文章目录
- 背景描述
- 分析
- 解决
- 代码参考
- neo4j 工具类
- Neo4jDriver
- 知识图谱构建效果
- GuihuaNeo4jClass
背景描述
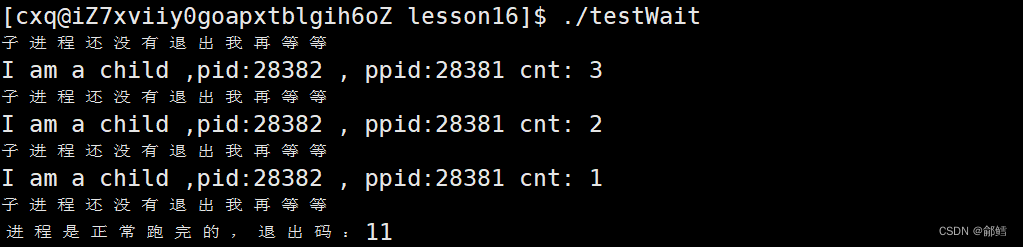
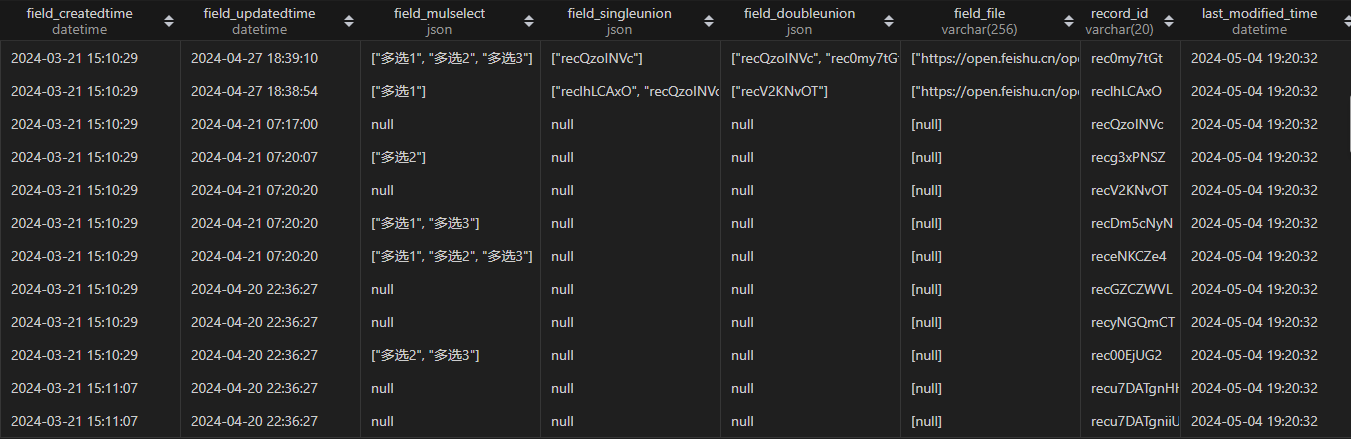
使用 tqdm 显示,处理的速度;
笔者使用 py2neo库,调用 neo4j 的API 完成节点插入;
有80万条数据需要插入到neo4j图数据中,在前期处理速度200条每秒,随着程序的运行处理速度越来越慢,200 -> 100 -> 50 -> 30,速度一直降低到每秒处理30条数据;
如果保持原来的速度,1个小时就处理完了,现在就得花费8个小时才能处理完成;
分析
那么到底是什么原因导致速度会越来越慢?
笔者分析之后是因为:笔者会给节点创建关系,首先需要在neo4j图数据库中查询到该节点,再给该节点创建关系。随着图数据库中的节点数量越来越多,就导致查询时间过长,从而形成了随着程序运行插入节点速度变慢的现象。
解决
有很多种办法解决这个问题:
-
记忆背包
采用记忆背包的办法,将已经创建过的节点,保存在字典中。再给该节点创建关系或者属性时,不再从图谱中查询,而是直接从字典中获取; -
减少重复查询操作
尽量减少多次重复的查询操作。
假如有一个实体的属性表、有一个关系表;为了保证代码的低耦合,通常咱们先往知识图谱中,插入完成属性表;再查询节点,再给该实体插入关系。很明显第二次的节点查询就是重复的查询。
完全可以考虑,一次性就完成节点属性添加和关系链接操作,这就能减少了一次查询操作; -
是否需要创建新实体
通常创建实体时,先在图谱中查询是否有该节点,如果图谱中有则不创建,使用查询得到的节点;
如果咱们只是想表示某个节点他有哪些关系,那么节点不唯一也可以考虑,那么便不再理会图谱中是否已有该节点,直接创建该节点,然后建立关系即可。
代码参考
我使用下述代码,一次性完成属性添加、孩子节点创建与关系链接;从而实现减少图谱的查询操作;
实现了将原本需要耗费8个小时以上的时间,缩短到2个小时完成neo4j图数据库的插入;
neo4j 工具类
我写的neo4j 工具类如下
Neo4jDriver: 可以直接拿去使用;GuihuaNeo4jClass: 笔者自己项目的一个类,无法直接供大家使用,供大家参考;
Neo4jDriver
import json
from dataclasses import dataclassfrom py2neo import Graph, Node, NodeMatcher, RelationshipMatcher, Relationshipfrom settings import domain_class_name, summary_class_name, ner_schema# 连接到Neo4j数据库
class Neo4jDriver:def __init__(self, url, username, password):self.graph = Graph(url, auth=(username, password))self.node_matcher = NodeMatcher(self.graph)self.relationship_matcher = RelationshipMatcher(self.graph)def query_node(self, class_, **kwargs):if node := self.node_matcher.match(class_, **kwargs):# 节点存在,则获取return node.first()def create_query_node(self, class_, **kwargs):"""不创建重复节点"""# 节点存在,则获取if node := self.query_node(class_, **kwargs):return node# 节点不存在,则创建node = Node(class_, **kwargs)self.graph.create(node)return nodedef create_node(self, class_, **kwargs):node = Node(class_, **kwargs)self.graph.create(node)return nodedef query_relationship(self, start_node, rel, end_node):r = self.relationship_matcher.match([start_node, end_node], r_type=rel)return r.first()def create_query_relationship(self, start_node, rel, end_node):if r := self.query_relationship(start_node, rel, end_node):return rself.graph.create(Relationship(start_node, rel, end_node))def create_relationship(self, start_node, rel, end_node):self.graph.create(Relationship(start_node, rel, end_node))
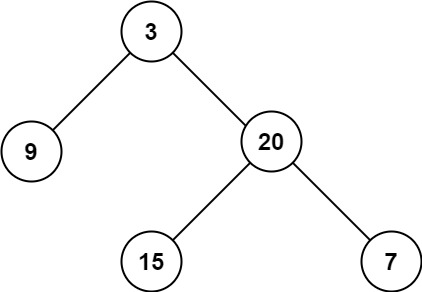
知识图谱构建效果
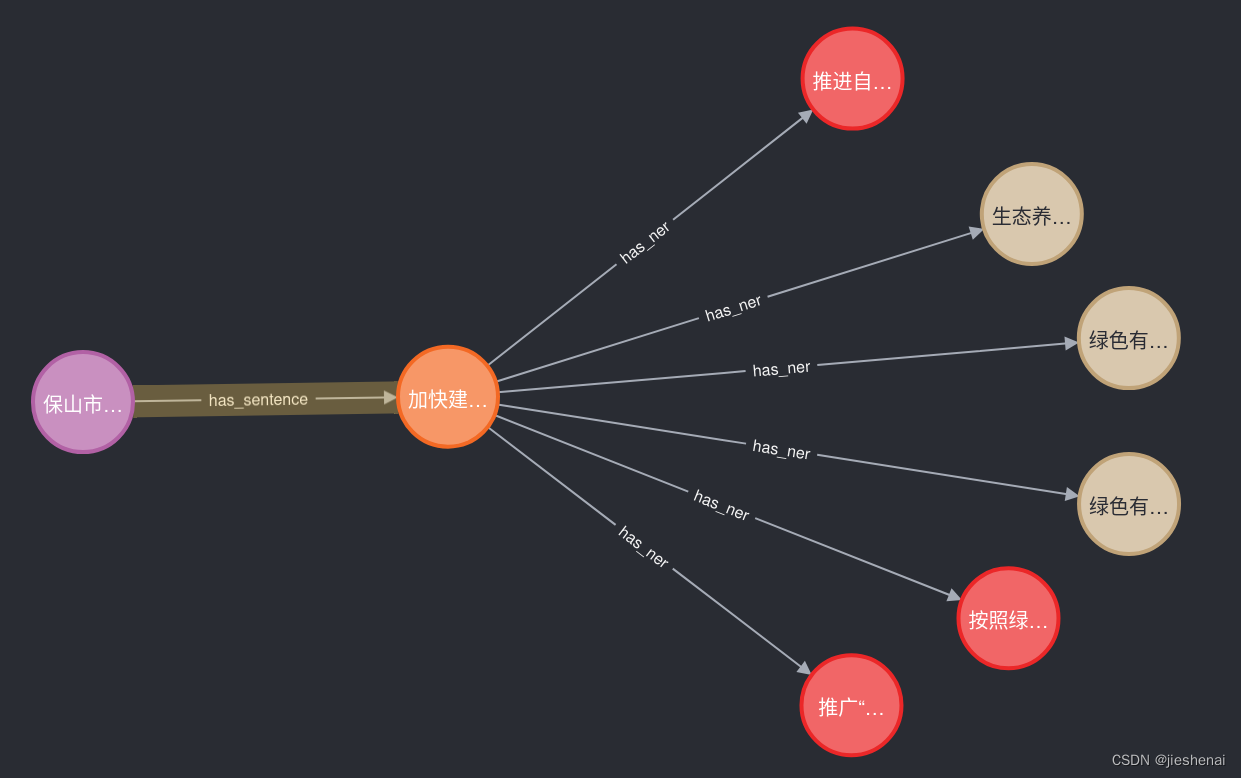 上图的schema如下:
上图的schema如下:
保山市: file
加快建...是:sentence
最右侧的一列节点是sentence的下面的实体
GuihuaNeo4jClass
简要给大家分享一下,编写GuihuaNeo4jClass的思路:
all_file_node = {}
all_sents_node = {}
all_ner_node = {} # key: (ner_class, name)
如下字典为所有 GuihuaNeo4jClass 实例共有(都可以访问)的字典,用于存储在构建neo4j的过程中,创建的一些节点,这样就无需走neo4j的查询,直接走本地字典的查询,速度会快一点;
下述为创建GuihuaNeo4jClass类,初始化时,需要传入的一些参数:
driver: Neo4jDriver
text: str
prov: str
city: str
filename: str
方法讲解:
get_file_node
def get_file_node(self):# 首先在self.all_file_node,查询是否已经有该节点,如果有则直接从字典获取该节点if self.filename in self.all_file_node.keys():return self.all_file_node[self.filename]# 字典中没有该节点,表示该节点还没有创建过,准备创建该节点# data 字典里面存储的是该节点的一些属性信息data = {"name": self.filename, "prov": self.prov, "city": self.city}self.file_node = self.driver.create_node("file", **data)# 新节点创建完成,将该节点保存到 GuihuaNeo4jClass 的文件字典 self.all_file_node中;# self.all_file_node 是每个实例共享的一个类字典;self.all_file_node[self.filename] = self.file_nodereturn self.file_node
get_sentence_node: 与get_file_node 类似;
add_class: 创建sentence节点,并创建 file -> sentence的关系;
add_ner: 创建在schema定义的一些实体节点,并创建 sentence -> ner_node 的关系;
@dataclass()
class GuihuaNeo4jClass:all_file_node = {}all_sents_node = {}all_ner_node = {} # key: (ner_class, name)driver: Neo4jDrivertext: strprov: strcity: strfilename: strdef get_file_node(self):if self.filename in self.all_file_node.keys():return self.all_file_node[self.filename]data = {"name": self.filename, "prov": self.prov, "city": self.city}self.file_node = self.driver.create_node("file", **data)# saveself.all_file_node[self.filename] = self.file_nodereturn self.file_nodedef get_sentence_node(self, **kwargs):if self.text in self.all_sents_node.keys():return self.all_sents_node[self.text]for key in kwargs.keys():assert key in [domain_class_name, summary_class_name]data = {"sentence": self.text,}data.update(kwargs)node = self.driver.create_node("sentence", **data)self.sent_node = node# saveself.all_sents_node[self.text] = self.sent_nodereturn self.sent_nodedef add_class(self, domain_info, summary_info):self.file_node = self.get_file_node()# 给file下面添加text, rel: has_reldomain_output = domain_info.outputs[0].textsummary_output = summary_info.outputs[0].textclass_data = {domain_class_name: domain_output,summary_class_name: summary_output,}self.sent_node = self.get_sentence_node(**class_data)self.driver.create_relationship(self.file_node, "has_sentence", self.sent_node)def add_ner(self, ner_info):"""给文本句创建节点建立一个静态的 llm_ner_label"""try:llm_ner_label = ner_info.outputs[0].textllm_ner_label = json.loads(llm_ner_label)except:returnif not isinstance(llm_ner_label, dict):returnfor key, values in llm_ner_label.items():if not key in ner_schema:continuefor name in values:if (key, name) in self.all_ner_node.keys():ner_node = self.all_ner_node[(key, name)]else:ner_node = self.driver.create_node(key, name=name)# saveself.all_ner_node[(key, name)] = ner_nodeself.driver.create_relationship(self.sent_node, 'has_ner', ner_node)