通义万相2.1图生视频大模型
- 通义万相2.1图生视频
- 技术架构
- 万相2.1的功能特点
- 性能优势
- 与其他工具的集成方案
- 蓝耘平台部署万相2.1
- 核心目标
- 典型应用场景
- 未来发展方向
- 通义万相2.1ALGC实战应用
- 操作说明
- 功能测试
- 为什么选择蓝耘智算
- 蓝耘智算平台的优势
- 如何通过API调用万相2.1
- 写在最后
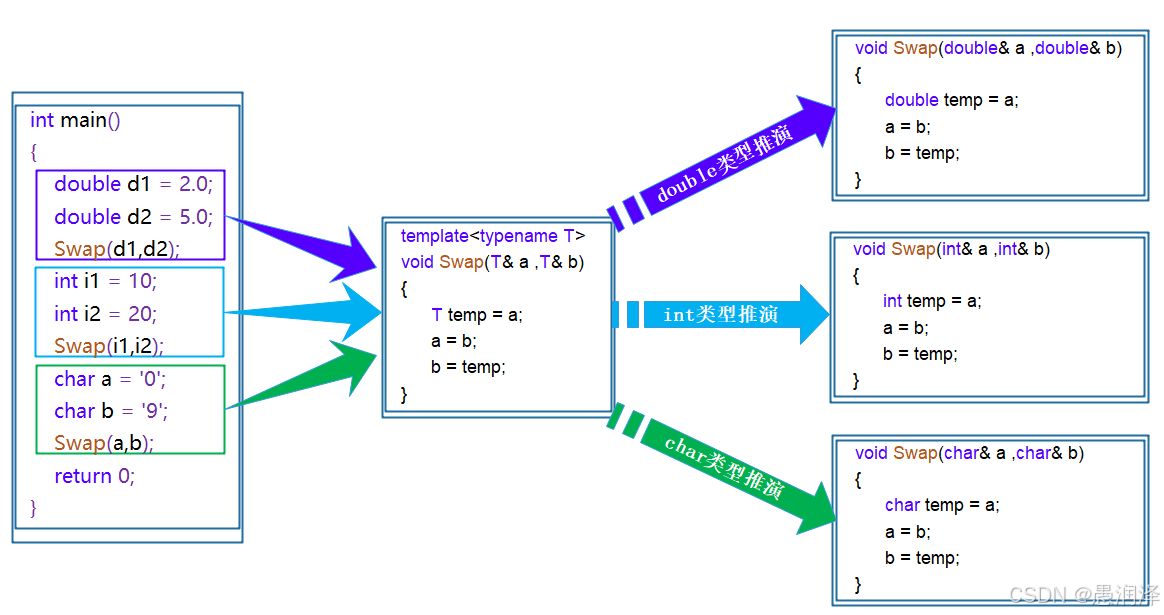
通义万相2.1图生视频
通义万相 2.1 是阿里云通义大模型旗下的图生视频大模型,于 2025 年 1 月发布,2 月 25 日阿里巴巴宣布全面开源。

通义万相2.1:VBench榜单荣登第一!阿里通义万相最新视频生成模型,支持生成1080P长视频
技术架构
采用自研的高效变分自编码器(VAE)和动态图变换器(DiT)架构。通过时空全注意机制,更准确地模拟现实世界的复杂动态;引入参数共享机制,提升性能的同时降低训练成本;优化文本嵌入,实现更优的文本可控性并减少计算需求。在视频 VAE 方面,设计创新的视频编解码方案,将视频拆分成若干块并缓存中间特征,支持无限长 1080P 视频的高效编解码。

VAE架构:变分自编码器(VAE)是生成模型,用编码器将输入数据映射到一个潜在空间,再用解码器将潜在空间的表示映射回数据空间,实现数据的生成和重建。

DiT架构:DiT(Diffusion in Time)架构是基于扩散模型的生成模型,在时间维度上逐步引入噪声,逐步去除噪声生成数据。DiT能有效地捕捉视频的时空结构,支持高效编解码和生成高质量的视频。IC-LoRA:IC-LoRA是一种图像生成训练方法,基于结合图像内容和文本描述,增强文本到图像的上下文能力,让生成的图像更加符合用户的文本描述和期望。
上下文建模:基于增强时空上下文建模能力,更好地理解和生成具有连贯性和一致性的视频内容,让视频中的动作、场景和风格等元素更加自然和协调。
万相2.1的功能特点
🚀 快速阅读

图生视频:
- 支持用户将任意图片转化为动态视频,按照上传的图像比例或预设比例进行生成,同时可以通过提示词来控制视频运动,比如控制主体的动作、运镜方式等,让静态图片实现动态化呈现。
多语言支持:
- 支持中文和英文输入,是首个支持中文文字生成及中英文文字特效生成的视频生成模型,方便全球用户使用,能满足不同语言背景用户的创作需求,尤其在处理具有中国文化特色的内容时表现出色。
灵感扩写:
- 提供灵感扩写功能,可以根据简单的提示词内容,通过智能扩写获得更完善的提示词描述,显著提升视频画面丰富度与表现力,帮助用户快速生成更具创意和细节的视频内容。
复杂动作展现:
- 稳定展现各种复杂的人物肢体运动,如旋转、跳跃、转身、翻滚等,及镜头的移动,让视频内容更加生动和真实。
物理规律还原:
- 逼真还原真实世界的物理规律,如碰撞、反弹、切割、挤压等。比如生成雨滴落在伞上溅起水花的场景,让视频更具真实感。
艺术风格转换:
- 具备强大的艺术风格表现力,能一键转换视频的影视质感与艺术风格,如电影色调、印象笔触、抽象表现等,生成各种风格的视频。
性能优势
运动模拟精准:
-
在大幅度的肢体运动和肢体旋转场景的视频生成上表现更稳定,能够精准模拟现实世界的物理规律。
-
如人物运动时的自然过渡、雨滴落在伞上溅起水花等,在处理花样滑冰、游泳、跳水等复杂运动时,能保持肢体的协调性和运动轨迹的真实性。
指令遵循度高:
- 对镜头移动等指令能严格遵循并输出视频,对长文本指令也能准确理解和执行,可根据用户的详细描述生成符合要求的视频内容。
画面质量高:
- 可生成影视级高清视频,在视频生成领域的权威评测集
VBench上,以总分 86.22% 的成绩大幅超越
Sora、Luma、Pika等国内外模型,在运动幅度、多对象生成、空间关系等 16 个评分维度中的关键能力上拿下最高分。
与其他工具的集成方案
Photoshop 插件开发
通过插件调用通义万相API,实现以下功能:
- 一键生成背景图并导入当前画布。
- 圈选区域后输入提示词进行局部重绘。
- 自动匹配生成图的色彩方案至PS调色板。
Figma 自动化工作流
使用Figma API与通义万相结合:
- 输入文本描述生成图标库,直接转换为SVG矢量图。
- 根据线框图(Wireframe)自动填充高保真UI素材。
Blender 3D 辅助设计
- 生成贴图材质:输入“腐蚀金属纹理”生成法线贴图(
Normal Map)。 - 概念图转3D草稿:基于2D生成图自动创建低多边形(
Low Poly)模型。
蓝耘平台部署万相2.1
定位:
- 蓝耘GPU平台是面向 AI高性能计算(
HPC)和生成式AI (AIGC) 场景设计的分布式GPU算力服务平台,专注于为企业与开发者提供弹性、高性价比的GPU算力资源,支持从模型训练、推理到大规模部署的全流程需求。
核心目标

- 解决传统算力方案中存在的高成本、低利用率、扩展性差等问题,助力AI模型(如通义万相2.1)实现高效工业化落地。
技术架构与核心优势:
- 硬件层:弹性GPU集群
多型号GPU支持:搭载NVIDIA A100、V100、H100等高性能显卡,支持混合集群调度。
分布式架构:通过高速网络(如InfiniBand)实现多机多卡并行计算,突破单机算力瓶颈。
按需扩展:支持分钟级动态扩容,适应突发算力需求(如电商大促期间的AI图像批量生成)。
- 软件层:深度优化技术栈
容器化部署:集成Kubernetes与Docker,实现任务快速迁移与隔离。
显存优化:采用显存虚拟化技术与分块加载策略,提升大模型(如万相2.1)的显存利用率。
框架适配:预置PyTorch、TensorFlow等主流框架的定制化版本,降低分布式训练代码改造成本。
- 核心优势
成本降低:通过资源池化与动态调度,GPU利用率提升至80%+(对比传统方案30%-50%)。
性能加速:针对生成式AI任务(如高分辨率图像生成),推理速度提升2-5倍。
稳定性保障:自动故障转移与冗余备份,任务中断率<0.1%。
典型应用场景
- AIGC内容生成
图像/视频生成:支持Stable Diffusion、阿里万相等模型的高并发推理,适用于广告创意、游戏原画等场景。
3D建模:加速NeRF、GAN等模型的训练,缩短3D内容生产周期。
- 大模型训练与微调
千亿参数模型分布式训练:支持数据并行、模型并行混合策略,降低训练耗时。
低成本微调:通过弹性资源分配,按需调用GPU完成垂类模型迭代。
- 科学计算与仿真
分子动力学模拟:利用GPU加速量子化学计算。
气象预测:优化WRF等科学计算框架的并行效率。
蓝耘GPU平台和通义万相2.1的协同优势
技术适配性:软硬协同优化
| 优化维度 | 蓝耘GPU的技术支持 | 对万相2.1的增益效果 |
|---|---|---|
| 分布式并行计算 | 多机多卡协同(如NVIDIA A100集群) | 突破单卡显存限制,支持8K图像/长视频生成 |
| 显存管理 | 显存虚拟化+动态分块加载 | 大模型推理显存占用降低40%,避免OOM中断 |
| 通信优化 | InfiniBand网络+定制NCCL通信库 | 多节点任务通信延迟减少60%,提升批量任务吞吐量 |
| 框架适配 | 预置PyTorch轻量化推理框架 | 万相2.1模型零代码修改即可部署,缩短上线周期 |
未来发展方向
- 边缘计算融合:推动GPU算力下沉至边缘节点,支持实时AI推理(如直播互动、工业质检)。
- 绿色算力:通过液冷技术与能耗优化,降低PUE(电源使用效率)至1.2以下。
- 生态扩展:与更多AI模型(如国产大模型)深度适配,构建开放算力生态。
总结
蓝耘GPU平台通过软硬协同优化与分布式架构设计,成为生成式AI时代的关键算力基座,尤其在与通义万相2.1等前沿模型的结合中,展现了显著的效率提升与成本优势。其灵活性和企业级服务能力,使其在电商、游戏、科研等领域快速落地,推动AI从实验性技术向生产级工具演进。🌟
通义万相2.1图生视频,文生视频已上线蓝耘应用市场,如下就是:

看到这里是否也跃跃欲试,接下来我们为大家介绍如何注册蓝耘GPU平台,点击一键跳转注册🔥
跳转到如下界面:我们根据需要填写对应信息就可以注册成功。

注册成功后进入主页面,进入应用市场

即可看到通义万相2.1图生视频模型:

通义万相2.1ALGC实战应用
首先选择自己需要的通义万相模型,这里我以图生视频为例:
点击部署,跳转到如下界面:

按照自己的需求完成配置。

建议选择按量计费,RTX4090显卡,这样性能会更好!
配置好之后打开工作空间,启动应用后

跳转进入进入如下界面:

这就是通义万相2.1图生视频的具体操作页面!
操作说明
- 模型加载
“Checkpoint 加载器(简易)” 用于选择和加载 AI 图像生成模型,点击 “Checkpoint 名称” 可更换不同的模型文件,模型决定了生成图像的风格、质量等基础特性。
- 文本提示设置
正面提示词:“CLIP 文本编码” 中的正面提示词框(如 “beautiful scenery nature glare bottle landscape , people galaxy bottle”),在这里输入你想要生成图像的具体描述,例如画面元素、场景、风格等。
负面提示词:另一个 “CLIP 文本编码” 用于设置负面提示词(如 “text, watermark” ),即你不希望在生成图像中出现的元素。
- 图像参数设置
“空 Latent 图像” 节点可设置生成图像的宽度、高度和批量大小。宽度和高度决定了图像尺寸,批量大小表示一次生成图像的数量。
- 采样设置
“K 采样器” 节点中:
种子:可输入特定数值固定随机生成的起始状态,方便复现图像;若不填则每次随机。
步数:决定采样计算的次数,步数越多,图像越精细,但耗时也越长。
Cfg(分类器自由引导尺度):数值越大,生成图像与提示词的匹配度越高,但可能会导致图像缺乏多样性。
采样器名称:选择不同的采样算法,不同算法生成效果和速度有差异。
- 生成与保存
设置好以上参数后,点击界面下方的 “执行” 按钮开始生成图像。生成的图像经过 “VAE 解码” 处理后,通过 “保存图像” 节点保存到指定位置,“文件名前缀” 可自定义。
如果想调整工作流,可通过拖动节点、连接或断开连线来修改数据流向和处理流程。
功能测试
首先我们点击工作流,然后点击浏览模板,如下图所示:

然后下滑选择ComfyUI-WanVideoWrapper模板,点击wanvideo_480p_I2V_example_02模板

进入到如下界面:

随后在如下流程框,上传对应的图像

在这个界面,上面的输入框输入期望生成视频的正向提示词

如下界面输入对应的负面提示词:

最后点击,执行即可

执行后,对应的生成队列就会新增,静待几分钟,等待视频生成

最终效果如下:

如上所示,通过万相2.1模型生成的视频效果还是非常不错的,上面的是我视频转出成为 GIF的效果,实际上的视频生成的清晰度和流畅度要更加优秀!
为什么选择蓝耘智算
蓝耘智算平台的优势
蓝耘智算结合通义万相 2.1 具有多方面优势:
强大算力支持:
- 蓝耘智算拥有大规模 GPU 集群,支持
NVIDIA A100、V100、RTX 4090等多种主流 GPU 型号。面对通义万相 2.1处理复杂文生图任务,如高分辨率图像生成、复杂场景渲染、大规模数据集训练时,蓝耘的算力能确保模型流畅运行,充分发挥其语义理解、细节生成优势,大幅缩短生成时间。例如生成超高清科幻场景图像,普通算力需数分钟,蓝耘智算支撑下,通义万相 2.1 几十秒即可完成 。
灵活资源调度:
- 蓝耘智算云平台支持按需计费,用户可根据业务需求动态调整资源。业务高峰期,如广告设计公司集中制作广告时,可灵活增加算力,保证任务快速处理;低谷期则减少资源配置,避免浪费,降低成本。同时,平台的裸金属调度和容器调度等多种调度方式,可满足通义万相 2.1 在不同场景的运行需求 。
全栈服务保障:
- 蓝耘不仅提供 GPU 算力,还提供从裸金属、容器到
Kubernetes,集 GPU池化资源、高性能网络、高性能存储等基础设施,以及资源调度、开发环境、运行监控、运维服务于一体的全栈服务。丰富的开发工具和框架,可帮助开发者快速搭建开发环境;运行监控实时监测任务状态,及时解决问题;运维服务确保平台基础设施稳定,让用户专注创作 。
如何通过API调用万相2.1
创建应用
-
登录控制台,进入 “应用管理” > “创建新应用”。
-
填写应用名称(如
MyImageApp),选择服务类型为 “图像生成” 或
“AI模型”。创建成功后,记录应用ID(app_id)和密钥(API Key + Secret Key)。
获取令牌(Token)
- 部分平台使用动态Token,需通过API临时获取:
import requests
auth_url = "https://api.lanyun.com/auth/token"
response = requests.post(auth_url, json={"api_key": "YOUR_API_KEY","secret_key": "YOUR_SECRET_KEY"
})
access_token = response.json()["access_token"]
API请求详解
请求头(Headers)
- 必填字段:
{"Authorization": "Bearer YOUR_ACCESS_TOKEN","Content-Type": "application/json","X-App-Id": "your_app_id" // 部分平台需要
}
认证失败处理:
- 错误码 401:检查Token是否过期或密钥是否正确。
- 错误码 403:确认应用是否已开通“通义万相”服务权限。
请求体(Body)参数
{"model": "tongyi-wanxiang-2.1","prompt": "一只卡通风格的熊猫,坐在竹林里吃竹子,阳光透过树叶洒下斑点","negative_prompt": "模糊,低分辨率,文字", // 可选:排除不想要的内容"num_images": 2, // 生成数量(通常限制1-4)"size": "1024x1024", // 支持 512x512, 768x768, 1024x1024, 1024x1792等"quality": "hd", // standard(标准)或 hd(高清,耗时更长)"style": "cartoon", // 可选风格(见下文)"seed": 12345, // 可选:固定随机种子,确保生成结果可复现"steps": 30, // 生成步数(20-50,值越高细节越好但速度越慢)"cfg_scale": 7.5 // 提示词相关性(1-20,默认7,值越高越贴近提示)
}
支持的艺术风格
| 风格值 | 描述 |
|---|---|
digital_art | 数字绘画 |
photographic | 照片级真实 |
fantasy_art | 奇幻艺术 |
anime | 动漫风格 |
watercolor | 水彩画 |
oil_painting | 油画 |
cinematic | 电影质感 |
| 同步与异步模式 |
同步请求(快速生成)
- 直接返回生成结果,适用于简单任务(如低分辨率、标准质量):
response = requests.post(ENDPOINT, headers=headers, json=data)
if response.status_code == 200:images = response.json()["data"]for img in images:print("URL:", img["url"], "Seed:", img["seed"])
异步请求(高清/复杂任务)
- 提交任务:
async_data = {"model": "tongyi-wanxiang-2.1","prompt": "...","size": "1024x1792","quality": "hd","async": True # 显式指定异步模式
}
response = requests.post(ENDPOINT, headers=headers, json=async_data)
task_id = response.json()["task_id"]
轮询任务状态:
import time
status_url = f"https://api.lanyun.com/v1/tasks/{task_id}"while True:status_response = requests.get(status_url, headers=headers)status = status_response.json()["status"]if status == "SUCCESS":image_urls = status_response.json()["output"]["urls"]breakelif status in ["FAILED", "CANCELLED"]:print("失败原因:", status_response.json()["error_message"])breakelse:print("任务处理中,等待10秒...")time.sleep(10)
调试技巧
精简测试:
- 使用最小参数集测试连通性:
{"model": "tongyi-wanxiang-2.1","prompt": "一只白色的猫","num_images": 1,"size": "512x512"
}
日志记录:
- 记录完整的请求和响应,方便排查:
import logging
logging.basicConfig(level=logging.DEBUG) # 启用requests库的调试日志
常见的错误码
| 错误码 | 含义 | 解决方法 |
|---|---|---|
| 400 | 请求参数错误 | 检查JSON格式、必填字段、参数取值范围 |
| 429 | 请求频率超限 | 降低调用频率,或申请提升QPS配额 |
| 500 | 服务器内部错误 | 联系平台技术支持,提供请求ID(request_id) |
| 503 | 服务暂时不可用 | 重试或等待维护结束 |
成本与配额管理
计费方式:
- 按生成图片数量计费(如 0.1元/张 标准质量,0.2元/张 高清)。
- 或按Token消耗量计费(取决于输入文本长度)。
查看配额:
- 在控制台 “费用中心” > “用量明细” 查看剩余调用次数/余额。
- 设置用量警报,避免超额。
完整代码示例(含错误处理)
import requests
import timedef generate_image(prompt, style="digital_art", retries=3):API_KEY = "your_api_key"ENDPOINT = "https://api.lanyun.com/v1/images/generations"headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"}data = {"model": "tongyi-wanxiang-2.1","prompt": prompt,"size": "1024x1024","style": style,"num_images": 1}for attempt in range(retries):try:response = requests.post(ENDPOINT, headers=headers, json=data, timeout=30)if response.status_code == 200:return response.json()["data"][0]["url"]else:print(f"Attempt {attempt+1} failed. Code: {response.status_code}, Error: {response.text}")if response.status_code == 429: # 频率限制time.sleep(10) # 等待10秒后重试except requests.exceptions.RequestException as e:print(f"Network error: {e}")return None# 调用示例
image_url = generate_image("未来城市,赛博朋克风格,霓虹灯光,雨夜")
if image_url:print("生成成功!URL:", image_url)
else:print("生成失败,请检查参数或联系支持")
高级功能
批量生成:
- 使用
num_images=4生成多张图片,筛选最佳结果。
自定义模型:
- 如果企业有定制模型,可通过
"model": "your_custom_model_id"调用。
图片编辑:
- 部分平台支持基于原图修改(需上传掩码图):
{"model": "tongyi-wanxiang-2.1","prompt": "将衣服颜色改为红色","init_image": "https://example.com/input.jpg","mask_image": "https://example.com/mask.png" // 标记修改区域
}
写在最后
🎉通义万相 2.1,引领 AIGC 视频创作新时代!
那么本文到这里就结束了,有关蓝耘智算平台部署和使用通义万相2.1大模型的具体操作相信你也已经学会了,相信你也已经迫不及待了吧,快去试试吧!我们下期再见!
快去试试吧!!!
蓝耘GPU平台注册链接:
https://cloud.lanyun.net//#/registerPage?promoterCode=0131