1、命名实体识别介绍
1.1 简介
命名实体识别(NER)是自然语言处理(NLP)中的一项关键技术,它的目标是从文本中识别出具有特定意义或指代性强的实体,并对这些实体进行分类。这些实体通常包括人名、地名、组织机构名、日期、时间、专有名词等。NER在许多实际应用中都非常重要,如信息提取、文本挖掘、机器翻译、自动摘要等。
NER的任务主要分为两部分:
- 实体的边界识别:这部分任务是要确定文本中实体的起始和结束位置,即在文本中准确地定位出实体的边界。
- 确定实体的类型:在识别出实体的边界之后,还需要确定每个实体的具体类型,如人名、地名、机构名等。
例如,在处理文本“马云在杭州创建了阿里巴巴”时,NER系统需要识别出“阿里巴巴”是一个组织机构名,“马云”是一个人名,“杭州”是一个地名。
NER的技术实现通常涉及机器学习、深度学习等方法,通过训练模型来识别和分类文本中的实体。随着深度学习技术的发展,NER的准确率和效率有了显著提高,成为NLP领域研究和应用的热点之一。我们今天使用transformers库来实现一下。
1.2 标注方法
序列标注的方法中有多种标注方式:BIO、BIOSE、IOB、BILOU、BMEWO,其中前三种最为常见。
-
BIO:标识实体的开始,中间部分和非实体部分
- b代表“开始”(表示命名实体的开始,即NE)
- I代表“内部”(表示该词在NE内部)
- o代表‘outside’(表示这个单词只是一个NE之外的普通单词)
-
BIOSE:增加S单个实体情况的标注和增加E实体的结束标识
- b代表“开始”(表示一个NE的开始)
- I代表“内部”(表示该词在NE内部)
- o代表‘outside’(表示这个单词只是一个NE之外的普通单词)
- e代表‘end’(表示这个词是一个NE的结尾)
- s代表“singleton”(表示单个单词是一个NE)
-
IOB (即IOB-1):三位序列标注法(B-begin,I-inside,O-outside),IOB与BIO字母对应的含义相同,其不同点是IOB中,标签B仅用于两个连续的同类型命名实体的边界区分,不用于命名实体的起始位置,这里举个例子:
-
词序列:(word)(word)(word)(word)(word)(word)
IOB标注:(I-loc)(I-loc)(B-loc)(I-loc)(o)(o)
BIO标注:(B-loc)(I-loc)(B-loc)(I-loc)(o)(o)
在命名实体识别(NER)中,BIO和IOB都使用B、I、O三种标签来标注实体,但是它们在使用B标签的方式上有所不同。
在BIO标注方法中,B标签用于表示一个实体的开始,I标签用于表示实体的内部,而O标签用于表示非实体词。每个实体都由一个B标签开始,后面跟着零个或多个I标签。
IOB标注方法与BIO类似,但是在IOB中,B标签有特殊的用途。它仅用于标记两个连续的同类型命名实体的边界,而不是用于标记一个实体的开始。这意味着,如果一个实体紧接着另一个同类型的实体,那么第二个实体不会以B标签开始,而是以I标签开始。
在这个例子中,前两个词是同一个实体的组成部分,因此在IOB标注中,它们都以I-loc开始。当遇到一个新的同类型实体时,使用B-loc来标记它们的边界。而在BIO标注中,每个实体的开始都使用B标签。
总的来说,IOB和BIO的主要区别在于如何处理连续的命名实体。IOB在处理这种情况时更加精细,但是在实际应用中,BIO因为其简单性和直观性而被更广泛地使用。 -
因为IOB的整体效果不好,所以出现了IOB-2,约定了所有命名实体均以B tag开头。这样IOB-2就与BIO的标注方式等价了。
- I表示实体内部
- B表示实体开始
- O表示实体外部
-
标记 说明 B-Person 人名开始 I- Person 人名中间 B-Organization 组织名开始 I-Organization 组织名中间 O 非命名实体
-
1.3 评价指标
-
精准率:度量模型的精确度/准确度。 它是正确识别的正值(真正)与所有识别出的正值之间的比率。 精准率指标显示正确标记的预测实体的数量。
Precision = #True_Positive / (#True_Positive + #False_Positive) -
召回率:度量模型预测实际正类的能力。 这是预测的真正值与实际标记的结果之间的比率。 召回率指标显示正确的预测实体的数量。
Recall = #True_Positive / (#True_Positive + #False_Negatives) -
F1 分数:F1 分数是精准率和召回率的函数。 在精准率和召回率之间进行平衡时,需要用到它。
F1 Score = 2 * Precision * Recall / (Precision + Recall)
举例说明
| 词组 | Gold标签 | Predict标签 |
|---|---|---|
| 马 | B-PER | B-PER |
| 云 | I-PER | I-PER |
| 在 | O | O |
| 杭 | B-LOC | B-LOC |
| 州 | I-LOC | I-LOC |
| 创 | O | O |
| 建 | O | O |
| 了 | O | O |
| 阿 | B-ORG | B-ORG |
| 里 | I-ORG | I-ORG |
| 巴 | I-ORG | O |
| 巴 | I-ORG | O |
例子中一共有三个实体,
- 预测了三个实体,预测对了2个,所以精准率= 2 3 \frac{2}{3} 32
- 样本中实际游3个实体,预测对了2个,召回率= 2 3 \frac{2}{3} 32
- F1 Score = 2 * Precision * Recall / (Precision + Recall) = 2* 2 3 \frac{2}{3} 32* 2 3 \frac{2}{3} 32/( 2 3 \frac{2}{3} 32+ 2 3 \frac{2}{3} 32) = 2 3 \frac{2}{3} 32
2 实战
基本步骤:
2.1 加载数据集
打开hugging face,
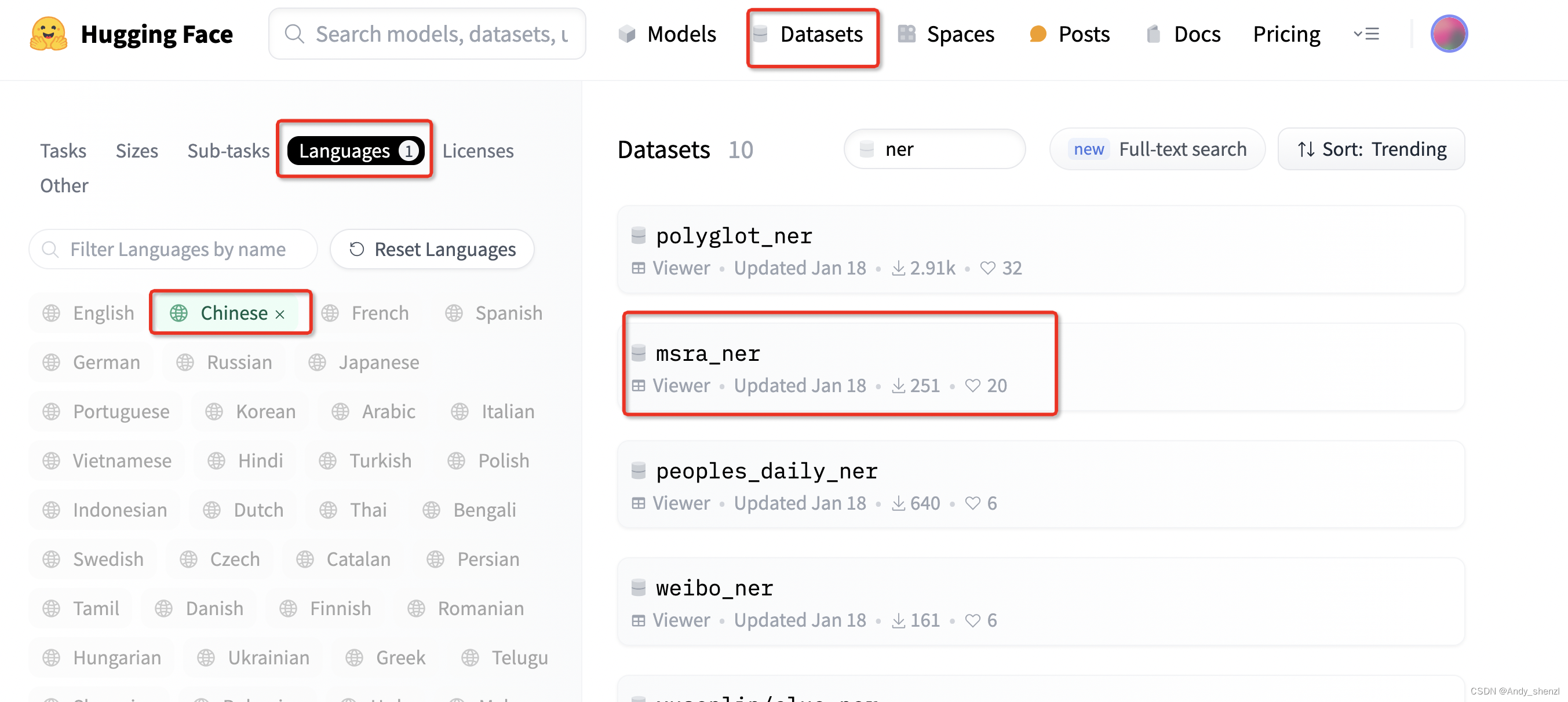
我们这里使用msra_ner数据集
ner_datasets = load_dataset("msra_ner", cache_dir="./data")
ner_datasets
DatasetDict({train: Dataset({features: ['id', 'tokens', 'ner_tags'],num_rows: 45001})test: Dataset({features: ['id', 'tokens', 'ner_tags'],num_rows: 3443})
})查看数据
print(ner_datasets["train"][0])
{'id': '0', 'tokens': ['当', '希', '望', '工', '程', '救', '助', '的', '百', '万', '儿', '童', '成', '长', '起', '来', ',', '科', '教', '兴', '国', '蔚', '然', '成', '风', '时', ',', '今', '天', '有', '收', '藏', '价', '值', '的', '书', '你', '没', '买', ',', '明', '日', '就', '叫', '你', '悔', '不', '当', '初', '!'], 'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
这个数据集的第一条好像没有被标注,我们来看下,这个数据集的标注类型
ner_datasets["train"].features
{'id': Value(dtype='string', id=None),'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),'ner_tags': Sequence(feature=ClassLabel(names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC'], id=None), length=-1, id=None)}label_list = ner_datasets["train"].features["ner_tags"].feature.names
label_list
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
这个是IOB-2类型
2.2 数据预处理
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
tokenizer(ner_datasets["train"][0]["tokens"], is_split_into_words=True) {'input_ids': [101, 2496, 2361, 3307, 2339, 4923, 3131, 1221, 4638, 4636, 674, 1036, 4997, 2768, 7270, 6629, 3341, 8024, 4906, 3136, 1069, 1744, 5917, 4197, 2768, 7599, 3198, 8024, 791, 1921, 3300, 3119, 5966, 817, 966, 4638, 741, 872, 3766, 743, 8024, 3209, 3189, 2218, 1373, 872, 2637, 679, 2496, 1159, 8013, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
前面我们查看数据时,看到数据其实已经分词了, 对于已经做好tokenize的数据,要指定is_split_into_words参数为True
# 借助word_ids 实现标签映射
def process_function(examples):tokenized_exmaples = tokenizer(examples["tokens"], max_length=128, truncation=True, is_split_into_words=True)labels = []for i, label in enumerate(examples["ner_tags"]):word_ids = tokenized_exmaples.word_ids(batch_index=i)label_ids = []for word_id in word_ids:if word_id is None:label_ids.append(-100)else:label_ids.append(label[word_id])labels.append(label_ids)tokenized_exmaples["labels"] = labelsreturn tokenized_exmaples
这段代码是一个处理函数,用于对给定的例子进行标记映射。它接受一个包含文本和相应命名实体识别(NER)标签的字典作为输入,并返回一个包含标记化文本和映射标签的字典。以下是该函数的详细解释:
tokenizer:这是一个标记器函数,用于将文本转换为标记。它接受文本、最大长度、截断标志和是否按单词分割的标志作为输入。tokenized_exmaples = tokenizer(examples["tokens"], max_length=128, truncation=True, is_split_into_words=True):这行代码使用标记器函数对输入文本进行标记化处理,并将结果存储在tokenized_exmaples变量中。最大长度设置为128,如果文本长度超过128,则进行截断。同时,标记器会按单词进行分割。labels = []:这是一个空列表,用于存储映射后的标签。for i, label in enumerate(examples["ner_tags"])::这行代码遍历输入字典中的NER标签,并为每个标签分配一个索引i。word_ids = tokenized_exmaples.word_ids(batch_index=i):这行代码获取标记化文本中的单词ID。word_ids是一个列表,其中包含与每个标记对应的单词ID。如果标记是一个子单词,则其单词ID与其前一个标记的单词ID相同;如果标记是一个特殊标记(如CLS或SEP),则其单词ID为None。label_ids = []:这是一个空列表,用于存储映射后的标签ID。for word_id in word_ids::这行代码遍历word_ids列表中的每个单词ID。if word_id is None::这行代码检查单词ID是否为None。如果是,说明当前标记是一个特殊标记,我们将标签ID设置为-100。else::如果单词ID不是None,说明当前标记是一个单词的一部分。我们将输入标签中的相应标签ID添加到label_ids列表中。labels.append(label_ids):这行代码将label_ids列表添加到labels列表中。tokenized_exmaples["labels"] = labels:这行代码将labels列表添加到标记化示例字典中。return tokenized_exmaples:这行代码返回包含标记化文本和映射标签的字典。
总之,这个处理函数使用标记器对输入文本进行标记化处理,并将输入标签映射到标记化文本上。映射后的标签将用于后续的命名实体识别任务。
tokenized_datasets = ner_datasets.map(process_function, batched=True)
tokenized_datasets
DatasetDict({train: Dataset({features: ['id', 'tokens', 'ner_tags', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 45001})test: Dataset({features: ['id', 'tokens', 'ner_tags', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 3443})
})
找一个数据看一下
print(tokenized_datasets["train"][5])
{'id': '5', 'tokens': ['我', '们', '是', '受', '到', '郑', '振', '铎', '先', '生', '、', '阿', '英', '先', '生', '著', '作', '的', '启', '示', ',', '从', '个', '人', '条', '件', '出', '发', ',', '瞄', '准', '现', '代', '出', '版', '史', '研', '究', '的', '空', '白', ',', '重', '点', '集', '藏', '解', '放', '区', '、', '国', '民', '党', '毁', '禁', '出', '版', '物', '。'], 'ner_tags': [0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 0, 0, 0, 0, 0, 0], 'input_ids': [101, 2769, 812, 3221, 1358, 1168, 6948, 2920, 7195, 1044, 4495, 510, 7350, 5739, 1044, 4495, 5865, 868, 4638, 1423, 4850, 8024, 794, 702, 782, 3340, 816, 1139, 1355, 8024, 4730, 1114, 4385, 807, 1139, 4276, 1380, 4777, 4955, 4638, 4958, 4635, 8024, 7028, 4157, 7415, 5966, 6237, 3123, 1277, 510, 1744, 3696, 1054, 3673, 4881, 1139, 4276, 4289, 511, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [-100, 0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 0, 0, 0, 0, 0, 0, -100]}
2.3 创建模型
# 对于所有的非二分类任务,切记要指定num_labels,否则就会device错误
model = AutoModelForTokenClassification.from_pretrained("bert-base-chinese", num_labels=len(label_list))2.4 创建评估函数
seqeval = evaluate.load("seqeval")
seqeval
这里使用seqeval进行计算,我们使用开头那个例子来看一下
| 词组 | Gold标签 | Predict标签 |
|---|---|---|
| 马 | B-PER | B-PER |
| 云 | I-PER | I-PER |
| 在 | O | O |
| 杭 | B-LOC | B-LOC |
| 州 | I-LOC | I-LOC |
| 创 | O | O |
| 建 | O | O |
| 了 | O | O |
| 阿 | B-ORG | B-ORG |
| 里 | I-ORG | I-ORG |
| 巴 | I-ORG | O |
| 巴 | I-ORG | O |
references = [["B-PER", "I-PER", "O", "B-LOC", "I-LOC", "O", "O", "O", "B-ORG", "I-ORG", "I-ORG", "I-ORG"]]
predictions = [["B-PER", "I-PER", "O", "B-LOC", "I-LOC", "O", "O", "O", "B-ORG", "I-ORG", "O", "O"]]results = seqeval.compute(predictions=predictions, references=references){'LOC': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},'ORG': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1},'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},'overall_precision': 0.6666666666666666,'overall_recall': 0.6666666666666666,'overall_f1': 0.6666666666666666,'overall_accuracy': 0.8333333333333334}
创建评估函数
import numpy as npdef eval_metric(pred):predictions, labels = predpredictions = np.argmax(predictions, axis=-1)# 将id转换为原始的字符串类型的标签true_predictions = [[label_list[p] for p, l in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels) ]true_labels = [[label_list[l] for p, l in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels) ]result = seqeval.compute(predictions=true_predictions, references=true_labels, mode="strict", scheme="IOB2")return {"f1": result["overall_f1"]}这段代码定义了一个评估指标函数eval_metric,用于评估序列标注模型在命名实体识别(NER)任务上的性能。函数的输入是一个元组pred,其中包含模型预测的分数和真实的标签。代码使用numpy库来处理数组运算,并使用seqeval库来计算评估指标。
以下是代码的详细解释:
import numpy as np:导入numpy库,用于执行高效的数学运算。def eval_metric(pred)::定义一个名为eval_metric的函数,它接受一个参数pred,这是一个包含模型预测分数和真实标签的元组。predictions, labels = pred:将pred元组解包为两个变量predictions和labels,分别存储模型预测的分数和真实的标签。predictions = np.argmax(predictions, axis=-1):使用numpy的argmax函数沿最后一个轴(即类别轴)找到每个样本的最大预测分数的索引,这些索引对应于预测的标签ID。true_predictions = [...]:这是一个列表推导式,用于将预测的标签ID转换为原始的字符串类型的标签。对于每个预测和标签序列,它遍历它们并创建一个新的列表,其中只包含标签不是-100的元素。label_list[p]用于将标签ID转换为字符串标签。true_labels = [...]:这是另一个列表推导式,与true_predictions类似,但它用于转换真实的标签ID为字符串标签。result = seqeval.compute(predictions=true_predictions, references=true_labels, mode="strict", scheme="IOB2"):这行代码使用seqeval库的compute函数来计算评估指标。true_predictions是模型的预测,true_labels是真实的标签。mode参数设置为"strict",表示严格评估模式,scheme参数设置为"IOB2",表示使用IOB2标签格式。return {"f1": result["overall_f1"]}:函数返回一个字典,其中包含整体的F1分数,这是NER任务中常用的评估指标。
总之,这个函数用于评估模型在NER任务上的性能,它将模型输出的分数转换为标签,并使用seqeval库来计算F1分数。
2.5 创建训练器
args = TrainingArguments(output_dir="models_for_ner",per_device_train_batch_size=64,per_device_eval_batch_size=128,evaluation_strategy="epoch",save_strategy="epoch",metric_for_best_model="f1",load_best_model_at_end=True,logging_steps=50,num_train_epochs=1,report_to=['tensorboard']
)
为了节省时间我们只训练一遍num_train_epochs=1
2.6 模型训练
trainer = Trainer(model=model,args=args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],compute_metrics=eval_metric,data_collator=DataCollatorForTokenClassification(tokenizer=tokenizer)
)
trainer.train()

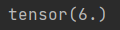
F1达到了0.946
2.7 评估
trainer.evaluate(eval_dataset=tokenized_datasets["test"]){'eval_loss': 0.02092777192592621,'eval_f1': 0.9463030643800956,'eval_runtime': 16.7905,'eval_samples_per_second': 205.056,'eval_steps_per_second': 1.608,'epoch': 1.0}
2.8 预测
# 如果模型是基于GPU训练的,那么推理时要指定device
# 对于NER任务,可以指定aggregation_strategy为simple,得到具体的实体的结果,而不是token的结果
ner_pipe = pipeline("token-classification", model=model, tokenizer=tokenizer, device=0, aggregation_strategy="simple")res = ner_pipe("马云在杭州创建了阿里巴巴")
res[{'entity_group': 'PER','score': 0.9968899,'word': '马 云','start': 0,'end': 2},{'entity_group': 'LOC','score': 0.99767697,'word': '杭 州','start': 3,'end': 5},{'entity_group': 'ORG','score': 0.98138344,'word': '阿 里 巴 巴','start': 8,'end': 12}]
完整代码