- 2022年发表。
- 出自论文:《Training language models to follow instructions with human feedback》,OpenAI。
- 与 chatgpt 最相近的工作。
- 在OpenAI官网中,又称为Aligning language models to follow instructions
文章目录
- 1、提出动机
- 2、模型结构
- 3、训练机制
- 3.1、数据的收集
- 3.2、SFT
- 3.3、RLHF
- 3.3.1、Train reward model
- 3.3.2、Train policy with PPO
- 4、与先前GPT的区别
1、提出动机
- GPT-3虽牛,但仍会生成一些带偏见、不真实、有害的负面信息,有时候一本正经胡说八道。这从做研究的角度来看,确实没啥,因为你只要在某个数据集上碾压对手,那就是牛的。但对于工业实践来说,你带有这些问题的话,特别是对于大公司来说,肯定会被用户骂死,骂到产品下线为止。
- 且GPT-1, GPT-2, GPT-3的主要任务还是续写即文字接龙,不太擅长与听你指令干活。比如,你输入“给我写一份方案”,GPT很可能输出的是“主题是关于如何入门深度学习”,而不是给你生成出一份方案。
- InstructGPT因此而提出,它提出了一个叫 “align” 即对齐的概念,指的是使模型输出与人类真是意图更为接近,即对齐,更符合人类偏好。
2、模型结构
- 模型结构就不说了(大致结构也就是transformer的decoder结构);因为训练机制和数据才是gpt的重点!
- 可参看我之前对GPT系列的讲解:GPT系列:GPT, GPT-2, GPT-3精简总结 (模型结构+训练范式+实验)
3、训练机制
InstructGPT的训练机制主要分为了3步:
- 1、SFT:Supervised Fine-Tuning,有监督微调。
- 2、训练奖励模型
- 3、强化学习(PPO方法)
注:其中第2,3步合起来也就是常听到的RLHF了,基于人类反馈的强化学习。
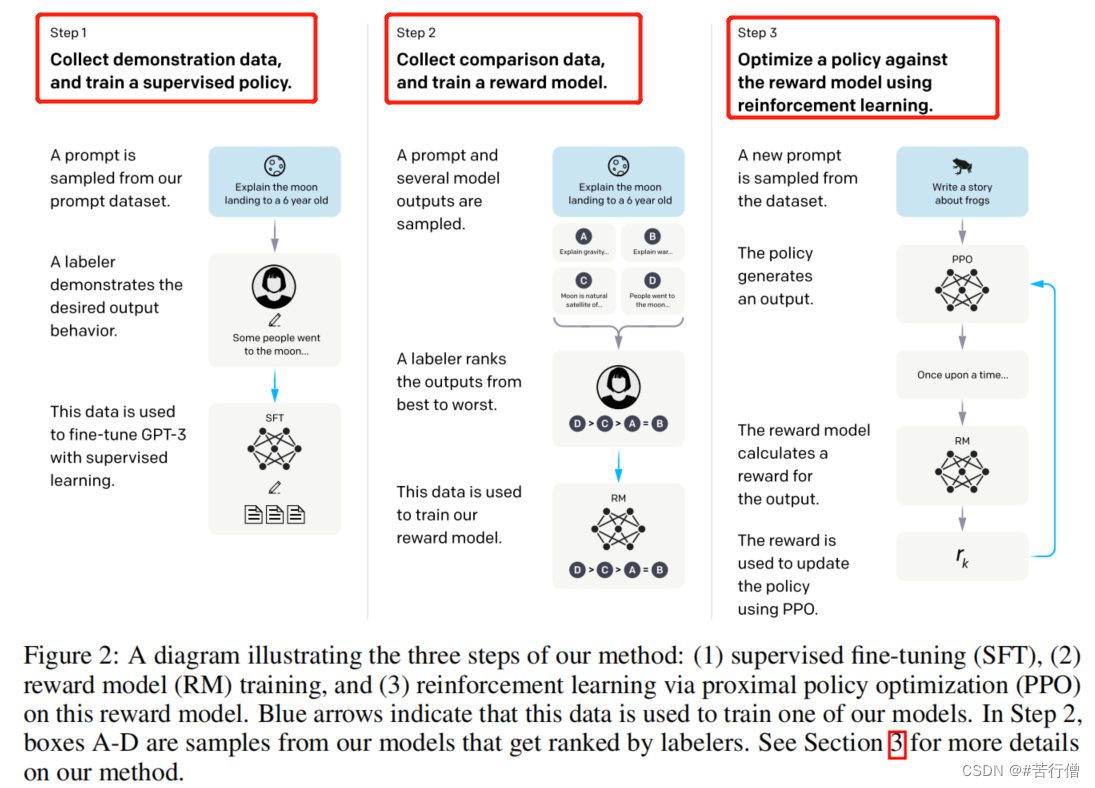
3.1、数据的收集

3.2、SFT
Supervised Fine-Tuning
SFT做的事情其实就是语言模型做的预训练。和GPT-3区别在于,InstructGPT的数据为人工标的高质量数据。
- gpt3中对于某个下游任务,采用的是few-shot的形式(任务描述+例子+prompt),通常采用固定的任务描述形式,且需要人为去测试哪种任务表述方式好。很明显了,这种方式和实际场景中用户的表述存在很大的gap。
- InstructGPT在SFT中标注的数据正是为了消除这种gap的。
- 具体数据来源从gpt3的真实用户请求中采样了大量下游任务的描述,然后标注人员对任务描述续写,从而得到高质量回答。真实用户请求又被称为某个任务的指令,所以也就是概念 “基于人类反馈的指令微调” 的由来。
3.3、RLHF
Reinforcement Learning from Human Feedback
3.3.1、Train reward model
这一步单独生成了一个reward model(打分模型)用于PPO里打分。
训练步骤如下:
- 1、基于SFT训练好的模型,对输入(提问)生成多个输出(答案)(根据输出概率分布进行采样即可得到多个输出或是beam-search类的方法等),然后人工去给这些输出打分。
- 2、使用第一步得到的样本集,训练模型,模型的输入为一个提问+一个答案,模型的输出为对该答案的打分。【gpt模型下游的softmax改为MLP】
- 3、既然是排序问题,那loss用的是排序问题里常用的pairwise ranking loss。其中,K就是模型生成K个答案,论文采用的是K=9;这个loss就是计算了两两的答案的损失。也就是希望真实排序靠前标签对应的打分比排序靠后的标签对应的打分要高;最后再除与所有可能的组合数(从K个里选2个)。长得也就是LR的loss形式:sigmoid+log。
- 4、有了loss那就能反向传播更新模型参数了。

3.3.2、Train policy with PPO
Proximal Policy Optimization:强化学习PPO模型是OpenAI 2017年的工作。
⭐⭐⭐这一步用到的模型是:
1、用于强化学习的SFT模型(用于生成答案)。
2、原SFT模型(用于计算loss中的KL散度,为了保证PPO学习出的模型的预测不至于偏离原预训练模型的预测太多,因为RL就是用SFT模型初始化的)
3、reward model(用于对生成的答案打分;相当于作为老师,来对模型的回答进行‘批改’,让模型愈发把知识‘对齐’到我们想要的样子。)。
⭐ 为啥需要PPO这一步呢?使用强化学习(而非监督学习)的方式更新语言模型,最大的优势是在于能够使得模型更加自由的探索更新方向,从而突破监督学习的性能天花板。
⭐ 在reward model训练完之后有奖励模型咯,用它来作为PPO训练的value function。
PPO算法更新参数的大致流程如下图:
图源于:https://mp.weixin.qq.com/s/1v4Uuc1YAZ9MRr1UWMH9xw
-
输入x是第三个数据集里的prompt,而输出y则是强化学习的SFT模型的输出。y会随着模型参数的更新而不一样,这里有区别与监督学习,监督学习中,训练多个epoch时同一个x对应的y是一样的,但强化学习中同样的x对应的y是会随着模型更新而变化的。
-
这里我简单讲讲,因为主要思想也挺简单的,即使我没搞过强化学;李沐老师说如果前面标的数据够多,其实这一步可能并不需要。
-
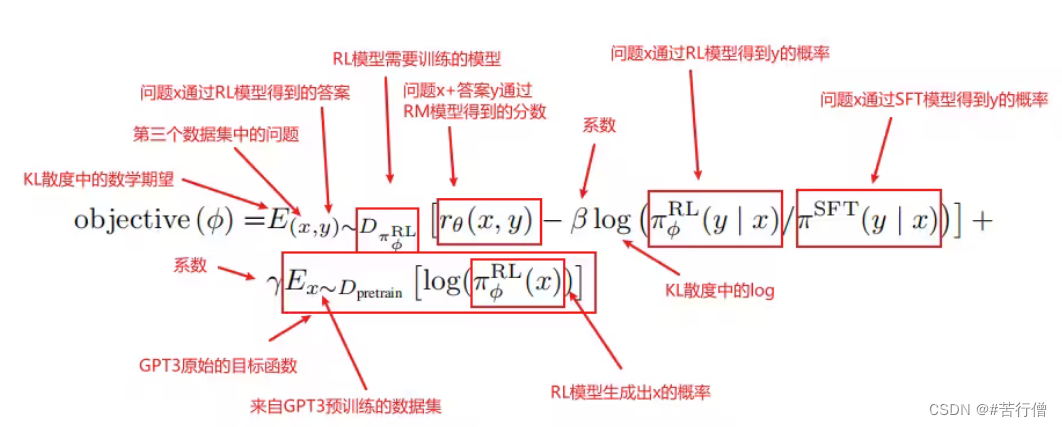
PPO的主要思想。 强化学习的模型称为策略模型,又称为策略。其中rθ是RM,为了确保RM打分不至于被过度优化,增加了个log项,那是KL散度,为了保证PPO学习出的强化学习SFT的预测不至于偏离原SFT模型的预测太多,因为RL就是用SFT模型初始化的。这就是PPO的主要思想。
-
语言模型预训练项。 另外地,InstructGPT在PPO的loss基础上加上了预训练损失,为了防止强化学习SFT模型只对打分这个任务过度拟合,导致泛化性能损失,所以加上了预训练语言模型的损失来确保模型在公开NLP数据集上的表现。加上了这一项,PPO就变为了PPO-ptx。
-
有了loss就能反向传播更新模型参数了。

解释版:
4、与先前GPT的区别
- 解决 GPT-3 的输出与人类意图之间的 Align 问题;
- InstructGPT的输出比GPT3的输出更好,更真实可靠,更丰富。
- InstructGPT对有害结果的生成控制地更好,但对于偏见问题没有明显改善。
- InstructGPT泛化性更好,在缺乏人类指令数据上也表现不错;
- InstructGPT基于SFT后的模型在公开数据集上表现也不错。
参考链接:
[1] 李沐:InstructGPT论文精读