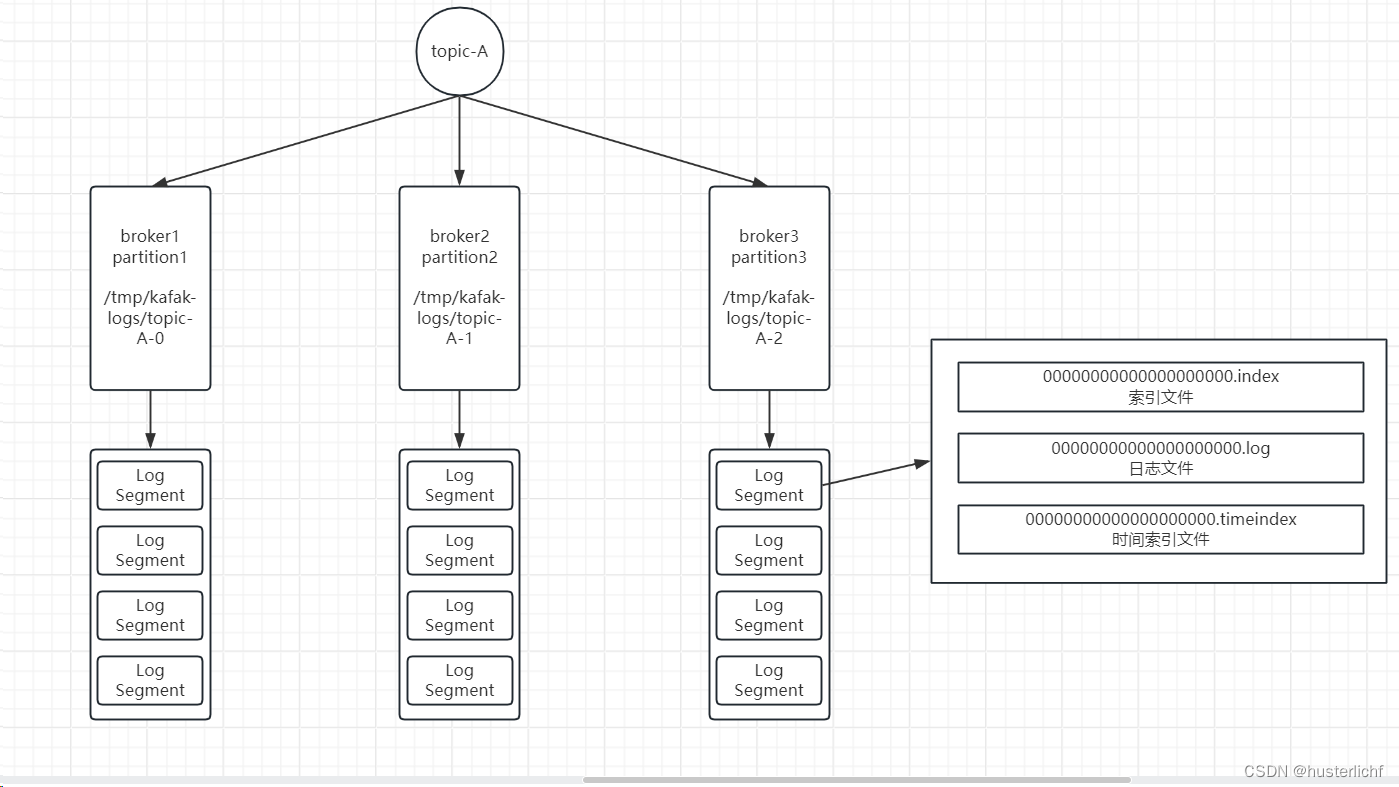
目录
- 前言
- 1. 速览图像生成模型
- 1.1 VAE
- 1.2 Flow-based Model
- 1.3 Diffusion Model
- 1.4 GAN
- 1.5 对比速览
- 2. Diffusion Model
- 3. Stable Diffusion
- 3.1 Text Encoder
- 3.2 Decoder
- 3.3 Generation Model
- 总结
- 参考
前言
简单学习下图像生成模型的相关知识🤗
以下内容来自于李宏毅老师的视频讲解
课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
视频链接:机器学习2023(生成式AI)
1. 速览图像生成模型
这节我们来讲图像生成模型,在开始之前呢,我们先讲图像生成有什么特别的地方,那图像生成有什么特别的地方呢?大家都知道俗话说一张图胜过前言万语,所以今天假设我们图像生成的任务是拿一段文字去生成一张图,比如说你把 “一只奔跑的狗” 这段文本丢给 Midjourney 然后它就会生成一张图给你

但是我们知道一张图胜过千言万语,如果要把一张图描述成文字那它可以描述的语句远比 “一只在奔跑的狗” 还要多,比如说这只狗奔跑的位置是在街道上或者这只狗是一只柯基,有很多的描述是不在你做图像生成的时候输入的文字里面的,所以你输入的文字只是千言万语的部分,在做图像生成的时候有很多部分不在人类输入的文字里面,机器需要进行大量脑补才能够生成好的图像。
那这就是图像生成跟文字生成比较不一样的地方,当然文字生成输入跟输出也不是一对一的关系,但是很多文字生成的任务比如说翻译,你一旦给定了输入了句子你输出的可能性其实是蛮有限的,但图像不一样,你给定一个句子它输出的可能性有非常多不同的样貌,也就是我们的输入只是输出的一小部分,机器需要大量的脑补才能够产生正确的结果,那等下我们要跟大家讲说这个需要进行大量脑补这件事造成模型的设计上有什么特别的地方
OK,那我们知道文字生成多采用 Autoregressive 的方法,那之前跟大家讲过在在文字生成的时候有两种策略,Autoregressive 各个击破或者是 Non-Autoregressive 一次到位的方法

那我们知道文字生成是这样,给定一个句子,不管你是像 GPT 一样通通都是 Decoder 还是一个 Sequence to Sequence 的 Model,给一个输入,一个句子,然后接下来你要输出一个机率的分布,然后根据这个机率的分布去做 sample 取出一个文字,根据取出来的文字再产生新的机率分布再取出新的文字,这样就可以产生一个回答的结果
那对于图像生成来说,其实直觉上你会觉得应该也可以套用几乎一模一样的做法,一个图像生成的模型应该可以是一段文字接下来它输出的这个 distribution 不是文字的 distribution 而是颜色的 distribution
比如绿色产生的机率是多少,黄色产生的机率是多少,通常用 Pixel 像素来表示,也就是说现在要画一只奔跑的狗,那你第一个像素中放红色像素的机率有多少,要放一个绿色像素的机率有多少

那我们知道说图像中的一个 Pixel 它是由 RGB 三个颜色组成的,而 RGB 分别又是由一个 0 到 255 的数字所表示的,所以按理说应该有 256x256x256 种不同的颜色,不过你实际在做图像生成的时候其实你也用不上那么多的颜色,你可以选个比如说 256 色其实往往就蛮足够的
那其实像这种用 Autoregressive 生成图像的方法过去也是有的,OpenAI 其实也做过很类似的事情,它们也只选了 256 个颜色而已,那总之你决定第一个 pixel 要放每一个颜色的机率,然后根据这个机率做 sample 比如 sample 到绿色就填充一个绿色的 pixel,然后接下来根据已经填充了绿色 pixel 这件事还有已经输入的文字再产生新的分布,然后可能就决定画红色的 pixel,依此类推
那如果要画一张 256x256 分辨率的图像,那同样的过程就是要重复 256x256=65536 次,你就可以画一张 256x256 的图像就结束了
能不能这么做呢?能这么做,所以其实 OpenAI 有一个图像版的 GPT,那图像版的 GPU 它就是先把一张二维的图片拉直变成一个 sequence,然后接下来就是直接当作一个 language model 的问题,直接把它当作文字
只是现在我们这个 Token 的数目因为只有 256 色所以 Token 的数目就是 256,然后用一个 Autoregressive 的 Model train 下去就结束了,这个方法其实也可以生成蛮高清的图片,如下图所示:

那我们之前有讲过说对于图像生成而言这种方法太耗费时间了,所以在图像生成任务中今天你看到多数的模型采取的都是一步到位的方法,也就是说给一段文字,如果你要生成一张图像,那在概念上你会做的事情就是我把每一个位置要放什么颜色的 distribution 都先产生出来,然后再根据这些 distribution 去做 sample,但是这么做会有什么问题呢?

因为我们刚才有讲过说一张图胜过千言万语,所以当你输入正在奔跑的狗的时候它的正确答案不是只有一个,它有很多种不同的可能性,不同大小不同毛色不同背景等等,所以今天当你输入一段文字的时候正确答案不是一个,一般我们在做机器学习的时候我们通常比较习惯的是输入一个东西有一个标准的正确答案
但是在图像生成这个问题中并不是这样的,图像生成的问题是有一个输入它的正确答案是一个分布,是一个 distribution,在这个分布内的都可以说是正确答案,但是如果我们一个一个 pixel 分开去做 sample 会发生什么事情呢?如果一个一个 pixel 分开去做 sample,每一个 pixel 的产生都是各自独立的,那就会变成有些 pixel 是想画往左跑的狗,有些 pixel 想要画往右跑的狗,有些 pixel 想要画黑的狗,有些 pixel 想要画白的狗,然后最后全部凑起来就可能是一个四不像
那在上图中我们把四张图片各切一块拼在一起,那你就不知道在画些什么东西,所以如果是一步到位的方法,你要 pixel 独立各自去做 sample 其实是会得到非常差的结果的,所以怎么办呢?
你会发现今天图像生成的模型都有一个共同的套路,这个共同的套路是什么呢?它们都不是直接给一段文字就生成图,它们都会有一个额外的输入,这个额外的输入是由一个高维的 Normal Distribution 做 sample 得到的一个高位的向量,然后把这个向量丢到图像生成的模型里面跟这个文字合力去产生你最后的结果

所以你会发现说不管你今天是用什么图像生成的模型,VAE、Flow-based Model、GAN 或者是热门的 Diffusion Model 其实方法都是一样的,你都不只是只有拿文字去生图像,你都需要一个额外的输入,你都需要从一个简单的概率分布里面去 sample 出一个东西,sample 出来的这个东西有点像是噪声。
因为你是从这个 Normal Distribution 里面 sample 出来,所以 sample 出来就是一个像是噪声的东西,丢到图像生成模型里面你才能够产生最终的结果。那这背后所代表的含义是什么呢?我们现在如果把文字用 y y y 来描述,图像用 x x x 来描述,那正确答案的分布我们可以写成 P ( x ∣ y ) P(x|y) P(x∣y),它显然会非常的复杂,如果我们可以知道说 P ( x ∣ y ) P(x|y) P(x∣y) 长什么样子,我们从这个分布里面去做 sample 我们就可以把图画出来
但是问题是 P ( x ∣ y ) P(x|y) P(x∣y) 它非常的复杂,其实在过去早些时候比如说在 GAN 都还没有的 2014 年以前人们还不知道用什么 deep learning 生图的时候,多数就假设说 P ( x ∣ y ) P(x|y) P(x∣y) 可能是一个 Mixture Gaussian 由多个 Gaussian 所组成的,然后我们看这个模型能不能够 learn 出来,那其实它生成的图都非常模糊跟今天就是完全不在同一个量级上面,所以这个 P ( x ∣ y ) P(x|y) P(x∣y) 它显然非常的复杂,复杂到它不是一个你用人脑可以想出来的模型,它不是一个简单的 Gaussian Distribution,所以怎么办呢?
这边的策略是我们把 Normal Distribution 里面 sample 出来的 vector 都对应到 P ( x ∣ y ) P(x|y) P(x∣y) 里面的每一个 x x x,我们知道说如果要画一只奔跑的够,有很多不同可能的样子,那我们把 Normal Distribution 里面 sample 出来的 vector 一个一个对应到可能画的狗,这个图像生成的模型等于就是在产生这种对应关系,图像生成的模型它做的工作就是想办法把 Normal Distribution 里面 sample 出来的东西对应到正确的狗在奔跑的图片
OK,那所以接下来难的点就是怎么把这个 distribution 变成 P ( x ∣ y ) P(x|y) P(x∣y) 的样子呢?那这个其实就是所以的图像生成的模型都在解的问题,那所以这些图像生成的模型和背后想攻克的问题其实是一样的,只是解法是不一样的
那我们下面快速的过一下常用的图像生成的模型,以下的说明都非常简略,很多东西就一笔带过,那如果大家想知道这些图像生成模型背后真正的原因可以查阅下相关资料
1.1 VAE
第一个要讲的是 VAE(Variational Auto-encoder),如下图所示:

那 VAE 它做的事情是什么呢?我们今天想要从 Normal Distribution 对应到图像怎么做呢?我们期待有一个 Decoder,这个 Decoder 就吃 Normal Distribution sample 出来的 vector 作为输入,它的输入就应该是一张正确的图片,那上面是把文字的输入省略了。那怎么训练这样的 Decoder 呢?怎么训练一个向量对应到一张图片这样子的 Decoder 呢?你要知道今天训练一个 Network 你要有成对的数据才能训练 Network
如果有人告诉你说每一张图片都应该对应到哪一个向量那你就可以训练这个 Decoder,我们并不知道 Normal Distribution sample 出来的 vector 跟这些狗正在奔跑的图片到底有什么样的关系,那怎么办呢?
那另外我们有一个东西叫 Encoder,Encoder 做的事情跟 Decoder 正好相反,把一张图片变成一个向量,那只有 Encoder 或者只有 Decoder 都没有办法训练,所以怎么办呢?把 Encoder 跟 Decoder 串起来,一个 Encoder 输入一张图片产生一个向量,这个向量丢给 Decoder 要还原回一样的图片,那 Encoder 跟 Decoder 是一起训练的,要让输入跟输出越接近越好。
但是光有这样的训练是不够的,因为如果光有这样的训练,那生成的向量的分布不一定会是一个 Normal Distribution,所以你要加一个额外的限制来强迫中间的向量是 Normal Distribution,这个就是 VAE 的概念
如果大家想要了解更多关于 VAE 背后的原理可以看看李宏毅老师之前的视频:ML Lecture 18: Unsupervised Learning - Deep Generative Model (Part II)
1.2 Flow-based Model
接下来讲 Flow-based Model,如下图所示:

Flow-based Model 是怎么做的呢?它跟刚才的 VAE 反过来,我们先来想 Encoder,我们能不能训练一个 Encoder 吃一张图片输出就是一个向量,而这个向量的分布希望它是一个 Normal Distribution,如果能够做到这件事情,一个 Encoder 输入一张图片输出的向量就是 Normal Distribution,然后接下来我们再强迫这个 Encoder 是一个 Invertible 的 function,你就可以直接把这个 Encoder 当作 Decoder 来用
训练的时候它是吃图片输出向量,这个向量的分布是 Normal Distribution,实际上你要画图的时候要把这个 Encoder 反过来用,让它可以输入一个向量然后就输出一张图片
那你第一个会问的问题是怎么强迫 Encoder 一定是 Invertible 的呢?我们现在是在训练 Neural Network,随便训练一个 Neural Network 你怎么知道它的 Inverse 长什么样子呢?这个就是 Flow-based Model 神奇的地方,它有刻意限制 Network 的架构,所以 Flow-based Model 不是你随便的 Network 架构都可以当作 Encoder 来用的,它有刻意限制了 Network 的架构让你 train 完以后你马上知道这个 Encoder 的 Inverse 长什么样子
那这个细节大家可以看下:Flow-based Generative Model
那另外一件事情是因为这个 Encoder 它必须是 Invertible,意味着什么,意味着输出的那个 vector 的 dimension 要跟输入图片一样,如果你输入的图片是 256x256 的,那你 Encoder 的输出就要是一个 256x256 的向量,为什么输入跟输出的大小一定是一样呢?如果不一样你就没有办法保证 Invertible 的,如果输出的向量比输入的图片 dimension 小,你就没办法保证它是 Invertible,所以输出的向量必要要跟输入的图片它们的大小是一样的,所以这个就是 Flow-based Model 的概念
1.3 Diffusion Model
接下来我们来讲 Diffusion Model,如下图所示:

下一节我们会更详细的跟大家讲 Diffusion Model 是怎么做的,这里我们就简单讲一下 Diffusion Model 的概念,那 Diffusion Model 是什么呢?我们就是把一张图片一直加噪声一直加噪声,加到原来的图看不出来是什么,那看起来就像是从 Normal Distribution sample 出来的一个噪声一样。那怎么生成图片呢?生成图片的方法就是你 learn 一个 Denoise 的 Model,那实际上怎么做我们下一节会讲到,learn 一个 Denoise 的 Model 后把 Normal Distribution sample 出来的 vector 当作输入然后不断去噪去噪,你要的图就慢慢产生出来了,就是这么的神奇
那可能大家心里充满了困惑和怀疑,那也是很正常的,那我们下一节会再详细的讲这个模型
1.4 GAN
OK,那最好一个要讲的就是大家都耳熟能详的 GAN,如下图所示:

那 GAN 它是只 learn Decoder 它就没有 learn Encoder 了,那 GAN 怎么 learn Decoder 呢?那一开始你就给它一大堆从 Normal Distribution sample 出来的向量,那一开始呢这个 Decoder 没有经过训练所以它根本不知道怎么画一张图,所以就输出一些乱七八糟的东西,通常一开始的输出的东西都是一些噪声,你根本不知道在画些什么
那接下来你会训练一个 Discriminator,这个 Discriminator 的工作就是去分辨输入的图片也就是 Decoder 产生出来的是虚假的图片还是真正的图片,如果我们今天把真正的图片的分布想成 P ( x ) P(x) P(x),当然如果你是有文字输入的要就是 P ( x ∣ y ) P(x|y) P(x∣y),不过这边先把文字的 condition 省略掉,那这个真实图片的分布是 P ( x ) P(x) P(x)
Decoder 产生出来的图片分布是 P ′ ( x ) P'(x) P′(x),这个 Discriminator 实际上在做的事情是什么呢?其实这个 Discriminator 训练的时候的 loss 其实就代表了 P ( x ) P(x) P(x) 和 P ′ ( x ) P'(x) P′(x) 它们的相似程度,那这个在直觉上其实也是蛮容易理解的,因为当 Discriminator 没有办法分辨来自这两个 Distribution 的 image 的时候,代表这两个 distribution 的 image 非常的接近。
Decoder 要做的事情就是想办法调整它的参数让 Discriminator 做得越差越好,那这个就是 GAN 的概念,当 Discriminator 做得差了就代表 P ′ ( x ) P'(x) P′(x) 也就是这个 Decoder 生成的图片的分布跟真正的图片的分布有很大的差距,那这个就是 GAN
如果你想要知道更多关于 GAN 的内容你可以参考下:GAN Lecture 1 (2018): Introduction
1.5 对比速览

上图是一次速览 VAE、Flow-based Model 跟 Diffusion Model 的差异,那它们的共通性就是它们都有一个 Encoder 的机制一个 Decoder 的机制,在 VAE 里面 Encoder、Decoder 都是 Neural Network,都是类神经网络,都很复杂;那在 Flow-based Model 里面我们其实只 learn 了 Encoder,但是我们做了一些手脚来保证 Encoder 是 Invertible 的,所以我们的 Decoder 其实就是 Encoder 的 Inverse,所以在 Flow-based Model 里面只需要 learn Encoder
那 Diffusion Model 是反过来,其实它只有 learn Decoder 这个 Model,它没有 Encoder 这个东西,它就是把图片一直加噪声一直加噪声,当然你也可以把加噪声这个步骤想成是一个 Encoder,只是这是一个不需要 learn 的 Encoder,它没有参数所以不需要 train 它。那产生这个噪声以后再做 Denoise,做 N 次 Denoise 把这个噪声还原成图片,那这个做 N 次 Denoise 的过程其实就是 Decoder,你可以想成每做一次 Denoise 就是 Decoder 通过了一层,所以 VAE、Flow-based Model 以及 Diffusion Model 其实它们有非常多的共通性
今天最强的那些图像生成的模型比如说 DALL-E、Stable Diffusion、Imagen 都是用 Diffusion Model 做的,但是这些模型之所以会这么强也不完全是 Diffusion Model 的功劳,那我们后面会概览一下 Stable Diffusion,那你会知道说 Stable Diffusion 里面其实是加了很多其它的东西才会让它这么厉害
那上图中没有 GAN,为什么没有 GAN 呢?因为 GAN 它其实就是另外一个角度的思考,所以它跟 VAE、Flow-based Model 以及 Diffusion Model 事实上是没有互斥的,你永远可以在你的 Decoder 后面再接一个 Discriminator 让你的 Decoder 的 output 跟真实的图片的分布越接近越好,于是就有了:
- VAE+GAN:Autoencoding beyond pixels using a learned similarity metric
- Flow+GAN:Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models
- Diffusion+GAN:Diffusion-GAN: Training GANs with Diffusion
OK,以上就是图像生成模型速览的全部内容了
小结
文生图任务与其它任务不一样,它的正确答案是一个分布,因此图像生成模型共同需要攻克的问题是怎么把 Normal Distribution 中 sample 出来的 vector 对应到正确的图片上
2. Diffusion Model
这节简略介绍下 Diffusion Model 的基本概念,那其实 Diffusion Model 有很多不同的变形,我们拿最知名的 Denoising Diffusion Probabilistic Models 也就是大家常常提到的 DDPM 来讲解
那今天其实比较成功的那些图像生成模型比如 OpenAI 的 DALL-E、Google 的 Imagen 以及 Stable Diffusion 基本都是用差不多的方法来构建属于他们自己的 Diffusion Model
那 Diffusion Model 是怎么运作的呢?我们来看下图:

Diffusion Model 运作的方式如上图所示,我们来看它是怎么生成一张图片的。在生成图片的第一步你要去 sample 出一个都是噪声的图片,也就是我们要从 Gaussian Distribution 里面 sample 出一个 vector,这个 vector 的维度和你要生成的图片大小一样。假设你要生成一张 256x256 的图片,那你从 Gaussian Distribution 中 sample 出来的 vector 的维度也要是 256x256
那接下来需要将你 sample 出来的噪声图片送入到 Denoise Model,那 Denoise Model 内部长什么样子我们待会再将,那从 Denoise Model 的名字就可以知道说它的功能是输入一张都是噪声的图,那输出就会把噪声滤掉一点,那你就可能看到有一个猫的形状
然后我们继续做 Denoise,随着你的 Denoise 越做越多最终你就能看到一张清晰的图片,那这个 Denoise 的次数都是事先定好的,我们通常会给每一个 Denoise 的步骤一个编号(Step ID),那产生最终图片的 Denoise 的编号就比较小。一开始从完全都是噪声的输入开始做 Deniose,编号从 1000 一直做到 1,那这个从噪声到图片的步骤我们叫做 Reverse Process
OK,下面我们来讲 Denoise Model
那从上面的图上看来你可能会想说 Denoise Model 是不是同一个呢?是不是同一个 Denoise Model 反复用很多次呢?但是因为这边每一个 Denoise Model 输入的图片差异非常大,比如最开始的 Denoise Model 的输入就是一个纯噪声,而在靠后的 Denoise Model 输入的图片噪声非常小,它已经非常接近完整的图。所以如果所有的 Denoise Model 都是同一个,它可能不一定能够真的做得很好,所以怎么办呢?

我们来看上图,那我们的 Denoise Model 它除了输入图片外还会额外多一个输入,这个输入代表现在 Noise 严重的程度,1000 代表刚开始 Denoise 的时候,这个时候 Noise 的严重程度很大,然后 1 代表说现在 Denoise 的步骤快结束了,这个是最后一步 Denoise 的步骤,那显然噪声很小。那这个 Denoise Model 我们希望它可以根据我们现在输入在第几个 Step 做出不同的回应,这个就是 Denoise Moduel。
所以我们确实只有用一个 Denoise Model,但是这个 Denoise Model 会有一个额外的数字输入,告诉它现在是在 Denoise 的哪一个 Step
OK,那 Denoise Model 实际内部做的事情是什么呢?我们来看下图:

在 Denoise 的模组里面它实际上有一个 Noise Predicter,这个 Noise Predicter 做的事情就是去预测图片里面的噪声长什么样子,这个 Noise Predicter 的输入是一张要被 Denoise 的图片和描述图片 Noise 严重程度的 Step ID,输出呢就是一张噪声的图,它就是预测说图片里面噪声应该长什么样子,再把它输出的噪声去减掉要被 Denoise 的图片就产生了 Denoise 后的结果。
所以这边 Denoise Model 并不是输入一张有 Noise 的图片输出就直接是 Denoise 后的图片,它其实是产生了一个输入图片的噪声,再把噪声减掉输入的图片来达到 Denoise 的效果。那你可能会想为什么要这么麻烦呢?为什么不直接 learn 一个 End-to-End 的 model,输入是要被 Denoise 的图片输出就直接是 Denoise 的结果呢?你可以这么做,也有一些 paper 是这么做的,不过现在多数的 paper 还是选择 learn 一个 Noise Predicter。
因为我们可以想想看产生一张图片和产生 Noise 它的难度是不一样的,如果今天你的 Denoise Model 可以产生一只带噪声的猫,那它几乎就可以说它已经会画一只猫了,那所以要产生一个带噪声的猫跟产生一张图片里面的噪声,这个难度是不一样的。所以直接 learn 一个 Noise Predicter 可能是比较简单的,learn 一个 End-to-End 的 Model 要直接产生 Denoise 的结果是比较困难的。
OK,那接下来的问题就是怎么训练这个 Noise Predicter 呢?

我们已经知道我们 Denoise Model 输入是一张 Noise 的图片和现在在 Denoise 的 Step ID 然后产生 Denoise 的结果。我们上面有说其实 Denoise Model 里面是一个 Noise Predicter,它的输入就是一张 Noise 的图片和 Step ID 然后产生一个预测出来的噪声,但是你要产生出一个预测出来的噪声你得有 Ground Truth 啊
我们在训练 Network 的时候就是要有 pair data 才能够训练呀,你需要告诉 Noise Predicter 这张图片里面的噪声长什么样子它才能够学习怎么把噪声输出出来啊,那这件事情怎么做呢?怎么制造出这样的数据呢?
那这个 Noise Predicter 它的训练数据是我们人去创造出来的,怎么创造呢?如下图所示:

它的创造方法是这样的,你从你的 Dataset 里面拿一张图片出来你自己加噪声进去,你就 Random sample 从 Gaussian Distribution 里面 sample 一组噪声出来加上去产生有点 Noise 的 image,那你可能再 sample 一次再得到更 Noise 的 image,依此类推最后整张图就看不出原来是什么东西。这个加噪声的过程叫做 Forward Process 又叫做 Diffusion Process

那做完这个 Diffusion Process 以后你就有 Noise Predicter 的训练数据了,这是因为对 Noise Predicter 来说它的训练数据就是一张加完噪声的图片跟现在是第几次加噪声,这个是 Network 的 input,而加入的这个噪声就是 Network 应该要 predict 的输出,就是 Network 输出的 ground truth。所以我们才说你在做完 DIffusion Process 以后你手上就有训练数据了,接下里就跟训练一般的 Network 一样 train 下去就结束了。

但是我们要的不只是生图而已,刚才讲的好像只是从一个噪声里面生成图还没有把文字考虑进来,那要怎么把文字考虑进来呢?我们待会讲,在讲怎么把文字考虑进来之前需要先让大家知道的事情是如果你今天要训练一个图像生成模型,它输入文字产生图片(如上图所示),你其实还是需要成对的数据,你还是需要图片跟文字成对的数据,需要多少成对的数据呢?那你今天在网络上看到非常厉害的图像生成模型像 Midjourney、Stable Diffusion 或者是 DALL-E 它们的数据往往来自于 Laion,网址是:https://laion.ai/projects/
Laion 有多少 image 呢,5.85 Billon 的图片也就是 58.5 亿张的图片,所以也难怪今天的这些模型可以产生这么好的效果

Laion 其实有一个搜索的 Demo 平台,链接是 https://rom1504.github.io/clip-retrieval/,大家可以去里面看看有什么样的图片,比如说上图中的猫的图片,它不只是只有猫的图片跟英文文字的对应它还有跟中文的对应还有跟日文的对应,所以这也就解释了为什么你今天看到的那些图像生成模型不是只看得到英文,中文它也能看懂,这是因为它的训练数据里面也有中文跟其它的语言,所以这个是你需要准备的训练数据。
OK,那有了这个文字和图像成对的数据以后我们先来看下 Denoise 的时候是怎么做的

Denoise 的时候做法非常简单,把文字加到 Denoise Model 中就结束了,所以现在 Denoise Model 不是只看输入的图片做 Denoise,它是根据输入的图片加上一段文字的叙述去吧 Noise 拿掉,所以在每一个 Step 你的 Denoise Model 都会有一个额外的输入,这个额外的输入就是你要根据这段文字的叙述生成什么样的图片
OK,那这个 Denoise Model 里面的 Noise Predicter 要怎么改呢?我们来看下图:

那在 Noise Predicter 中你就是直接把一段文字给 Noise Predicter 就结束了,你就要让 Noise Predictor 多一个额外的输入也就是一段文字描述就结束了
OK,那训练的部分要怎么改呢?

你现在每一张图片都有一段文字,所以你先把这张图片做完 Diffusion Process 得到 pair data 的训练数据以后,你在训练的时候不只要给你的 Noise Predicter 加入噪声后的图片和 Step ID 还要多给一个文字的输入,然后 Noise Predicter 会根据这三样东西产生适合的 Noise,产生要消掉的 Noise,也就是我们所说的 ground truth
下图是 DDPM 完整的 Algorithm,这两个 Algorithm 里面其实还是暗藏一些玄机,这个以后再讲

小结
这节简单了解了 Diffusion Model 的工作流程,它主要是先 random sample 一张噪声的图片然后不断通过 Denoise Model 去噪最终变成一张完整的图片。而 Denoise Model 并不都是同一个,它内部实际上有一个 Noise Predicter 噪声预测器,这个 Noise Predicter 有两个输入,一个是带有噪声的图片以及噪声描述图片噪声严重程度的 Step ID,通过这两个输入 Noise Predicter 得到一个噪声的输入,然后与输入的噪声图片相减得到 Denosie 后的图片,这就是 Diffusion Model 图像生成的流程。
现在的文生图模型如 Midjourney、Stable Diffusion 或者是 DALL-E 它们应该都是利用 Diffusion Model 的方式来生图的,不过相比于 Diffusion Model 而言文生图多了一个文字的输入,这个需要在 Denoise 的时候加上这段文字描述
以上就是关于 Diffusion Model 的简单介绍
3. Stable Diffusion
OK,这节我们来讲大名鼎鼎的 Stable Diffusion,那其实今天比较好的图像生成的模型就算它不是 Stable Diffusion,它的套路其实也跟 Stable Diffusion 差不多,所以我们进行就是要来介绍这个 SOTA 的图像生成模型它背后的套路长什么样子

今天最好的图像生成模型基本上它内部就是有三个元件(如上图所示),第一个元件是一个 Text Encoder 是一个好的文字的 Encoder,它会把一段文字的叙述把它变成一个一个的向量
然后接下来你会有一个 Generation Model,那今天大家都用 Diffusion Model,但用别的也是可以的,这个 Generation Model 输入噪声和文字 Encoder 的向量输出一个中间产物,这个中间产物等一下再细讲,它可以是一个人看得懂的只是比较小比较模糊的图片,它也可以甚至是人根本看不懂的东西,那这个中间产物是一个图片被压缩以后的结果,这是第二个模组
从 Generation Model 的输出产生一个中间产物代表图片被压缩以后的版本,接下来直接套一个 Decoder,这个 Decode 的作用是从压缩后的版本还原回原始
我们刚才讲说整个图像生成模型的框架有三个模组,一个文字的 Encoder,一个生成的模型今天用 Diffusion Model,还有一个 Decoder 直接从生成模型输出的图片的压缩版本还原回原来的图片。通常三个模组是分开训练然后再把它们组合起来的,今天你看到的比较好的文生图的模型都是差不多的套路
Stable Diffusion

上面是 Stable Diffusion 论文里面的一张图,我们可以看到它最右边有一个 Encoder 可以处理输入的东西,但它的输入不是只有文字啦,它还有别的可能的输入,但是反正输入文字你需要一个 Encoder 来处理它,然后你需要有一个生成的模型,那这边 Stable Diffusion 内部当然用的就是 Diffusion Model,也就是中间绿色的部分,那你还需要有一个 Decoder 把 Diffusion Model 生成的中间产物,一个图片压缩后的版本还原回原来的图片,也就是最左边红色的部分,其实就是我们刚才讲的三个 component
DALL-E

那 DALL-E 系列其实一开始也是用的相同的套路,你需要有一个文字的 Encoder 先对文字进行理解,接下来你要有一个生成的模型,那其实在 DALL-E 里面它是有两个生成的模型,你可以用 Auto Regressive Model,因为今天已经先做了一些处理以后现在你要产生的并不是一张完整的图片,如果你要生成完整的图片的话 Auto Regressive Model 的运算里太大了,但是如果生成的只是一个图片的压缩的版本也许用 Auto Regressive 的方法还可以,所以可以用 Auto Regressive 也可以用 Diffusion Model 生成图片的压缩版本,最后用个 Decoder 还原回原来的图片,这是 DALL-E 系列的做法
Auto Regressive Model 是什么呢?
Imagen

Google 也有一个图像生成的模型叫 Imagen 如上图所示,它也是输入一段文字产生一张图片,这个套路也是一样的,先有一个好的文字的 Encoder 然后你要有一个图像生成的模型从文字去生成图片压缩后的版本,那在 Imagen 里面它生出来的东西就是人看得懂的东西,它生成出来的东西就是一张比较小的图片,最终目标是要生 1024x1024 的大图,但是 Diffusion Model 只帮我们生成这个 64x64 的小图,然后接下来再有一个 Decoder,不过它的 Decoder 也是一个 Diffusion Model,它的 Decoder 把小图再生成大图,这个就是 Imagen
3.1 Text Encoder
现在我们就来介绍整个图像生成模型 Framework 里面的三个 component,第一个要介绍的是文字的 Encoder,文字的 Encoder 其实也不用再多做介绍,就是我们之前讲的那些东西,比如说你可以拿 GPT 当作你的 Encoder,更早时代你也可以拿 BERT 当作你的 Encoder

那上面展示的这个实验结果是要告诉你说这个 Encoder,这个文字的 Encoder 其实对结果的影响是非常大的,那这个结果来自于 Google 的 Imagen 这篇 paper,那在 Google 他们用的 Encoder 是一个叫做 T5 的 Encoder,总之就是一个文字的 Encoder 就对了。
他们尝试了不同的版本由小到大,那在上图中他们用两个不同的指标来衡量生成图片的好坏,一个是 FID,FID 的值越小代表你生成的图片越好,另一个是 CLIP Score,那这个 CLIP Score 它是值越大越好,总之越往右下角越好
那从上图中我们可以很明显的看到说,随着用的这个 Encoder 越来越大图像生成的品质是越来越高的,所以我们知道说文字的 Encoder 对结果其实是非常重要的,那这个其实也是可以理解的,因为对于这个图像生成的模型而言,如果你今天没有用额外的文字的 Encoder,它读过的文字就是 Laion 中那 50 亿张图片所带有的 caption,那它读的文字量还是很有限的,可能有很多奇奇怪怪的东西它是不知道那是什么的,那所以你有一个好的文字的 Encoder 可以帮助它去 process 那些它在图像跟文字成对的数据里面没有看过的比如说新的词汇,所以这个文字的 Encoder 对结果的影响其实是很大的
那相对而言这个 Diffusion Model 的大小似乎就没有那么重要,图中的 UNet Size 其实指的是那个 Diffusion Model 里面的那个 Noise Predictor 的大小,那在 Imagen 这篇 paper 里面就尝试用了不同大小的 Diffusion Model,发现增大 Diffusion Model 对结果的帮助是比较有限的。
所以看起来文字的 Encoder 其实对于今天这些图像生成模型这么好的表现其实是非常重要的
今天我们在做这种图像生成任务的时候一个难题就是你怎么评估这个图像生成的模型到底做得好还是做得不好呢?你怎么来衡量生成的一张图片的好坏呢?你需要有一些特别的方法,那其中一个今天很常用的叫做 FID(Fréchet Inception Distance)

FID 是什么呢?FID 就是你得先有一个 Pre-trained 好的 CNN Model,你得先有一个 Pre-trained 好的图像分类的模型,你把手上的图片不管是机器生成的还是真实的图片通通丢到这个 CNN 里面得到 CNN 的 Latent Representation
你把真实图像的 Representation 和机器生成图像的 Representation 画出来,在上图中蓝色的点代表的是生成的图片通过这个图像分类的 Model 以后所产生的 Representation,红色的点则代表的是真实图片所产生的 Representation,如果这两组 Representation 越接近就代表说生成的图像跟真实的图像越接近,如果这两组 Representation 分得很远就代表说真实的图像跟生成的图像它们非常的不像
那怎么计算两组 Representation 之间的距离呢?FID 这边用的是一个其实很粗糙但是有用的方法。它的假设非常简单,假设这两组 Representation 都是 Gaussian Distribution,然后算这两个 Gaussian Distribution 的 Distance,那这个算的是一个叫做 Fréchet 的 Distance,然后就结束了
那这个方法看起来有点粗糙,但是它的结果看起来是好的,跟人类的评估是蛮一致的,所以 FID 现在仍然是一个非常常用的做法,就算是今天这个 Imagen 这么新的模型还是用 FID 作为评估的基准之一。那因为它算的两组 Distribution 之间的距离所以这个分数是越小越好,距离越小代表你的模型生成的结果越好。但 FID 有一个问题需要注意,那就是你需要 sample 处很多的 image,你不能只 sample 出几张 image 就量 FID,你需要 sample 大量的 image 才能量 FID
那另一个指标 CLIP Score 又是什么呢?我们先讲 CLIP,CLIP 是 Contrastive Language-Image Pre-Training 的缩写,它是用 400 个 Million 的 image 和 text pair 的 data 所训练出来的一个模型,

这个模型做的事情就是它里面有一个 image 的 Encoder,有一个 text 的 Encoder,那 Text 的 Encoder 读一段文字作为输入产生一个向量,Image 的 Encoder 读一张图片作为输入产生一个向量,那如果这张图片和这段文字它们是 pair 的,它们是成对的,也就是说这段文字是在描述这个图片,那这两个向量就要越近越好,如果它们不是成对的那这两个向量就要越远越好
那 CLIP Score 简单来说把你机器产生出来的图片丢进去然后把你当时让机器产生图片的那段文字的叙述也丢进去,然后看看 CLIP 计算出来的向量的距离,看它们像不像,如果很像就代表 CLIP Score 高也就代表说你的模型生成的那个图跟那段文字是有对应的关系的,这个就是 CLIP Score
3.2 Decoder
OK,那刚才讲的是 Text Encoder 接下来我们先讲 Decoder,那这个 Decoder 做的事情是什么呢?这个 Decoder 它一般在训练的时候就不需要图像和文本成对的数据,你要训练中间的这个 Generation Model 比如说 Diffusion Model 让它可以输入文字的 Embedding 再产生中间产物这需要 pair data,需要图像跟文字的对应关系
那图像跟文字对应的数据虽然今天你说可以收集到 50 亿这么多的图像跟文字成对的数据,但是没有跟文字成对的图像是更多更多的,而这个额外的 Decoder 它的好处就是它的训练是不需要文字数据的
你可以单凭着大量的图像的数据就自动把这个 Decoder 训练出来,那这个 Decoder 是怎么训练的呢?

如果你的中间产物是一张比较小的图,也就是你今天的 Decoder 的输入是小图,那 Decoder 的训练非常简单,你就把你手上可以找得到的图像都拿出来然后把它们做 Downsampling 变成小图你就有成对的资料,你就可以训练 Decoder 把小图变成大图就结束了

那如果我们的中间产物不是小图而是某种 Latent Representation 呢?那我们怎么训练一个 Decoder 它可以把 Latent Representation 当作输入,把这些 Latent Representation 还原成一张图片呢?那你就要训练一个 Auto-encoder,这个 Auto-encoder 做的事情就是有一个 Encoder 输入一张图片变成一个 Latent Representation 然后把 Latent Representation 通过 Decoder 还原原来的图片,然后你要让输入跟输出越接近越好,那像这样的讨论我们前面已经讲过了。总之你就训练这个 Encoder 跟 Decoder,训练完就把这个 Decoder 拿出来用,这个 Decoder 就可以输入一个 Latent Representation 还原一张图片。这个是中间产物是 Latent Representation 的情况,那像 Imagen 用的就是前面把小图当中间产物,那像 Stable Diffusion 还有 DALL-E 就是用的上图的方法,把 Latent Representation 当作中间产物
OK,那通常这个中间产物长什么样子呢?如果讲得更具体一点通常的做法是(上图)这个样子,假设你输入的图片是 HxWx3,那通常你的这个 Latent Representation 可以写成 hxwx3,所以你要把它当作是一张小图也可以,只是这张小图是人类看不懂的小图,这个 h 跟 w 是 H 跟 W 做 downsampling 的结果,然后这个 c 就代表的是 channel,就代表说在这小图上每一个位置是用多少个数字来表示,如果 c 等于 10 就代表每一个位置是用 10 个数字来表示
3.3 Generation Model
OK,那最后就来进入 Generation Model 的部分

那 Generation Model 的作用就是输入文字的 Representation 产生一个中间产物图片压缩的结果,那怎么做呢?那我们已经讲过 Diffusion Model 的概念了,我们现在唯一不一样的地方是刚才在做 Diffusion Process 的时候你的 Noise 是直接加在图片上,但是现在我们要 Diffusion Model 产生出来的东西已经不是图片了,那怎么办呢?

我们的这个 Noise 要加在中间产物上或加在 Latent Representation 上,所以假设我今天是拿 Latent Representation 当作中间产物,这边的做法就是你先拿个 Encoder 出来,Encoder 吃一张图片然后产生 Latent Representation,接下来你的噪声是加载 Latent Representation 上的,你会 sample 一个噪声,这个噪声的 Dimension 跟这个 Latent Representation 的 Dimension 是一样的
你 sample 一些噪声出来加到 Latent Representation 上然后就稍微变一点,再 sample 一些噪声又再变一点,依此类推直到最后你加了够多的噪声,然后你的 Latent Representation 变成纯粹从噪声里面 sample 出来的样子

然后接下来呢你就要 train 一个 Noise Predicter,这个跟一般的 Diffusion Model 是完全一模一样的,加入噪声以后的 Representation 当作输入,那你也需要现在是第几个 step 当作输入,然后你也需要文字当作输入,那现在文字呢就是用 Latent Representation 也就是一排向量来表示
所以你就把这个加入 Noise 以后的 Latent Representation 跟文字的 Encoder 编码这段文字的结果跟现在是第几个 step 这三个东西一起丢到 Nise Predicter 里面希望它可以把 Noise 给 predict 出来
OK,然后今天在生图的时候你的做法就是你有一个纯粹从 Normal Distribution 里面 sample 出来的 Latent Representation,它的大小像是一个小图的样子,但是它是从 Normal Distribution 里面 sample 出来的,然后你把这个东西加上这段文字丢给一个 Denoise 的 Model,然后 Denoise 的 Model 就去掉一些 Noise,然后这个步骤就反复继续下去,直到你通过一定次数的 Denoise 之后产生出来的结果够好了丢给 Decoder 就可以生图了
那所以你会发现你在用 Midjourney 的时候它有一个生图的过程,从模糊慢慢到清楚,那如果是 Diffusion Model 的话你应该看到的是一开始完全 Random 的噪声,然后噪声慢慢越来越少越来越少,最后你的清晰的图才生成出来
但是其实你用 Midjourney 的时候它生图不是这个样子,你会发现说它的图是从一张模糊的图只看得出轮廓然后接下来越来越清楚越来越清楚,它其实是把这个 process 里面每一次产生出来的这些 Latent Representation 通过 Decoder 以后拿出来给你看,所以虽然这个东西是一个从 Gaussian Distribution sample 出来的东西但是你通过 Decoder 以后它看起来就是一张比较模糊的图,看起来就不像是由噪声加在上面,这就是为什么 Midjourney 它的中间产物其实也是人看得出来是什么东西的图。它就把这些中间产生出来的 Latent Representation 丢给 Decoder 然后再产生出来的结果给你看
OK,那这个就是今天 Stable Diffusion 的文字生图像的 Framework,就是三个步骤,文字的 Encoder,一个 image 的 Generation Model 生成个中间产物出来 Decoder 再做最后的处理,你会发现最好的图像生成模型基本上都是这样子的套路
OK,以上就是 Stable Diffusion Framework 的全部内容了
小结
Stable Diffusion 包括 Text Encoder、Generation Model 以及 Decoder 三个组件,其中 Text Encoder 可以用 BERT 或者 GPT 来处理文本得到向量,Decoder 则是利用 Generation Model 产生的中间产物来生成对应的图像,而 Generation Model 则是输入文字的 Representation 产生做一个中间产物图片压缩的结果,这个中间产物可以是一张小图,也可以说是 Latent Representation
总结
这里我们简单了解了图像生成模型,首先快速学习了一些图像生成模型像 VAE、Flow-based Model、Diffusion Model、GAN 等等,然后介绍了 Diffusion Model 的工作流程,先 random sample 一张噪声的图片然后不断通过 Denoise Model 去噪最终变成一张完整的图片,最后我们学习了 Stable Diffusion,它由 Text Encoder、Generation Model 以及 Decoder 三个部分组成,其中 Generation Model 的中间产物可以是小图或者 Latent Representation
OK,以上就是图像生成模型浅析的全部内容了😄
参考
- 机器学习2023(生成式AI)
- https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
- https://openai.com/research/image-gpt
- ML Lecture 18: Unsupervised Learning - Deep Generative Model (Part II)
- Flow-based Generative Model
- GAN Lecture 1 (2018): Introduction
- Autoencoding beyond pixels using a learned similarity metric
- Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models
- Diffusion-GAN: Training GANs with Diffusion
- Denoising Diffusion Probabilistic Models
- https://laion.ai/projects/
- https://rom1504.github.io/clip-retrieval/
- High-Resolution Image Synthesis with Latent Diffusion Models
- Hierarchical Text-Conditional Image Generation with CLIP Latents
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- https://imagen.research.google/
- GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
- Learning Transferable Visual Models From Natural Language Supervision