问题描述
记录一次大数据量接口优化过程。最近在优化一个大数据量的接口,是提供给安卓端APP调用的,因为安卓端没做分批次获取,接口的数据量也比较大,因为加载速度超过一两分钟,所以导致接口超时的异常,要让安卓APP分批次调用需要收取费用,所以只能先优化一下接口的速度。
分析问题
先使用阿里开源的监控工具Arthas来分析接口,Arthas 是一款线上监控诊断平台,可以实时查看应用 load、内存、gc、线程的状态信息,可以在不修改代码的情况,定位问题,分析接口耗时、传参、异常等情况,提高线上问题排查效率
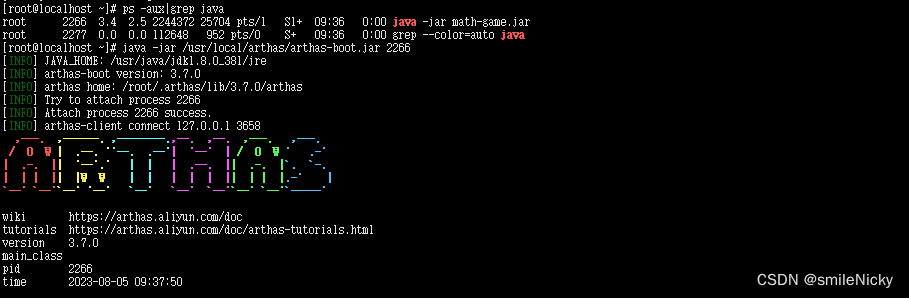
找到对应的接口代码,使用Arthas的trace命令跟踪一下接口耗时情况,listOrder是对应方法名,skipJDKMethod是不打印jdk里面的方法
trace com.sample.order.orderServiceImpl listOrder -n 1 --skipJDKMethod
要筛选出响应时间大于1000毫秒的,可以使用如下命令
trace com.sample.order.orderServiceImpl listOrder '#cost > 1000' -n 1
通过Arthas就可以分析出一个接口方法里具体那个调用耗时,然后一层层分析即可,Arthas分析的接口大致如下,仅供参考
--[100.00% 3434.755668ms ] org.springframework.cglib.proxy.MethodInterceptor:intercept()`---[100.00% 3434.620187ms ] cn.test.server.business.VisitorBusiness:getStaffList()+---[0.00% 0.045431ms ] cn.test.client.dto.StaffListReqDto:getComId() #188+---[0.00% 0.019135ms ] cn.core.common.utils.CoreUtils:isEmpty() #188+---[0.00% 0.021816ms ] cn.hutool.core.date.DateUtil:timer() #192+---[0.00% 0.019987ms ] com.google.common.base.Splitter:on() #194+---[0.00% 0.005501ms ] cn.test.client.dto.StaffListReqDto:getComId() #194+---[0.00% 0.026292ms ] com.google.common.base.Splitter:splitToList() #194+---[0.00% 0.131507ms ] cn.hutool.core.convert.Convert:toInt() #195+---[0.34% 11.668407ms ] cn.core.user.client.querier.SchoolQuerierService:findBySchoolId() #198+---[0.00% 0.024199ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #203+---[0.02% 0.535107ms ] org.slf4j.Logger:info() #203+---[2.66% 91.504718ms ] cn.core.user.client.querier.RelationQuerierService:queryUserByIdsAndRoleType() #206+---[0.00% 0.019208ms ] com.google.common.collect.Lists:newArrayList() #206+---[0.00% 0.01107ms ] cn.core.common.utils.CoreUtils:isEmpty() #207+---[0.00% 0.013517ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #211+---[0.02% 0.532242ms ] org.slf4j.Logger:info() #211+---[0.00% 0.016216ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #218+---[0.01% 0.435469ms ] org.slf4j.Logger:info() #218+---[0.00% 0.009024ms ] cn.test.client.dto.StaffListReqDto:getComId() #221+---[0.53% 18.336268ms ]cn.test.persistence.dao.LogMapper:listStaffSyncRecordByComId() #221+---[0.00% 0.009043ms ] com.google.common.collect.Lists:newArrayList() #221+---[0.00% 0.019237ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #223+---[0.01% 0.279834ms ] org.slf4j.Logger:info() #223+---[0.00% 0.014057ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #227+---[0.01% 0.270155ms ] org.slf4j.Logger:info() #227+---[0.00% 0.006338ms ] com.google.common.collect.Lists:newArrayList() #231+---[0.00% 0.019707ms ] cn.hutool.core.date.TimeInterval:intervalRestart() #263+---[0.02% 0.548875ms ] org.slf4j.Logger:info() #263`---[0.00% 0.027475ms ] cn.test.client.dto.Result:success() #265
通过Arthas分析问题,定位到接口里,是因为查询出所有的数据后,再循环这些数据,在循环里又调了API去做业务处理,针对这种情况,怎么做调优?
处理问题
针对这种情况,我想到了分批次,分页来获取接口比较好,但是安卓端要改,需要收费额外的费用,所以我只能用多线程来做分批次处理了,JDK8里提供了CompletableFuture这个api来处理多任务,多线程,所以使用这个API加上线程池来处理接口
public OrderResult<List<OrderListDto>> getOrderList(ListReqDto reqDto) throws ExecutionException, InterruptedException {if (CoreUtils.isEmpty(reqDto.getComId())) {return OrderResult.fail("comId can not be null");}// Hutool计时器TimeInterval timer = DateUtil.timer();EmsReqVo reqVo = new EmsReqVo();reqVo.setComId(reqDto.getComId());List<OrderRecVo> orderRecList = Optional.ofNullable(orderMapper.queryOrderRecVo(reqVo )).orElse(Lists.newArrayList());LOG.info("查询所有预约订单:{}", timer.intervalRestart());if (CollUtil.isEmpty(orderRecList )) {return OrderResult.success(Lists.newArrayList());}// 任务列表List<CompletableFuture<OrderListDto>> fList = new ArrayList<>();// 自定义线程池ExecutorService executor = new ThreadPoolExecutor(10, 100, 5,TimeUnit.MINUTES,new ArrayBlockingQueue<>(10000));List<OrderListDto> orderDtoList= Lists.newArrayList();orderRecList.stream().forEach(v -> {CompletableFuture<OrderListDto> f = CompletableFuture.supplyAsync(()-> {Long userId = v.getUserId;// 根据userId去调用户数据,比较耗时UserDto userDto = userService.selectOne(userId);// 封装参数返回OrderListDto orderListDto = OrderListDto.builder().code(generator(v.getId())) // 流水号.name(v.getOwnerName()) // 预约人姓名.sex(gender) // 预约人性别.identity(v.getIdentityNum()) // 证件号码.addr(v.getAddress()) // 证件地址.tel(v.getMobile()) // 联系电话.build();return orderListDto;},executor);fList.add(f);});// 获取所有的任务CompletableFuture<Void> all= CompletableFuture.allOf(fList.toArray(new CompletableFuture[0]));CompletableFuture<List<OrderListDto>> allInfo = all.thenApply(v-> fList.stream().map(a-> {try {return a.get();} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}return null;}).collect(Collectors.toList()));// 返回listorderDtoList= allInfo.get();// 关闭线程池executor.shutdown();LOG.info("查询预约订单记录 use:{}", timer.intervalRestart());return OrderResult.success(orderDtoList);}
通过CompletableFuture多任务处理,接口速度提高都十几秒
所以需要继续调优,在循环里调api会有网络带宽的影响,所以改成通过userId的集合去获取所有数据,封装成一个map集合,在循环里调用
List<Integer> userIds = orderRecList.stream().map(OrderRecVo::getReceiveId).collect(Collectors.toList());List<UserDto> usersList = Optional.ofNullable(userService.getUsersByIds(userIds)).orElse(Lists.newArrayList());Map<Integer, UserDto> usersMap = usersList.stream().collect(Collectors.toMap(UserDto::getId, u -> u));
在循环里再通过map获取即可
UserDto userDto = Optional.ofNullable(usersMap.get(v.getUserId())).orElse(new TinyUserDto());
通过所有id集合获取总的所有数据,再通过map去获取的方式,接口速度快了很多,大概到毫秒级别