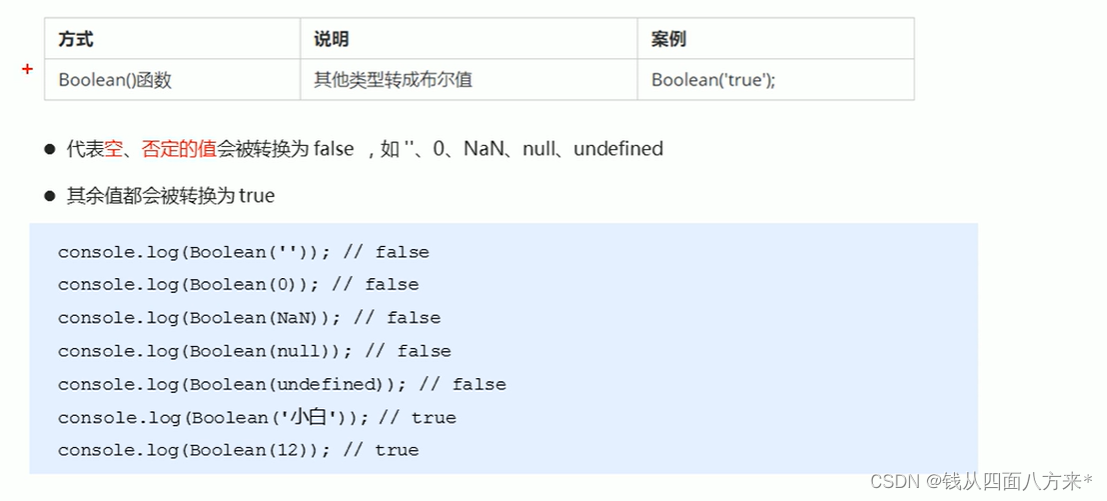
今天给各位介绍一个发表高质量论文的好方向:ResNet结合Transformer。
ResNet因其深层结构和残差连接,能够有效地从图像中提取出丰富的局部特征。同时,Transformer的自注意力机制能够捕捉图像中的长距离依赖关系,为模型提供全局上下文信息。
这种策略结合了两者分别在处理空间、序列数据上的优势,强化了模型特征提取和全局理解方面的能力,让模型在保持强大的局部分析能力的同时,也能够利用全局信息来进一步提升性能。 比如高性能低参数的SpikingResformer,以及准确率高达99.12%的EfficientRMT-Net。
本文整理了9种ResNet结合Transformer的创新方案,并简单提炼了可参考的方法以及创新点,希望能给各位的论文添砖加瓦。
论文以及开源代码需要的同学看文末
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
方法:本文介绍了一种新型的脉冲自注意机制,名为双脉冲自注意(DSSA),以及基于该机制的脉冲视觉Transformer架构——SpikingResformer。DSSA通过双脉冲转换生成脉冲自注意,完全基于脉冲驱动且与SNN兼容。SpikingResformer结合了ResNet多阶段设计和提出的脉冲自注意机制,实现了更好的性能和更低的参数和能耗。
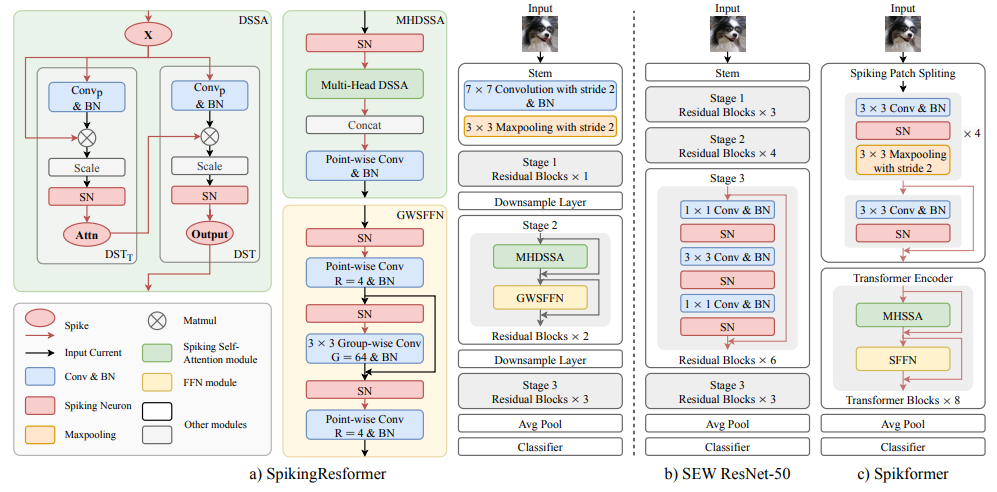
创新点:
-
提出了一种名为Dual Spike Self-Attention(DSSA)的新型脉冲自注意机制,通过Dual Spike Transformation实现脉冲自注意,完全适用于脉冲神经网络(SNNs)。
-
提出了一种名为SpikingResformer的创新脉冲Vision Transformer架构,将ResNet-based多阶段架构与DSSA结合,提高性能和能量效率,并减少参数数量。在ImageNet上,SpikingResformer-L的top-1准确率达到了79.40%,是SNN领域的最好结果。
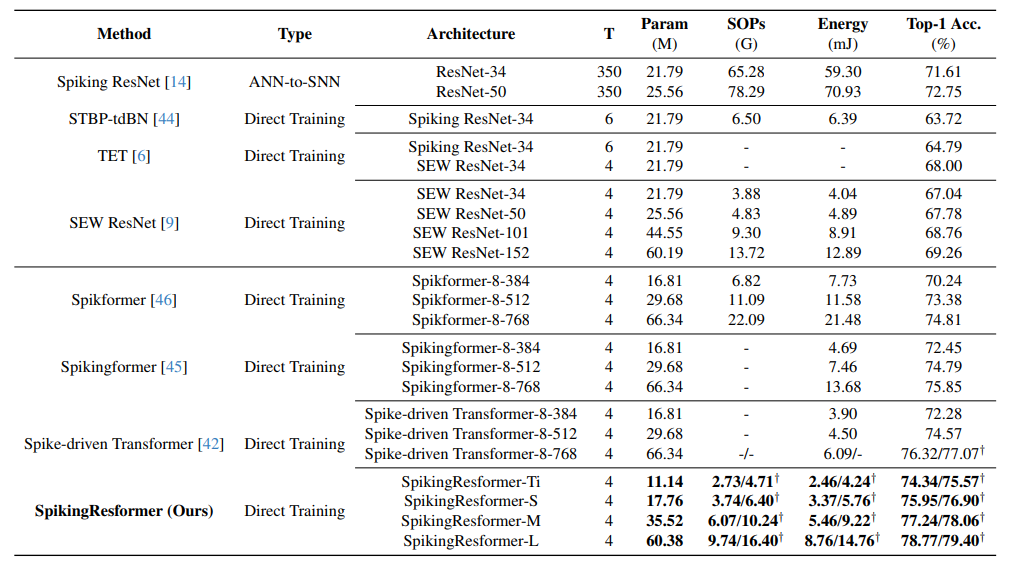
EfficientRMT-Net—An Efficient ResNet-50 and Vision Transformers Approach for Classifying Potato Plant Leaf Diseases
方法:论文将Vision Transformer(ViT)和ResNet-50架构整合到一个名为EfficientRMT-Net的新模型中,可以有效准确地识别各种土豆叶病。EfficientRMT-Net利用卷积神经网络(CNN)模型进行不同特征提取,并采用深度卷积(DWC)来降低计算需求。还采用阶段块结构来改善可扩展性和敏感区域检测,增强不同数据集的可迁移性。
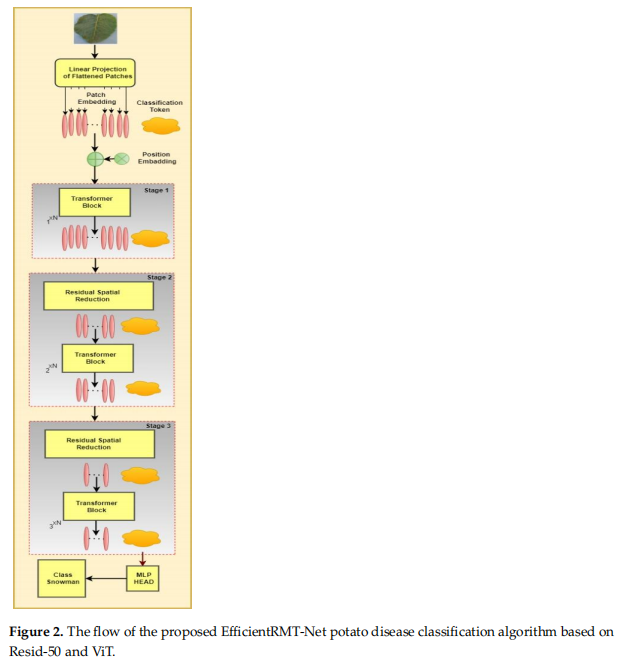
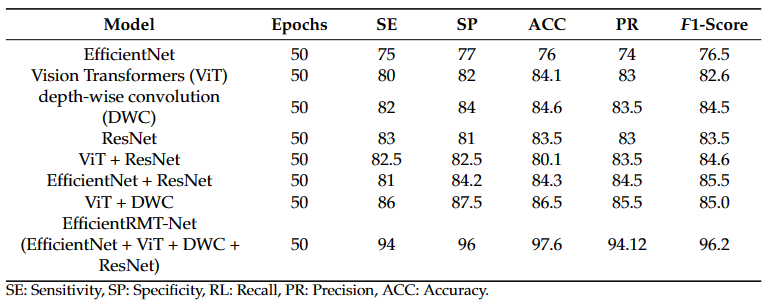
创新点:
-
EfficientRMT-Net模型在普通图像数据集上的准确率为97.65%,在专门的土豆叶图像数据集上为99.12%,优于现有方法。
-
EfficientRMT-Net结合了ResNet-50、Vision Transformer(ViT)、depth-wise convolution (DWC)等架构和技术,提高了模型的准确性和效率。
-
EfficientRMT-Net模型具有较高的分类准确率、敏感性、特异性、精确度和F1分数。
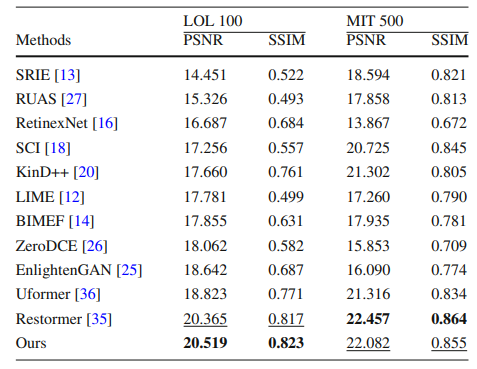
Swin transformer and ResNet based deep networks for low-light image enhancement
方法:通过结合Swin Transformer和ResNet,开发一种用于低光图像增强的Swin Transformer和ResNet基于的生成对抗网络(STRN)。STRN的生成器由浅层特征提取、深层特征提取和高质量图像重建模块组成,通过使用RSTB-DRB块来计算全局和局部注意力。
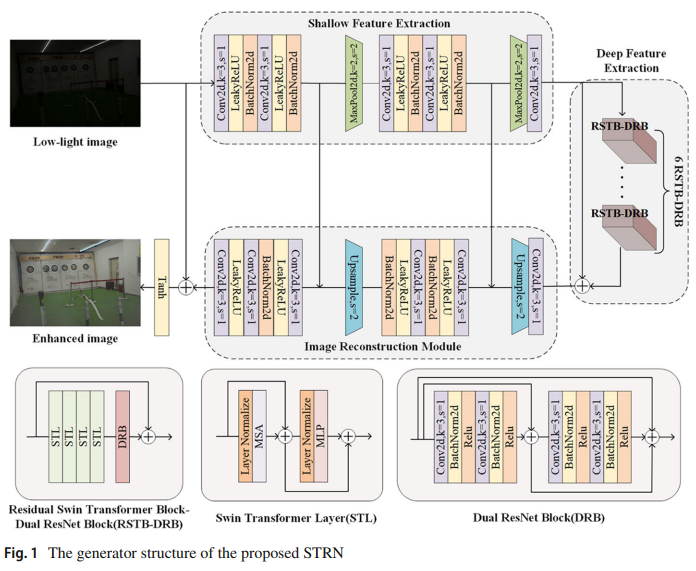
创新点:
-
引入Transformer网络:相比于基于卷积神经网络(CNN)的方法,Transformer网络通过自注意力机制可以捕捉到长距离上下文之间的交互作用,从而提高了低光图像增强的性能。
-
引入DRB(Dense Residual Block):DRB不仅可以提取局部特征,还可以提高RSTB(Recurrent Squeeze-and-Transform Block)的稳定性训练,从而进一步提升了算法的性能。
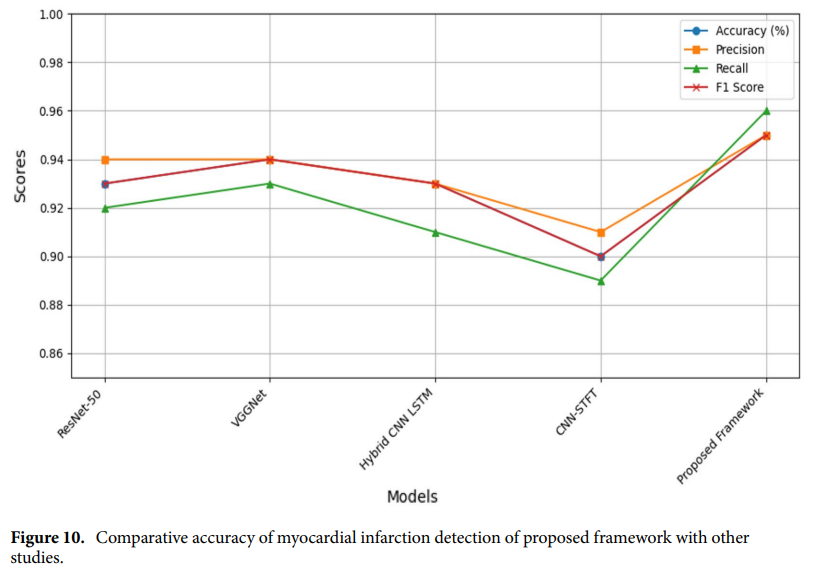
A hybrid ResNet‑ViT approach to bridge the global and local features for myocardial infarction detection
方法:论文提出了一种基于ResNet和Vision Transformer(ViT)模型的混合方法,旨在改进心肌梗死(MI)的检测准确性。通过将ResNet和ViT模型提取的特征进行融合,该方法结合了全局和局部特征,提供了更全面的心肌梗死模式表示。
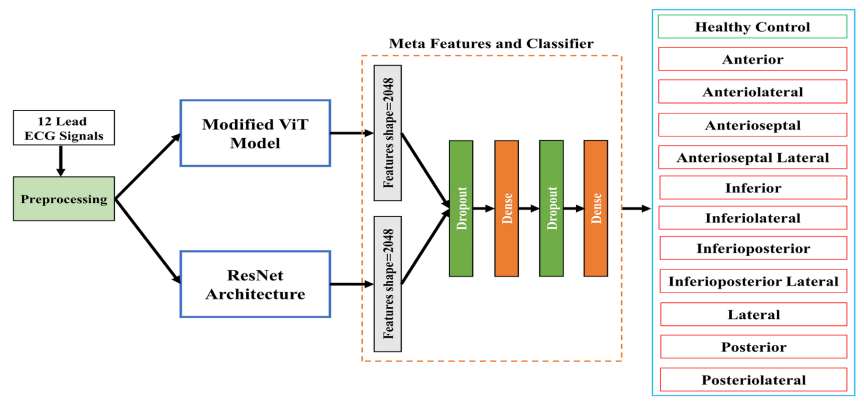
创新点:
-
针对ViT模型的局限性,作者引入了一个精简模型来改善嵌入特征提取,并通过多分支网络和通道注意机制实现了更丰富的信息学习。
-
通过同时训练ResNet和修改后的ViT模型来提取图像数据,为特征提取引入了双路径策略,从而获得更全面的特征表示。
-
通过融合全局和局部特征,作者的方法解决了生成鲁棒特征向量的挑战,提供了更全面的心肌梗死模式表示。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“残差结合”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏