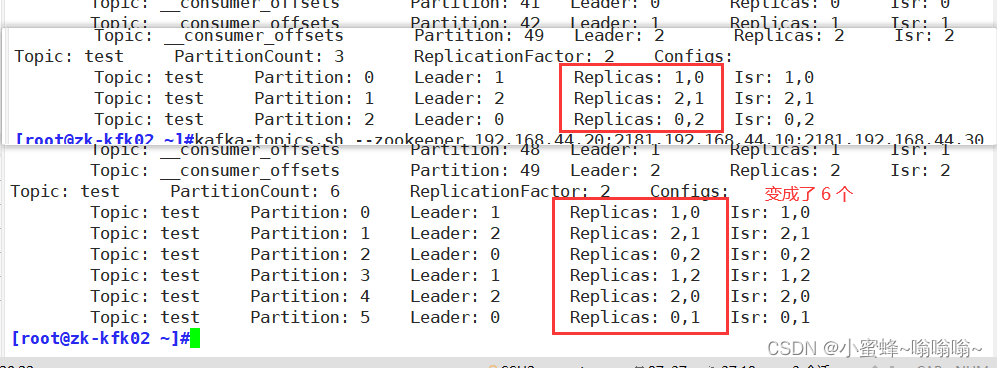
1,顺序表实现---动态分配
#include<stdlib.h>
#define InitSize 10
typedef struct {int *data;//静态分配int length;int MaxSize;
}SqList;
void InitList(SqList& L)
{L.data = (int*)malloc(InitSize * sizeof(int));//分配空间L.length = 0;L.MaxSize = InitSize;//初始空间为10}
void ListInsert(SqList& L, int x, int a)
{L.data[x] = a;
}
void Increaselength(SqList& L, int len)
{int *p = L.data;L.data = (int*)malloc((InitSize + len) * sizeof(int));//重新开辟空间for (int i = 0; i < L.MaxSize;i++){L.data[i] = p[i];}L.MaxSize = InitSize + len;free(p);}
int main()
{SqList q;InitList(q);ListInsert(q, 2, 4);Increaselength(q, 5);ListInsert(q, 12, 2);printf("data[2]=%d,data[12]=%d", q.data[2], q.data[12]);system("pause");return 0;
}

 第i个元素中的i表示的是位序
第i个元素中的i表示的是位序
2, 静态分配的插入与删除操作:
2.1插入操作:
typedef struct {int data[MaxSize];int length;}SqList;
void InitList(SqList& L)
{L.length = 0;for (int i = 0; i <MaxSize-1; i++){L.data[i] = i;//赋予原始数据,注意不要插满L.length++;}}
bool ListInsert(SqList &L,int i,int e)//在第i个位置插入e
{if (i<1 || i>L.length + 1)return false;if (L.length >= MaxSize)//存储空间已满{return false;}for(int j=L.length;j>=i;j--){L.data[j] = L.data[j - 1];}L.data[i - 1] = e;L.length++;return true;}
int main()
{SqList L;InitList(L);if (ListInsert(L, 8, 1)){printf("data[7]=%d ", L.data[7]);//验证插入}system("pause");return 0;}
2.2,删除操作:
typedef struct {int data[MaxSize];int length;}SqList;
void InitList(SqList& L)
{L.length = 0;for (int i = 0; i < MaxSize - 1; i++){L.data[i] = i;//赋予原始数据,注意不要插满L.length++;}}
bool ListDelete(SqList &L,int i,int &e)//在第i个位置插入e
{if (i<1 || i>L.length)return false;e=L.data[i - 1];//赋值for(int j=i;j<L.length;j++){L.data[j-1] = L.data[j];}L.length--;return true;}int main()
{SqList L;InitList(L);int e = -1;if (ListDelete(L, 8, e))//位置8的元素是7{printf("删除的元素是%d data[7]=%d", e,L.data[7]);//验证删除,删除后data[7]=8}system("pause");return 0;} 3,顺序表的查找:
3,顺序表的查找:
3.1按位查找
动态分配和普通数组访问方式相同,时间复杂度为O(1)
GetElem(SqList L,int i)
{
return L.data[i-1];
}3.2按值查找
动态分配方式:
int LocatElem(SqList L, int e)
{
for(int i=0;i<L.length;i++)
{
if(L.data[i]==e)
return i+1;
}
return 0;}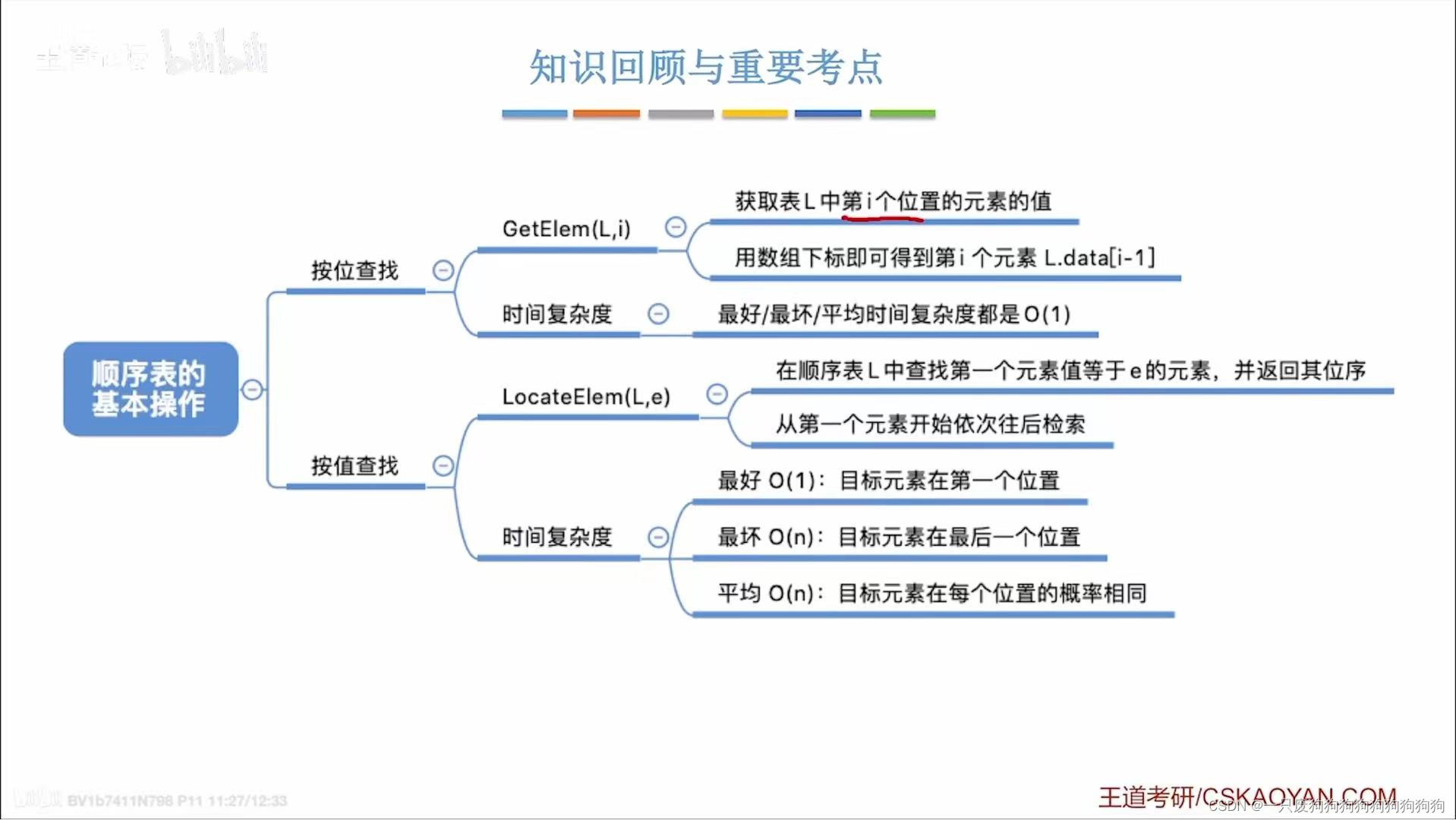
4,链表初始化
4.1不带头结点的单链表的初始化:
与顺序表不同,单链表是用指针来定义
typedef struct LNode {int data;struct LNode* next;//每个元素包括数据和指向下一个节点的指针}LNode,*LinkList;//LNode*等价于LinkList
bool InitList(LinkList &L)//声明是一个单链表
{L = NULL;return true;}
bool IsEmpty(LinkList &L)//声明是一个单链表
{return (L == NULL);}
int main()
{LinkList L;//声明一个指向单链表的指针InitList(L);if(IsEmpty(L))printf("初始化成功");system("pause");return 0;}4.2,带头结点的单链表的初始化:
typedef struct LNode {int data;struct LNode* next;//每个元素包括数据和指向下一个节点的指针}LNode,*LinkList;//LNode*等价于LinkList
bool InitList(LinkList &L)//声明是一个单链表
{L = (LNode*)malloc(sizeof(LNode));//头指针指向下一个节点:即为头节点if (L == NULL)return false;//没有内存,分配失败L->next = NULL;//头节点暂时没有节点return true;}
bool IsEmpty(LinkList &L)//声明是一个单链表
{return (L == NULL);}
int main()
{LinkList L;InitList(L);if(IsEmpty(L)==false)printf("初始化成功");system("pause");return 0;}
5,链表插入操作:
5.1,带头结点,按位序插入:
typedef struct LNode {int data;struct LNode* next;//每个元素包括数据和指向下一个节点的指针}LNode,*LinkList;//LNode*等价于LinkList
//带头结点按位序插入
bool ListInsert(LinkList& L,int i,int e)//在第i个位置插入e
{if (i < 1)return false;int j = 0;LNode *p;p= L;//是从第0个节点开始遍历,所以p应该与头节点相同while (p != NULL && j < i - 1)//找到第i-1的节点{p = p->next;j++;}if (p == NULL)//超出链表长度{return false;}LNode *s = (LNode*)malloc(sizeof(LNode));s->data = e;s->next = p->next;p->next = s;return true;}
bool InitList(LinkList &L)//声明是一个单链表
{L = (LNode*)malloc(sizeof(LNode));//头指针指向下一个节点:即为头节点if (L == NULL)return false;//没有内存,分配失败L->next = NULL;//头节点暂时没有节点return true;}
bool IsEmpty(LinkList &L)//声明是一个单链表
{return (L == NULL);}
int main()
{LinkList L;InitList(L);if(IsEmpty(L)==false)printf("初始化成功");if(ListInsert(L, 1, 1))printf("插入成功");system("pause");return 0;}5.2,不带头节点按位序插入:
bool ListInsert(LinkList& L,int i,int e)//在第i个位置插入e
{if (i < 1)return false;if (i == 1)//此处插入第一个节点和其他节点不同,直接与L交互{LNode* s = (LNode*)malloc(sizeof(LNode));s->data = e;s->next = L;//指向L指向的节点L = s;//需要更改头结点的指向,比较麻烦return true;}int j = 1;//没有第0个节点LNode *p;p= L;//是从第0个节点开始遍历,所以p应该与头节点相同while (p != NULL && j < i - 1)//找到第i-1的节点{p = p->next;j++;}if (p == NULL)//超出链表长度{return false;}LNode* s = (LNode*)malloc(sizeof(LNode));s->data = e;s->next = p->next;p->next = s;return true;}5.3,指定节点的后插操作:
//在指定节点后插入一个元素
bool InsertNextLNode(LNode *p,int e)//传入节点即可,不需要传入表
{if (p == NULL)return false;//节点选择错误LNode* s = (LNode*)malloc(sizeof(LNode));if (s == NULL)//内存分配不够return false;s->data = e;s->next = p->next;p->next = s;return true;
} 
5.4前插操作:
在p节点之前插入s节点
思路:无法找到前驱节点,因此可以插在p节点之后,然后将两个节点中的数据调换
bool InsertPriorNode(LNode* p, LNode* s)
{if (p == NULL || s == NULL)return false;s->next = p->next;p->next = s;int temp = s->data;s->data = p->data;p->data = temp;return true;
}6,链表删除操作:
6.1,带头结点按位序删除第i个节点:
思路:先找到第i-1节点,然后将前一个结点的next指针指向后一个结点的next指针
bool ListDelete(LinkList L, int i, int& e)
{if (i < 1)return false;LNode* p = L;//当前指向结点int j = 0;while (p != NULL&&j<i-1) {//找到i-1结点p = p->next;j++;}if (p == NULL)return false;if (p->next== NULL)//需要删除的结点也为空return false;LNode* q = p->next;//应当被删除的结点e = q->data;p->next = q->next;free(q);return true;
}6.2,指定节点的删除p:
将p的后一个结点复制到p,然后将p的后一个结点释放掉
bool DeleteNode(LNode* p)
{if (p == NULL)return false;LNode* q = p->next;p->data = p->next->data;p->next = q->next;free(q);return true;
}注意:如果p是最后一个结点,只能从表头依次寻找p的前驱
7,单链表的查找(带头结点)
7.1按位查找
LNode *GetElem2(LinkList L, int i)
{if (i < 0)//第位序0返回的是头节点return NULL;LNode* p;p = L;int j = 0;//带头结点下标从0开始while (p != NULL && j < i){p = p->next;j++;}return p;
}回顾:

7.2按值查找
LNode* GetElem3(LinkList L, int e)
{LNode* p=L->next;while (p != NULL && p->data!=e)//因为头节点中没有数据,所以应该从头节点的下一个结点开始查找{p = p->next;}return p;
}求表长:
int GetLength(LinkList L)
{LNode* p = L; int len = 0;while (p->next != NULL){p = p->next;len++;}return len;
}8,单链表的建立:
8.1尾插法建立单链表
LinkList List_TailInsert(LinkList& L)
{int a = 0;L = (LinkList)malloc(sizeof(LNode));//建立头结点scanf("%d", &a);LNode* r,*s = L;//r是尾结点while (a != 9999)//结束标志{s = (LNode*)malloc(sizeof(LNode));//放入新节点s->data = a;r->next = s;//建立链表连接r = s;//新的尾结点scanf("%d", &a);//循环输入数字}r->next = NULL;return L;}8.2头插法建立单链表
LinkList List_HeadInsert(LinkList& L)
{int a = 0;LNode* s;L = (LinkList)malloc(sizeof(LNode));//建立头结点L->next = NULL;//初始化单链表,以防有脏数据scanf("%d", &a);while (a != 9999)//结束标志{s = (LNode*)malloc(sizeof(LNode));//放入新节点s->data = a;s->next= L->next;//建立链表连接L->next = s;//新的尾结点scanf("%d", &a);//循环输入数字}return L;}尾插法元素排列为顺序,头插法元素排列为逆序,头插法可以用于链表的逆置
9,双链表(带头结点):
9.1定义:
typedef struct DNode {int data;struct DNode *prior,* next;
}DNode,*DLinkList;
bool InitDLinkList(DLinkList &L)
{L = (DNode*)malloc(sizeof(DNode));//分配头结点if (L == NULL)return false;L->prior = NULL;//头结点的前驱节点都为NULL;L->next = NULL;return true;
}
int main()
{DLinkList L;InitDLinkList(L);}9.2插入操作(在p结点后插入s结点)
bool InsertNextDNode(DNode* p, DNode* s)
{if (p == NULL && s == NULL)return false;s->next = p->next;if (p->next != NULL)//p有后继节点p->next->prior = s;//则后继节点的前继指针指向ss->prior = p;p->next = s;return true;
}9.3删除操作(删除p结点的后继节点):
bool DeleteNextDNode(DNode* p)
{if (p == NULL)return false;DNode* q = p->next;if (q == NULL)return false;//没有后继节点p->next = q->next;if (q->next != NULL)//后继结点不为最后一个结点q->next->prior = p;//则后继节点的前继指针为sfree(q);return true;
}9.4销毁双链表:
void DestoryList(DLinkList &L)//L代表的是链表的头指针
{while (L->next != NULL){DeleteNextDNode(L);//从表头开始删除}free(L);//释放头结点L = NULL;//头指针指向NULL
}9.5遍历:
向后遍历:
while(p!=NULL)
{
p=p->next;
}向前遍历(跳过头结点):
while(p->prior!=NULL)
{
p=p->prior;} 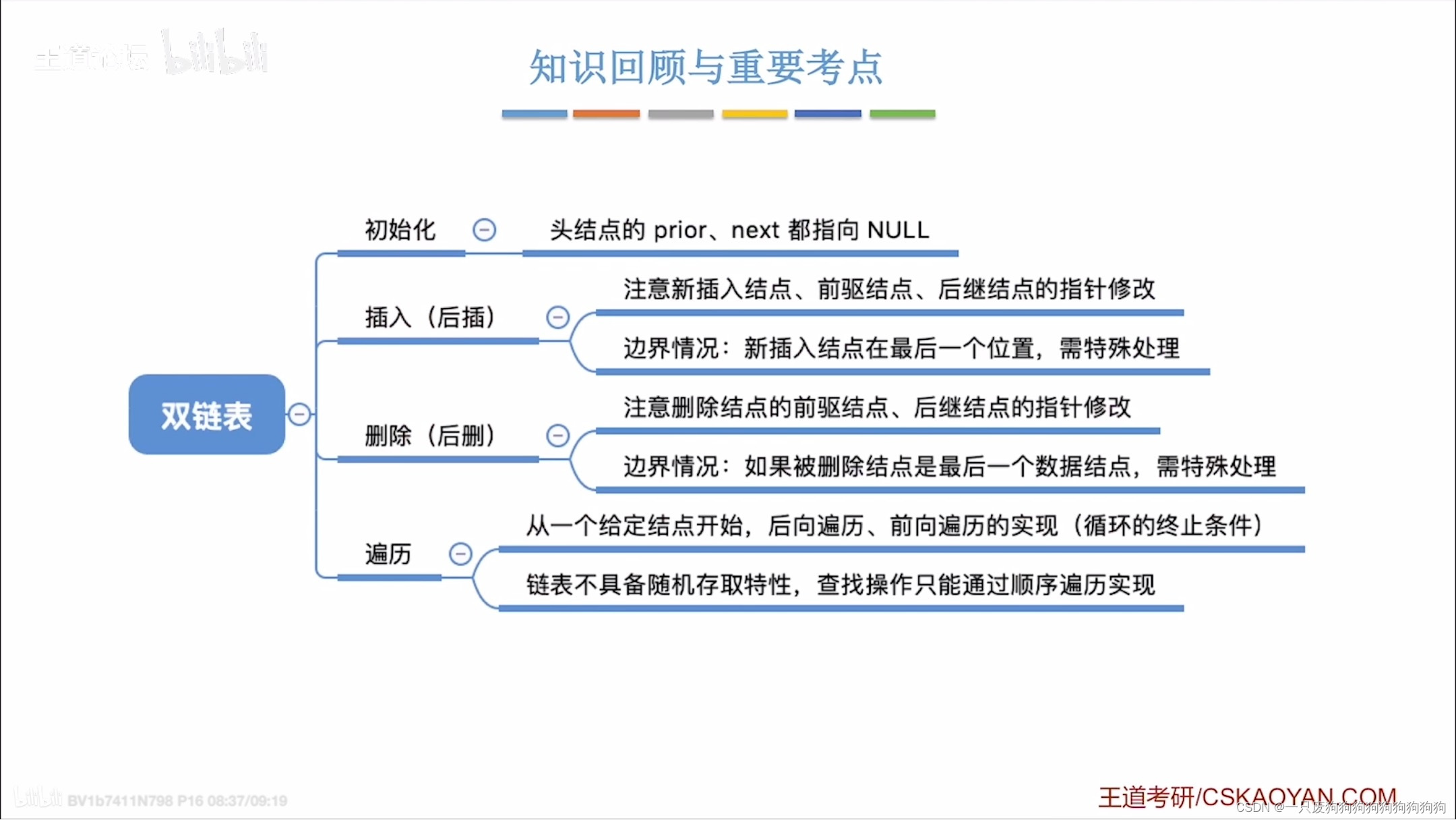
10,循环链表:
10.1循环单链表
定义:
typedef struct LNode {int data;struct LNode* next;
}LNode,*LinkList;//初始化相同
bool InitList(LinkList& L)
{L = (LNode*)malloc(sizeof(LNode));//定义头结点if (L == NULL)//空间分配失败return false;L->next = L;//头指针只向自己return true;
}
bool IsEmpty(LinkList L)
{if (L->next == L)return true;elsereturn false;
}
bool IsTail(LinkList L,LNode *p)//判断p结点是否为尾结点
{if (p->next == L)return true;elsereturn false;
}从一个结点出发,不同于单链表只能找到后续的各个节点,循环单链表可以找到其他任何一个结点
10.2循环双链表:
初始化:
判断是否为空是否是表尾结点与循环单链表相同,初始化与双链表不同的是:
L->prior=L;
L->next=L;插入后继结点:
bool InsertNextDNode(DNode* p, DNode* s)
{s->next = p->next;p->next->prior = s;//双链表需要判断是否是最后一个结点,循环双链表不需要s->prior = p;p->next = s;return true;
}删除后继结点:
void DeleteNextDNode(DNode* p)
{p->next = q->next;q->next->prior = p;//双链表需要判断是否是最后一个结点,循环双链表不需要free(q);}
11,静态链表:用数组的方式实现链表
初始化:
#define MaxSize 10
typedef struct{
int data;
int next;
}SLinkList[MaxSize];
int main(){
SLinkList a;}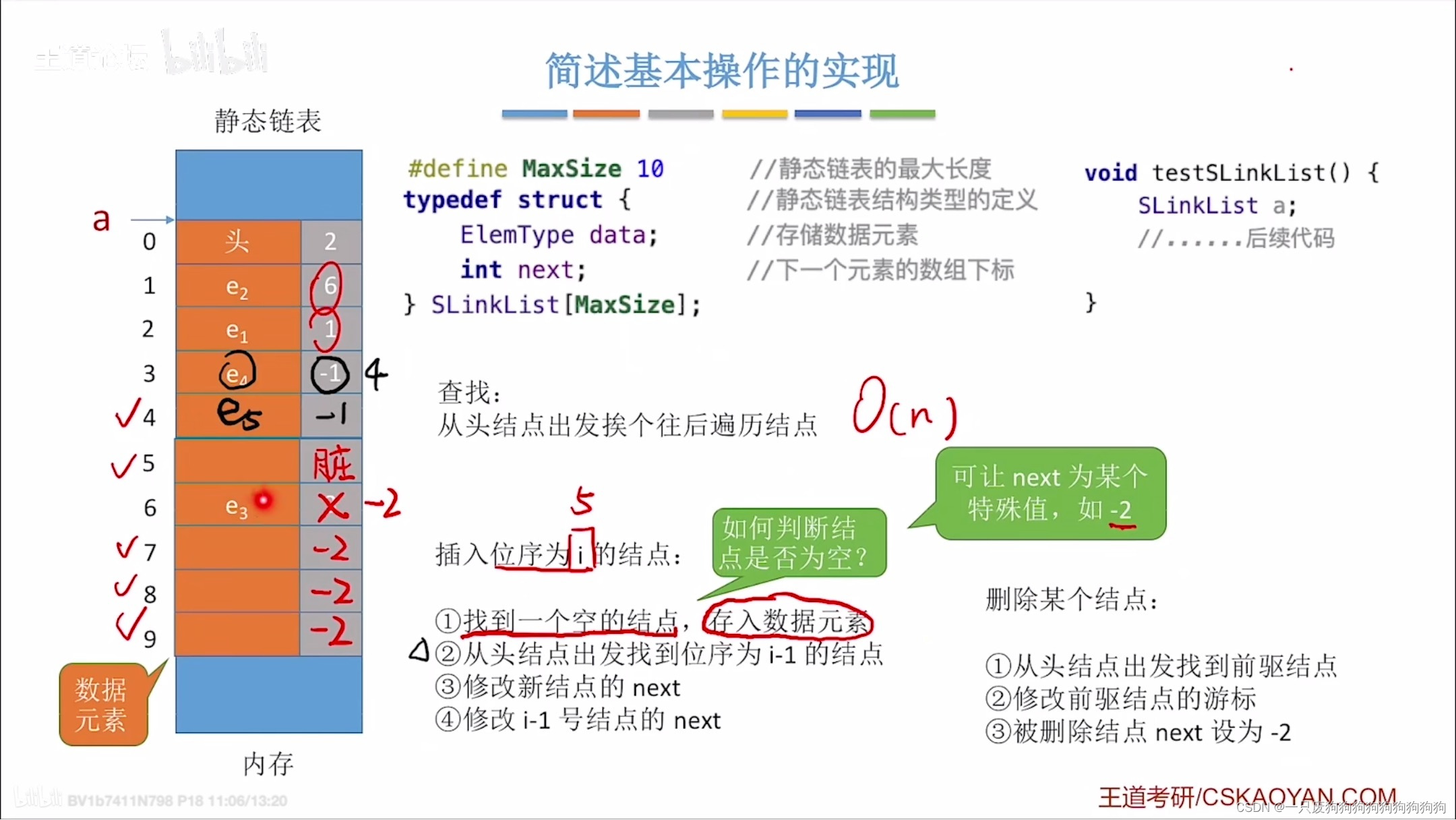
12,顺序表与链表的比较

![Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序(0)](https://img-blog.csdnimg.cn/direct/92d4e9ec7ef8496c911afe7f831eedde.png)