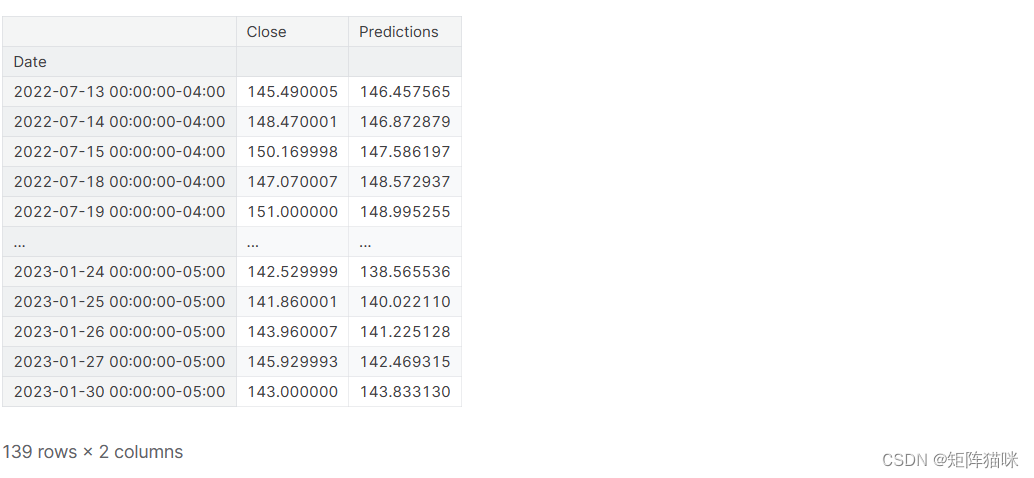
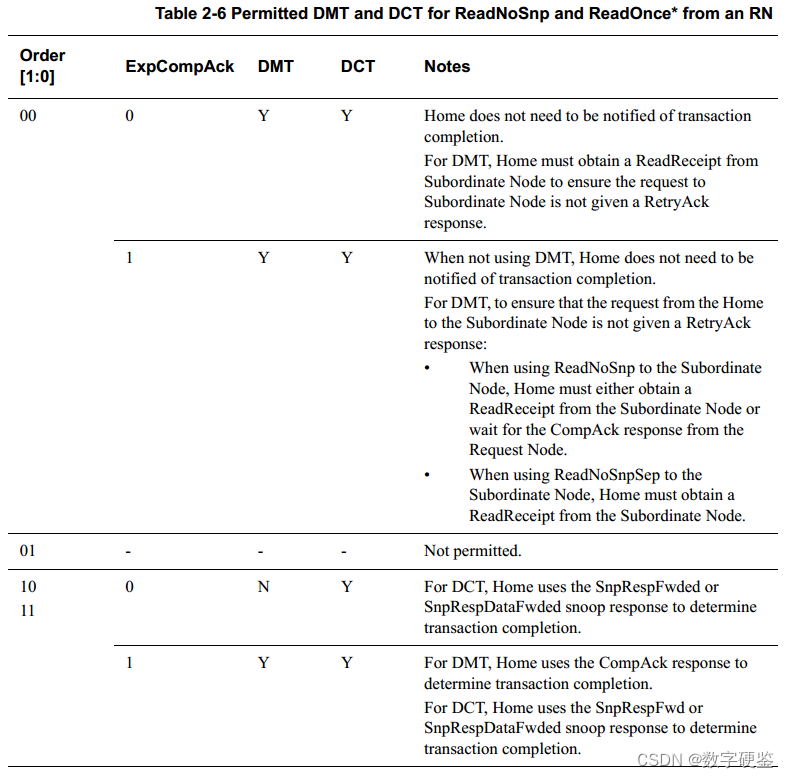
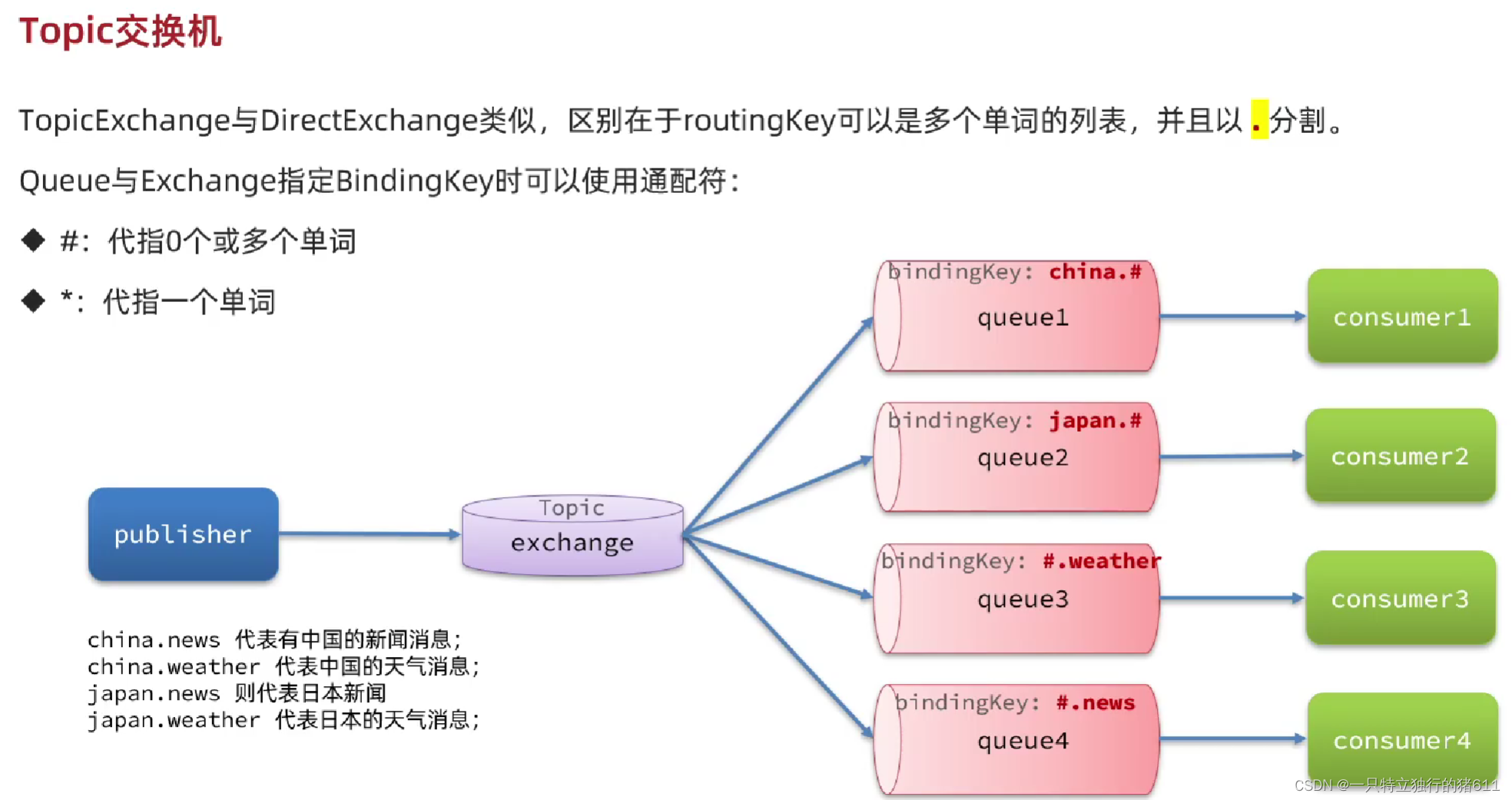
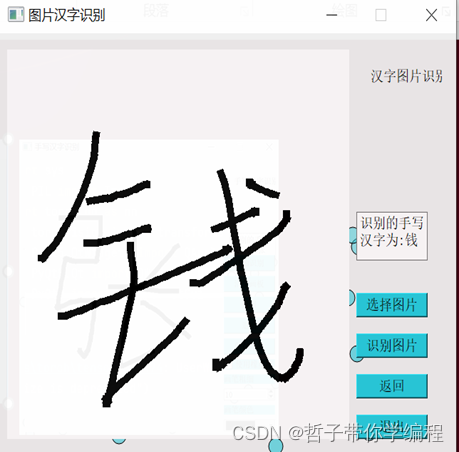
ChatGPT
OneFlow是一个开源的深度学习框架,它是由中国的一家公司——OneFlow Inc. 开发的,致力于提高大规模分布式训练的性能和效率。它提供了一种新颖的编程范式,旨在简化分布式系统的搭建过程,并提高资源的利用率。在OneFlow中,您会遇到以下一些核心概念:
1. Tensor:类似于其他深度学习框架如PyTorch和TensorFlow的张量概念,Tensor是OneFlow中的基本数据结构,用于表示多维数组。它可以存储模型的输入数据、输出数据以及模型的参数。
2. Operator(算子):在OneFlow中,神经网络中的操作,如卷积、池化、激活函数等被抽象为算子。算子接收输入Tensor,进行计算,并输出结果Tensor。
3. Job Function:在OneFlow中用于定义高性能模型的函数。开发者定义Job Function时会指定网络结构,并且可以嵌入OneFlow提供的各种Operator。
4. Module:模块化是面向对象的编程范式,在OneFlow中,Module可用于创建复杂的网络结构,类似于PyTorch中的nn.Module。
5. Scope:作用域,它定义了算子执行的上下文环境,如变量的生命周期、内存分配策略等。
6. Blob:OneFlow的老版中使用Blob来表示计算图中的一个节点。Blob可以被理解为Tensor的一个别名,在新版OneFlow中,Tensor概念取代了Blob。
7. Consistent and Lazy Execution:OneFlow引入一种新的执行模式,称为Consistent Execution,它允许跨多台机器和多个设备平滑地扩展神经网络的训练。懒执行(Lazy Execution)则是指计算图的构建和执行是延迟发生的,可以帮助提高计算效率和优化资源分配。
8. Distributed Training:OneFlow支持分布式训练,可以在多个GPU或者多个节点上并行执行模型的训练过程。这是通过分布式数据并行的方式实现的。
9. Automatic Graph Optimization:OneFlow自动优化计算图,包括内存复用、计算与通信的重叠以及算子融合等优化策略。
10. Eager Execution:OneFlow同时支持Eager模式,这意味着每个算子或操作可以立即执行并返回结果,而无需构建整个计算图。这对于调试和实验是非常有用的。
11. Flow Serialization:OneFlow允许将训练好的模型序列化保存,以便可以在不同环境中重载和推理使用。
12. Device Management:OneFlow有自己的设备管理系统,可以指定算子在特定的设备上执行(例如CPU或GPU)。
这些概念为使用OneFlow框架进行深度学习研究或开发提供了基础。随着OneFlow的更新迭代,这些概念也可能会有所更改。需要注意的是,OneFlow虽然是为了提高性能和效率而设计的,但在全球范围内的受欢迎程度和社区活跃程度可能不如PyTorch和TensorFlow等主流深度学习框架。因此,在选择框架时,还需要考虑社区支持、学习资源、现有代码库等因素。

通义灵码
以下是一份简化的OneFlow概念清单:
-
OneFlow:
- 框架介绍: OneFlow是一款专注于高性能、易用性和可扩展性的分布式机器学习框架,旨在简化大规模数据并行、模型并行和混合并行场景下的深度学习训练与推理过程。
-
分布式计算基础:
- Placement: 表示张量或运算在硬件设备(如GPU、CPU)上的分布策略。例如,
flow.placement(type="cuda", ranks=[[0,1,2,3],[4,5,6,7]])定义了一个在两个设备组(每个组包含四个CUDA GPU)上分布的数据布局。 - Global View: 提供一种全局视角来描述数据和计算任务在整个集群中的分布情况,是OneFlow实现高效分布式训练的核心机制之一。它允许用户以统一的方式处理局部数据和全局数据,简化了并行编程模型。
- Placement: 表示张量或运算在硬件设备(如GPU、CPU)上的分布策略。例如,
-
编程模型与API:
- @flow.global_function(type="train"): 装饰器用于定义一个全局可执行的训练任务。它封装了模型的前向传播、反向传播、优化步骤等,并支持在分布式环境下运行。
- Tensor (张量): 类似于其他深度学习框架中的张量,表示多维数组,是数据的基本容器。在OneFlow中,张量可以分布在不同的设备上,并通过全局视图进行协调。
- Numpy API兼容性: OneFlow提供了与NumPy类似的接口,便于从Python生态中无缝迁移代码,同时利用OneFlow的分布式特性。
-
类型提示(Typing):
- oneflow.typing: 提供类型注解,帮助静态检查和确保函数参数和返回值的正确性。例如,
tp.Numpy可能用来指定输入数据类型应为类似于NumPy的数组。
- oneflow.typing: 提供类型注解,帮助静态检查和确保函数参数和返回值的正确性。例如,
-
模型定义与训练:
- mlp(data): 示例中定义了一个多层感知机(MLP)模型,接收输入数据并返回预测结果。
- train_job(images: tp.Numpy): 使用
@flow.global_function装饰的训练函数,接收一个类型为tp.Numpy的图像数据批次,并在内部执行模型训练流程。
-
其他可能涉及的概念:
- Batch Size: 训练时每一批次处理的数据样本数量,如
BATCH_SIZE=100。 - 优化器(Optimizer): 负责更新模型权重以最小化损失函数。虽然没有直接提到,但在实际训练中会用到,如Adam、SGD等。
- Loss Function: 评估模型预测与真实标签之间差异的函数,用于指导反向传播和权重更新。
- Batch Size: 训练时每一批次处理的数据样本数量,如
请注意,这份清单可能不包括OneFlow所有具体概念或最新的特性。对于更详尽、官方的“OneFlow概念清单”,建议查阅OneFlow项目的官方文档或相关教程以获取最准确、全面的信息。如果您有具体概念需要进一步解释或探讨,请随时提问。

文心一言
OneFlow是一款深度学习框架,由北京一流科技有限公司开发,旨在为用户提供高效、易用和灵活的深度学习解决方案。以下是OneFlow概念清单:
- 核心技术:OneFlow独创四大核心技术,技术水平世界领先,具有高性能和高效的计算优化能力。
- 分布式训练:支持在单个GPU或多个GPU之间进行分布式训练,以提高训练效率,加速深度学习模型的训练过程。
- 易用性:设计简洁,提供了高级的API接口,使得用户能够快速上手,并简化了模型的构建、训练和部署过程。
- 灵活性:支持动态图和静态图混合编程模式,允许用户根据需求选择合适的模式进行开发。同时,提供了丰富的内置算子和模型组件,并支持自定义算子和模型组件,以满足各种深度学习任务的需求,包括图像识别、自然语言处理、目标检测等。
- 模型部署:OneFlow提供了轻量级的模型导出和部署功能,使得训练好的模型能够轻松地部署到生产环境中进行推理。
- 生态系统:OneFlow拥有活跃的社区支持,提供了丰富的文档、教程和示例,方便用户学习和使用。同时,它与其他深度学习框架如TensorFlow、PyTorch等兼容,可以无缝地进行集成和迁移。
OneFlow以其高效的计算和优化能力,在多个领域取得了显著的成果,如图像识别、自然语言处理、语音识别等。通过OneFlow,用户可以高效地构建、训练和部署深度学习模型,从而推动人工智能技术的发展和应用。
请注意,随着技术的不断发展,OneFlow的概念和功能可能会有所更新和扩展,建议访问其官方网站或查阅相关文档以获取最新的信息和资源。

讯飞星火
OneFlow是一个开源的深度学习框架,其概念清单中包含了多个核心组件和概念,具体如下:
- Placeholder:这是数据占位符的概念,在模型定义时用于描述输入/输出的数据形状,但并不包含实际的数据值。它相当于一个空的容器,稍后在执行时会被具体的数据填充。
- Tensor 和 Blob:Tensor在其他深度学习框架如PyTorch中被广泛使用,它是一个多维数组,包含数据值和类型、梯度以及存放的设备类型等属性。在OneFlow中,Blob是类似的概念,用于表示和管理张量数据。
- Job Function(作业函数):在OneFlow中,将训练、预测等具体任务统称为作业函数。这些函数连接用户的业务逻辑与OneFlow管理的计算资源,是组织和执行深度学习任务的核心概念。
- Layer 和 Operator(op):Layer指的是神经网络中的层,而Operator或简称Op则是基础的计算操作,比如加减乘除、卷积等。这些构建块用于定义网络的结构和计算流程。
- Consistent/Mirrored View:这是OneFlow中特有的概念,涉及到分布式训练时的一致性和镜像视图,帮助用户更好地管理和同步不同设备或节点上的数据。
以上只是OneFlow概念清单的一部分,了解这些基本概念有助于更深入地理解和使用OneFlow进行深度学习模型的开发和训练。

Kimi
OneFlow是一个开源的机器学习框架,它旨在提供高性能、可扩展的深度学习解决方案。以下是与OneFlow相关的一些关键概念和组件的清单:
-
计算图:OneFlow使用计算图来表示深度学习模型中的操作和数据流动。
-
自动微分:OneFlow支持自动微分,允许用户计算模型参数的梯度,这是训练深度学习模型的关键部分。
-
多GPU支持:OneFlow能够有效地利用多个GPU进行并行计算,加速模型训练。
-
分布式训练:OneFlow提供了分布式训练的支持,可以在多个节点上进行模型训练,进一步提高训练速度。
-
易用性:OneFlow提供了类似于TensorFlow和PyTorch的API,使得开发者可以更容易地迁移和部署模型。
-
灵活性:OneFlow允许用户自定义操作和层,提供了灵活性来实现自定义的机器学习算法。
-
模型并行:OneFlow支持模型并行,即将模型的不同部分放置在不同的设备上进行训练。
-
数据并行:OneFlow也支持数据并行,允许同时在多个GPU上训练相同的模型副本。
-
图优化:OneFlow对计算图进行优化,以提高执行效率和减少资源消耗。
-
资源管理:OneFlow提供了资源管理工具,帮助用户优化硬件资源的使用。
-
社区支持:作为一个开源项目,OneFlow有一个活跃的社区,用户可以参与贡献代码、分享经验和解决问题。
-
跨平台:OneFlow支持在多种硬件和操作系统上运行,包括Linux、Windows等。
-
模型库:OneFlow提供了丰富的预训练模型和模型库,方便用户快速实现和测试常见的深度学习任务。
-
工具和扩展:OneFlow配备了多种工具和扩展,如可视化工具、模型分析工具等,帮助用户更好地开发和调试模型。
-
文档和教程:OneFlow提供了详细的文档和教程,帮助新用户快速上手。
OneFlow的设计目标是提供一个高性能、易于使用的深度学习平台,尤其适合需要大规模并行计算和分布式训练的场景。随着深度学习技术的不断发展,OneFlow也在不断更新和完善其功能。



![[随记]Mac安装Docker及运行开源Penpot](https://img-blog.csdnimg.cn/direct/941b70002d5e44cba1512672f6999975.png)