python知识点汇总十二
- 1、什么是 C/S 和 B/S 架构
- 2、count(1)、count(*)、count(列名)有啥区别?
- 3、如何使用线程池
- 3.1、为什么使用线程池?
- 4、MySQL 数据库备份命令
- 5、supervisor和Gunicorn
- 6、python项目部署
- 6.1、entrypoint.sh制作
- 6.2、Dockerfile制作
- 6.3、django静态文件配置和部署、前端代码部署
- 6.4、制作nginx镜像
- 6.5、docker-compose
- 7、Django中使用 ORM 和原生 SQL 的优缺点
- 8、列举 Django 中执行原生 sql 的方法
- 1、raw()方法
- 2、使用extra
- 3、执行原生查询
- 9、比较两个 json 数据是否相等
1、什么是 C/S 和 B/S 架构
C/S:客户端-服务端的架构,他需要安装一个客户端,才能使用这个软件,所以软件升级,除服务端升级以外,需要同步客户端,
B/S:浏览器-服务器的架构,是不需要安装客户端,只需要浏览器就可以访问软件,软件升级只需要更新服务器就可以
B/S与C/S软件测试思维是一致的,控件点击、数据库交互、后端服务器交互。
但是客户端需要考虑安装、卸载、升级的测试
2、count(1)、count(*)、count(列名)有啥区别?
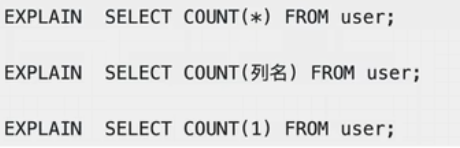

执行效率上:
列名为主键的情况下,count(列名)会比count(1)查询快;
列名不为主键的情况下,count(1)会比count(列名)查询快
3、如何使用线程池
3.1、为什么使用线程池?
传统多线程方案会使用“即时创建,即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器将处于不停的创建线程、销毁线程的状态。
一个线程的运行时间可以分为3部分:线程的启动时间、线程体的运行时间和线程的销毁时间。在多线程处理的情景中,如何线程不能被重用,就意味着每次创建都要经过启动、运行、销毁3个过程,这势必会增加系统响应时间,降低了效率。
使用线程池:由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能够带来更好的性能和系统稳定性。
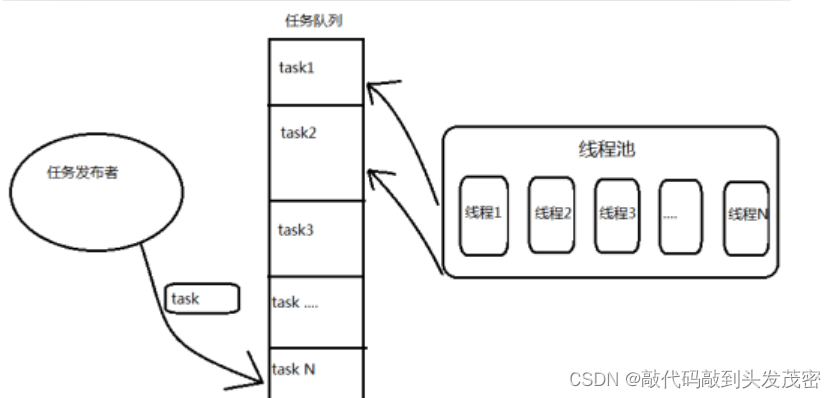
Python中的线程池是通过ThreadPoolExecutor类来实现的。
t1 = ThreadPoolExecutor(max_workers=5) 线程池中最多支持同时执行多少个任务;
t1.submit(work):往线程池中提交执行的任务
t1.shutdown():等待线程池中所有的任务执行完毕之后,开始执行
线程池代码
from concurrent.futures.process import ProcessPoolExecutor
from concurrent.futures.thread import ThreadPoolExecutorimport time
import threading
def work():for i in range(6):print(f"线程1工作")time.sleep(1)def work1():for i in range(5):print(f"线程2学习")time.sleep(1)if __name__ == '__main__':#todo 创建一个线程池t1 = ThreadPoolExecutor(max_workers=5) # todo 线程池中最多支持同时执行多少个任务st=time.time()#todo 往线程池中提交执行的任务t1.submit(work)t1.submit(work1)#todo 等待线程池中所有的任务执行完毕之后,开始执行t1.shutdown()et=time.time()print('执行的时间:',et-st)4、MySQL 数据库备份命令
1、先在根目录下创建一个备份文件的目录
[root@master ~]# mkdir /backup
2、利用mysqldump备份
[root@master ~]# mysqldump -uroot -proot -B booksDB > /backup/booksDB.sql
3、备份booksDB数据库中的books表
[root@master ~]# mysqldump -uroot -proot booksDB books > /backup/booksDB_books.sql
5、supervisor和Gunicorn
Gunicorn是基于unix系统,被广泛应用的高性能的Python WSGI HTTP Server。用来解析HTTP请求的网关服务。
它通常是在进行反向代理(如nginx),或者进行负载均衡和一个web 应用(比如 Django 或者 Flask)之间。
特点:
1、能和大多数的Python Web框架兼容;
2、简单易上手;
3、轻量级的资源消耗;
4、目前,gunicorn只能运行在Linux环境中,不支持windows平台。
supervisor:
Supervisor是用Python开发的进程管理工具,可以很方便的用来启动、重启、关闭进程(不仅仅是 Python 进程)。能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。
命令行中启动异步任务、定时任务,当窗口关闭或者服务器关闭,进程就结束了。
在本容器中还需要运行celery的worker服务和beat服务。我们使用 supervisor 进行进程控制。
6、python项目部署
6.1、entrypoint.sh制作
执行数据库迁移
创建管理员用户
启动supervisor

6.2、Dockerfile制作
FROM:以python为基础镜像
RUN:安装必要的库(pip install requirements.txt)
ENV:设置环境变量(生产环境)
COPY . .:复制
VOLUME /app/logs/:挂载日志
EXPOSE 8000:暴露端口
ENTRYPOINT [ “./entrypoint.sh” ]:启动容器时执行的命令
# 从哪个镜像开始构建
FROM python:3.9-alpine
# 注释标签
LABEL maintainer='zhilong'
LABEL description='Django project'# 创建/app目录并切换进目录下
WORKDIR /app
# 拷贝代码到镜像中
# 拷贝文件到镜像中
# 第一个目录是宿主机目录,第二个目录是镜像的目录
# 第一个目录是相对路径,相对Dockerfile所在的目录
# 第二个目录如果是相对路径,那么就是以workdir的目录
COPY . .# 安装必要的库
# RUN执行shell命令
# build的时候执行
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/g' /etc/apk/repositories && \apk update && \apk upgrade && \apk add --no-cache tzdata mariadb-dev gcc libc-dev && \cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \echo "Asia/Shanghai" > /etc/timezone && \python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ --upgrade pip && \pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ && \chmod 777 ./entrypoint.sh#设置环境变量
ENV ENV=production# 创建日志挂载点避免容器越来越大
VOLUME /app/logs/# 挂载端口
EXPOSE 8000# 启动容器后会执行的命令
# 执行shell命令
# CMDENTRYPOINT [ "./entrypoint.sh" ]
构建镜像:
docker build -t ck14_app .
启动容器
docker run --name ck14_django --network ck14 -d -p5000:8000 -v ck14_logs:/app/logs --restart=always ck14_app
6.3、django静态文件配置和部署、前端代码部署
static目录:包含admin、rest_framework
打包命令:npm run build
打包完成后,将dist文件夹拷贝到nginx文件夹中
dist目录:包含前端静态文件(css、index.html、js等待)
6.4、制作nginx镜像
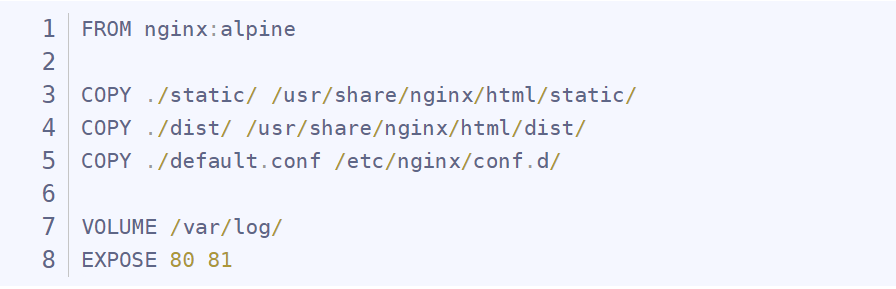
此时nginx目录下包含:default.conf、Dockerfile、dist、static

生成镜像命令:sudo docker build -t ck14_web_nginx .
运行容器
sudo docker run --name ck14_nginx --network ck14 -d -p 5001:80 -p 5002:81 ck14_web_nginx
6.5、docker-compose
一个项目肯定包含多个容器,每个容器都手动单独部署肯定费时费力。docker-compose可以通过脚本来批量构建镜像和启动容器,快速的部署项目。
使用docker-compose部署主要是编写docker-compose.yml脚本。
不论是Dockerfile还是docker-compose.yml脚本的编写都依赖上下文,所以需要明确部署文件夹的项目结构。
目录结构如下:

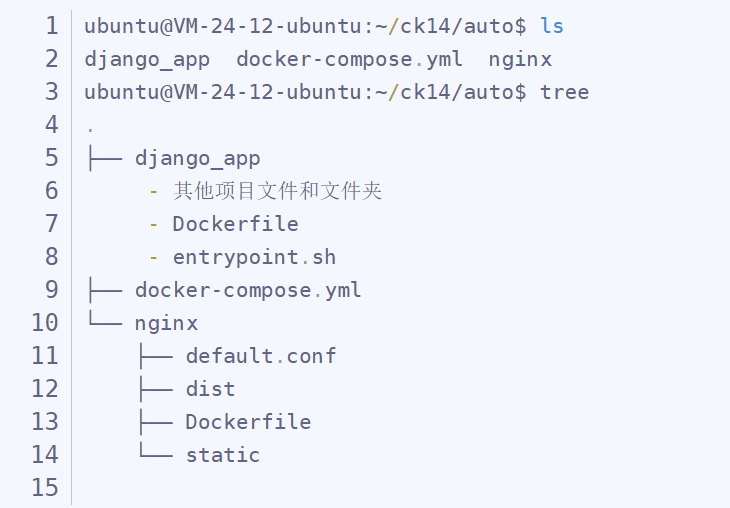
构建镜像
# 版本号设置为3
version: '3'# 服务名称,表示要启动的容器服务
services:# 每个服务的名字就是容器的名字# 当我们使用docker-compose -p ck14 up -d命令后# 这个服务的容器名默认为ck14_redis_1redis:# 启动这个容器需要用到的镜像image: redis:alpine# 重启策略restart: alwaysmariadb:image: mariadb:latestrestart: alwaysenvironment:# 启动容器要定义的环境变量MARIADB_ROOT_PASSWORD: rootMARIADB_DATABASE: ck14_data# 挂载卷volumes:- mariadb:/var/lib/mysqldjango_app:# 容器依赖,会等待对应的服务容器启动后才会启动当前服务depends_on:- redis- mariadb# Dockerfile所在目录build: ./django_appimage: ck14_django_imagerestart: alwaysenvironment:ENV: productionvolumes:- app_logs:/app/logsnginx:depends_on:- django_app# Dockerfile所在的目录build: ./nginximage: ck14_nginx_imageports:- "5001:80"- "5002:81"volumes:- nginx_logs:/var/log
volumes:mariadb:app_logs:nginx_logs:启动容器
sudo docker-compose up -p ck14 -d
停止容器
sudo docker-compose -p ck14 down
sudo docker-compose rm:删除指定服务的容器(停止状态的)sudo docker-compose start:启动指定服务已存在的容器
sudo docker-compose stop:停止已运行的服务的容器
sudo docker-compose restart:重启容器
7、Django中使用 ORM 和原生 SQL 的优缺点
ORM的优点正是原生SQL的缺点
ORM的缺点正是原生SQL的优点
ORM优点:
1、简化开发:ORM将数据库表映射为对象,使得开发者可以使用对象的方式进行数据库操作,不需要编写复杂的sql语句。
2、跨数据库支持:ORM可以根据配置自动适配不同的数据库,使得应用程序具有移植性。
3、安全性:ORM提供了内置的参数化查询,可以有限防止SQL注入攻击。
4、可读性:使用ORM可以使代码更加清晰易读,因为它使用了类和方法的调用方式,而不需要繁琐的SQL语句。
ORM缺点:
1、性能问题:ORM在某些情况下可能会引起性能问题,因为它需要将对象转换为SQL语句并执行,可能会产生额外的开销。
2、灵活性受限:ORM提供了一些常用的数据库操作方法,但对于一些复杂的查询或特定数据库功能,可能需要编写原生SQL语句来实现。
使用原生sql的优势:
1、性能优势:原生SQL可以直接操作数据库,避免了ORM转换的开销,在某些复杂查询或大数据量操作时,性能可能更好。
2、灵活性:原生SQL可以更灵活地编写复杂的查询语句,利用数据库的特性和功能。
使用原生SQL的缺点:
1、学习成本高:编写和调试复杂的SQL语句需要一定的数据库知识和经验。
2、 安全性问题:原生SQL容易受到SQL注入攻击,需要开发者自行处理参数化查询等安全问题。
3、可读性差:原生SQL语句通常比较冗长,可读性较差,代码维护和理解难度较大。
8、列举 Django 中执行原生 sql 的方法
1、raw()方法
返回查询集,通过在管理器上调用raw方法来实现
q=Student.objects.raw('select id,name' from t_student where id=2)
In [6]: q=Student.objects.raw('select id,name from t_student where id=2')In [7]: q
Out[7]: <RawQuerySet: select id,name from t_student where id=2>打印sql
In [8]: print(q.query)
select id,name from t_student where id=2取值
In [9]: q[0]
Out[9]: <Student: kobe>In [10]: q[0].name
Out[10]: 'kobe'In [11]: q[0].age
Out[11]: 20
2、使用extra
queryset=NewsChannel.objects.filter(name__contains='美').extra(where=['id>4'])queryset=NewsChannel.objects.extra(where=["name='美女' OR name='体育'","url='/sport/'"])
3、执行原生查询
执行调用原生数据驱动执行sql
with connection.cursor() as cursor:cursor.execute("select * from t_student")one=cursor.fetchone()print(one)two=cursor.fetchmany(2)print(two)all=cursor.fetchall()print(all)
执行结果
(2, 'kobe', 20, None, None, datetime.datetime(2023, 1, 1, 15, 26, 3, 84534), 5)
((3, 'li', 20, None, None, datetime.datetime(2023, 1, 1, 15, 26, 3, 84534), 1), (4, 'james', 18, '13888888888', None, datetime.datetime(2023, 1, 6, 7, 7, 17, 669711), 5))
((5, 'kelai', 22, '13688888888', None, datetime.datetime(2023, 1, 6, 7, 7, 17, 850752), 1), (6, 'kd', 19, '13888888777', None, datetime.datetime(2023, 1, 6, 7, 7, 17, 875757), 4), (7, 'harden', 18, '13888878228', None, datetime.datetime(2023, 1, 6, 7, 21, 25, 347180), 4), (8, 'curry', 22, '13688883388', None, datetime.datetime(2023, 1, 6, 7, 21, 25, 347180), 1), (9, 'ad', 19, '13888855577', None, datetime.datetime(2023, 1, 6, 7, 21, 25, 347180), 1), (10, 'happy', None, None, None, datetime.datetime(2023, 1, 7, 8, 19, 56, 927533), 4))
9、比较两个 json 数据是否相等
比较两个 JSON 数据是否相等可以通过以下步骤进行:
1、首先,将两个 JSON 数据解析为对象或字典。
2、然后,逐个比较两个对象或字典的键和值是否相等。
3、如果两个对象或字典的键和值都相等,则它们的 JSON 数据相等;否则,它们的 JSON 数据不相等。
需要注意的是,在比较过程中,需要考虑以下几点:
- 对象或字典中的键值对的顺序不影响 JSON 数据的相等性。
- 对于数组类型的值,需要递归地比较数组中的元素是否相等。