今天,向大家介绍一篇在知识图谱嵌入领域具有重要意义的研究论文——Editing Language Model-based Knowledge Graph Embeddings。这项工作由浙江大学和腾讯公司的研究人员联合完成,为我们在动态更新知识图谱嵌入方面提供了新的视角和方法。
研究背景
在当今的人工智能领域,知识图谱作为一种丰富的结构化知识库,对于驱动智能应用如搜索引擎、推荐系统和问答机器人等发挥着至关重要的作用。它通过将现实世界中的实体和关系映射为图谱中的节点和边,为机器提供了一种强有力的知识表示方式。
然而,随着时间的推移和社会的演进,知识图谱面临着一个显著挑战:如何有效地应对知识更新的需求?在现实世界中,新的实体不断出现,实体间的关系也会发生变化,这就要求我们的知识图谱能够灵活地反映这些动态变化。
传统的知识图谱嵌入方法,如TransE或RotatE,通常在模型部署后难以进行更新。当知识图谱更新时,这些方法往往需要重新训练整个模型,这不仅耗时,而且计算成本高昂。此外,随着预训练语言模型的兴起,基于这些模型的KG嵌入方法虽然在表示能力上取得了进步,但在知识更新的灵活性上仍然存在局限。
因此,如何设计出一种机制,使得基于语言模型的知识图谱嵌入能够在不重新训练整个模型的情况下,快速适应知识的更新,成为了一个亟待解决的问题。这正是本论文所要探讨的核心议题。
研究方法
为了实现这一目标,论文提出了以下几个关键的研究方法:
研究任务的创新定义
作者们首先定义了两个关键的研究任务:EDIT和ADD。这两个任务分别针对知识图谱嵌入中的错误知识修正和新知识添加。EDIT任务关注于如何准确地纠正KG嵌入中已经存在的错误知识,而ADD任务则着眼于如何将新出现的知识有效地整合进已有的KG嵌入中。这两个任务的提出,为动态更新KG嵌入提供了明确的目标和方向。
数据集的精心构建
为了全面评估所提出方法的性能,作者们构建了四个新的数据集,这些数据集基于两个广泛使用的知识图谱:FB15k237和WN18RR。这些数据集经过精心设计,包含了需要编辑或添加的知识,为实验提供了标准化的测试平台。通过这些数据集,研究者能够系统地评估模型在编辑和添加知识时的准确性、效率和对现有知识的保护。
KGEditor模型的创新设计
KGEditor模型是这篇论文的核心贡献之一,它是一个利用超网络(Hypernetwork)来动态编辑KG嵌入的框架。KGEditor的核心思想是通过在超网络中学习额外的参数层,对KG嵌入的实体和关系表示进行精确的调整,而无需重新训练整个模型。
超网络结构的巧妙应用
超网络在KGEditor中扮演着至关重要的角色。它通过学习输入知识的特定模式,生成额外的参数层,这些参数层随后被用来调整KG嵌入中的实体和关系表示。这种方法不仅能够实现对特定知识的快速更新,而且能够保持对其他知识的最小干扰。
编辑知识的效率和效果
KGEditor模型在参数数量和计算时间上均优于现有的基线方法,这表明它在知识编辑上具有更高的效率。此外,通过一系列实验,作者们证明了KGEditor在保持知识局部性的同时进行知识更新方面表现出色,这意味着KGEditor能够在不破坏其他知识表示的前提下,有效地编辑特定的知识。
评估指标的全面设计
为了全面评估编辑操作的效果,作者们设计了一套评估指标,包括知识可靠性(Knowledge Reliability)、知识局部性(Knowledge Locality)和知识效率(Knowledge Efficiency)。这些指标从不同角度衡量了编辑操作的质量和效率,为比较不同编辑方法提供了科学的依据。
实验结果
实验结果表明,KGEditor在多个评估指标上均优于现有技术,特别是在保持知识局部性的同时进行知识更新方面表现出色。此外,KGEditor在参数数量和计算效率上也具有明显优势。
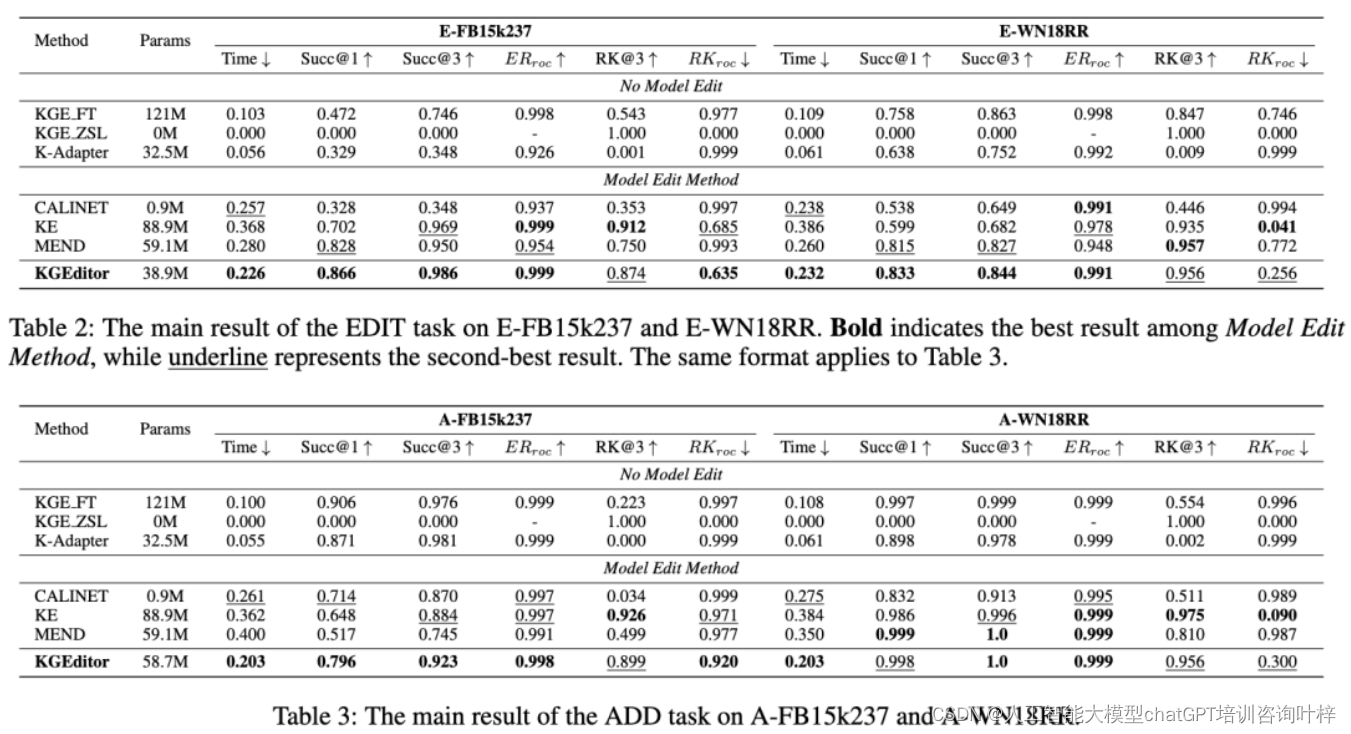
知识可靠性的验证
作者们首先评估了KGEditor在EDIT和ADD任务上的知识可靠性。通过计算Success@1指标,即在所有需要编辑的三元组中,KGEditor能够准确预测正确实体的比例,实验结果显示KGEditor在两个任务上都取得了高成功率。这意味着KGEditor能够有效地修正错误知识(EDIT任务)和整合新知识(ADD任务)。
知识局部性的考察
接下来,作者们考察了KGEditor在编辑操作中的知识局部性。通过计算Retain Knowledge (RK@k)指标,即在模型编辑后,原有正确知识被保留的比例,实验结果表明KGEditor在编辑特定知识时,对其他知识的影响很小。这验证了KGEditor在进行知识编辑时,能够保持对其他知识的最小干扰,体现了良好的知识局部性。
知识编辑效率的评估
在知识编辑效率方面,作者们比较了KGEditor和其他基线方法在参数数量和计算时间上的差异。实验结果表明,KGEditor在参数数量上更为精简,在计算时间上也更短。这表明KGEditor在知识编辑上具有更高的效率,能够在更短的时间内,用更少的计算资源完成知识更新。
模型扩展性的探索
此外,作者们还探讨了编辑多个知识点对KGEditor性能的影响。通过逐步增加需要编辑的三元组数量,作者们评估了KGEditor处理更复杂编辑任务的能力。实验结果显示,KGEditor能够稳定地处理一定数量的编辑操作,而不会显著降低模型性能。这验证了KGEditor在处理更大规模知识编辑任务时的扩展性。
实验的深入分析
在实验分析部分,作者们还深入探讨了影响KGEditor性能的多个因素:
-
编辑操作的数量: 实验结果表明,KGEditor能够稳定地处理一定数量的编辑操作,但当编辑操作的数量超过一定阈值时,模型性能会有所下降。这提示我们在实际应用中需要合理控制单次编辑操作的数量。
-
不同KGEmbedding初始化方法: 论文还比较了不同的KGEmbedding初始化方法(如FT-KGE和PT-KGE)对KGEditor性能的影响。结果表明,基于提示(prompt-based)的模型更适合于编辑任务,这可能是因为提示能够更有效地利用语言模型的知识表示能力。
-
实体和关系的复杂性: 对于涉及多对多关系和复杂知识的编辑操作,KGEditor展现了一定的鲁棒性,但仍有改进空间。这提示我们在设计KGEditor时,需要考虑如何处理更复杂的知识关系。
这项研究为知识图谱嵌入的动态更新提供了一种有效的解决方案,对于促进知识的动态更新和维护具有重要意义。未来的研究可以在此基础上进一步探索,例如处理更复杂的知识关系,或者将这种编辑技术应用到更大规模的语言模型中。
建议大家去看看原论文:
论文作者:程思源(浙江大学)、张宁豫(浙江大学)、田博中(浙江大学)、陈曦(腾讯)、刘庆斌(腾讯)、陈华钧(浙江大学)
发表会议:AAAI 2024
论文链接:https://arxiv.org/abs/2301.10405
代码链接:https://github.com/zjunlp/PromptKG/tree/main/deltaKG
Demo链接:https://huggingface.co/spaces/zjunlp/KGEditor