1、局部变量和静态变量的区别
-
普通局部变量和静态局部变量区别
-
-
存储位置:
-
-
-
-
普通局部变量存储在栈上
-
静态局部变量存储在静态存储区
-
-
-
-
生命周期:
-
-
-
-
当函数执行完毕时,普通局部变量会被销毁
-
静态局部变量的生命周期则是整个程序运行期间,即使函数调用结束,静态局部变量的值也会被保留
-
-
-
-
初始值:
-
-
-
-
普通局部变量在每次函数调用时都会被初始化,它们的初始值是不确定的,除非显式地进行初始化
-
静态局部变量在第一次函数调用时会被初始化,然后保持其值不变,直到程序结束
-
-
-
#include <stdio.h> void normal_func() {int i = 0;i++;printf("局部变量 i = %d\n", i); } void static_func() {static int j = 0;j++;printf("static局部变量 j = %d\n", j); } int main() {// 调用3次normal_func()normal_func();normal_func();normal_func(); // 调用3次static_func()static_func();static_func();static_func(); return 0; } -
运行结果:
-
局部变量 i = 1 局部变量 i = 1 局部变量 i = 1 static局部变量 j = 1 static局部变量 j = 2 static局部变量 j = 3
2、预处理
-
C语言对源程序处理的四个步骤:预处理、编译、汇编、链接。
-
预处理
-
-
宏定义展开、头文件展开、条件编译,这里并不会检查语法
-
-
编译
-
-
检查语法,将预处理后文件编译生成汇编文件
-
-
汇编
-
-
将汇编文件生成目标文件(二进制文件)
-
-
链接
-
-
将目标文件链接为可执行程序
-
gcc -E hello.c -o hello.i //处理文件包含,宏和注释 gcc -S hello.i -o hello.s //编译为汇编文件 gcc -c hello.s -o hello.o //经汇编后为二进制的机器指令 gcc hello.o -o hello //链接所用的到库 1 预处理:预处理相当于根据预处理命令组装成新的 C 程序,不过常以 i 为扩展 名。 2 编 译:将得到的 i 文件翻译成汇编代码 .s 文件。 3 汇 编:将汇编文件翻译成机器指令,并打包成可重定位目标程序的 O 文件。 该文件是二进制文件,字节编码是机器指令。 4 链 接:将引用的其他 O 文件并入到我们程序所在的 o 文件中,处理得到最终 的可执行文件
-
-
C编译器提供的预处理功能主要包括:
-
文件包含 #include
-
宏定义 #define
-
条件编译 #if #endif ……
-
3、文件包含处理
-
文件包含处理
-
指一个源文件可以将另外一个文件的全部内容包含进来
-
C语言提供了#include命令用来实现文件包含的操作
-
-
#include< > 与 #include ""的区别
-
<> 表示系统直接按系统指定的目录检索
-
"" 表示系统先在 "" 指定的路径(没写路径代表当前路径)查找头文件,如果找不到,再按系统指定的目录检索
-
4、宏定义
-
在预编译时将宏名替换成字符串的过程称为"宏展开"(也叫宏替换)。
-
宏名一般用大写,以便于与变量区别
-
宏定义不作语法检查,只有在编译被宏展开后的源程序才会报错
-
宏定不要不要行末加分号
-
#define PI 3.14
#define MAX(a, b) ((a) > (b) ? (a) : (b))
#define FUNC(a) func(a)
void func(int a) {int b = a;
}
int main() {double a = PI;int temp = MAX(1, 2+3);FUNC(10);
return 0;
}
5、条件编译
一般情况下,源程序中所有的行都参加编译。但有时希望对部分源程序行只在满足一定条件时才编译,即对这部分源程序行指定编译条件。
防止头文件被重复包含
#ifndef _SOMEFILE_H #define _SOMEFILE_H //需要声明的变量、函数 //宏定义 //结构体 #endif
软件裁剪
同样的C源代码,条件选项不同可以编译出不同的可执行程序:
#include <stdio.h>
// #define A 有注释,没有注释,观察运行结果
#define A
int main() {
#ifdef Aprintf("这是大写操作\n");
#elseprintf("这是小写操作\n");
#endif
return 0;
}
6、递归
-
函数递归调用:
-
函数可以调用函数本身(不要用main()调用main(),不是不能这么做,而是不建议,往往得不到你想要的结果)。
-
-
递归的优点
-
递归给某些编程问题提供了最简单的方法。
-
-
递归的缺点
-
一个有缺陷的递归会很快耗尽计算机的资源,递归的程序难以理解和维护
-
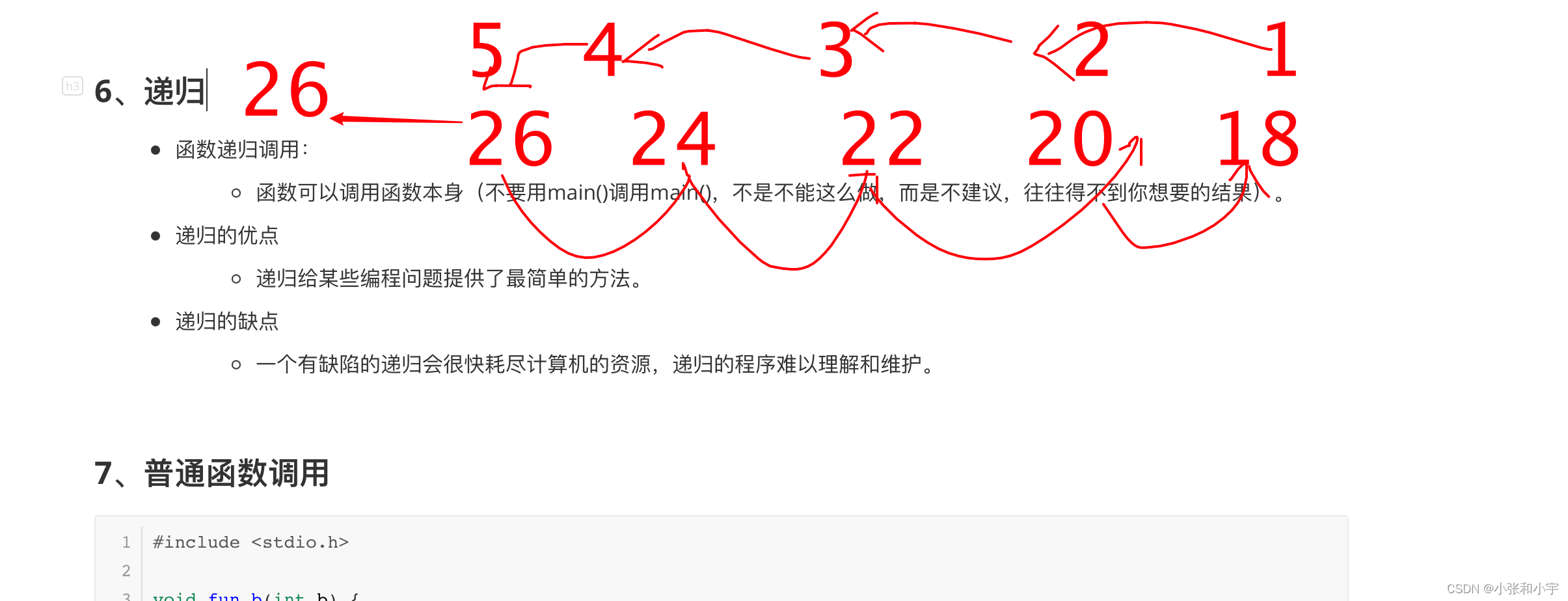
7、普通函数调用
#include <stdio.h>
void fun_b(int b) {printf("b = %d\n", b);
return;
}
void func_a(int a) {fun_b(a - 1);
printf("a = %d\n", a);
}
int main(void) {func_a(2);printf("main\n");
return 0;
}
运行顺序:
-
结论:
-
先调用,后返回(栈结构)
-
调用谁,返回谁的位置

-
运行结果:
b = 1 a = 2 main
8、函数递归调用
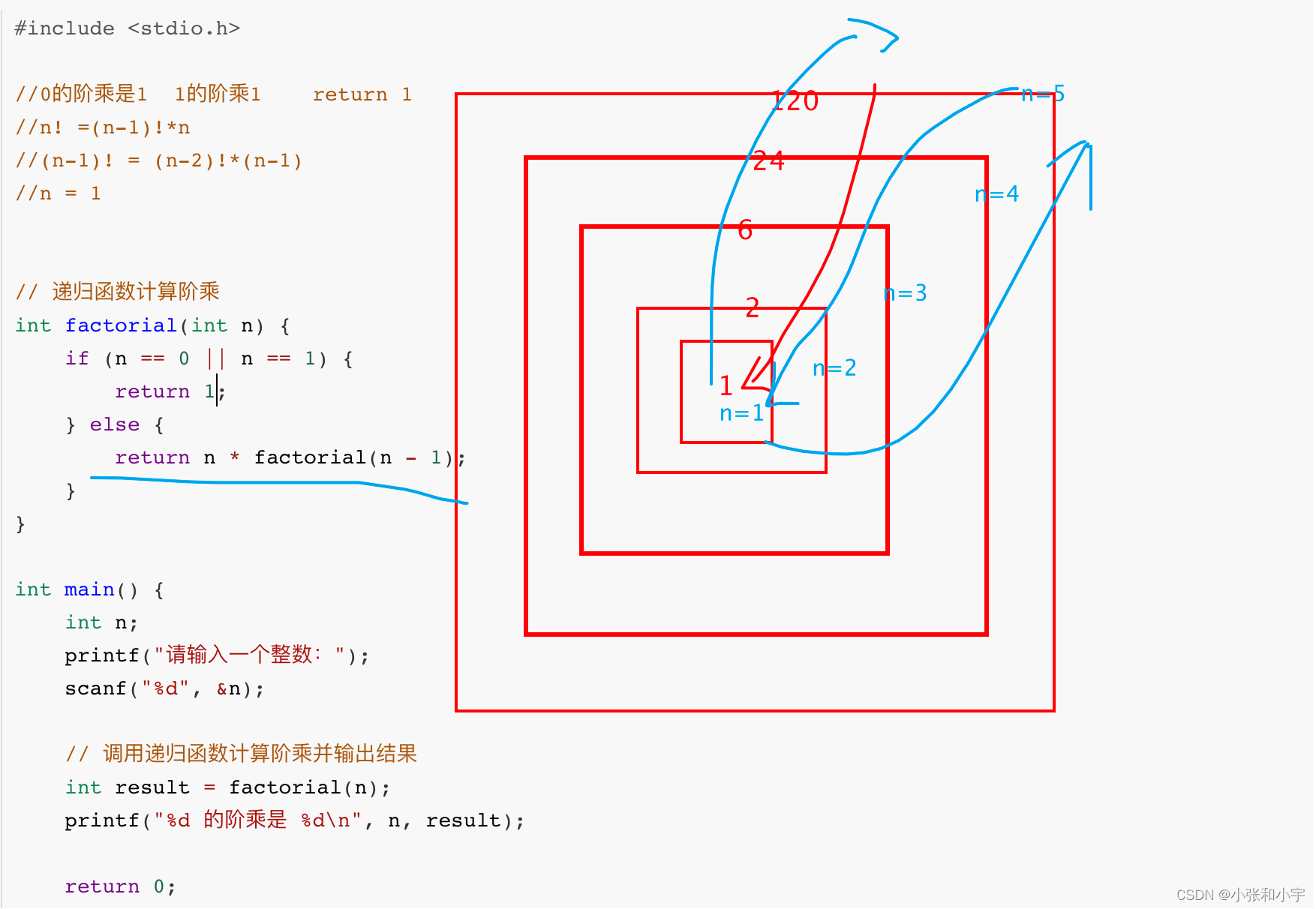
#include <stdio.h>
//0的阶乘是1 1的阶乘1 return 1
//n! =(n-1)!*n
//(n-1)! = (n-2)!*(n-1)
//n = 1
// 递归函数计算阶乘
int factorial(int n) {if (n == 0 || n == 1) {return 1;} else {return n * factorial(n - 1);}
}
int main() {int n;printf("请输入一个整数:");scanf("%d", &n);
// 调用递归函数计算阶乘并输出结果int result = factorial(n);printf("%d 的阶乘是 %d\n", n, result);
return 0;
}
运行顺序:
9、大小端验证
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;所谓的小端模式,是指数据的低位保存在内存的低地址中,而数 据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。 1)大端模式: 低地址 -----------------> 高地址 0x12 | 0x34 | 0x56 | 0x78 2)小端模式: 低地址 ------------------> 高地址 0x78 | 0x56 | 0x34 | 0x12
#include <stdio.h>
#include <stdint.h>
int check_endianness() {uint32_t temp = 0x44332211; // 4个字节,32位uint8_t * p = NULL; // 8位
p = (uint8_t *)&temp; // 只取uint8_t的长度printf("%#x\n", *p);printf("%#x\n", p[0]); // *p 和 p[0]等价
uint16_t * p1 = (uint16_t *)&temp; printf("*p1 = %#x\n", *p1);
if (*p == 0x11 ) {return 0; // 0是小端} else {return 1; // 大端}
}
int main() {int res = check_endianness();if (res == 0) {printf("小端\n");} else {printf("大端\n");}
return 0;
}
10、大小端转换
#include <stdio.h>
int changeBigEndian(int data) {
return (data >> 24 & 0x000000ff) |(data >> 8 & 0x0000ff00) |(data << 8 & 0x00ff0000) |(data << 24 & 0xff000000);
}
int main() {
int mem = 0x44332211;
printf("%0x\n", changeBigEndian(mem));return 0;
}
11、二分查找
#include <stdio.h>
// 二分查找函数
int binarySearch(int arr[], int size, int target) {int left = 0;int right = size - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] == target) {return mid; // 找到目标元素,返回索引} else if (arr[mid] < target) {left = mid + 1; // 在右半部分继续查找} else {right = mid - 1; // 在左半部分继续查找}}return -1; // 目标元素不存在,返回-1
}
int main() {int arr[] = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19};int size = sizeof(arr) / sizeof(arr[0]);int target = 11;int index = binarySearch(arr, size, target);if (index != -1) {printf("目标元素 %d 在数组中的索引为 %d\n", target, index);} else {printf("目标元素 %d 不在数组中\n", target);}return 0;
}
12、什么是指针,在什么地方使用的
指针(Pointer)是一种特殊的变量类型,它用于存储内存地址。指针的实质就是内存“地址”。 使用范围: 动态内存分配:指针常用于动态分配内存,例如使用 malloc()、calloc() 或 new 分配内存,并使用指针来管理和访问分配的内存块。 数组和字符串:数组名本身就是指向数组第一个元素的指针,在函数参数传递、数组访问等场景中经常用到指针。 函数指针:函数指针是指向函数的指针变量,可以用来在运行时动态确定调用的函数,或者将函数作为参数传递给其他函数。 ……
13、函数指针是什么
函数指针是指向函数的指针变量,它存储了函数的地址,可以用来调用该函数。在 C 语言中,函数名可以视为函数在内存中的地址,因此可以将函数名赋值给函数指针变量,从而实现通过函数指针来调用函数。
#include <stdio.h>
int getData(int a, int b) {return a + b;
}
int main() {
int(*func)(int, int);
func = getData;printf("%d\n", func(5, 8));
return 0;
}
复议:指针函数
-
指针函数是一个返回指针的函数。它的返回值是一个指针,指向某种数据类型的内存地址。
-
指针函数通常用于动态内存分配、返回数组、返回字符串等场景。
int* create_array(int size) {int* arr = malloc(size * sizeof(int)); // 动态分配内存return arr;
}
14、声明和定义的区别
-
声明告诉编译器,某个名称(如变量、函数、类等)存在,但不分配内存空间或提供实现细节。
-
声明通常包括名称和类型信息,以及可能的参数列表。
-
声明可以出现在函数或变量的定义之前,以便在使用之前提供有关名称的信息。
int add(int a, int b);
-
定义不仅声明了名称的存在,还为其分配了内存空间或提供了实现细节。
-
对于变量,定义会分配内存空间;对于函数,定义会提供函数体的实现。
-
每个定义都是一个声明,但不是每个声明都是一个定义。
// 函数定义
int add(int a, int b) {return a + b;
}
15、extern关键字是干什么用
用来修饰全局变量,全局变量本身是全局可用的,但是由于文件是单个完成编译,并且编译是自上而下的,所以说,对于不是在本范围内定义的全局变量,要想使用必须用 extern 进行声明,如果不加上 extern ,就会造成重定义。
注意,经 extern 声明的变量,不可以再初始化。
16、位运算
#include <stdio.h>
#include <inttypes.h>
int main() {// 将变量a的第2位设置为1,其他位保持不变uint8_t a = 0b10110011; // 0xb3;a |= (1 << 2); // 或者 x = x | (1 << 2);printf("%02x\n", a); // b7, 10110111
// 将变量b的第2位、第6位设置为1,其他位保持不变uint8_t b = 0b10110011; // 0xb3;b |= (1 << 2 | 1 << 6);printf("%02x\n", b); // f7,11110111
// 将变量c的第5位设置为0,其他位保持不变uint8_t c = 0b10110011; // 0xb3;c &= ~(1 << 5);printf("%02x\n", c); // 93,10010011
// 将变量d的第0~3位设置为0,其他位保持不变uint8_t d = 0b11111111; // 0xff;d &= ~(1 << 0 | 1 << 1 | 1 << 2 | 1 << 3);printf("%02x\n", d); // f0,11110000
// 将变量e的第2位取反,其他位保持不变uint8_t e = 0b10110011; // 0xb3;e ^= (1 << 2);printf("%02x\n", e); // b7, 10110111
return 0;
}
17、说说什么是野指针,怎么产生的,如何避免
野指针是指向"垃圾"内存的指针,也就是说,它的值是不确定的。野指针通常由以下几种情况产生: 未初始化的指针:如果你声明了一个指针变量但没有给它赋值,那么它就是一个野指针。例如:int *ptr;。 已删除的指针:如果你使用delete或free删除了一个指针,但没有将它设置为NULL,那么它就成了一个野指针。例如: 超出作用域的指针:如果你返回了一个函数内部的局部变量的地址,那么这个地址在函数返回后就不再有效,因此返回的指针就是一个野指针。 初始化: ptr = NULL;
18、堆和栈有什么区别?
- 栈区(stack) - - 栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。 - 堆区(heap) - - 堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。