Python 语音识别系列-实战学习-语音识别特征提取
- 前言
- 1.预加重、分帧和加窗
- 2.提取特征
- 3.可视化特征
- 4.总结
前言
语音识别特征提取是语音处理中的一个重要环节,其主要任务是将连续的时域语音信号转换为连续的特征向量,以便于后续的语音识别和语音处理任务。在特征提取阶段,这些特征向量能够捕捉到语音信号中的关键信息,如音调、音色和音节等。
特征提取主要可以分为以下几个方面:
- 时域特征提取:包括自相关函数、方差、峰值等。
- 频域特征提取:如傅里叶变换、快速傅里叶变换、波束傅里叶变换等。
- 时频域特征提取:包括短时傅里叶变换、波形分解、时频图等。
- 高级特征提取:涉及语言模型、语音模型、语音合成等。
在具体实践中,语音特征提取的方法和技术,如:
- 梅尔频率倒谱系数 (MFCC):这是最常用的特征提取方法之一。它通过将音频信号的频率变换为梅尔尺度,来模拟人类耳朵的听觉特性。
- 滤波器组的Fbank特征(Filter bank)/MFSC:Fbank特征的提取方式相当于MFCC去掉最后一步的离散余弦变换。与MFCC特征相比,Fbank特征保留了更多的原始语音数据。
- 线性预测分析(LPC):假设系统的传递函数与全极点的数字滤波器相似,通过计算语音信号的采样值和线性预测的采样值,并最小化两者之间的均方误差(MSE),从而得到LPC特征。
- 感知线性预测系数(PLP):这是一种基于听觉模型的特征参数,等效于LPC特征,但它是基于人耳听觉的,通过计算应用到频谱分析中,将输入语音信号经过人耳听觉模型处理,有利于抗噪声语音特征的提取。
这些特征通常会被用于构建机器学习模型,如隐马尔可夫模型 (HMM)、深度神经网络 (DNN) 等,以进行更精准的语音识别。在实际应用中,可能会结合多种特征提取技术来优化识别效果。
在进行语音识别的特征处理前,对原始音频数据进行一系列预处理步骤是非常重要的,这些步骤有助于提高最终识别系统的准确性和鲁棒性。以下是一些在特征提取之前常见的音频预处理技术:
- 预加重: 预加重是一个高通滤波过程,用于放大高频成分。这有助于平衡音频信号中由于声带和嘴唇效应造成的频率衰减。
- 分帧和加窗: 由于语音信号是非平稳的,通过将长的音频信号分割成短时帧,可以近似地认为每个短时帧是平稳的。每帧通常包括20到40毫秒的音频。为了减少相邻帧之间的边界效应,会对每帧使用窗函数(如汉明窗或汉宁窗)。
- 去噪: 去噪旨在减少背景噪声,提高语音信号的清晰度。常用的方法包括频谱减法、Wiener滤波器、深度学习方法等。对于实时或近实时的应用,非因果性去噪方法(如使用预先录制的噪声模型)可能更为有效。
- 归一化: 音频信号的归一化(如均值归零和方差归一化)有助于减少不同录音条件下的变异,使特征提取更加稳定。
1.预加重、分帧和加窗
import numpy as np
import librosadef pre_emphasis(signal, alpha=0.97):"""对给定的音频信号应用预加重。预加重可以增强信号的高频部分,常用于语音处理中。参数:- signal: 原始音频信号数组- alpha: 预加重系数,通常介于0.95到0.97之间返回:- 预加重后的音频信号"""return np.append(signal[0], signal[1:] - alpha * signal[:-1])def frame_signal(signal, frame_size, hop_size, sample_rate):"""将音频信号分割成多个帧。参数:- signal: 预加重后的音频信号- frame_size: 帧大小,以秒为单位- hop_size: 帧之间的跳跃大小,以秒为单位- sample_rate: 音频的采样率返回:- 分帧后的音频数据"""frame_length = int(frame_size * sample_rate)hop_length = int(hop_size * sample_rate)return librosa.util.frame(signal, frame_length=frame_length, hop_length=hop_length)def apply_window(frames, frame_size, sample_rate, window_type='hamming'):"""对每帧音频数据应用窗函数。窗函数有助于减少边界效应,提高频谱分析的质量。参数:- frames: 分帧后的音频数据- frame_size: 帧大小,以秒为单位- sample_rate: 音频的采样率- window_type: 使用的窗函数类型,例如'hamming', 'hanning'返回:- 加窗后的帧"""frame_length = int(frame_size * sample_rate)if window_type == 'hamming':window = np.hamming(frame_length)elif window_type == 'hanning':window = np.hanning(frame_length)else:window = np.ones(frame_length) # 矩形窗return frames * window[:, np.newaxis]# 示例使用
audio_file = '跑步.wav'
signal, sr = librosa.load(audio_file, sr=None) # 加载音频文件# 预加重
pre_emphasized_signal = pre_emphasis(signal)# 分帧
frames = frame_signal(pre_emphasized_signal, 0.025, 0.01, sr) # 设定帧大小为25毫秒,帧间隔为10毫秒# 加窗
windowed_frames = apply_window(frames, 0.025, sr)print("加工处理后的帧形状:", windowed_frames.shape)
在这段代码中:
首先对原始音频信号进行预加重处理,这有助于后续处理中更好地提取高频特征。
然后将音频信号分割成短时帧,每帧25毫秒长,帧与帧之间的间隔为10毫秒。
最后,对每个帧应用汉明窗函数,以减少边界处的信号不连续性,改善频谱分析的效果。
也可以用 librosa.effects.preemphasis 来进行预加重 :
import numpy as np
import librosa
import librosa.display
from matplotlib import pyplot as pltaudio_file = '跑步.wav'
audio, s_r = librosa.load(audio_file, sr=16000)print(audio.shape, '|', s_r)
signal = librosa.effects.preemphasis(audio) # 进行预加重 plt.figure(dpi=200)
plt.subplot(211)
plt.title( "orignal_wav")
plt.tight_layout()
librosa.display.waveshow(audio, sr=s_r)plt.subplot(212)
plt.title( "after_emphasis")
plt.tight_layout()
librosa.display.waveshow(signal, sr=s_r,color='r')

2.提取特征
要在音频特征提取过程中加入语音去噪等预处理步骤,可以使用noisereduce库对音频信号进行去噪处理。这有助于提高后续特征提取的准确性和效果。需要安装noisereduce库:pip install noisereduce
需将audio_path变量替换为你的音频文件的实际路径。这段代码将输出两种特征的尺寸,验证特征是否正确提取。
import librosa
import numpy as np
import noisereduce as nrdef extract_features(audio_path):# 加载音频文件signal, sample_rate = librosa.load(audio_path, sr=None) # 使用原始采样率# 去噪处理noise_clip = signal[0:int(0.5 * sample_rate)] # 假设前0.5秒为噪声部分reduced_noise_signal = nr.reduce_noise(audio_clip=signal, noise_clip=noise_clip, verbose=False)# 提取MFCC特征mfccs = librosa.feature.mfcc(y=reduced_noise_signal, sr=sample_rate, n_mfcc=13)# 提取Filterbank特征fbank = librosa.feature.melspectrogram(y=reduced_noise_signal, sr=sample_rate, n_mels=40)fbank = librosa.power_to_db(fbank)return mfccs, fbank# 使用示例
audio_path = '跑步.wav'
mfccs, fbank = extract_features(audio_path)print("MFCCs:", mfccs.shape)
print("Filterbank Features:", fbank.shape)代码解释:
- 加载音频文件:librosa.load函数用来加载音频文件。sr=None参数确保使用音频文件的原始采样率。
- 提取MFCC特征:使用librosa.feature.mfcc函数提取MFCC特征。n_mfcc=13指定提取13个MFCC特征。
- 提取Filterbank特征:librosa.feature.melspectrogram用于计算mel频谱图,n_mels=40定义了使用40个mel滤波器。然后,使用librosa.power_to_db将mel频谱的能量转换为分贝值。
3.可视化特征
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np# 读取音频文件
audio_path = '跑步.wav'
audio, sample_rate = librosa.load(audio_path)# 计算滤波器组特征
melspec = librosa.feature.melspectrogram(y=audio, sr=sample_rate, n_fft=2048, hop_length=512, n_mels=128)
melspec_db = librosa.power_to_db(S=melspec, ref=np.max)# 计算MFCC特征
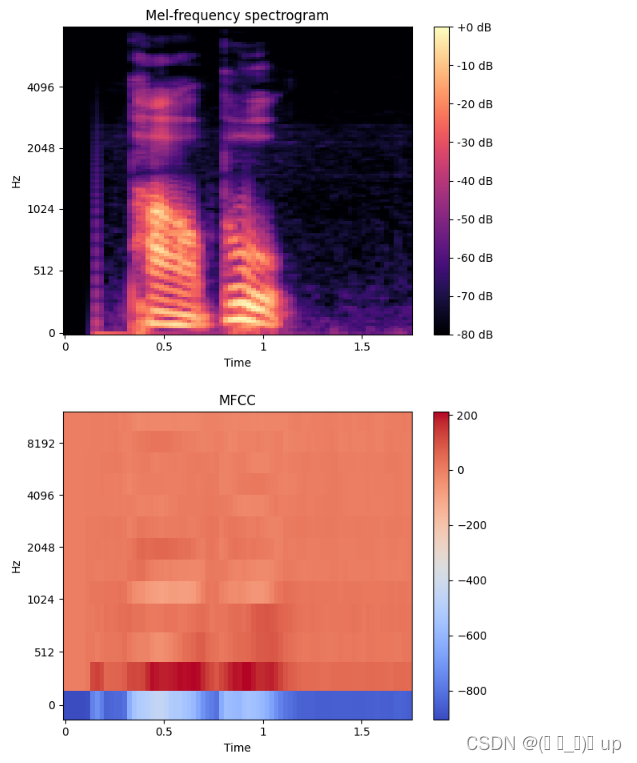
mfccs = librosa.feature.mfcc(S=melspec_db, sr=sample_rate, n_mfcc=13)# 可视化滤波器组特征
plt.figure()
librosa.display.specshow(melspec_db, x_axis='time', y_axis='mel', sr=sample_rate, fmax=8000)
plt.colorbar(format='%+2.0f dB')
plt.title('Mel-frequency spectrogram')
plt.tight_layout()# 可视化MFCC特征
plt.figure()
librosa.display.specshow(mfccs, x_axis='time', y_axis='mel', sr=sample_rate)
plt.colorbar()
plt.title('MFCC')
plt.tight_layout()plt.show()
4.总结
此次学习了语音特征分析之前的语音预处理步骤,且主要讲解了MFCC特征和 Filterbank特征的python实现,下一步将采用一些模型对语音进行建模。