目录
- 线性模型
- 衡量预估质量
- 训练数据
- 参数学习
- 训练损失
- 最小化损失来学习参数
- 显式解
- 总结
- 基础优化
- 梯度下降
- 选择学习率
- 小批量随机梯度下降
- 选择批量大小
- 总结
- 线性回归的从零开始实现
- 实现一个函数读取小批量效果展示
- 这里可视化看一下
- 线性回归从零开始实现
- 线性回归的简洁实现效果展示
- 线性回归的简洁实现
- 问题总结
线性模型

线性模型可以看做是单层神经网络

衡量预估质量

训练数据

参数学习
训练损失
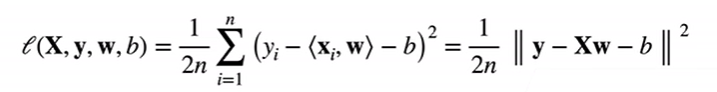
这里的b应该加粗,原先b是标量然后通过广播机制变为一列,即向量b。
最小化损失来学习参数
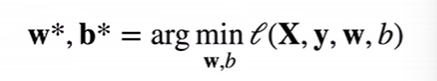
显式解
加入一列全一的特征,加入X中。即:
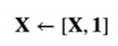
将偏差加入权重。即:
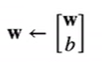
损失函数:
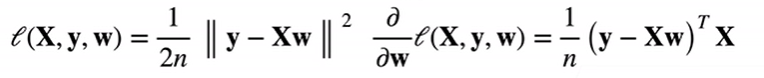
示范过程:
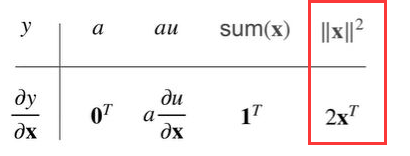
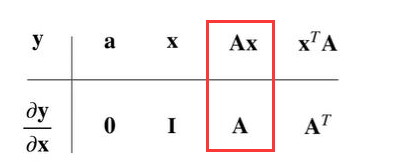
因为是线性模型:所以损失是凸函数,所以最优解满足
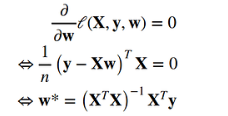
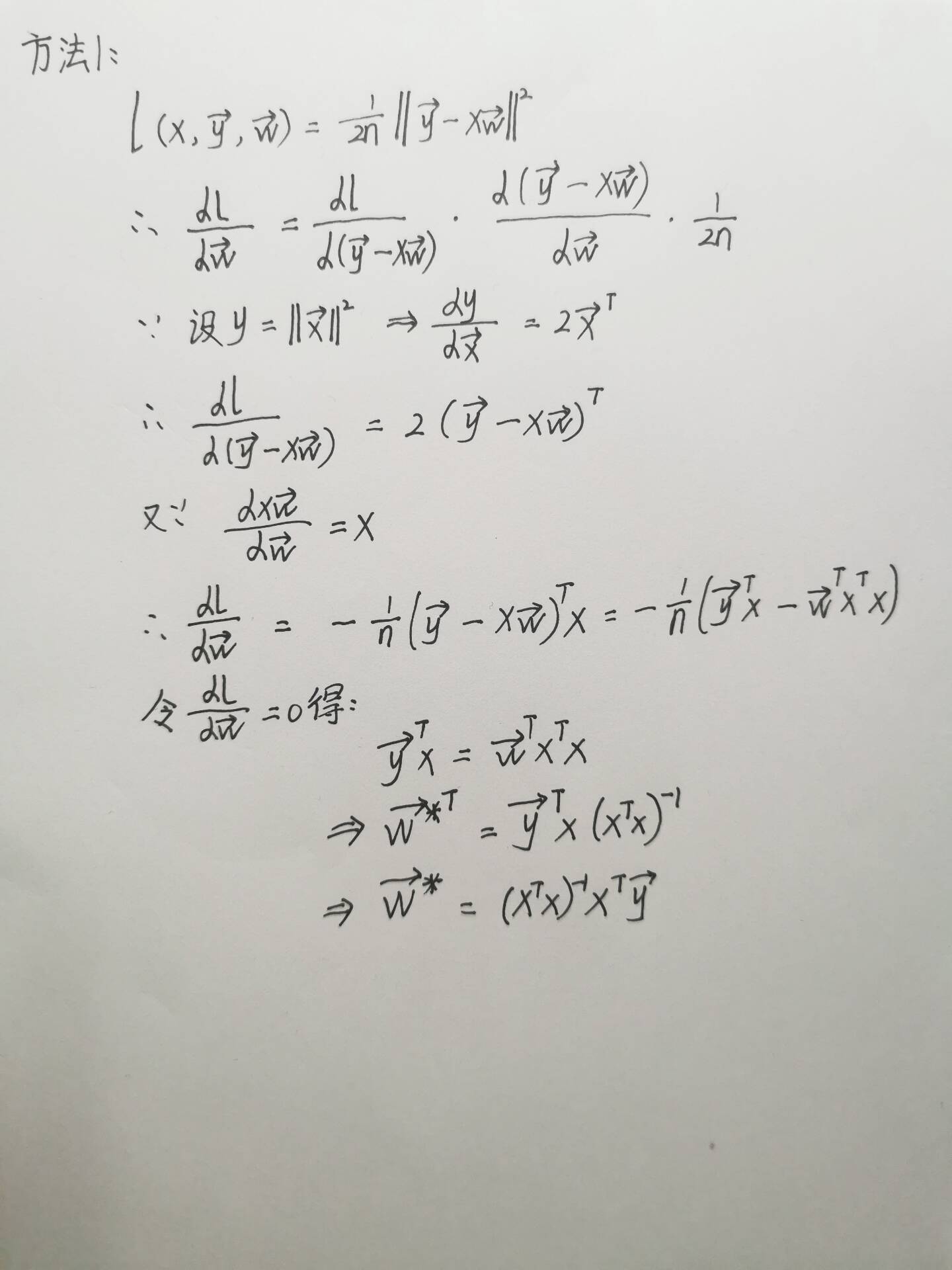
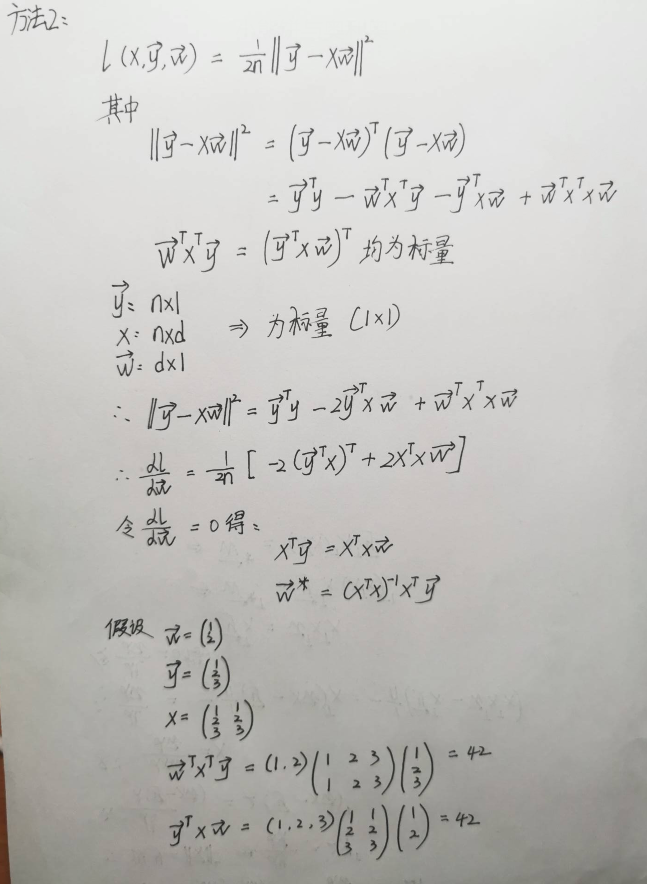

总结
1、线性回归是对n维输入的加权,外加偏差。2、使用平方损失来衡量预测值和真实值的差异。
3、线性回归有显示解。
4、线性回归可以看做是单层神经网络。
基础优化
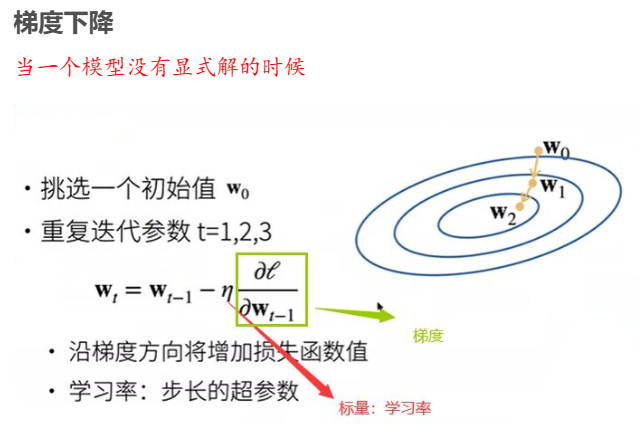
梯度下降
当一个模型没有显式解的时候
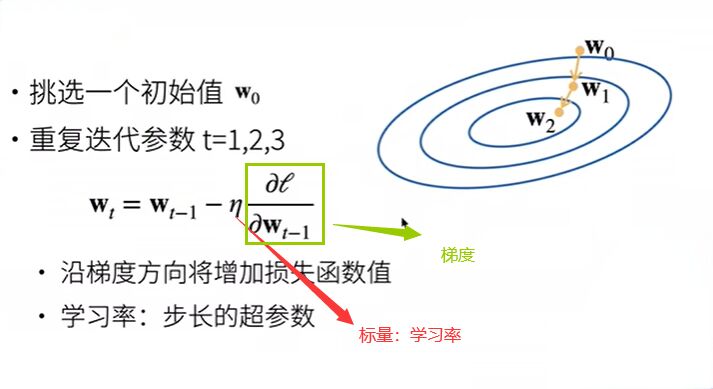
选择学习率
小批量随机梯度下降

选择批量大小

总结

线性回归的从零开始实现
我们将从零开始实现整个方法,包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。
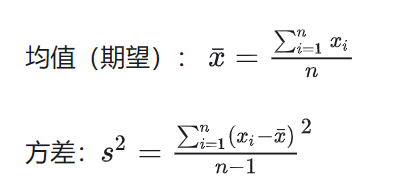
import torch
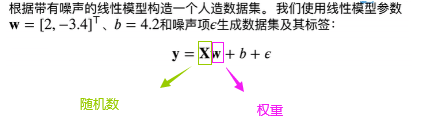
def synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声。"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0], '\nlabel:', labels[0])
正态分布函数:normal()
1、normal(0,1,(num_examples,len(w)))表示均值为0,方差为1的随机数,它的大小是说有num_examples个样本,列数是w的长度
2、矩阵乘法:matmul()
3、y.reshape((-1, 1)中的-1表示维度的大小自动计算,第二个维度是1表示新数组将有一个列。
例如:
import torch
y = torch.tensor([1, 2, 3, 4, 5])
print(y.reshape((-1, 1)))
结果:
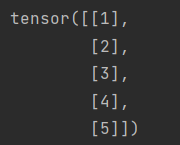
在这个例子中,-1被自动替换为5,因为y有5个元素,并且你想要一个只有一列的二维数组。所以,根据另一个维度(这里是1)自动计算这个维度的大小。
4、features是特征,features中的每一行都包含一个二维数据样本,labels中的每一行包含一维标签值(一个标量)

import torch
from d2l import torch as d2l
import matplotlib.pyplot as pltdef synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声。"""X = torch.normal(0, 1, (num_examples, len(w)))#方差为0,均值为1,num_examples个样本,列数是w的长度y = torch.matmul(X, w) + b #这里的y是一个行向量y += torch.normal(0, 0.01, y.shape) #意思是给 y 加上一个符合正态分布的随机噪声。torch.normal(0, 0.01, y.shape) 生成一个与 y 形状相同的张量,#其中的元素是从均值为 0、标准差为 0.01 的正态分布中随机抽取的。#然后,这个随机生成的张量会被加到 y 上。return X, y.reshape((-1, 1)) #这里的y目的是转换为列向量true_w = torch.tensor([2, -3.4])
true_b = 4.2
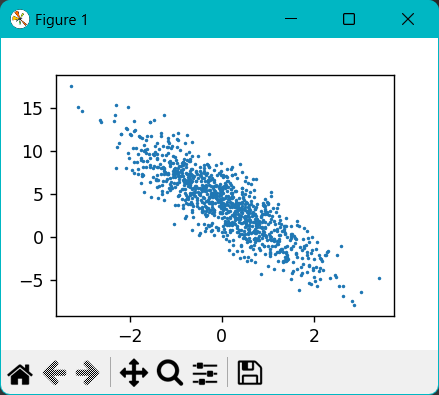
features, labels = synthetic_data(true_w, true_b, 1000)d2l.set_figsize() #用于设置Matplotlib图像的大小,可以接受两个参数宽度和高度
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1) #detach()分离出数值,不再含有梯度
plt.show()
d2l.plt.scatter(): 使用 scatter 函数绘制散点图。
第一个参数是x轴的数据(即 features 的第二列)。
第二个参数是y轴的数据(即 labels)。
第三个参数1: 这是散点的大小。在这里,所有散点的大小都被设置为1。
features[:, 1].detach().numpy():
features[:, 1]:从 features 数组中选择所有行的第二列
.detach(): features 是一个PyTorch张量,.detach() 方法用于创建一个新的张量,从当前计算图中分离出来,这样它就不会计算梯度。这对于绘图来说通常是必要的,因为我们不需要对绘图数据进行反向传播。
.numpy(): 将PyTorch张量转换为NumPy数组,因为 matplotlib 通常与NumPy数组一起使用。
结果:
实现一个函数读取小批量效果展示
import random
import torchdef synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声。"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)def data_iter(batch_size, features, labels):num_examples = len(features) #多个样本indices = list(range(num_examples)) #从0到n-1# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices) # 将列表中的元素打乱顺序for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]#yield相当于返回一个可迭代对象batch_size = 10
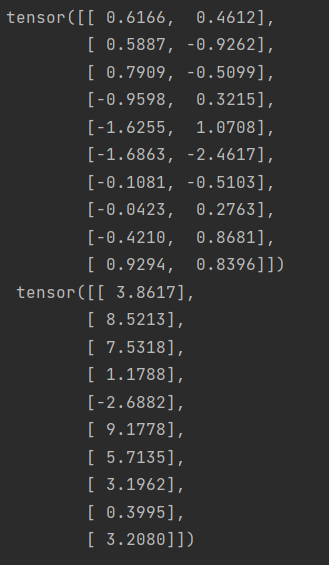
for X, y in data_iter(batch_size, features, labels):print(X, '\n', y)breakindices 是一个从0到 num_examples-1 的整数列表,代表所有样本的索引。
i:min(i + batch_size, num_examples) 是一个切片操作,用于从 indices 中选择一部分索引。从 i 开始,选取到 i + batch_size 或者 num_examples(取两者中较小的一个)结束。是为了确保在最后一个批次中不会超出索引范围。例如,如果总共有1000个样本,批大小为100,当 i 为900时,i + batch_size 会超出索引范围,因此 min(i + batch_size, num_examples) 会确保只选取到最后一个索引。
将上面通过切片操作得到的索引列表转换为一个PyTorch张量
data_iter 函数是一个数据迭代器,它接收批大小 batch_size、特征 features 和标签 labels 作为输入。它首先计算样本数量 num_examples,并创建一个从0到 num_examples-1 的索引列表。然后,它打乱索引列表的顺序,以便在每次迭代时随机选择样本。最后,它使用这些随机索引从特征和标签中抽取小批量数据,并使用 yield 语句返回这些数据。yield 使得这个函数成为一个生成器,每次调用时返回一批数据。设置批大小为10,并使用 data_iter 函数迭代数据和标签。在循环中,每次迭代都会打印出一个小批量的特征 X 和标签 y。由于循环后面有一个 break 语句,所以只会打印出第一批数据。
结果:
这里可视化看一下
import random
import torch
from d2l import torch as d2l
import matplotlib.pyplot as pltdef synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声。"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices) # 将列表中的元素打乱顺序for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]batch_size = 10
for X, y in data_iter(batch_size, features, labels):print(X, '\n', y)break# 获取一个批次的数据
X_batch, y_batch = next(data_iter(batch_size, features, labels))# 绘制批次数据的散点图
d2l.plt.scatter(X_batch[:, 0].numpy(), y_batch.numpy())
d2l.plt.show()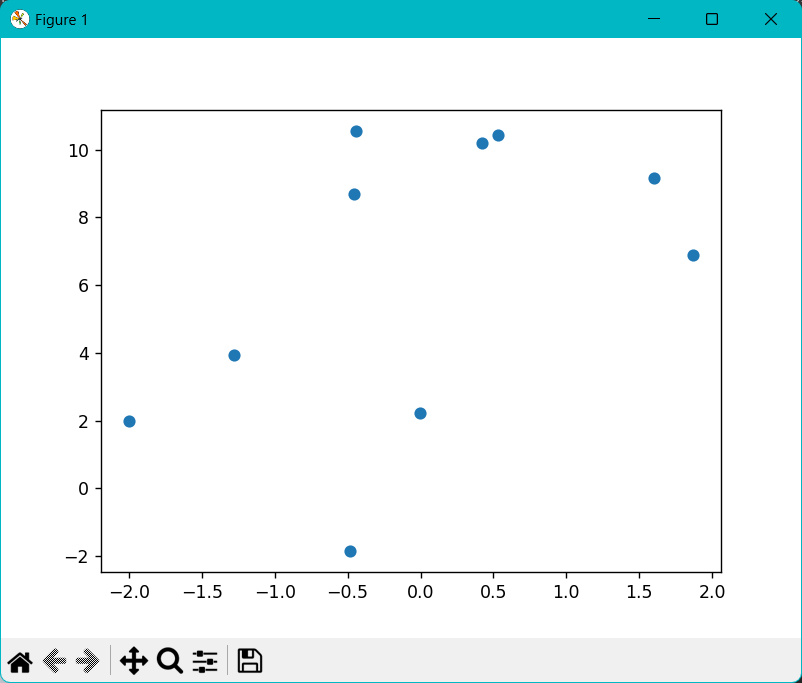
线性回归从零开始实现
import random
import torchdef synthetic_data(w, b, num_examples):"""生成y=Xw+b+噪声。"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices) # 将列表中的元素打乱顺序for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]batch_size = 10# 定义初始化模型参数,需要w,b进行更新,所以才将requires_grad设置为True
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
#size=(2, 1)生成的张量 w 是一个形状为 2x1 的二维张量,即它有 2 行和 1 列。
b = torch.zeros(1, requires_grad=True)
#这里的 1 意味着 b 是一个一维张量,它只有一个元素,并且这个元素的值为 0。
#在 PyTorch 中,一维张量通常可以看作是一个向量。
#因此,b 是一个只包含一个元素(值为 0)的向量。# 定义模型
def linreg(X, w, b):"""线性回归模型。"""return torch.matmul(X, w) + b# 定义损失函数,其中y_hat是预测值y是真实值
def squared_loss(y_hat, y):"""均方损失。均方误差公式"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2# 定义优化算法
def sgd(params, lr, batch_size):"""小批量随机梯度下降。"""with torch.no_grad():#不需要计算梯度,使用 torch.no_grad() 可以减少内存消耗,并提高运行速度。for param in params:#其中param可能是w也可能是bparam -= lr * param.grad / batch_sizeparam.grad.zero_()lr = 0.03
num_epochs = 3 #意思是把整个数据扫三遍
net = linreg #定义的模型
loss = squared_loss#均方损失
for epoch in range(num_epochs): #每一次对数据扫一遍for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) #一个长为批量大小的损失# 因为’1‘形状是(’batch_size‘,1),而不是一个标量。'1'中的所有元素被加到# 并以此计算关于['w','b']的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch{epoch + 1},loss{float(train_l.mean()):f}')#:f确保train_l.mean()的结果以浮点数形式被格式化并嵌入到字符串中
print(f'w的估计误差:{true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b - b}')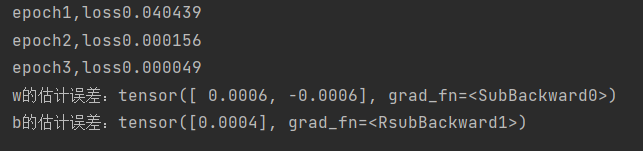
说明 param -= lr * param.grad / batch_size中param.grad / batch_size的含义。是用来计算平均梯度的。
示例:
import torchX = torch.tensor([[1.0, 2.0], [2.0, 3.0], [3.0, 4.0]])
w = torch.tensor([[1.0], [2.0]], dtype=torch.float32, requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
y = torch.tensor([[0.0], [1.0], [2.0]])y_hat = torch.matmul(X, w) + b
l = (y_hat - y)**2 / 2
l.sum().backward()print(w.grad)
print(b.grad)
运行结果:
tensor([[46.],[67.]])
tensor([21.])
计算过程:

计算损失函数时,对它调用.backward()会将自动求导计算的梯度累积存在param.grad中。当一个批次包含batch_size个样本时,并且每个样本都贡献一个梯度给模型参数。那么调用backward()后,paramgrad中存储的就是这些梯度的和。这就是为什么在更新参数时,需要将param.grad除以batch_size。这样做可以得到一个平均梯度。
这样,w.grad / batch_size和b.grad / batch_size相当于在batch_size中取平均值。
然后这整句公式的含义:是进行梯度下降
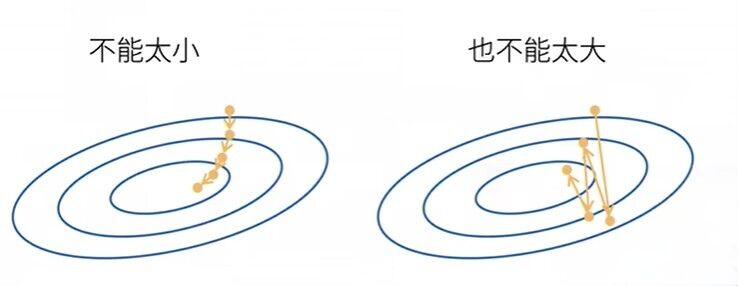
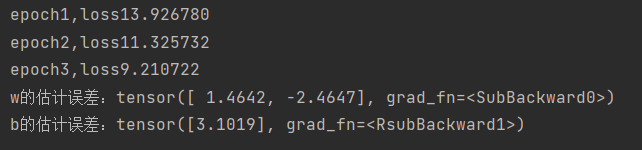
学习率不能太高也不能太低。
当学习率很低时
#当lr = 0.03改为0.001时
lr = 0.001
跑完三次后损失还是很大
多跑几遍看看
#num_epochs由3改为10
num_epochs = 10
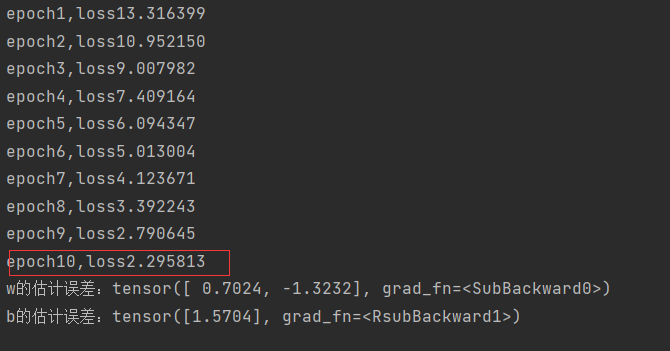
跑完十次后损失还是很大
学习率很高时
#lr 从0.03改为10时
lr = 10
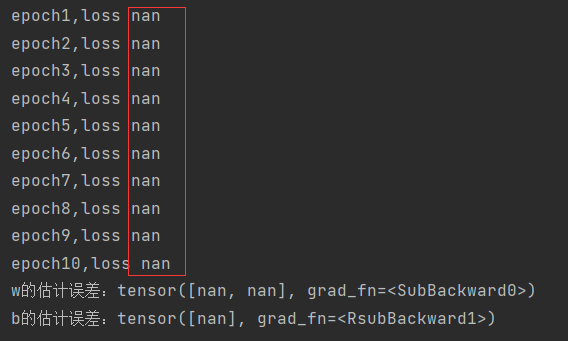
这种情况是求导的时候会除0或者是无限的值,然后超出了浮点类型的计算范围。
线性回归的简洁实现效果展示
import torch
from torch.utils import data
from d2l import torch as d2ldef load_array(data_arrays, batch_size, is_train=True):"""构造一个PyTorch数据迭代器。"""#在PyTorch中,data.TensorDataset是一个用于包装数据张量(tensors)的数据集类。#*data_arrays 是一个解包操作,它将data_arrays这个元组(或列表)中的每个元素作为单独的参数传递给TensorDataset。#data_arrays是一个包含特征张量features和标签张量labels的元组,那么*data_arrays的效果等同于直接传递这两个张量作为参数dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset, batch_size, shuffle=is_train) #每一次随机从中挑选batch_size个样本,并随机打乱顺序true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
batch_size = 10
data_iter = load_array((features, labels),batch_size)
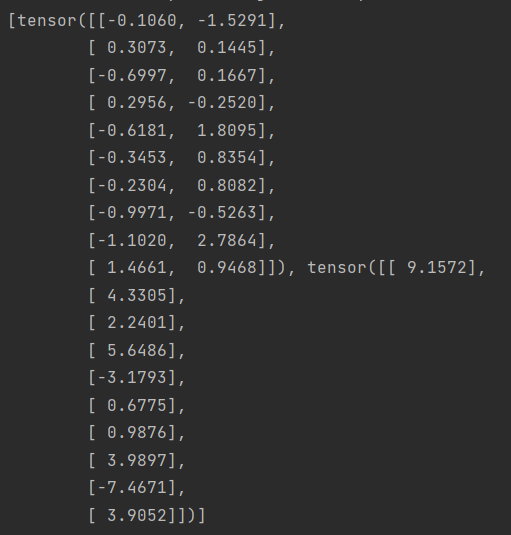
print(next(iter(data_iter)))#iter() 函数用于获取一个迭代器对象。next() 函数用于获取迭代器对象的下一个元素。
结果:
# ’nn‘ 是神经网络的缩写
from torch import nn
#使用框架预定义好的层
net = nn.Sequential(nn.Linear(2, 1))#输入的维度是2,输出的维度是1
#这意味着这个线性层接受一个形状为[batch_size, 2]的张量作为输入,并输出一个形状为[batch_size, 1]的张量。#初始化模型参数
print(net[0].weight.data.normal_(0, 0.01))#net 是一个 nn.Sequential 的实例,它包含了一个 nn.Linear 层。
#.weight表示该层的权重参数。对于 nn.Linear(2, 1),这个权重参数是一个形状为 [2, 1] 的二维张量。
#.data:这是访问张量底层数据的方式。在这里,我们仅用它来初始化权重。
#normal_(0, 0.01):它会将张量的值替换为从均值为0、标准差为0.01的正态分布中抽取的随机值。这里的下划线 _ 表示这是一个原地操作,它会直接修改调用它的张量,而不是返回一个新的张量。
print(net[0].bias.data.fill_(0))#.bias表示该层的偏置参数。对于nn.Linear(2, 1),这个偏置参数是一个形状为[1]的一维张量。
#fill_(0):它会将张量的所有值设置为给定的标量值,这里是0。结果: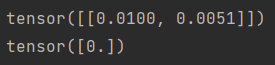
net = nn.Sequential(nn.Linear(2, 1))的使用示例:
import torch
import torch.nn as nn # 定义网络模型
model = nn.Sequential(nn.Linear(2, 1)) # 创建一个输入张量,形状为 [batch_size, 2]
input_tensor = torch.randn(3, 2) # 这里batch_size是3 # 通过网络模型传递输入张量
output_tensor = model(input_tensor) # 输出张量的形状将是 [batch_size, 1]
print(output_tensor.shape) # 输出: torch.Size([3, 1])
线性回归的简洁实现
# ’nn‘ 是神经网络的缩写
import torch.optim
from torch import nn
from torch.utils import data
from d2l import torch as d2ldef load_array(data_arrays, batch_size, is_train=True):"""构造一个PyTorch数据迭代器。"""#在PyTorch中,data.TensorDataset是一个用于包装数据张量(tensors)的数据集类。#*data_arrays 是一个解包操作,它将data_arrays这个元组(或列表)中的每个元素作为单独的参数传递给TensorDataset。#data_arrays是一个包含特征张量features和标签张量labels的元组,那么*data_arrays的效果等同于直接传递这两个张量作为参数dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset, batch_size, shuffle=is_train) #每一次随机从中挑选batch_size个样本,并随机打乱顺序true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
batch_size = 10
data_iter = load_array((features, labels),batch_size)#使用框架预定义好的层
net = nn.Sequential(nn.Linear(2, 1))#输入的维度是2,输出的维度是1
#这意味着这个线性层接受一个形状为[batch_size, 2]的张量作为输入,并输出一个形状为[batch_size, 1]的张量。#初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)#计算均方误差使用的是MSELoss类,也称为平方范数
loss = nn.MSELoss()
#实例化SGD实例,torch.optim.SGD 是一个用于实现随机梯度下降(Stochastic Gradient Descent, SGD)优化算法的类。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)#net.parameters():拿出所有的参数(即权重w和偏置b)。#训练过程代码和从零开始实现类似
num_epochs = 3
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y)#这里net自带了模型参数,不需要w和b弄进去了trainer.zero_grad()#trainer优化器梯度清零l.backward()#这里不需要求和,因为pytorch自动求和了trainer.step()#进行模型的更新和从零开始的sgd函数类似l = loss(net(features), labels)print(f'epoch {epoch + 1}, loss {l:f}')结果: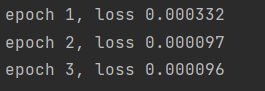
问题总结
1、为啥使用平方损失而不是绝对差值呢
区别不大,但绝对差值是个不可导的函数
2、损失为什么要求平均?
求不求平均本质上没有关系,不求平均梯度的数值有点大,如果使用梯度下降的话,那么不除以n的话,就把学习率除以n。除以n的好处是说:不管批量和样本多大我的梯度都差不多,调学习率好调。
3、线性回归损失函数是不是通常都是MSE(均方损失误差)
是的
4、不管是gd(梯度下降)还是sgd(随机梯度下降)怎么找到合适的学习率?有什么好的方法吗?
两个办法
找到一个对学习率不那么敏感的算法,比如adam。
通过合理的参数的初始化
5、针对batchsize大小的数据集进行网络训练的时候,网络中每个参数更新时的减去的梯度是batchsize中每个样本对应参数梯度求和后取得平均值吗?
是的
6、detach()是什么作用?
告诉不要算梯度了
7、如果样本大小不是批量数的整数倍,那需要随机剔除多余的样本吗?
假设有100个样本,批量大小为60
第一次60,那么剩下40怎么办?
1、普遍做法是拿到一个小的样本,长为40的批量样本
2、把不完整的批量大小扔掉
3、从下一个里面补20个
8、本质上我们为什么要用SGD(随机梯度下降),是因为大部分的实际loss(损失函数)太复杂,推导不出导数为0的解么?只能逐个batch去逼近?
是的
9、l.backward()这里是调用pytorch自定义的back propogation(梯度反向传播)吗?
是的