深度学习知识点:卷积神经网络(CNN)
- 前言
- 卷积神经网络(CNN)
- 卷积神经网络的结构
- Keras搭建CNN
- 经典网络分类
- LeNet
- AlexNet
- AlexNet 对比LeNet 的优势?
- VGG
- VGG使用2个3×3卷积的优势在哪里?
- 每层卷积是否只能用一种尺寸的卷积核?
- Inception(GoogLeNet)
- inception结构能不能缓解梯度消失?
- ResNet
- ResNet为什么不用Dropout?
- ResNet网络越来越深,准确率会不会提升?
- ResNet v1 与 ResNet v2的区别?
- DenseNet
- DenseNet 比 ResNet 好?
- 为什么 DenseNet 比 ResNet 更耗显存?
- 卷积层有哪些基本参数?
- 如何计算卷积层的输出的大小?
- 如何计算卷积层参数数量?
- 有哪些池化方法?
- 1×1卷积的作用?
- 卷积层和池化层有什么区别?
- 卷积核是否一定越大越好?
- 卷积在图像中有什么直观作用?
- CNN中空洞卷积的作用是什么?
- 怎样才能减少卷积层参数量?
- 在进行卷积操作时,必须同时考虑通道和区域吗?
- 采用宽卷积,窄卷积的好处有什么?
- 介绍反卷积(转置卷积)
- 如何提高卷积神经网络的泛化能力?
- 卷积神经网络在NLP与CV领域应用的区别?
- 全连接、局部连接、全卷积与局部卷积的区别?
- 卷积层和全连接层的区别?
- Max pooling如何工作?还有其他池化技术吗?
- 卷积神经网络的优点?为什么用小卷积核?
- CNN拆成3x1 1x3的优点?
- BN、LN、IN、GN和SN的区别?
- 为什么需要卷积?不能使用全连接层吗?
- 为什么降采样使用max pooling,而分类使用average pooling?
- CNN是否抗旋转?如果旋转图像,CNN的预测会怎样?
- 什么是数据增强?为什么需要它们?你知道哪种增强?
- 如何选择要使用的增强?
- 什么是迁移学习?它是如何工作的?
- 什么是目标检测?你知道有哪些框架吗?
- 什么是对象分割?你知道有哪些框架吗?
- 参考
前言
- 本文是个人收集、整理、总结的一些人工智能知识点,由于本人水平有限,难免出现错漏,敬请批评改正。
- 由于本文是对知识点的收集和整理,图片基本来源于网络,图片若侵权,可联系删除。
- 更多精彩内容,可点击进入人工智能知识点
专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
卷积神经网络(CNN)
对图像(不同的数据窗口数据)和滤波矩阵做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作。
卷积神经网络由输入层、卷积层、激励层、池化层、全连接层组成。
①最左边:
数据输入层,对数据做一些处理:
去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)
归一化(把所有的数据都归一到同样的范围)、PCA/白化等。CNN只对训练集做“去均值”这一步。
②中间是:
CONV:卷积层,线性乘积 求和。
RELU:激励层,ReLU是激活函数的一种。
POOL:池化层,即取区域平均或最大。

③最右边是:
FC:全连接层
卷积神经网络的结构

池化层的作用:减小图像尺寸即数据降维,缓解过拟合,保持一定程度的旋转和平移不变性。
Keras搭建CNN

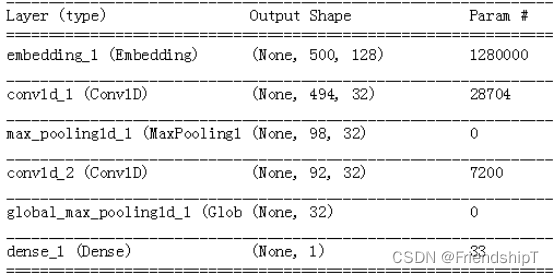
总结: 通常情况下,一维CNN的架构与CV的二维CNN很相似, 它将 Conv1D 层和 MaxPooling1D 层堆叠在一起,最后是一个全局池化运算或展平操作。
RNN 在处理非常长的序列时计算代价很大,但一维CNN的计算代价很小, 所以在 RNN 之前使用一维CNN作为预处理步骤是一个好主意,这样可以使序列变短,并提取出有用的表示交给 RNN 来处理。
经典网络分类
LeNet
- 最早用于数字识别;针对灰度图进行训练的,输入图像大小为32×32×1,5×5卷积核,不包含输入层的情况下共有7层,每层都包含可训练参数。
输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。(conv1->pool->conv2->pool2再接全连接层)
(1)每个卷积层包含三个部分:卷积、池化和非线性激活函数
(2)使用卷积提取空间特征
(3)降采样(Subsample)的平均池化层(Average Pooling)
(4)双曲正切(Tanh)或S型(Sigmoid)的激活函数MLP作为最后的分类器
(5)层与层之间的稀疏连接减少计算复杂度

AlexNet
- 用多层小卷积叠加来替换单个的大卷积。
输入尺寸:227×227×3
卷积层:5个
降采样层(池化层):3个
全连接层:2个(不包含输出层)
输出层:1个。1000个类别
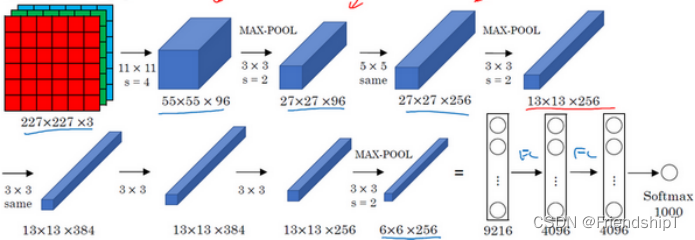
AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。
AlexNet 对比LeNet 的优势?
1.AlexNet比LeNet更深;
2.用多层的小卷积来替换单个的大卷积;
3.非线性激活函数:ReLU
4.防止过拟合的方法:Dropout,数据增强
5.大数据训练:百万级ImageNet图像数据
6.其他:GPU实现,LRN归一化层的使用
VGG
- 构筑了16~19层深的卷积神经网络,VGG-16中的16:含有参数的有16个层
- VGGNet论文中全部使用了3×3的小型卷积核和2×2的最大池化层,通过不断加深网络结构来提升性能。
- 卷积层:CONV=3×3 filters, s = 1, padding = same convolution。
- 池化层:MAX_POOL = 2×2 , s = 2。
- 优点:简化了卷积神经网络的结构;缺点:训练的特征数量非常大。
随着网络加深,图像的宽度和高度都在以一定的规律不断减小,每次池化后刚好缩小一半,信道数目不断增加一倍。
VGG使用2个3×3卷积的优势在哪里?
①减少网络层参数:
用两个3×3卷积比用1个5×5卷积拥有更少的参数量,只有后者的2×3×3/(5×5)=0.72。但是起到的效果是一样的,两个33的卷积层串联相当于一个5×5的卷积层,感受野的大小都是5×5,即1个像素会跟周围5×5的像素产生关联.
②更多的非线性变换:
2个3×3卷积层拥有比1个5×5卷积层更多的非线性变换(前者可以使用两次ReLU激活函数,而后者只有一次),使得卷积神经网络对特征的学习能力更强。
每层卷积是否只能用一种尺寸的卷积核?
可以,经典的神经网络一般都属于层叠式网络,每层仅用一个尺寸的卷积核,如VGG结构中使用了大量的3×3卷积层。
同一层特征图也可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好。比如GoogLeNet、Inception系列的网络。
Inception(GoogLeNet)
增加了卷积神经网络的宽度,在多个不同尺寸的卷积核上进行卷积后再聚合,并使用1×1卷积降维减少参数量。
inception结构能不能缓解梯度消失?
可以,因为inception结构额外计算了两个中间loss,防止了较深网络传播过程中的梯度消失问题。
ResNet
残差网络解决了网络退化的问题(随着网络的深度增加,准确度反而下降了)
ResNet为什么不用Dropout?
BN在训练过程对每个单个样本的forward均引入多个样本(Batch个)的统计信息,相当于自带一定噪音,起到正则效果,所以也就基本消除了Dropout的必要。 (ResNet训练152层深的神经网络)
ResNet网络越来越深,准确率会不会提升?
训练精度和测试精度迅速下降。
神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失,导致无法对前面网络层的权重进行有效的调整。
ResNet v1 与 ResNet v2的区别?
通过ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,
因此 捷径连接 的非线性激活函数(如ReLU)替换为 Identity Mappings。
同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。
DenseNet
含义:前面所有层与后面层的密集连接, 每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入
优点:缓解梯度消失问题,特征复用,加强特征传播,减少参数量
缺点:内存占用高
梯度消失原因:每一层都直接连接input和loss。
参数量少原因:每一层已经能够包含前面所有层的输出,只需要很少的特征图就可以了。
DenseNet 比 ResNet 好?
1.ResNet连接方式可能会阻碍信息的流动,但是DenseNet每层的输出都和最终的输出直接相连,梯度可以直接从末端流到之前的所有的层。
2.DensetNet连接有正则化的作用,可以减少过拟合。
3.DenseNet直接连接不同层的特征图,而不是像ResNet一样element-wise sum。
为什么 DenseNet 比 ResNet 更耗显存?
DenseNet的特征图像比ResNet大很多,导致卷积过程的计算量比resnet大很多。
卷积层有哪些基本参数?
①卷积核大小 (Kernel Size):
定义了卷积的感受野 在过去常设为5,如LeNet-5;现在多设为3,通过堆叠3×3的卷积核来达到更大的感受域。
②卷积核步长 (Stride):
常见设置为1,可以覆盖所有相邻位置特征的组合;当设置为更大值时相当于对特征组合降采样。
③填充方式 (Padding)
④输入通道数 :指定卷积操作时卷积核的深度
⑤输出通道数 :指定卷积核的个数
感受野:CNN每一层输出的特征图上的像素点在原始图像上映射的区域大小。
如何计算卷积层的输出的大小?
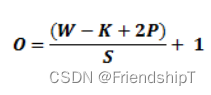
K 是过滤器尺寸,P 是填充,S 是步幅
如何计算卷积层参数数量?
卷积层参数量 = (filter size × 前一层特征图的通道数)× 当前层filter数量 + 当前层filter数量。 (卷积核长度×卷积核宽度×通道数+1)×卷积核个数
假设输入层矩阵维度是 96×96×3,第一层卷积层使用尺寸为 5×5、深度为 16 的过滤器(卷积核尺寸为 5×5、卷积核数量为 16),那么这层卷积层的参数个数为 5×5×3×16 + 16=1216个。
有哪些池化方法?
池化操作也叫做子采样(Subsampling)或降采样(Downsampling),往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。
①最大池化 和 ②平均池化
以最大池化为例,池化范围(2×2)(2×2)和滑窗步长(stride=2)(stride=2) 相同,仅提取一次相同区域的范化特征。
1×1卷积的作用?
①加入非线性函数。卷积层之后经过激励层,提升网络的表达能力;
②对卷积核通道数进行降维和升维,减小参数量。
卷积层和池化层有什么区别?
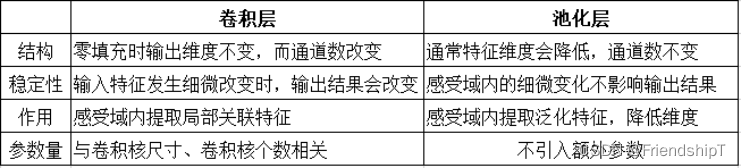
①卷积层有参数,池化层没有参数;
②经过卷积层节点矩阵深度会改变。池化层不会改变节点矩阵的深度,但是它可以缩小节点矩阵的大小。
卷积核是否一定越大越好?
不一定,
- 缺点:会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。
卷积神经网络(VGG、GoogLeNet等),发现通过堆叠2个3×3卷积核可以获得与5×5卷积核相同的感受视野,同时参数量会更少(3×3×2+1 < $ 5×5×1+1$) - 优点:
文本特征有时需要有较广的感受域让模型能够组合更多的特征(如词组和字符)
卷积核的大小并没有绝对的优劣,需要视具体的应用场景而定,但是极大和极小的卷积核都是不合适的,单独的1×1极小卷积核只能用作分离卷积而不能对输入的原始特征进行有效的组合,极大的卷积核通常会组合过多的无意义特征从而浪费了大量的计算资源。
卷积在图像中有什么直观作用?
用来提取图像的特征,但不同层次的卷积操作提取到的特征类型是不相同的:
- 浅层卷积: 边缘特征
- 中层卷积: 局部特征
- 深层卷积: 全局特征
CNN中空洞卷积的作用是什么?
空洞卷积也叫扩张卷积,在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射的大小保持不变。一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为9个。
怎样才能减少卷积层参数量?
①使用堆叠小卷积核代替大卷积核:
VGG网络中2个3×3的卷积核可以代替1个5×5的卷积核
②使用分离卷积操作:
将原本K×K×C的卷积操作分离为K×K×1和1×1×C的两部分操作
③添加1×1的卷积操作:与分离卷积类似,但是通道数可变,在K×K×C1卷积前添加1×1×C2的卷积核(满足C2<C1)
④在卷积层前使用池化操作:池化可以降低卷积层的输入特征维度
在进行卷积操作时,必须同时考虑通道和区域吗?
①标准卷积同时考虑通道和区域
②通道分离(深度分离)卷积网络(Xception网络):
首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道特征矩阵之后,再对这批新通道特征进行标准的1×1跨通道卷积操作。
采用宽卷积,窄卷积的好处有什么?
宽卷积、窄卷积其实是一种填充方式。
①宽卷积('SAME’填充):
对卷积核不满足整除条件的输入特征进行补全,以使卷积层的输出维度保持与输入特征维度一致。
②窄卷积('VALID’填充):
不进行任何填充,在输入特征边缘位置若不足以进行卷积操作,则对边缘信息进行舍弃,因此在步长为1的情况下该填充方式的卷积层输出特征维度可能会略小于输入特征的维度。
介绍反卷积(转置卷积)
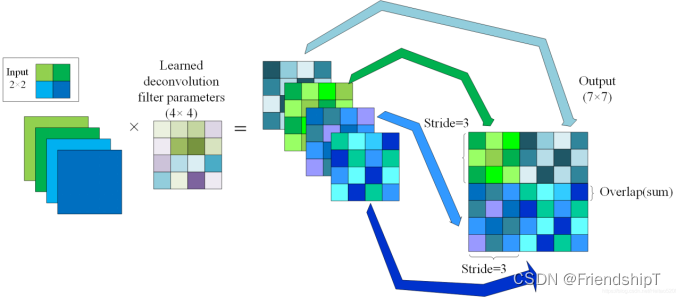
正向传播时乘以卷积核的转置矩阵,反向传播时乘以卷积核矩阵,由卷积输出结果近似重构输入数据,上采样。
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
过程如下:
①输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4−1==4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图。
②将4个特征图进行步长为3的相加; 输出的位置和输入的位置相同。步长为3是指每隔3个像素进行相加,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他类推。
可以看出反卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小 得到 out=(in−1)×s + k 上图过程就是 (2 - 1) × 3 + 4 = 7。
如何提高卷积神经网络的泛化能力?

卷积神经网络在NLP与CV领域应用的区别?
自然语言处理对一维信号(词序列)做操作,输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量)
计算机视觉则是对二维(图像)或三维(视频流)信号做操作。输入数据是连续取值(比如归一化到0,1之间的- 灰度值)。
全连接、局部连接、全卷积与局部卷积的区别?

卷积层和全连接层的区别?
- 卷积层是局部连接,所以提取的是局部信息;全连接层是全局连接,所以提取的是全局信息;
- 当卷积层的局部连接是全局连接时,全连接层是卷积层的特例;
Max pooling如何工作?还有其他池化技术吗?
1.Max pooling:选取滑动窗口的最大值
2.Average pooling:平均滑动串口的所有值
3.Global average pooling:平均每页特征图的所有值
卷积神经网络的优点?为什么用小卷积核?
多个小的卷积核叠加使用要远比一个大的卷积核单独使用效果要好的多。
1.局部连接
这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
2.权值共享
一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
3.下采样
Pooling层利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息。通过去掉Feature Map中不重要的样本,进一步减少参数数量。
CNN拆成3x1 1x3的优点?
为了压缩模型参数量(这里参数由3x3=9降低到1x3+3x1=6),但是计算量基本没变(乘数目没变)。
BN、LN、IN、GN和SN的区别?
将输入的 feature map shape 记为[N, C, H, W],其中N表示batch size,即N个样本;C表示通道数;H、W分别表示特征图的高度、宽度。
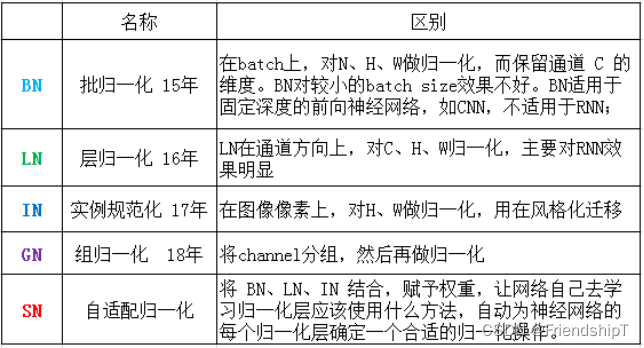
为什么需要卷积?不能使用全连接层吗?
- 卷积在神经网络中的作用主要有特征提取、降维、去噪、图像增强等。卷积层通过共享参数的方式减少了模型的复杂度,提高了计算效率,同时增强了模型的泛化能力。卷积还可以模拟生物视觉系统的感受野(receptive field)机制,从而更好地捕捉图像中的空间结构和纹理信息。
- 虽然全连接层在某些情况下也可以用于神经网络,但在图像处理和计算机视觉领域,卷积层的应用更为广泛。这是因为卷积层能够更好地处理图像数据,它们可以捕捉局部特征,并允许网络学习到空间层次的结构。此外,卷积层还可以通过池化等操作进一步降低数据的维度,从而减少计算量和过拟合的风险。
- 因此,虽然全连接层在某些情况下也可以用于神经网络,但在图像处理和计算机视觉领域,卷积层的应用更为广泛。
为什么降采样使用max pooling,而分类使用average pooling?
在降采样中,使用max pooling而非average pooling的原因有以下几点:
- 特征选择:max pooling更像是做特征选择,选出了分类辨识度更高的特征,提供了非线性。根据相关理论,特征提取的误差主要来自两个方面:邻域大小受限造成的估计值方差增大;卷积层参数误差造成估计均值的偏移。max pooling能减小第二种误差,更多地保留纹理信息。
- 感受野的增加:在卷积神经网络中,卷积操作使得每个像素对应的感受野增加。如果在这之后直接连接全连接层,参数数量会爆炸。通过使用max pooling进行降采样,可以减少全连接层的参数数量,降低过拟合的风险。
- 控制过拟合:在深度学习中,随着模型复杂度的增加,模型更容易陷入过拟合。使用max pooling能够控制模型的复杂度,降低过拟合的风险。
在分类问题中,使用average pooling的原因在于:
- 信息的完整传递:average pooling更侧重对整体特征信息进行采样,在减少参数维度方面的贡献更大一些,更多地体现在信息的完整传递这个层面上。在一个很大很有代表性的模型中,比如DenseNet中的模块之间的连接大多采用average pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。
- 全局平均池化操作的应用:在ResNet和Inception结构中最后一层都使用了平均池化。有的时候,在接近模型分类器的末端使用全局平均池化还可以代替flatten操作,使输入数据变成一维向量。
综上所述,降采样使用max pooling而分类使用average pooling的原因主要在于特征选择、感受野的增加、控制过拟合以及信息完整传递等方面。
CNN是否抗旋转?如果旋转图像,CNN的预测会怎样?
CNN(卷积神经网络)并不具备旋转不变性,这意味着如果对图像进行旋转,CNN的预测结果可能会受到影响。具体来说,当图像被旋转时,CNN可能会将其识别为不同的物体或者给出错误的分类结果。
然而,在实际应用中,可以通过数据增强来提高CNN对旋转的鲁棒性。数据增强是一种常用的技术,通过对训练数据进行各种变换,生成更多的训练样本,从而提高模型的泛化能力。对于旋转问题,可以在训练过程中对图像进行旋转,从而让CNN学习到各种不同旋转角度下的特征。
此外,还可以通过其他技术来提高CNN对旋转的鲁棒性,例如使用池化层或全连接层来提取更高级别的特征,或者使用自注意力机制等新型网络结构。这些技术可以帮助CNN更好地处理旋转问题,从而提高其对旋转的鲁棒性。
总之,虽然CNN本身不具备旋转不变性,但可以通过数据增强和其他技术来提高其对旋转的鲁棒性,从而更好地应用于各种图像处理和计算机视觉任务中。
什么是数据增强?为什么需要它们?你知道哪种增强?
数据增强是一种在数据约束环境下提高机器学习模型性能和准确性的低成本和有效的方法。它是通过从现有的训练样本中生成新的训练样本来实现的,以增加数据集的多样性和规模。数据增强在深度学习中尤其重要,因为深度学习算法需要大量的数据才能获得良好的性能。
数据增强可以通过各种技术来实现,包括旋转、平移、裁剪、翻转、噪声添加等。这些技术可以生成新的训练样本,使得模型能够更好地泛化到未知数据。
数据增强的原因主要有以下几点:
- 增加数据多样性:通过生成与原始数据集相似但不同的新样本,数据增强可以增加数据集的多样性,从而提高模型的泛化能力。
- 减少过拟合:数据增强可以使得模型在训练时使用更多的样本,从而减少过拟合的风险。过拟合是指模型在训练数据上表现很好,但在测试数据上表现较差的现象。
- 节省时间和资源:数据增强可以在有限的数据集上生成新的样本,从而使得模型可以在更小的数据集上进行训练,节省了时间和计算资源。
一些常见的数据增强技术包括:
- 图像增强:通过对图像进行旋转、平移、缩放、裁剪、翻转等操作,生成新的训练样本。
- 噪声增强:通过添加噪声或扰动来模拟真实世界中的不确定性,从而使得模型更加鲁棒。
- 对抗生成网络(GAN):使用GAN生成与原始数据集相似但不同的新样本,以提高模型的泛化能力。
- 虚拟增强:使用计算机模拟生成虚拟的训练样本,例如模拟游戏或虚拟现实场景。
总之,数据增强是一种非常有用的技术,可以帮助提高机器学习模型的性能和准确性。它可以通过各种技术实现,以增加数据集的多样性和规模,从而使得模型更好地泛化到未知数据。
如何选择要使用的增强?
选择要使用的数据增强技术取决于具体的应用场景和数据类型。以下是一些选择数据增强技术的考虑因素:
- 应用场景:不同的应用场景可能需要不同的数据增强技术。例如,在图像分类任务中,可以使用旋转、平移、裁剪等图像增强技术;在语音识别任务中,可以使用噪声添加等语音增强技术。
- 数据类型:数据类型也是选择数据增强技术的重要因素。例如,对于图像数据,可以使用图像增强技术;对于文本数据,可以使用文本生成等数据增强技术。
- 计算资源和时间限制:数据增强需要额外的计算资源和时间。因此,在选择数据增强技术时,需要考虑计算资源和时间限制。如果计算资源和时间有限,可以选择一些简单而有效的数据增强技术,如随机裁剪和翻转等。
- 模型需求:不同的模型对数据增强有不同的需求。例如,对于深度学习模型,需要大量的数据进行训练,因此可以使用数据增强技术来增加数据量;而对于一些简单的模型,可能不需要太多的数据增强技术。
- 鲁棒性和泛化能力:数据增强可以帮助提高模型的鲁棒性和泛化能力。因此,在选择数据增强技术时,需要考虑其对鲁棒性和泛化能力的贡献。
总之,选择要使用的数据增强技术需要考虑多个因素,包括应用场景、数据类型、计算资源和时间限制、模型需求以及鲁棒性和泛化能力等。需要根据具体情况进行权衡和选择。
什么是迁移学习?它是如何工作的?
迁移学习是一种机器学习方法,其核心思想是将在一个任务上学到的知识应用于另一个任务上。它是为了解决新任务时,可以利用已经训练好的模型(已学过的知识)来进行优化的一种策略。具体来说,迁移学习是通过从源领域学习到的知识,来帮助解决目标领域中的问题。
迁移学习的工作方式主要有以下几种:
- 基于样本的迁移:通过对源领域中有标定样本的加权利用,来完成知识迁移。
- 基于特征的迁移:将源领域和目标域映射到相同的空间,并最小化源领域和目标领域之间的距离来完成知识迁移。
- 基于模型的迁移:将源领域和目标域的模型与样本结合起来调整模型的参数。
- 基于关系的迁移:在源领域中学习概念之间的关系,然后将其类比到目标域中,完成知识的迁移。
在具体应用中,迁移学习的策略有很多种,如预训练-微调(pretrain-and-fine-tune)等。预训练-微调方法的基本思想是,首先在大量无标签的数据上预训练一个模型,然后在一个小规模的特定任务的数据集上微调这个预训练模型。这种方法的好处是可以利用预训练模型学习到的特征表示和模型参数作为起始点,然后根据具体任务调整模型参数,使得模型能够更好地适应新任务。
总的来说,迁移学习是一种有效的利用已学知识来解决新问题的方法,具有广泛的应用前景。
什么是目标检测?你知道有哪些框架吗?
目标检测是计算机视觉领域中的一项任务,旨在识别并定位图像或视频中的物体。目标检测算法通常会返回物体的位置和类别,而不仅仅是物体的类别,因此它们在功能上与图像分类有所不同。
以下是一些目标检测的常用框架:
- YOLO(You Only Look Once)系列:YOLO是一种实时目标检测算法,其通过将图像划分为网格并预测每个网格单元中是否存在物体以及物体的边界框、类别和置信度分数来实现目标检测。YOLO系列包括YOLOv1、YOLOv2、YOLOv3、YOLOv4和YOLOv5等版本,每个版本都进行了改进和优化。
- SSD(Single Shot Detection)系列:SSD是一种基于深度学习的单次检测算法,其通过预测不同尺度和长宽比的边界框以及物体的类别来实现目标检测。SSD系列包括SSD300、SSD512、SSD1024等版本,每个版本都针对不同的场景和需求进行了优化。
- Faster R-CNN系列:Faster R-CNN是一种基于Region Proposal Network(RPN)的目标检测算法,其通过预测物体的边界框和类别来实现目标检测。Faster R-CNN系列包括Faster R-CNN、Mask R-CNN和Cascade R-CNN等版本,每个版本都进行了改进和优化。
- RetinaNet系列:RetinaNet是一种基于Focal Loss的目标检测算法,其通过减轻类别不平衡问题并提高小物体的检测性能来实现目标检测。RetinaNet系列包括RetinaNet、ResNet-FPN等版本,每个版本都进行了改进和优化。
这些框架都各有优缺点,选择使用哪种框架取决于具体的需求和应用场景。
什么是对象分割?你知道有哪些框架吗?
对象分割是计算机视觉领域中的一项任务,旨在将图像中的每个对象或物体分割出来,并对其进行单独的分析和识别。对象分割是目标检测和图像分割等任务的延伸,它需要对图像中的每个对象进行精确定位和分离。
以下是一些对象分割的常用框架:
- Mask R-CNN:Mask R-CNN是一种基于Faster R-CNN的目标检测算法,它在Faster R-CNN的基础上增加了一个并行的分支用于预测物体的掩膜(mask),从而实现了对物体的精确分割。Mask R-CNN在COCO等数据集上取得了很好的效果,并且具有很好的通用性和可扩展性。
- U-Net:U-Net是一种基于卷积神经网络的对象分割算法,其结构类似于一个U字形,包括一个收缩路径和一个扩展路径。U-Net通过跳跃连接来保持空间信息,从而实现精确的对象分割。U-Net在许多医学图像分割任务中得到了广泛应用。
- PSPNet(Pyramid Scene Parsing Network):PSPNet是一种基于卷积神经网络的对象分割算法,其通过在不同尺度上解析场景来实现精确的对象分割。PSPNet在多个数据集上取得了很好的效果,并且可以处理不同大小和形状的物体。
- DeepLab系列:DeepLab是一种基于深度卷积神经网络的对象分割算法,其通过使用较大的卷积核和空洞卷积来增加感受野,从而实现精确的对象分割。DeepLab系列包括DeepLabv1、DeepLabv2、DeepLabv3和DeepLabv4等版本,每个版本都进行了改进和优化。
这些框架都各有优缺点,选择使用哪种框架取决于具体的需求和应用场景。同时,随着技术的不断发展,新的框架和方法也在不断涌现,不断提升着对象分割技术的准确性和可靠性。
参考
[1] https://blog.csdn.net/cc13186851239
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入人工智能知识点
专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目