffer进行处理而不需要采样操作,所以不需要像value methods中储存完整transition(St,At,Rt,Dt,St+1),而只需要按时间t将state,action,reward,和done分别储存即可。
Main Loop
value methods主体循环大致有四部分:
- 获取acton并执行;
- 记录当前transition;
- 更新参数;
- 判断是否episode结束。
REINFORCE中,1,4时必须的。
对于2,此时我们不需要储存完整transition,只需按时间t存储state,action,rewward,done,循环中可以保证时间t是统一的,故只需要储存当前值。
对于3,我们需要移除循环体,获得完整的episode数据后再进行更新。每次更新后,必须将所有临时replay buffer清空。
Update
已记录了所有St和At并且知道Actor的情况下,计算lofΠ(at|st)也很简单,只要得到损失函数并直接优化即可。