微调模型是为了让模型在特殊领域表现良好,帮助其学习到专业术语等。
本文采用llama_index框架微调BGE模型,跑通整个流程,并学习模型微调的方法。
已开源:https://github.com/stay-leave/enhance_llm
一、环境准备
Linux环境,GPU L20 48G,Python3.8.10。
pip该库即可。
二、数据准备
该框架实现了读取各种类型的文件,给的示例就是pdf。
因此准备了一些网络舆情相关的论文pdf,选择70%作为训练数据,剩下作为验证数据。都放在data文件夹下。

三、微调脚本编写
1.读取数据
使用SimpleDirectoryReader类读取文件。
读取到文本后,使用SentenceSplitter将一个很长的文档切分为若干块。
每一块设置的有token数和重叠token数,在
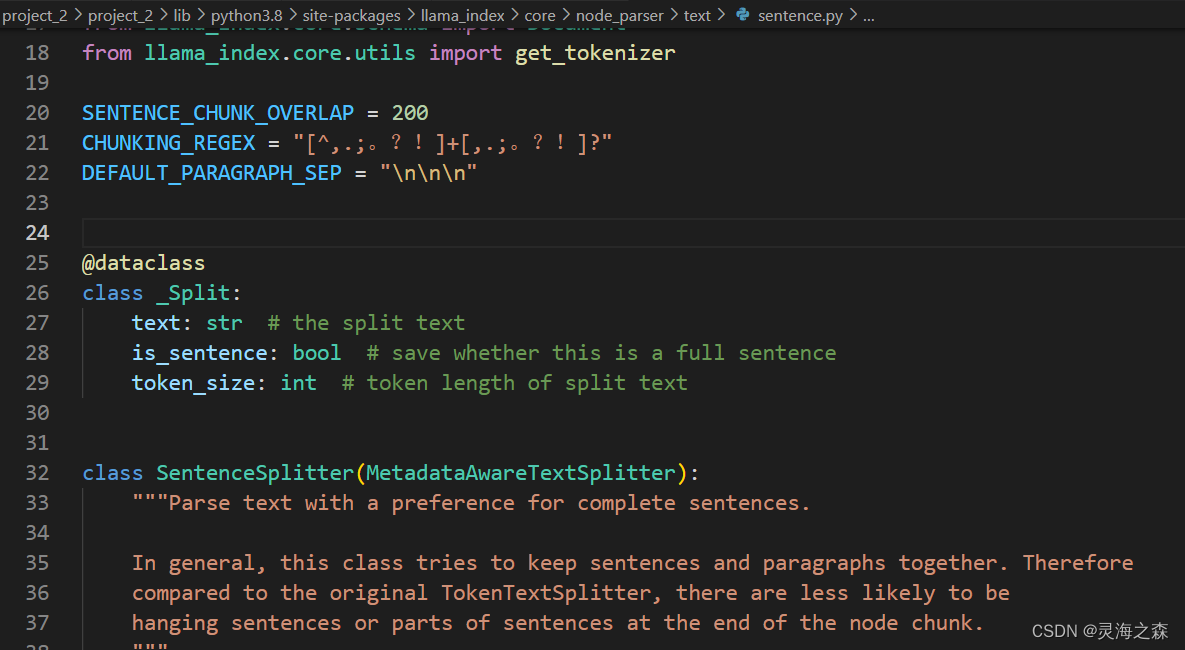 可以自选,默认的chunk_size大小没找到在哪,重叠的是200.
可以自选,默认的chunk_size大小没找到在哪,重叠的是200.
 以上是库的源码实现,我们调用是很简单的。VAL_CORPUS_FPATH 我一开始以为是在load_corpus里的某个类自动保存,结果根本没有。所以自己写了导出为json的函数,是将其text数据保存了。
以上是库的源码实现,我们调用是很简单的。VAL_CORPUS_FPATH 我一开始以为是在load_corpus里的某个类自动保存,结果根本没有。所以自己写了导出为json的函数,是将其text数据保存了。
# 源文件 列表
my_list = [i for i in os.listdir('project_2/data') if i.endswith('pdf')]
# 随机抽取70%的数据,作为训练集
random.shuffle(my_list) # 打乱
num_to_sample = int(len(my_list) * 0.7) # 阈值
# 构造本地文件路径
training_set = [f"project_2/data/{file}" for file in my_list[:num_to_sample]] # 训练集文件list
validation_set = [f"project_2/data/{file}" for file in my_list[num_to_sample:]] # 验证集文件list# 最终形成的训练和验证语料
TRAIN_CORPUS_FPATH = 'project_2/data/corpus/train_corpus.json'
VAL_CORPUS_FPATH = 'project_2/data/corpus/val_corpus.json'# 读取pdf数据,节点
def load_corpus(files, verbose=False):if verbose:print(f"正在加载文件 {files}")reader = SimpleDirectoryReader(input_files=files)docs = reader.load_data()if verbose:print(f"已加载 {len(docs)} 个文档")parser = SentenceSplitter()nodes = parser.get_nodes_from_documents(docs, show_progress=verbose)if verbose:print(f"已解析