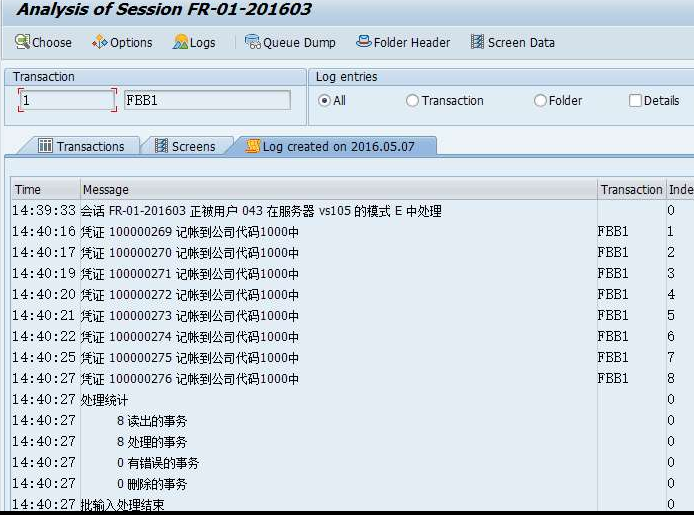
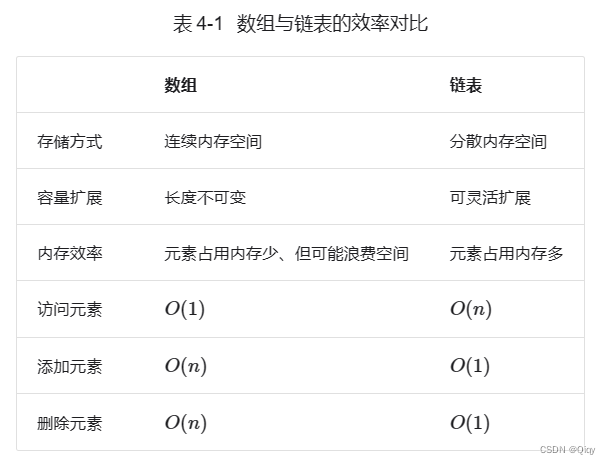
从scores.jason文件中读取学生信息,输出学生的学号,姓名,各科成绩,平均分, 各科标准差
scores.jason
{"学院": "计算机学院","班级": "2022级1班","成绩": [{"学号": 1001,"姓名": "李元芳","语文": 96,"数学": 62,"英语": 87},{"学号": 1002,"姓名": "孙悟空","语文": 90,"数学": 96,"英语": 60},{"学号": 1003,"姓名": "孙尚香","语文": 73,"数学": 89,"英语": 91},{"学号": 1004,"姓名": "苏妲己","语文": 77,"数学": 70,"英语": 62},{"学号": 1005,"姓名": "狄仁杰","语文": 93,"数学": 91,"英语": 80}]
}效果: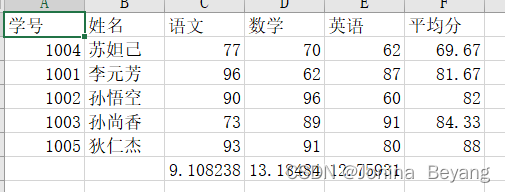
# # 从scores.jason文件中读取学生信息,输出学生的学号,姓名,各科成绩,平均分, 各科标准差
import statistics as stats
import openpyxl
import json
wb = openpyxl.Workbook()
sheet = wb.active
with open('../scores.json', mode='r', encoding='utf-8') as file_obj:result_dict = json.load(file_obj)scores_list = result_dict['成绩']# 处理数据# 语文分数verbol_scores = list()math_scores = list()eng_scores = list()for studend in scores_list: # type: dictsum_scores = 0for k, v in studend.items():if k == '语文':verbol_scores.append(v)sum_scores += vif k == '数学':math_scores.append(v)sum_scores += vif k == '英语':eng_scores.append(v)sum_scores += vstudend['平均分'] = round(sum_scores/3, 2)# 按照平均分大小排序,升序scores_list.sort(key=lambda x: x['平均分'], reverse=False)# 计算标准差verbol_std, math_std, eng_std = stats.pstdev(verbol_scores), stats.pstdev(math_scores), stats.pstdev(eng_scores)# 写数据sheet.append([i for i in scores_list[0]])for student in scores_list: # type: dict# 将dict_values对象转化为listsheet.append(list(student.values()))print(scores_list)# 写标准差row = sheet.max_row + 1for col, value in zip(('CDE'), (verbol_std, math_std, eng_std)):sheet[f'{col}{row}'] = valuewb.save('C://Users/小碧宰治/Desktop/test.xlsx')