读天才与算法:人脑与AI的数学思维笔记03_AlphaGo
1. 国际象棋
1.1. 1997年计算机“深蓝”(Deep Blue)击败了顶尖国际象棋手,但机器取代数学研究机构还言之尚早
1.2. 下国际象棋与数学的形式化证明颇有相似之处,但学者认为中国围棋的思维方式更能够体现数学家思考的创造性和直觉力
1.3. 国际象棋与围棋相比,则是随着棋子一个个被吃掉,棋局变得越来越简单
1.4. 计算机科学家克劳德·香农(Claude Shannon)估计的国际象棋走法数量约为120位(称为香农数)
1.5. 国际象棋的行棋步骤以一种可控、有序的方式逐级建立分支,最终形成一个包含各种可能性的树状结构,计算机甚至人类都可以根据逻辑规则逐级分析不同分支的蕴含关系
1.6. 国际象棋更容易进行得分评价
1.6.1. 国际象棋是破坏性的,在行棋过程中,棋子会被一个个吃掉
1.6.2. 棋局会逐步简化
2. 围棋
2.1. 围棋很像数学,可以在相当简单的规则下形成精妙绝伦、错综复杂的推理
2.2. 据美国围棋协会(American Go Association)估计,围棋的可能走法数量是一个大约有300位的数字
2.3. 围棋就不是一种易于推算下一步行棋对策的游戏了,我们很难建立围棋行棋可能性的树状图
2.4. 围棋棋手推演下一步落子策略的过程似乎更依赖于自身的直觉判断
2.5. 围棋最重要的一点,是可以通过客观的方法检验新的行棋思路是否具有价值
2.6. 人类的大脑可以敏锐地捕捉到视觉图像所呈现出的结构和模式,所以围棋棋手可以通过观察棋子布局来推断棋势,然后得出下一步的应对策略
2.6.1. 人类大脑的视觉结构处理能力作为一种基本的生存技能,经过数百万年的进化已经变得高度发达
2.6.2. 任何动物的生存能力在一定程度上都取决于它在形态万千的自然界中对不同结构图像的识别能力
2.6.2.1. 原本平静的丛林之中激起的一丝混乱,极有可能预示着另一种动物的潜入
2.6.2.2. 这类敏感信息备受动物们的关注,因为它关系到自己会成为猎物还是猎食者,这就是大自然的生存法则
2.6.2.3. 人类的大脑非常擅长识别模式并预测它们的发展方向,同时做出适当的反应
2.7. 计算机程序学习下围棋非常困难的主要原因之一,因为到目前为止,还没有一种简单易行的方法可以建立起一套稳妥的系统,去评价对弈双方的领先状况
2.7.1. 围棋则不然,它是建设性的,行棋越多,棋盘上的棋子越多,棋局也越来越复杂
2.8. 对围棋下法的革新一直持续不断、屡见不鲜
2.8.1. 最近一次是围棋界的传奇人物吴清源大师于20世纪30年代开创的新棋法,他的布局之法颠覆了传统围棋布局的常用套路
2.8.2. AlphaGo可能会引发一场更大的围棋“革命”
2.8.2.1. 虽然人类已经发明围棋数千年了,但人工智能技术的出现让我们感觉到人类对围棋的理解仍然还很肤浅
2.9. 局部极大值
2.9.1. 围棋算法是陷入数学家们所说的“局部极大值”的困境当中的
2.9.2. 图
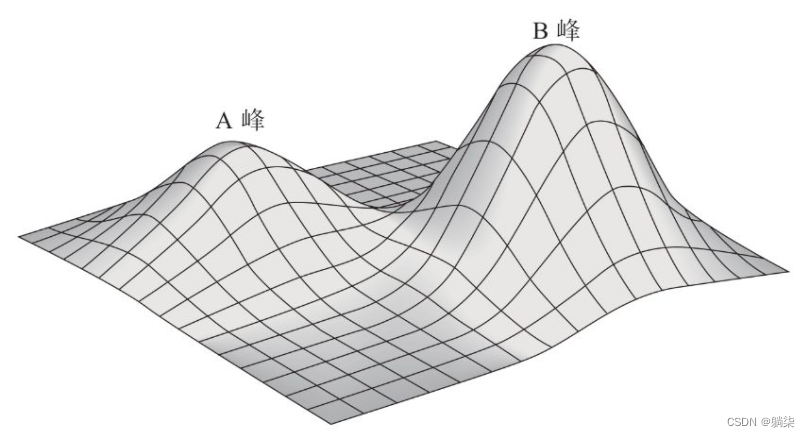
2.9.3. 在传统棋法的影响之下,围棋已发展出固有的一套成规,应用好这些规则的确能让棋手登上A峰
2.9.4. AlphaGo的出现拨开了迷雾,打破了这些规则对思维的束缚,使我们看到了更高的B峰
2.9.4.1. AlphaGo使用了一些新手都不会用的低级招式
2.9.4.2. 传统下法中棋手不会在三行三列交叉点上落子,但AlphaGo却向我们展示了如何利用好这一招并为整个棋局带来新的机遇
2.9.5. 围棋比赛的统计资料显示,使用传统下法的棋手通常会输给使用新下法的棋手两子
3. 戴密斯·哈萨比斯
3.1. Demis Hassabis
3.1.1. 虽然剑桥大学破格录取了他,但由于年龄太小,学校要求他晚一年入学
3.1.2. 课堂上教授却反复强调:“围棋极具创造性和直觉性,计算机永远下不好围棋。”
3.1.3. 当他从剑桥毕业时,他决心通过自己的努力来证明教授的言论是错误的
3.2. 与其编写一个会下围棋的程序,不如编写一个通用性的“元程序”,它可以用于编写出会下围棋的程序
3.3. 重点是“元程序”在实现以后将具有模式学习能力,随着经历的棋局越来越多,该程序会在下棋过程中自我学习,不断地从错误走法中总结经验并加以改进
3.4. 新生儿的大脑并没有预先设定应对生存挑战的方法,但他们会通过不断学习来强化自我,根据环境的变化做出适当的调整
3.4.1. 了解大脑的工作原理有助于实现自己创建一个会下围棋的计算机程序的梦想
3.5. 把人工智能算法比作哈勃望远镜,认为它是一种可以用来探索比以往更深、更远、更广领域的工具
3.5.1. 它会提升而不是取代人类的创造力
3.6. 考虑到未来的发展,哈萨比斯决定将公司卖给谷歌
3.6.1. 本来我们并不想这么做,但在过去3年里,为了筹措资金,我只有10%的时间用于研究。所以,我意识到,我的人生可能没有足够的时间,既能把公司发展成谷歌那样的规模,又可以在人工智能领域有所建树。这样的选择对我来说并不难
3.6.1.1. 哈萨比斯
3.6.2. 【躺柒】评:既要..也要..,最后很可能啥都没有;舍得,舍得,有舍才有得;在每天时间总量不变(1天24小时)或者人生时长有定数(神龟虽寿 犹有竟时)的情况下,就看如何分配了
4. DeepMind
4.1. 2010年9月,哈萨比斯与神经学家谢恩·莱格(Shane Legg)与穆斯塔法·苏莱曼(Mustafa Suleyman,哈萨比斯从小一起长大的好友)三人创建了公司,即DeepMind
4.1.1. 只有埃隆·马斯克(Elon Musk)、彼得·蒂尔(Peter Thiel)等极少数的投资人看好这家公司的前景并注入了资金
4.2. 在开始阶段选择了一个相对简单的目标:20世纪80年代的雅达利(Atari)游戏
4.2.1. 雅达利游戏的复杂性不可与古老的中国围棋同日而语
4.3. 打砖块游戏是一个完美的测试用例,可以检验DeepMind团队是否具备开发能够学会玩游戏的程序的能力
4.3.1. 该程序不会预先设定游戏规则,而是通过随机选择不同的“动作”(比如在打砖块游戏中移动球拍或是在Space Invaders游戏中发射激光炮射击外星人)不断试验,对相应的得分情况进行评估,分析其结果是有效提升还是止步不前
4.3.2. 该程序的实现基于20世纪90年代提出的强化学习(reinforcement learning)思想,目的在于根据分数的反馈或奖励函数来调整执行动作的概率
4.3.3. 新的算法将强化学习与神经网络相结合,后者将评估像素的状态以确定哪些特征与加分有直接关系
4.3.4. 程序在不断试验的过程中,可以真正学会通过特定的移动来提高它在游戏中的得分
4.3.5. 现在计算机程序不仅做到了,而且还做得更快、更好
4.4. 对他们而言,只针对一款游戏编写程序有些太简单了
4.4.1. 到了2014年,也就在DeepMind成立4年后,该项目在已经涉足的49款雅达利游戏的29款中获得了优于人类玩家的表现
4.5. 该团队在2015年初向《自然》杂志提交的论文中详细介绍了他们的研究成果
4.5.1. 在《自然》杂志上发表论文是科学家在科研事业上的重要里程碑,可DeepMind团队的论文不仅获得了极高的赞誉,还登上了杂志的封面
4.5.2. 这是人工智能发展史上的重要时刻。
4.5.2.1. 《华尔街日报》评论
4.6. DeepMind团队现在把目光投向了其他领域:医疗保健、气候变化、能源效率、语音的生成和识别、计算机视觉
5. AlphaGo
5.1. AlphaGo是戴密斯·哈萨比斯(Demis Hassabis)智慧的结晶
5.2. 唐纳德·米基
5.2.1. Donald Michie
5.2.2. 人工智能研究员
5.2.3. 20世纪60年代米基编写了一个名为“MENACE”的算法,该算法可以零基础学习玩井字棋游戏的最佳策略(MENACE代表导出〇和×策略的引擎)
5.3. 此前人们开发的下围棋程序,甚至很难与业余的优秀围棋选手相匹敌
5.3.1. Crazy Stone是唯一一款接近高水平棋手的围棋程序
5.4. 2015年10月,他们决定组织一场非公开的人机对弈来测试程序,对手是当时的欧洲冠军——来自中国的樊麾
5.4.1. 在世界围棋比赛中,欧洲顶级选手只能位列600名左右
5.4.2. 好比制造出一辆无人驾驶汽车然后在银石赛道上击败了人类选手驾驶的福特嘉年华,并不意味着它能在F1大奖赛中战胜刘易斯·汉密尔顿(Lewis Hamilton)
5.5. 在某些特定参数配置下,AlphaGo似乎完全无法评估出到底是谁掌控了比赛,常常会产生一种错觉,以为自己赢了,而实际情况却恰恰相反
5.6. 对于一般的基于开放式数据库的程序来说,不按套路出牌的策略非常管用
5.6.1. 不仅可以使机器手足无措,还可能误导机器在棋局的重要关口或是长远战略决策上犯下致命错误
5.6.2. 遇到AlphaGo,这个如意算盘可就打空了
5.6.2.1. AlphaGo可以实时动态评估棋局形势,并根据以前的经验制定出最佳策略
5.7. 带来希望,是因为正是人类的这种情绪反应激励着我们去探索未知、开创未来,毕竟还是人类给AlphaGo编写了制胜的代码
5.7.1. 感到忧心,是因为机器太过“冷漠”,它根本就不关心事情发展的最终结局是不是程序编写者所期望的
5.8. 从表面上看,AlphaGo所能做的仅仅是下围棋,但实际上,它的学习和适应能力才是最值得人类关注的一种全新的东西
5.8.1. 登月并没有产生关于宇宙的非凡的新突破,但却意味着我们为实现这一壮举而开发的技术产生了非凡的新突破
5.9. 真正的洞察力源于对棋局的综合把控
5.9.1. 这些棋类游戏现在已经成为挖掘新思想的宝库
6. 李世石九段对阵谷歌AlphaGo五番棋赛
6.1. 在酒店内的比赛现场却是封闭和保密的
6.1.1. 媒体和现场观众的任何行为都不会让AlphaGo分心,因为机器无论在什么状态下,都会保持“禅宗大师”一般的定力,呈现出一种完美的专注状态
6.2. 第一局
6.2.1. 第一局比赛中AlphaGo所走的每一步棋还是符合人类逻辑思维的,现场的专家也能够讲解和分析棋局
6.2.2. 李世石执黑先行,作为白方的DeepMind团队由其成员黄士杰(Aja Huang)代替AlphaGo行棋
6.2.2.1. 毕竟AlphaGo只是人工智能程序而不是能够自己下棋的机器人
6.3. 第二局
6.3.1. AlphaGo下出第37手:黄士杰在距离棋盘边缘5步的位置落下一颗黑子
6.3.1.1. 这一招使得包括李世石在内的所有人都倍感震惊
6.3.1.2. 在第5条线上落子一般被认为是不太恰当的选择
6.3.1.2.1. 因为这会给对手可乘之机:建立一个既可在短效、局部区域内抢得先手,又可在长远、全局范围内影响胜负的策略
6.3.1.3. 这确实不是人类的行棋方法
6.3.1.4. 这一着非但不是臭棋,反而是立意深远的妙手
6.4. 第三局
6.4.1. 怠惰走法(lazy moves)的策略
6.4.1.1. 通过分析,AlphaGo确信自己最终可以获胜,正因为如此,它选择了这种安全的策略
6.5. 第四局
6.5.1. 李世石采用了一种更为激进、极端的“先捞后洗”(amashi)的策略
6.5.2. “胜负手”(all-or-nothing)策略可能会让AlphaGo更难轻易得分
6.5.3. 当AlphaGo的棋路开始变得保守,频频使用怠惰走法时,就标志着AlphaGo已经确认自己领先了
6.5.4. 第78手就是李世石的逆袭大招
6.5.4.1. 当AlphaGo意识到自己失败后,会做出一些令人费解的疯狂行为
6.5.4.2. AlphaGo的行为没有通过图灵测试,因为任何一个具有战略眼光的人都不会做出那样的决策
6.5.4.3. 这一步棋打破了传统棋路,是为整局比赛带来深远影响的关键所在
6.5.4.3.1. ‘上帝之手’
6.5.4.4. AlphaGo与人类对弈的历史经验让它完全摒弃了某些思考
6.5.4.4.1. 根据它的评估,那种下法只有万分之一的可能性会出现
6.6. 第五局
6.6.1. 经过第四局,AlphaGo也收获颇丰
6.6.1.1. 现在就算李世石在第10 000手下出违反常规的怪招,它也不会再想着侥幸过关了
6.7. 李世石认为不只机器可以学习和进化,人也可以从失败中学到一些东西
6.7.1. 与一群职业棋手分析和探讨此前两场比赛中失利的原因,这场讨论一直持续到次日清晨6点
6.8. 算法的强大之处:从错误中吸取教训,进而反败为胜
6.8.1. 并不意味着AlphaGo不会再犯新的错误
7. 向人类宣战
7.1. 我们在持续重构世界秩序,直觉始终被尊崇。
7.1.1. 保罗·克利(Paul Klee)
7.2. 只在局部环境中按部就班地进行逻辑分析走不了太远,必须与发现“可能存在物”的直觉相结合才有可能取得显著的突破
7.2.1. 有些数学猜想虽然未得到证明,但提出猜想的数学家经常能感觉到在他的论述中暗含着某种真理
7.2.2. 善于提出好的猜想的数学家比善于证明猜想的数学家更值得尊敬
7.2.3. 束缚我们认知的障壁,会在计算机技术日新月异的发展中被瞬间攻破
7.3. 一些在诞生之初就受到指摘的事物,往往经历几代人才会逐渐被接受并被视为具有革命性的创新
7.3.1. 并不被19世纪的人们所认可或知晓的贝多芬的交响乐,现在被誉为艺术的巅峰
7.3.2. 凡·高的一生中,几乎没有售出过画作,它们只能用来交换食物或绘画材料,但现在他的大作却可以卖出数百万美元的高价
7.4. 当我们得知再怎么努力也只能成为屈居于机器之后的第二梯队棋手时,确实会意志消沉
7.4.1. 虽然机器的程序还是人编写的,但这也不会让人有挽回颜面的感觉
7.5. DeepMind团队将要开发出来的程序居然有可能让数学家丢掉饭碗,而创造这些程序的工具正是数学家们历经几个世纪的不懈努力才发现和创造出来的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/313112.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!