目录
编辑
1.优先级是什么
2.linux中的优先级是怎么实现的
ps -la 命令查看当前用户启动的进程编辑
linux下调整优先级:
①先top一下
②点击r
③需要输入进程的pid
④回车
编辑 ⑤输入想将优秀级修改的值:
linux进程优先级范围为什么必须是【60,99】
linux为什么让优先级的调整是一种受限制的状态:
3.linux下进程的调度与切换
重点:并发---涉及到进程切换
理解进程切换:
linux实现进程调度的算法:linux2.6如何进行程序调度:
①queue【140】进程优先级数组
②bitmap[5] 位图--提升优先级的遍历效率
③过期队列和活跃队列
④两个struct q * 的指针,实现活跃队列和过期队列的内容切换
4.总结 进程的创建到调度
1.优先级是什么
我们日常生活中,要涉及确定优先级,一定是我们需要访问某种资源,食堂打饭排队,谁先打饭,
那么进程也是需要资源支撑的,
前提:进程要访问某种资源,进程进行一定的方式(排队),确定享受资源的先后顺序。
优先级和权限的区别:
本质区别是:权限觉得能不能,优先级决定先后,只要到了优先级这一层那么说明权限几乎已经具备。
为什么要存在优先级:
本质原因:资源过少
而资源的多少是一个相对的概念,相对于需求资源的人的数量。为什么需要运行队列,cpu只有一个
2.linux中的优先级是怎么实现的
编写代码如下:
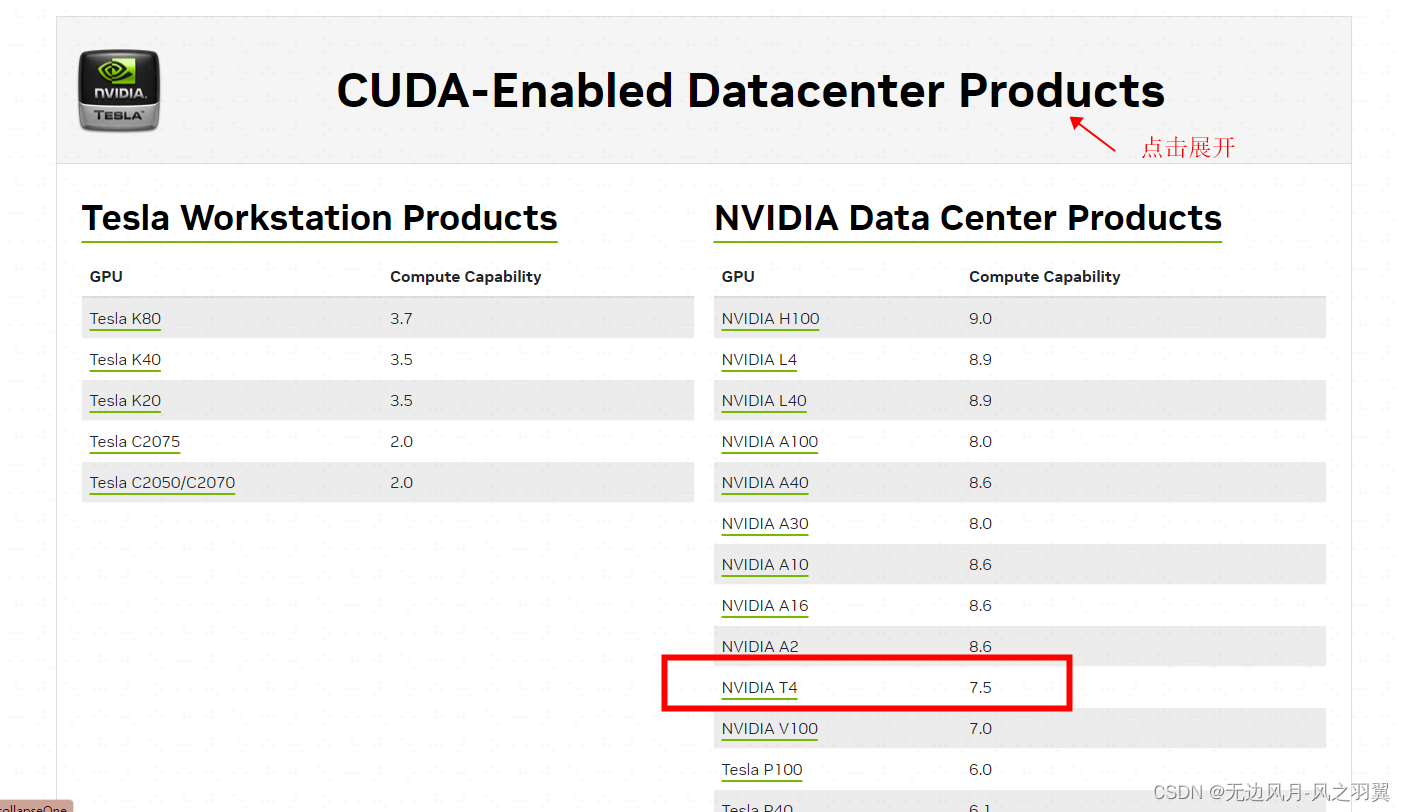
ps -la 命令查看当前用户启动的进程
PRI就是优先级
task_struct{
//优先级int PRI}就是计算机里面的整数,,相当于排队给你一个号码
linux默认优先级从80开始
linux优先级可以在启动前后中被修改
linux优先级的范围:【60,99】 40个数字
linux优先级本质是一个数字,数字越小,优先级越高
linux下调整优先级:
(实际中没有需要我们调整优先级的环境或者情况)
top命令
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
①先top一下

②点击r

③需要输入进程的pid

④回车
 ⑤输入想将优秀级修改的值:
⑤输入想将优秀级修改的值:
我们这里测试输入10回车

PRI变为90了,NI变为10
linux中允许 用户调整优先级,但是不能直接让你修改pri,而是在linux中存在一个nice值的概念,是修改nice值。这个nice不是优先级,而是进程优先级的修正数据。
真正的优先级 = 老的优先级(priold)+nice值(这就是内核确认优先级的方式)
linux进程优先级范围为什么必须是【60,99】
我们做一个极端值测试
刚才的进程优先级被调成90了
我们现在top
r一下

设置过于频繁不让设置
 sudo top
sudo top
在执行r就行

此时 :

说明我们的nice值是被覆盖写入的,刚才是10,现在是-10 ,可是pri变成90,不应该老的优先级+nice = 80吗
我们看下面的prI 为80,NI为0,如果我们真的变成80 -10 数据就不一致了,
老的pRI都是80开始,
我们将优先级设置100,


说明我们的linux内核会做判断, 如果nice调整过大,只会取nice极值,极大值为19.

nice值取值范围【-20,19】,所以优先级的取值范围为【60,99】
linux为什么让优先级的调整是一种受限制的状态:
如果不加限制,很多的程序员工程师就可以将自己进程的优先级调整非常小,别人的调整的非常大,系统中还有些正常进程。优先级决定了进程享受资源的前后,如果进程的优先级很小,调度器cpu在短时间内较大概率会频繁的调度这个进程,导致调度不太平衡,导致优先级高的优先得到资源,后续还有源源不断的进程产生,最后会导致常规进程很难得到cpu资源,意味着这个进程很长时间不被调度,作为一个要运行的进程,变得很卡顿,而其他优先级高的进程很快就跑完了,所以,这种情况称之为“进程饥饿”,就像去打饭长由于被插队长时间打不到饭。我们任何的现在的分时操作系统,按照时间段进程运行,每个进程运行一个时间段,在调度上都要进行公平的调度,否则会导致饥饿问题。所以进程优先级调整必须受限制。
3.linux下进程的调度与切换
概念准备
①进程在运行的时候,放在cpu上,cpu必须将进程代码执行完,才可以吗?
不对,死循环本身就不会执行完,现代操作系统,都是基于时间片进行轮转执行。
时间片:给每一个进程规定一个运行的最大时间。跑完一个时间片,操作系统将整个进程从cpu剥离,由调度器帮助完成。
进程和进程之间一定存在竞争,从优先级就可以看出来,本质cpu资源少,进程数目多,但是不能让大家恶意竞争,所以得有调度器基于时间片和优先级轮转调度。
进程之间是具有独立性的:
关掉任何一个进程对其他进程的运行都不影响(不影响别的进程的执行,代码和数据是安全的)。进程在运行期间,逻辑上我们认为其独享资源,多进程运行期间互不干扰。
如果电脑里面有两个cpu,在任意一个时刻,可以允许两个进程被同时调度执行,这叫两个进程并行运行。(多核cpu:所谓多核,一块cpu里面有一个控制器和很多运算器,可以跑很多计算,但是这些计算都是一个进程中的多条代码),如果计算机一个cpu,每个cpu都有其时间片,假设这个时间片为1毫秒,我们此时有十个进程,那么1秒里面就有1000个时间片,也就是意味着每个进程会被调度100次,微观上是卡顿的,但是人类感知不到,所以我们就感觉一个时间段内多个任务在跑,一个时间段内,多个代码可以推进叫做并发,是指进程在一个cpu下才有进程频繁切换的动作。一段时间内进行频繁的进程切换,就像当年葫芦娃的动画片是一张一张画出来,加速翻动。
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高 效完成任务,更合理竞争相关资源,便具有了优先级
独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行
并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为 并发
重点:并发---涉及到进程切换
cpu中存在大量寄存器:eax,ebx,ecx,edx,eds/ecs/fg/gs/eip/cro,crocr4 程序状态字,浮点数寄存器
ebp.esp(寄存器保存大量的临时数据)
eip俗称pc指针,程序记步器。
程序状态字:除0,异常退出
不同寄存器有不同的功能:比如eax用于保存临时数据
进程在cpu上运行,cpu上的所有寄存器要围绕这个进程进行展开运算运行,所以进程在运行的过程中,会产生大量的临时数据,放在cpu的寄存器。这些临时数据存在的意义支撑了当前进程运行到了什么状态,运行到了哪一步,不属于寄存器的数据都属于进程独有的数据。
理解进程切换:
所有的保存都是为了恢复,所有的恢复都是为了继续上次的运行位置继续运行。
当前进程的信息都在寄存器保存,如果进程运行时间片到了,进程切换时,将临时数据带走,
cpu内部所有的临时数据,我们叫做进程的硬件上下文数据,所以当进程走的时候,要将这些临时信息保存下来,保存在pcb字段,这个动作叫做保护上下文,此时这个进程已经算是从cpu上剥离了。首次调度,数据覆盖,第二次调度数据恢复:进程被放到cpu上开始运行,将曾经保存的硬件上下文数据进行恢复,
、两个工作:保护山下文,上下文恢复
switch_to
->__switch_to... //浮点寄存器等的切换->cpu_switch_to(prev, next)
arch/arm64/kernel/entry.S:
1032 /*
1033 * Register switch for AArch64. The callee-saved registers need to be saved
1034 * and restored. On entry:
1035 * x0 = previous task_struct (must be preserved across the switch)
1036 * x1 = next task_struct
1037 * Previous and next are guaranteed not to be the same.
1038 *
1039 */
1040 ENTRY(cpu_switch_to)
1041 mov x10, #THREAD_CPU_CONTEXT
1042 add x8, x0, x10
1043 mov x9, sp
1044 stp x19, x20, [x8], #16 // store callee-saved registers
1045 stp x21, x22, [x8], #16
1046 stp x23, x24, [x8], #16
1047 stp x25, x26, [x8], #16
1048 stp x27, x28, [x8], #16
1049 stp x29, x9, [x8], #16
1050 str lr, [x8]
1051 add x8, x1, x10
1052 ldp x19, x20, [x8], #16 // restore callee-saved registers
1053 ldp x21, x22, [x8], #16
1054 ldp x23, x24, [x8], #16
1055 ldp x25, x26, [x8], #16
1056 ldp x27, x28, [x8], #16
1057 ldp x29, x9, [x8], #16
1058 ldr lr, [x8]
1059 mov sp, x9
1060 msr sp_el0, x1
1061 ret
1062 ENDPROC(cpu_switch_to)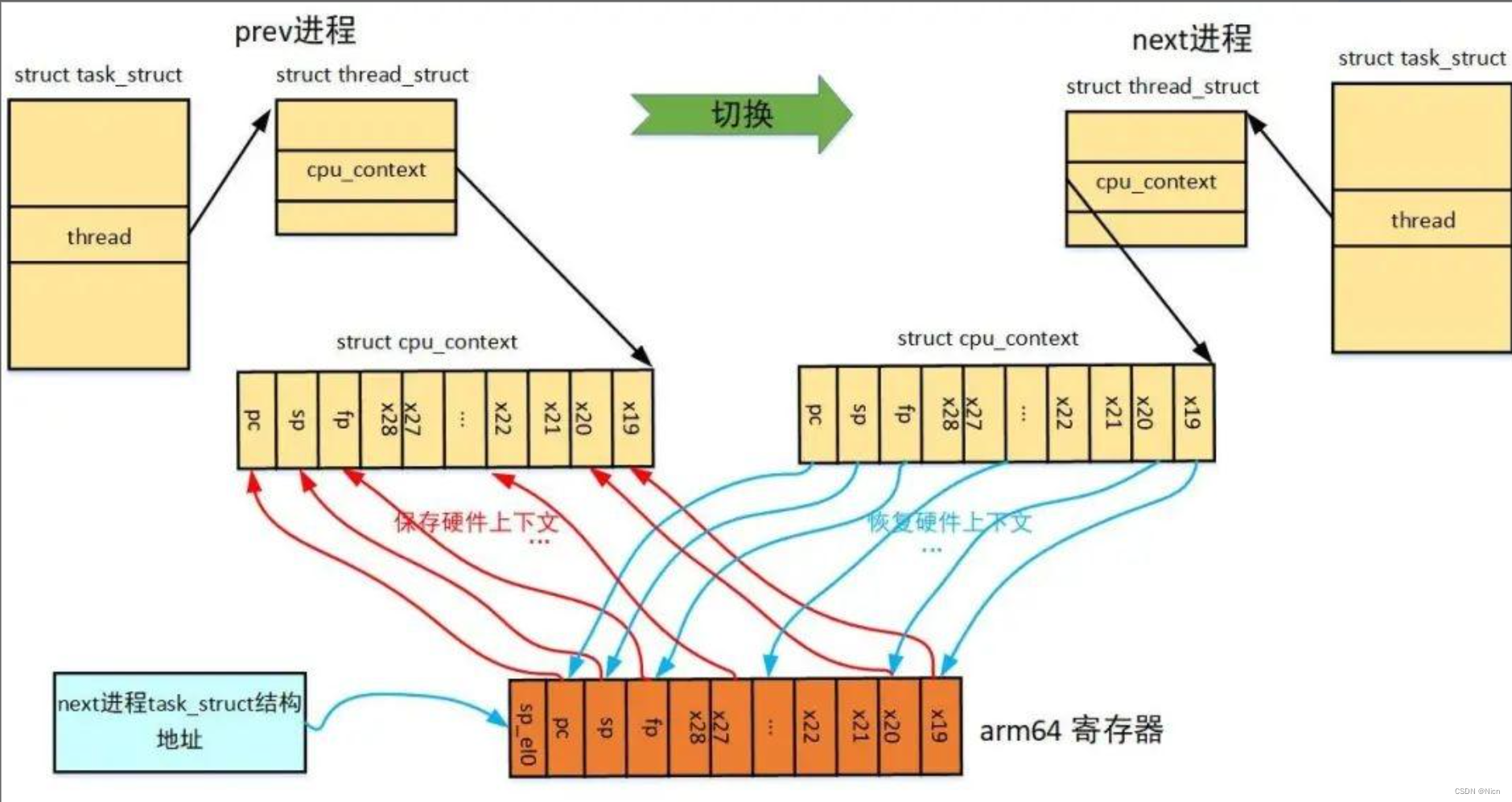
cpu有多个寄存器,但是只有一套,寄存器内部保存的数据可以有多套。
区分:寄存器vs寄存器的内容
铁打的寄存器,流水的数据。虽然寄存器数据放在了一个共享的cpu设备里面,但是所有的数据起其实都是进程私有的。进程在剥离的时候会将临时数据拿走。也就是cpu内的数据在任意时刻属于一个进程,大家去读书馆看同一本书,自己看到那一页这样的数据只属于你,大家都坐在一个位置读书,读一本书,但是属于自己的还是只会属于自己。
进程在cpu上的一生:
首先执行:生成硬件上下文,执行时间片,保存上下文投递到pcb,等待,再次被调用在恢复上下文,所有进程按照这样一样的套路然后被cpu轮流调度,而相关的内容和数据都在内存里,所以访问的速度会非常快,所以进程之间进行轮转的速度也不慢。是按照基于时间片的fifo算法运行。
linux实现进程调度的算法:linux2.6如何进行程序调度:
要考虑优先级和饥饿问题,更重要的linux具体的进程调度要考虑效率
一个cpu对应的运行队列:
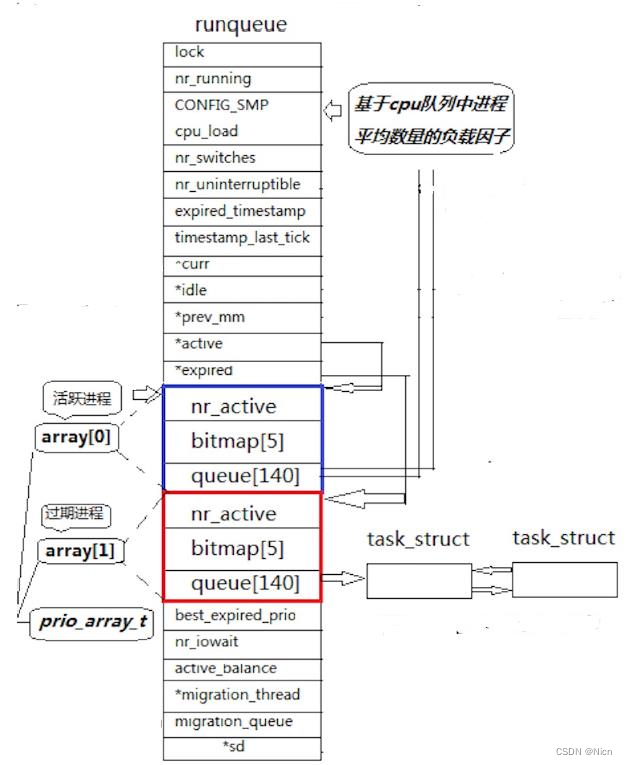
①queue【140】进程优先级数组
queue 是一个task_struct * 的指针数组,未来指向一个一个的进程,数组大小为140,0-99是不用的,只采用:100-139,linux不仅仅要考虑基于公平的进程调度这样的原则对应的操作系统 是一种实时操作系统,与分时操作系统相对的:
实时操作系统:(作为软件开发大概率用不到),我们现在的操作系统调度的时候都是相对公平的,保证进程在相同的时间片内享受同等的资源,即使有优先级,差距也不会很明显,但是有一类操作系统叫实时操作系统:一但进程运行起来了,就必须将当前进程跑完,然后再跑下一个,所有的进程都必须严格按照顺序去进行依次执行,如果有更高优先级的进行,先调度,实时操作系统对用户有高响应,用户的动作来了,操作系统就必须立马执行。这种叫做实时操作系统。这种操作系统适合于我们现在的自动驾驶,我用户要刹车了,操作系统不能说进程要排队,先把QQ音乐运行完。所以学习操作系统很多东西是在不同情况下使用的,所以,我们当前操作系统只考虑我们的100-139,0-99表示的实时优先级。
进程被调度后,然后通过优先级:优先级-60+100放入数组的对应下标的优先级队列中:
比如优先级为80,80-60+100 = 120,放入下标为120的进程中
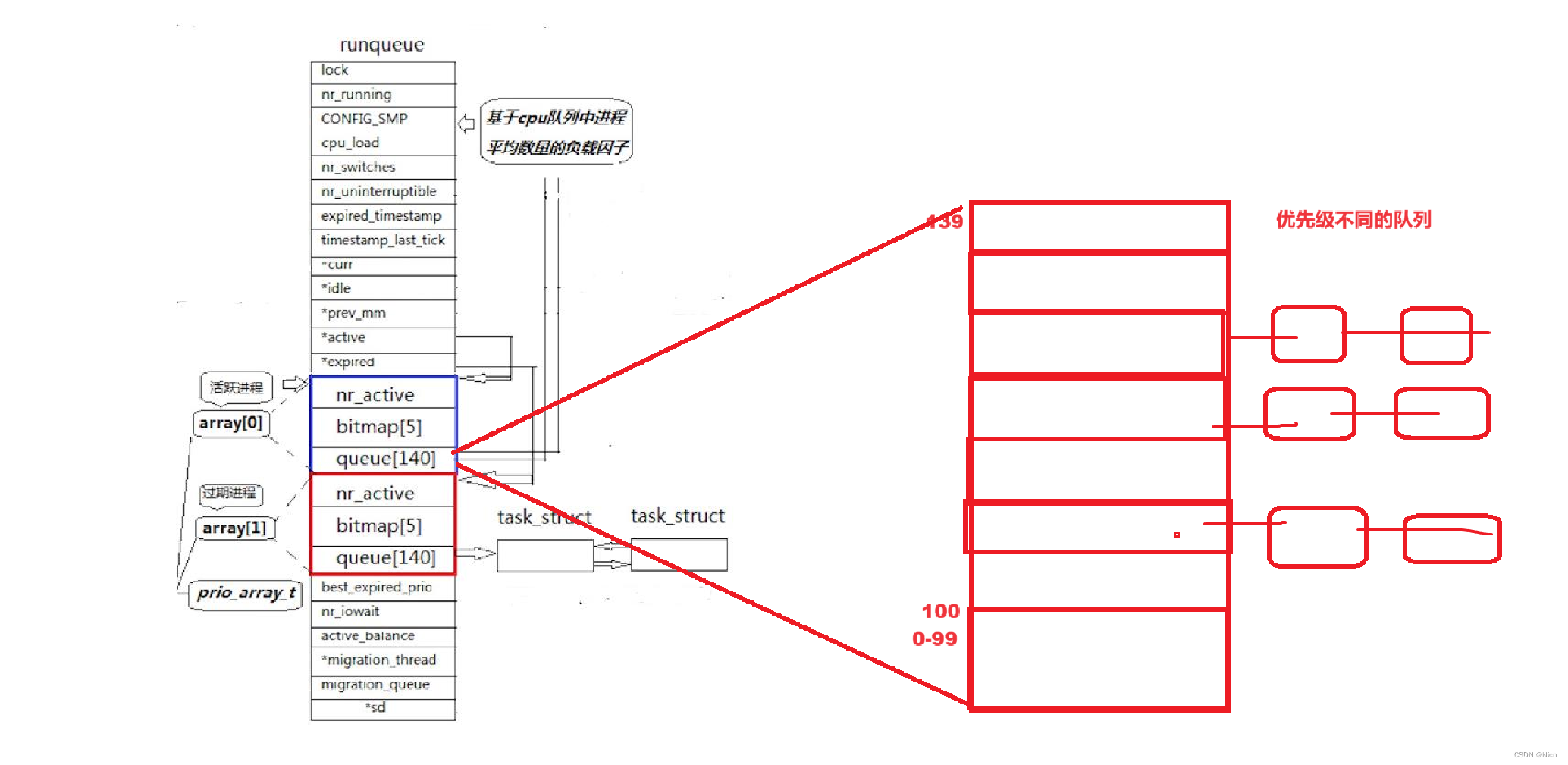
进程进入队列不是胡乱进入的,而是结合自己的优先级进入,每个进程根据自己的优先级进行排队,优先级队列,操作系统只用对优先级数组通过下标遍历,实际操作系统没有那么多的进程,
②bitmap[5] 位图--提升优先级的遍历效率
但是我们这里毕竟还是40个队列,难道每次都要变量整个数组检测吗?虽然是常数级,而且判断也只不过是为空不为,但是还是比较麻烦,linux给我们提供了一个bitmap[5]这个变量,是一个int 类型变量,一个整型4个字节,32个比特位,32*5 = 160,160个比特位,用比特位的位置,表示哪一个位置,比特位的内容表示该队列是否为空:其中有20个比特位不用:

比特位为1说明有进程队列,如果为0就说明没有进程队列,所以检测队列中是否有进程就转换为检测对应的比特位是否是1.位操作比遍历操作快得多。我们当时检测比特位为1的数目这样的题目是做过的,以整型为单位,一次可以检测32个队列,如果bitmap某一个下标(0-4),位0,说明这32个进程队列为空,数字不等于0,说明有1,那么我们找到最小比特位为1的进程队列就可以,效率大大提升。在选择进程这件事上时间复杂度几乎可以做到O(1),不管有多少进程,对于操作系统来说只是检测位图的事情,所以这也被称之为:O(1)调度算法
但是到现在进程的调度还是有一些疑问:如果我们现在的进程很多都是优先级高的进程,是不是就意味着优先级低的进程的饥饿went还有实际上进程在运行的时候,操作系统还要放入进程,那么会不会导致一个进程优先级的进程队列一直在运行,其他优先级的就是饥饿状态,是存在的。但是我们的设计者非常聪明:又搞了一块一模一样的结构:
③过期队列和活跃队列
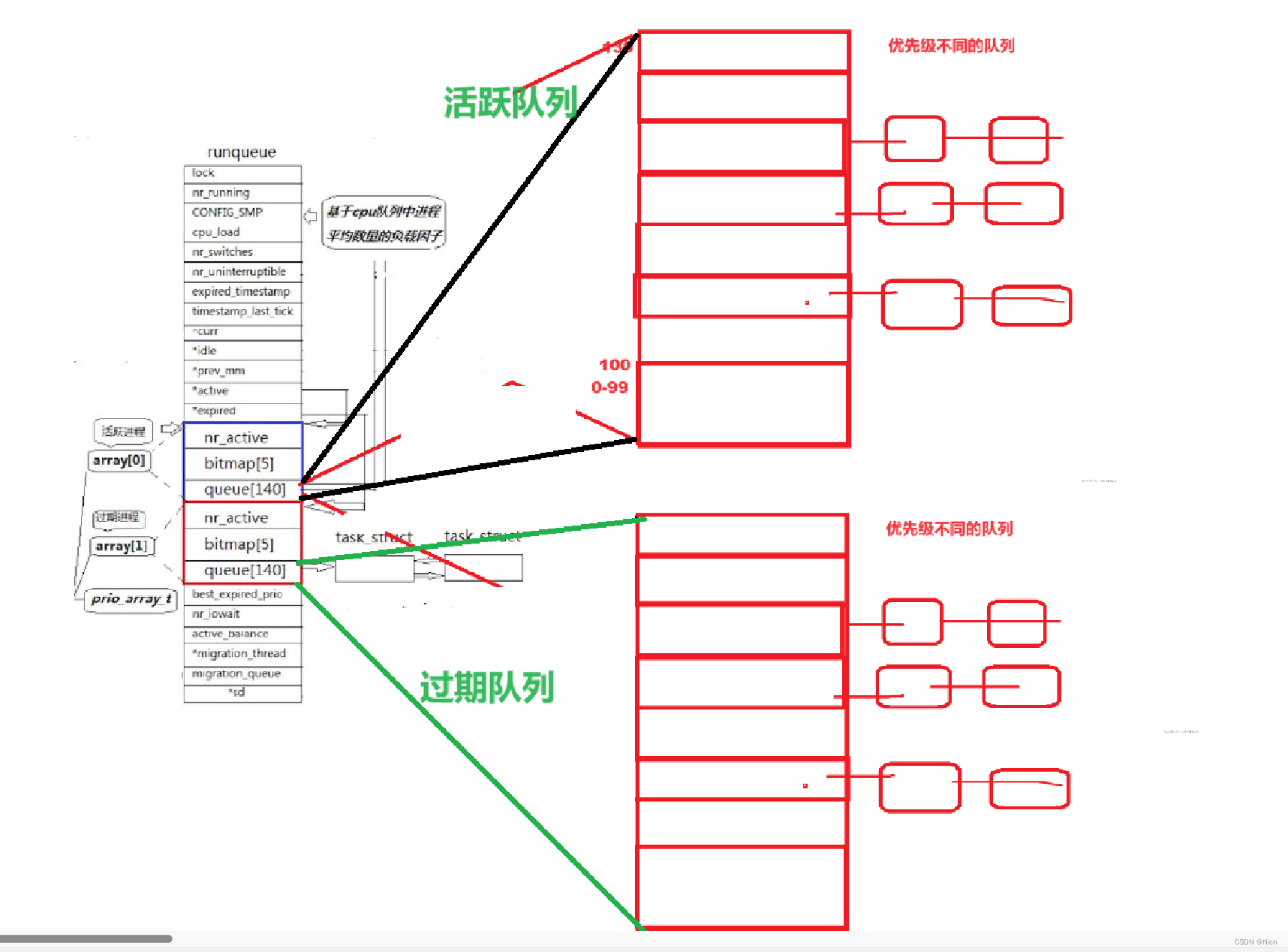
当我们cpu在进行正常执行的时候,选中一个数组,调度上面所有进程,后续再来的进程就到下一个优先级数组里面去。当前运行的数组优先级队列叫做活跃队列,而后续我们进程放入的队列称为我们的过期队列。cpu调度cpu的,操作系统放操做系统的进程,相当于一期一时期的调用,过期队列的位图相应的也设置好。
④两个struct q * 的指针,实现活跃队列和过期队列的内容切换
对于设计者来说:
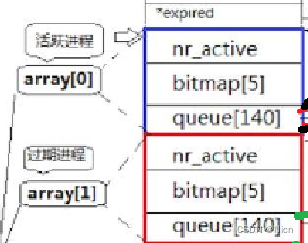
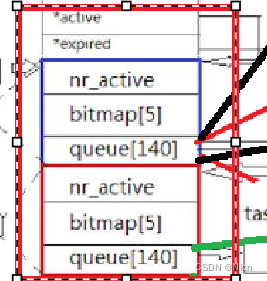
这两个东西存放的数据和数据类型是一样的呀,就可以使用一个数组来管理这两块,那么这个数组的类型应该是一个结构体的类型:
struct q{
nr_active;//当前队列中有多少活跃的进程,也就是进程优先级最高的进程bitmap[5];//进程的位图queue[140];//进程队列数组}那么我们创建这样一个数组:struct q arr[2];
arr[0]就代表我们的活跃队列
arr[1]代表过期队列
然后我们的运行队列中还有两个struct q * 的指针:
struct q* active = & arr[0] struct q* expired = &arr[1]
分别对应我们的活跃队列和过期队列,后续我们的操作体系调度时都是通过指针读取bitmap和优先级数组,然后就就可以访问进程了。
而对于新增进程,都放入过期队列中,活跃队列进程不断减少运行完毕,过期队列进程不断增多,然后我们将两个指针指向的内容进行交换,我们的过期队列里面的内容就变成活跃队列内容了,周而复始,基于优先级队列的O(1)的调度算法调度进程就可以完成了。
两个指针交换的时候,更改的是指针变量的内容也就是地址交换呀,只有4字节或者8字节的数据交换。
这样的设计:
每一次调度都是o(1)时间复杂度,每个优先级都可以照顾到位,对应40个优先级的数组
第二个,调度效率高,通过位图确定特定优先级
第三个还考虑了饥饿的问题,因为经过过期和活跃队列切换,让优先级低的进程也能被调度。
4.总结 进程的创建到调度
进程创建后接着创建进程的 pcb,将数据和代码加载到内存,进程pcb排入进程队列,同时pcb还要属于所有进程都在的双链表中,一但被调度,就要看进程的状态和优先级,状态:可能在运行可能在阻塞,状态决定了进程状态字段是多少(0,1,2表示t,s等),以及pcb进入哪一个等待队列,有了优先级就可以正常执行了,根据优先级执行一定要先保证能够实现基本的进程的切换,因为要被调度,可能一个时间片没有跑完,就要执行上下文的切换,就有上下文保护和恢复的概念,我们的切换就有了,我们的进程被动态执行调度就有了,然后再看系统层面上如何对进程做调度做管理,linux内核采用的是基于大O(1)的时间片轮转算法:两个队列再用两个指针,必要时进行交换。