原文地址:four-data-cleaning-techniques-to-improve-large-language-model-llm-performance
2024 年 4 月 2 日
检索增强生成(RAG)过程因其增强对大语言模型(LLM)的理解、为它们提供上下文并帮助防止幻觉的潜力而受到欢迎。 RAG 过程涉及几个步骤,从分块摄取文档到提取上下文,再到用该上下文提示 LLM 模型。虽然 RAG 可以显着改善预测,但有时也会导致错误的结果。摄取文档的方式在此过程中起着至关重要的作用。例如,如果我们的“上下文文档”包含LLM的拼写错误或不寻常的字符(例如表情符号),则可能会混淆LLM对所提供上下文的理解。
在这篇文章中,我们将演示如何使用四种常见的自然语言处理 (NLP)技术来清理文本,然后再将文本摄取并转换为块以供LLM进一步处理。我们还将说明这些技术如何显着增强模型对提示的响应。
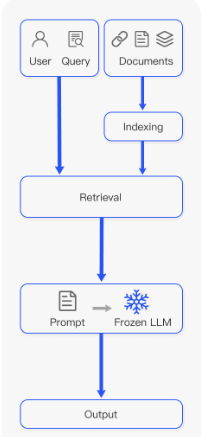
RAG 过程的步骤改编自RAG-Survey。
为什么清理文档很重要?
在将文本输入任何类型的机器学习算法之前清理文本是标准做法。无论您使用的是监督算法还是无监督算法,甚至是为生成 AI (GAI) 模型构建上下文,使文本保持良好状态都有助于:
确保准确性:通过消除错误并使一切保持一致,您就不太可能混淆模型或最终出现模型幻觉。
提高质量:更清晰的数据确保模型能够使用可靠且一致的信息,帮助我们的模型从准确的数据中进行推断。
促进分析:干净的数据易于解释和分析。例如,使用纯文本训练的模型可能难以理解表格数据。
通过清理我们的数据(尤其是非结构化数据),我们为模型提供了可靠且相关的上下文,从而改进了生成,降低了幻觉的可能性,并提高了 GAI 速度和性能,因为大量信息会导致更长的等待时间。
如何实现数据清洗?
为了帮助您构建数据清理工具箱,我们将探讨四种 NLP 技术以及它们如何帮助模型。
步骤1:数据清洗和降噪
我们将首先删除不提供含义的符号或字符,例如 HTML 标签(在抓取的情况下)、XML 解析、JSON、表情符号和主题标签。不必要的字符通常会混淆模型,并增加上下文标记的数量,从而增加计算成本。
认识到没有一刀切的解决方案,我们将使用常见的清理技术来调整我们的方法以适应不同的问题和文本类型:
标记化:将文本分割成单独的单词或标记。
消除噪音:消除不需要的符号、表情符号、主题标签和 Unicode 字符。
规范化:将文本转换为小写以保持一致性。
删除停用词:丢弃不会增加含义的常见或重复的单词,例如“a”、“in”、“of”和“the”。
词形还原或词干提取:将单词简化为其基本形式或词根形式。
我们以这条推文为例:
“I love coding! 😊 #PythonProgramming is fun! 🐍✨ Let’s clean some text 🧹”
虽然我们很清楚其含义,但让我们通过应用 Python 中的常用技术来简化模型。以下代码片段和本文中的所有其他代码片段都是在 ChatGPT 的帮助下生成的。
import re
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopword
s
from nltk.stem import WordNetLemmatizer# Sample text with emojis, hashtags, and other characters
text = “I love coding! 😊 #PythonProgramming is fun! 🐍✨ Let’s clean some text 🧹”# Tokenization
tokens = word_tokenize(text)# Remove Noise
cleaned_tokens = [re.sub(r’[^\w\s]’, ‘’, token) for token in tokens]# Normalization (convert to lowercase)
cleaned_tokens = [token.lower() for token in cleaned_tokens]# Remove Stopwords
stop_words = set(stopwords.words(‘english’))
cleaned_tokens = [token for token in cleaned_tokens if token not in stop_words]# Lemmatization
lemmatizer = WordNetLemmatizer()
cleaned_tokens = [lemmatizer.lemmatize(token) for token in cleaned_tokens]print(cleaned_tokens)# output:
# [‘love’, ‘coding’, ‘pythonprogramming’, ‘fun’, ‘clean’, ‘text’]该过程删除了不相关的字符,并为我们留下了我们的模型可以理解的干净且有意义的文本:['love', 'coding', 'pythonprogramming', 'fun', 'clean', 'text']。
步骤2:文本标准化和规范化
接下来,我们应该始终优先考虑文本的一致性和连贯性。这对于确保准确的检索和生成至关重要。在下面的 Python 示例中,让我们扫描文本输入是否存在拼写错误和其他可能导致不准确和性能下降的不一致之处。
import re# Sample text with spelling errors
text_with_errors = “””But ’s not oherence about more language oherence .
Other important aspect is ensuring accurte retrievel by oherence product name spellings.
Additionally, refning descriptions oherenc the oherence of the contnt.”””# Function to correct spelling errors
def correct_spelling_errors(text):# Define dictionary of common spelling mistakes and their correctionsspelling_corrections = {“ oherence ”: “everything”,“ oherence ”: “refinement”,“accurte”: “accurate”,“retrievel”: “retrieval”,“ oherence ”: “correcting”,“refning”: “refining”,“ oherenc”: “enhances”,“ oherence”: “coherence”,“contnt”: “content”,}# Iterate over each key-value pair in the dictionary and replace the# misspelled words with their correct versionsfor mistake, correction in spelling_corrections.items():text = re.sub(mistake, correction, text)return text# Correct spelling errors in the sample text
cleaned_text = correct_spelling_errors(text_with_errors)print(cleaned_text)
# output
# But it’s not everything about more language refinement.
# other important aspect is ensuring accurate retrieval by correcting product name spellings.
# Additionally, refining descriptions enhances the coherence of the content.通过连贯一致的文本表示,我们的模型现在可以生成准确且上下文相关的响应。此过程还使语义搜索能够提取最佳上下文块,特别是在 RAG 上下文中。
步骤3:元数据处理
元数据收集,例如识别重要的关键字和实体,使我们可以轻松识别文本中的元素,我们可以使用这些元素来改进语义搜索结果,特别是在内容推荐系统等企业应用程序中。此过程为模型提供了额外的上下文,通常需要提高 RAG 性能。让我们将此步骤应用到另一个 Python 示例中。
Import spacy
import json# Load English language model
nlp = spacy.load(“en_core_web_sm”)# Sample text with meta data candidates
text = “””In a blog post titled ‘The Top 10 Tech Trends of 2024,’
John Doe discusses the rise of artificial intelligence and machine learning
in various industries. The article mentions companies like Google and Microsoft
as pioneers in AI research. Additionally, it highlights emerging technologies
such as natural language processing and computer vision.”””# Process the text with spaCy
doc = nlp(text)# Extract named entities and their labels
meta_data = [{“text”: ent.text, “label”: ent.label_} for ent in doc.ents]# Convert meta data to JSON format
meta_data_json = json.dumps(meta_data)print(meta_data_json)# output
“””
[{“text”: “2024”, “label”: “DATE”},{“text”: “John Doe”, “label”: “PERSON”},{“text”: “Google”, “label”: “ORG”},{“text”: “Microsoft”, “label”: “ORG”},{“text”: “AI”, “label”: “ORG”},{“text”: “natural language processing”, “label”: “ORG”},{“text”: “computer vision”, “label”: “ORG”}
]
“””该代码强调了spaCy 的 实体识别功能如何识别文本中的日期、人员、组织以及其他重要实体。这有助于 RAG 应用程序更好地理解上下文和单词之间的关系。
步骤4:上下文信息处理
在与LLM合作时,您通常可能会使用多种语言或管理充满各种主题的大量文档,这对于您的模型来说很难理解。让我们看一下两种可以帮助您的模型更好地理解数据的技术。
让我们从语言翻译开始。使用Google Translation API,代码翻译原文“Hello, how are you?”从英语到西班牙语。
From googletrans import Translator# Original text
text = “Hello, how are you?”# Translate text
translator = Translator()
translated_text = translator.translate(text, src=’en’, dest=’es’).textprint(“Original Text:”, text)
print(“Translated Text:”, translated_text)主题建模包括数据聚类等技术,就像将凌乱的房间整理成整齐的类别一样,帮助您的模型识别文档的主题并快速对大量信息进行排序。潜在狄利克雷分配 (LDA)是用于自动化主题建模过程的最流行的技术,是一种统计模型,可通过仔细观察单词模式来帮助找到文本中隐藏的主题。
在下面的示例中,我们将使用sklearn处理一组文档并识别关键主题。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation# Sample documents
documents = ["Machine learning is a subset of artificial intelligence.","Natural language processing involves analyzing and understanding human languages.","Deep learning algorithms mimic the structure and function of the human brain.","Sentiment analysis aims to determine the emotional tone of a text."
]# Convert text into numerical feature vectors
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)# Apply Latent Dirichlet Allocation (LDA) for topic modeling
lda = LatentDirichletAllocation(n_components=2, random_state=42)
lda.fit(X)# Display topics
for topic_idx, topic in enumerate(lda.components_):print("Topic %d:" % (topic_idx + 1))print(" ".join([vectorizer.get_feature_names()[i] for i in topic.argsort()[:-5 - 1:-1]]))# output
#
#Topic 1:
#learning machine subset artificial intelligence
#Topic 2:
#processing natural language involves analyzing understanding如果您想探索更多主题建模技术,我们建议从以下开始:
非负矩阵分解 (NMF)非常适合负值没有意义的图像等情况。当您需要清晰、可理解的因素时,它会很方便。例如,在图像处理中,NMF 有助于提取特征,而不会混淆负值。
当您拥有分布在多个文档中的大量文本并且想要查找单词和文档之间的联系时,潜在语义分析 (LSA)会发挥作用。 LSA 使用奇异值分解 (SVD)来识别术语和文档之间的语义关系,有助于简化任务,例如按相似性对文档进行排序和检测抄袭。
当您不确定文档中有多少数据时,分层狄利克雷过程 (HDP)可帮助您快速对海量数据进行排序并识别文档中的主题。作为LDA的扩展,HDP允许无限的主题和更大的建模灵活性。它识别文本数据中的层次结构,以完成理解学术论文或新闻文章中主题的组织等任务。
概率潜在语义分析 (PLSA)可帮助您确定文档与某些主题相关的可能性有多大,这在构建基于过去交互提供个性化推荐的推荐系统时非常有用。
演示:清理 GAI 文本输入
让我们通过一个例子将它们放在一起。在此演示中,我们使用 ChatGPT 在两位技术人员之间生成对话。我们将在对话中应用基本的清洁技术,以展示这些实践如何实现可靠且一致的结果。
synthetic_text = """
Sarah (S): Technology Enthusiast
Mark (M): AI Expert
S: Hey Mark! How's it going? Heard about the latest advancements in Generative AI (GA)?
M: Hey Sarah! Yes, I've been diving deep into the realm of GA lately. It's fascinating how it's shaping the future of technology!
S: Absolutely! I mean, GA has been making waves across various industries. What do you think is driving its significance?
M: Well, GA, especially Retrieval Augmented Generative (RAG), is revolutionizing content generation. It's not just about regurgitating information anymore; it's about creating contextually relevant and engaging content.
S: Right! And with Machine Learning (ML) becoming more sophisticated, the possibilities seem endless.
M: Exactly! With advancements in ML algorithms like GPT (Generative Pre-trained Transformer), we're seeing unprecedented levels of creativity in AI-generated content.
S: But what about concerns regarding bias and ethics in GA?
M: Ah, the age-old question! While it's true that GA can inadvertently perpetuate biases present in the training data, there are techniques like Adversarial Training (AT) that aim to mitigate such issues.
S: Interesting! So, where do you see GA headed in the next few years?
M: Well, I believe we'll witness a surge in applications leveraging GA for personalized experiences. From virtual assistants to content creation tools, GA will become ubiquitous in our daily lives.
S: That's exciting! Imagine AI-powered virtual companions tailored to our preferences.
M: Indeed! And with advancements in Natural Language Processing (NLP) and computer vision, these virtual companions will be more intuitive and lifelike than ever before.
S: I can't wait to see what the future holds!
M: Agreed! It's an exciting time to be in the field of AI.
S: Absolutely! Thanks for sharing your insights, Mark.
M: Anytime, Sarah. Let's keep pushing the boundaries of Generative AI together!
S: Definitely! Catch you later, Mark!
M: Take care, Sarah!
"""第 1 步:基本清理
首先,我们从对话中删除表情符号、主题标签和 Unicode 字符。
# Sample text with emojis, hashtags, and unicode characters# Tokenization
tokens = word_tokenize(synthetic_text)# Remove Noise
cleaned_tokens = [re.sub(r'[^\w\s]', '', token) for token in tokens]# Normalization (convert to lowercase)
cleaned_tokens = [token.lower() for token in cleaned_tokens]# Remove Stopwords
stop_words = set(stopwords.words('english'))
cleaned_tokens = [token for token in cleaned_tokens if token not in stop_words]# Lemmatization
lemmatizer = WordNetLemmatizer()
cleaned_tokens = [lemmatizer.lemmatize(token) for token in cleaned_tokens]print(cleaned_tokens)第 2 步:准备我们的提示
接下来,我们将制作一个提示,要求模型根据从我们的综合对话中收集的信息作为友好的客户服务代理进行响应。
MESSAGE_SYSTEM_CONTENT = "You are a customer service agent that helps
a customer with answering questions. Please answer the question based on the
provided context below.
Make sure not to make any changes to the context if possible,
when prepare answers so as to provide accurate responses. If the answer
cannot be found in context, just politely say that you do not know,
do not try to make up an answer."第 3 步:准备交互
让我们准备与模型的交互。在此示例中,我们将使用 GPT-4。
def response_test(question:str, context:str, model:str = "gpt-4"):response = client.chat.completions.create(model=model,messages=[{"role": "system","content": MESSAGE_SYSTEM_CONTENT,},{"role": "user", "content": question},{"role": "assistant", "content": context},],)return response.choices[0].message.content第 4 步:准备问题
最后,让我们向模型提出一个问题,并比较清洁前后的结果。
question1 = "What are some specific techniques in Adversarial Training (AT)
that can help mitigate biases in Generative AI models?"在清洁之前,我们的模型会生成以下响应:
response = response_test(question1, synthetic_text)
print(response)#Output
# I'm sorry, but the context provided doesn't contain specific techniques in Adversarial Training (AT) that can help mitigate biases in Generative AI models.清理后,模型会生成以下响应。通过基本清洁技术增强理解,该模型可以提供更彻底的答案。
response = response_test(question1, new_content_string)
print(response)
#Output:
# The context mentions Adversarial Training (AT) as a technique that can
# help mitigate biases in Generative AI models. However, it does not provide
#any specific techniques within Adversarial Training itself.人工智能成果的光明未来
RAG 模型具有多种优势,包括通过提供相关上下文来增强人工智能生成结果的可靠性和一致性。这种情境化显着提高了人工智能生成内容的准确性。
为了充分利用 RAG 模型,在文档摄取过程中强大的数据清理技术至关重要。这些技术解决了文本数据中的差异、不精确的术语和其他潜在错误,显着提高了输入数据的质量。当使用更干净、更可靠的数据进行操作时,RAG 模型可提供更准确、更有意义的结果,使 AI 用例能够在跨领域提供更好的决策和解决问题的能力。
![Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序(0)](https://img-blog.csdnimg.cn/direct/92d4e9ec7ef8496c911afe7f831eedde.png)










![[NKCTF2024]-PWN:leak解析(中国剩余定理泄露libc地址,汇编覆盖返回地址)](https://img-blog.csdnimg.cn/direct/de3fdfbaf62b403b9833ad27d045f2d8.png)
