目录
须知
转置卷积
DCGAN
什么是DCGAN
生成器代码
判别器代码
补充知识
LeakyReLU(x)
torch.nn.Dropout
torch.nn.Dropout2d
DCGAN完整代码
运行结果
图形显示
须知
在讲解DCGAN之前我们首先要了解转置卷积和GAN
关于GAN在这片博客中已经很好的说明了:深度学习之GAN网络-CSDN博客
接下来简单的介绍一下转置卷积。
转置卷积
首先要了解卷积,关于卷积是什么可以看我的这篇博客:深度学习之CNN-CSDN博客
我们的卷积就是一种很典型的下采样方式,他具有可学习的参数,通过不断的训练我们可以达到我们想实现的目的。
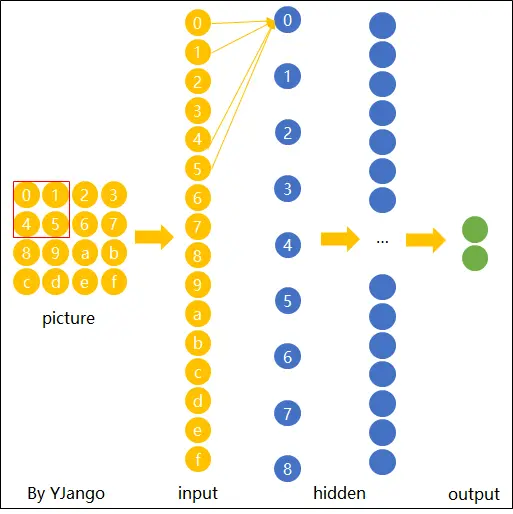
可以看到我们的图片的像素尺寸经过卷积之后缩小了,得到我们所说的特征图。
这个时候我们可以思考一个问题,我们可不可以通过得到的特征图得到我们原来的图像。
答案是可以的,这就用到了我们的转置卷积。
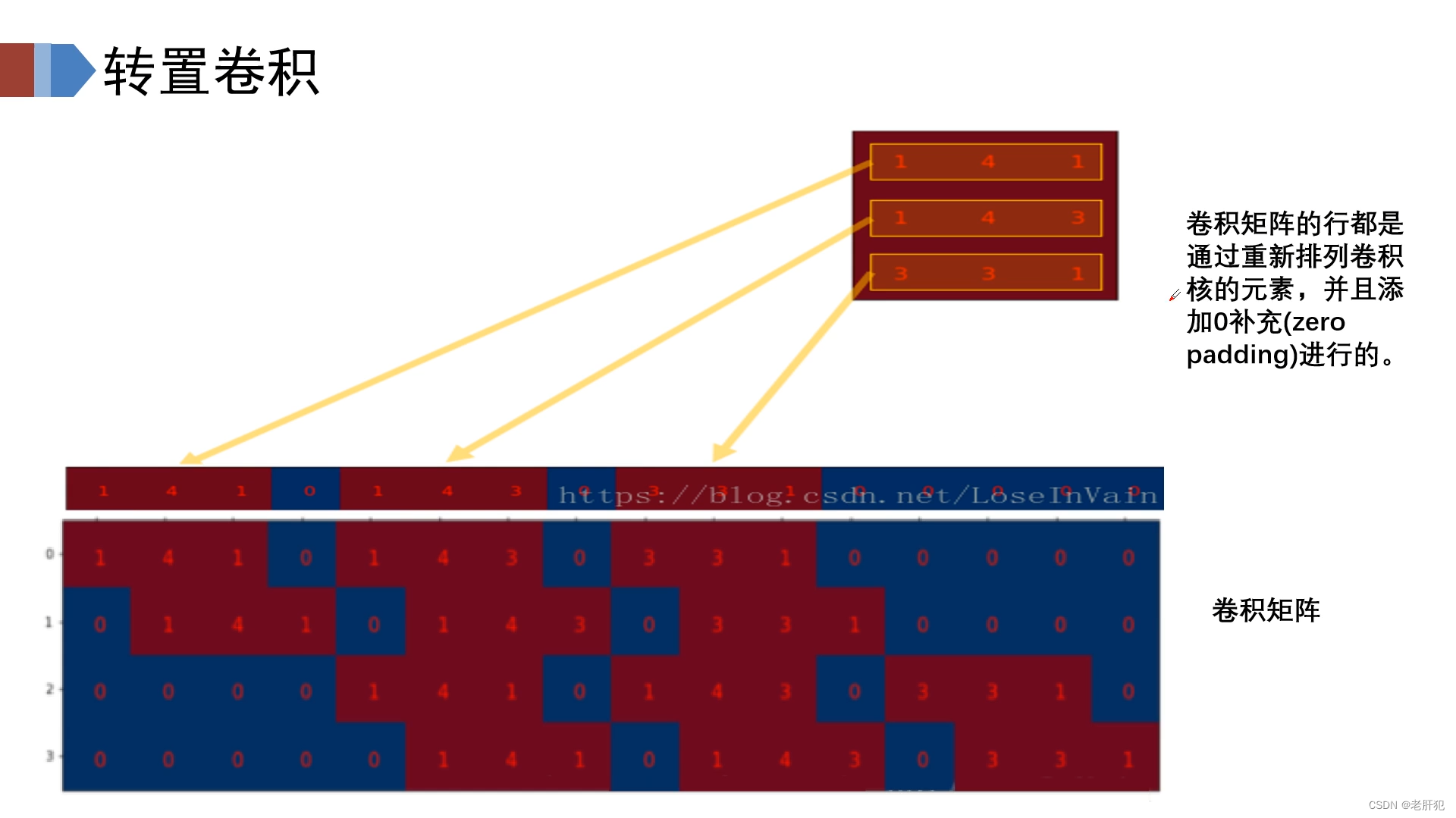
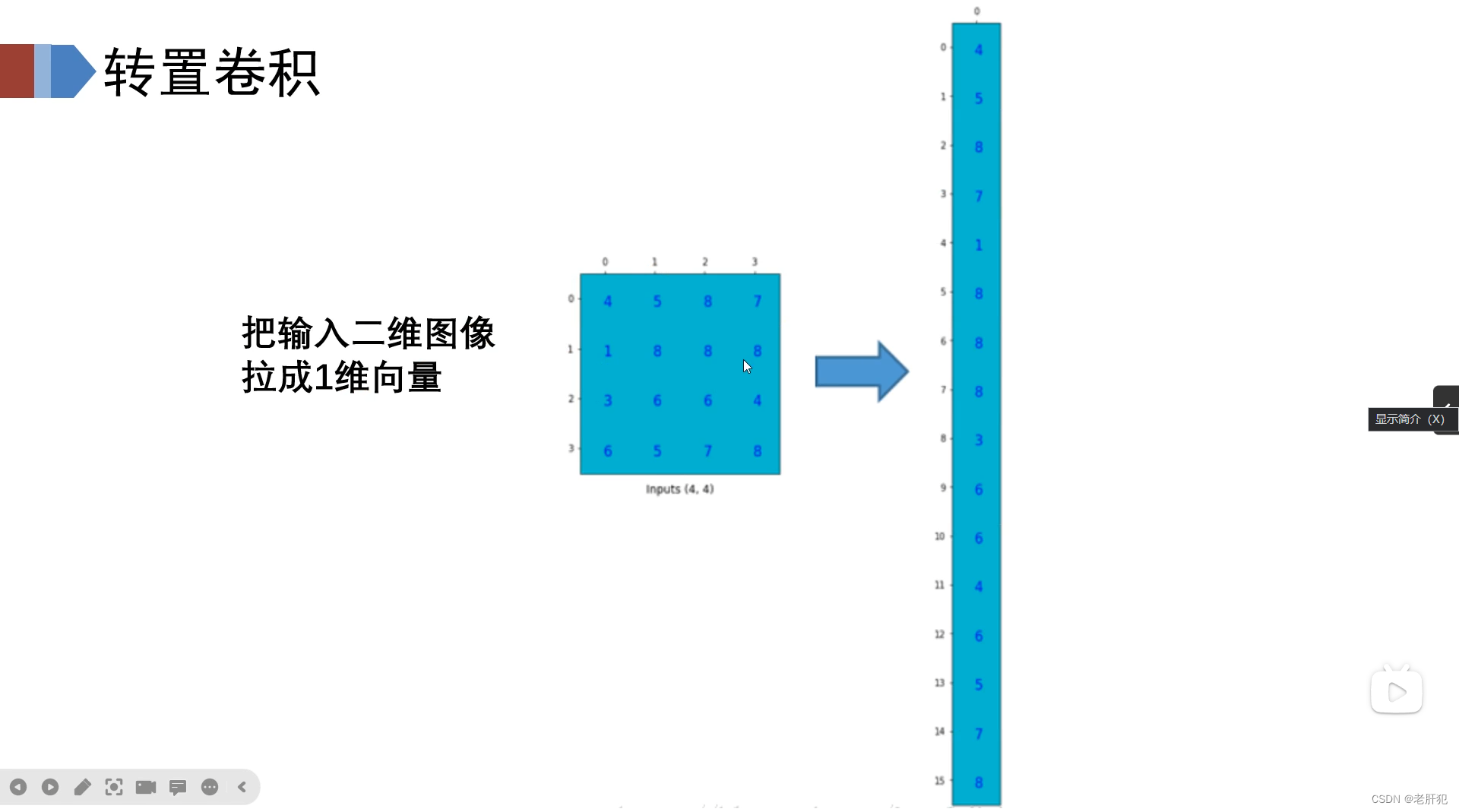
如图所示,我们的卷积核实际上在运行过程中是一个卷积矩阵 ,我们把一个图像数据给拉开,如下图所示
那么卷积操作实际上就是:
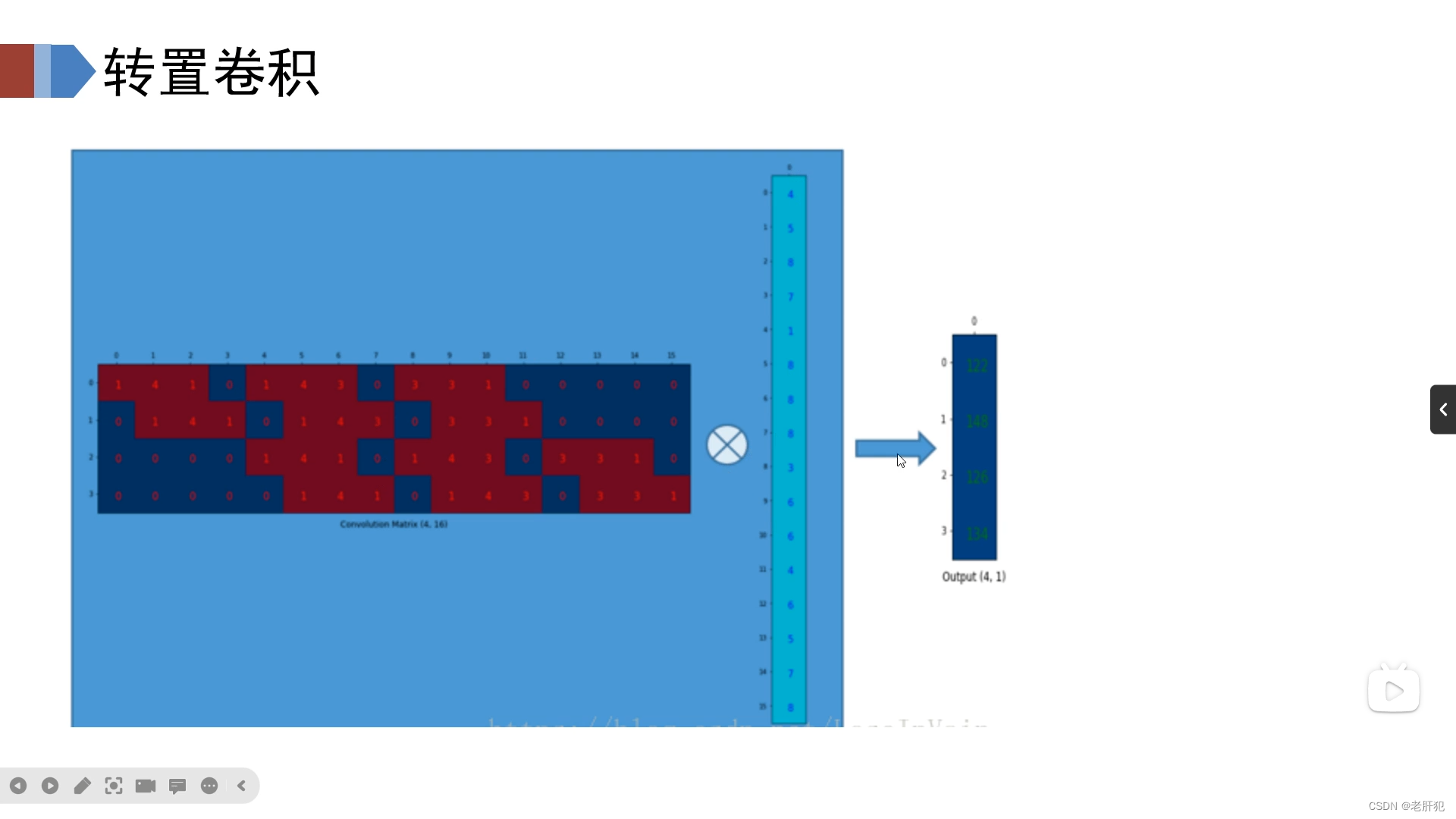 两个矩阵相乘
两个矩阵相乘
我们假设卷积矩阵为B,图像矩阵为A,卷积得到的特征矩阵为C,那么他们满足
A@B=C(@表示矩阵乘法)
那么
我们的B为正交矩阵(这个就不证明了),那么(上图如果用A,B,C表示的话,为:
)
所以对于特征图C我们要是想得到原图A,那么只需要进行C和B的转置矩阵相乘就好。
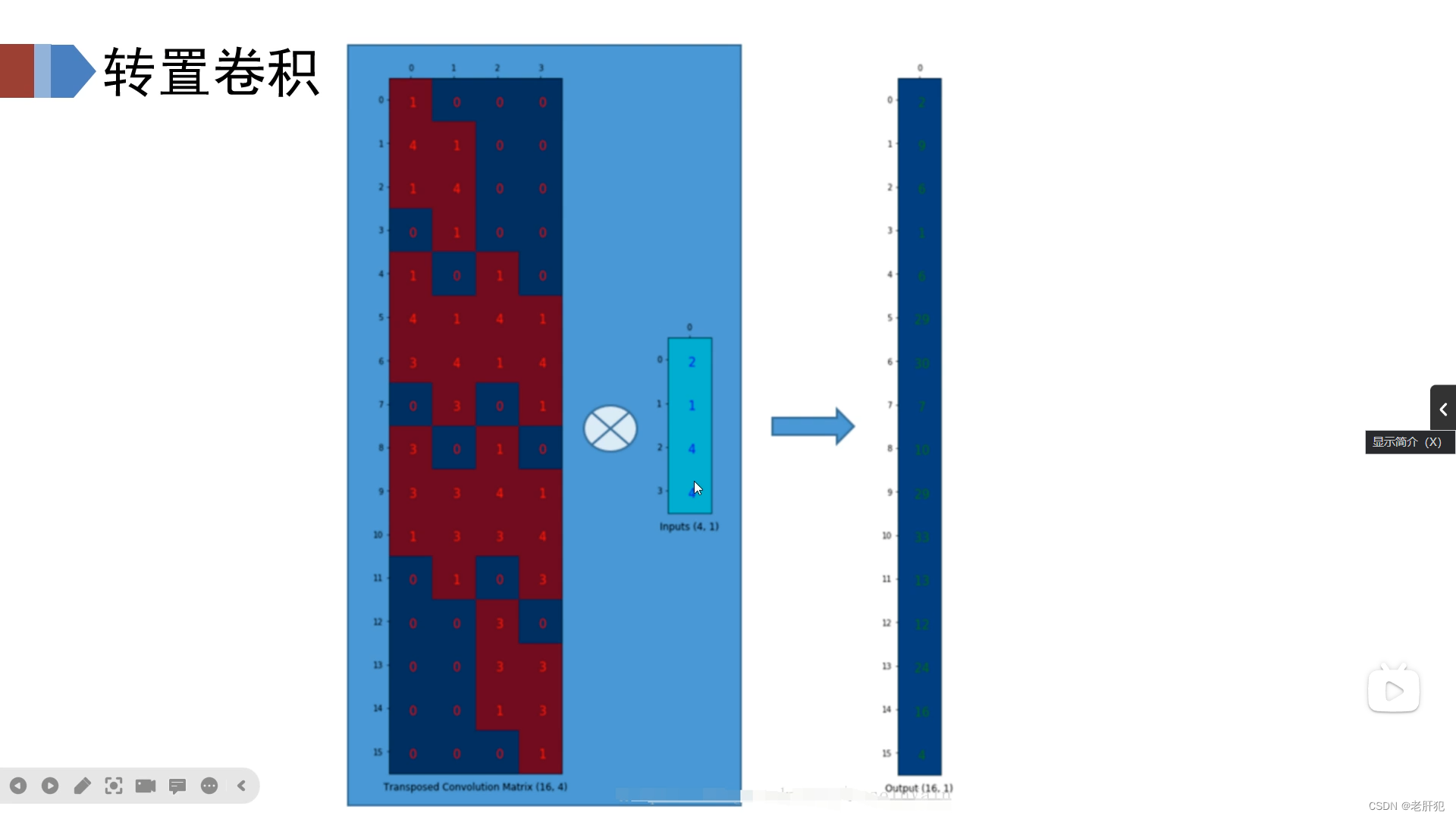
用A,B,C表示
由此得到了我们的转置矩阵,也由此得到了我们的转置卷积。
所以,转置卷积其实就是一种特殊的上采样方式,它里面包含了可控学习的参数,具有极强的实用性。
我们知道卷积的尺寸计算方法为:

w就是输入尺寸,k是过滤器尺寸,p是填充的大小,s是步幅。
我们将该公式换算一下就得到了转置卷积的尺寸计算方法了。
DCGAN
什么是DCGAN
DCGAN,全称是 Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络),是 Alec Radfor 等人于2015年提出的一种模型。该模型在 Original GAN 的理论基础上,开创性地 将 CNN 和 GAN 相结合 以 实现对图像的处理,并提出了一系列对网络结构的限制以提高网络的稳定性。
DCGAN和GAN明显的区别就是,他的生成器使用的是转置卷积层,判别器使用的是卷积层。
论文:[1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (arxiv.org)
在论文中相较于GAN,他主要的变化为:

大致意思为:
第一:在全卷积网络(all convolutional net)上面,用步幅卷积(strided convolutions)替代确定性空间池化函数(deterministic spatial pooling functions)(比如最大池化),让网络自己学习downsampling方式。
第二:取消了全连接层。 比如,使用 全局平均池化(global average pooling)替代 全连接层。global average pooling会降低收敛速度,但是可以提高模型的稳定性。GAN的输入采用均匀分布初始化,可能会使用全连接层(矩阵相乘),然后得到的结果可以reshape成一个4 维度的tensor,然后后面堆叠卷积层即可,在判别器里面,最后的卷积层可以先flatten拉展开为多维向量,然后送入一个sigmoid分类器。
第三:采用了批归一化(Batch Normalization), 即将每一层的输入变换到0均值和单位方差(或者说转变到[0,1]范围内。)。
BN 被证明是深度学习中非常重要的 加速收敛 和 减缓过拟合 的手段。这样有助于解决 初始化不良 问题并帮助梯度走向更深的网络。防止生成器把所有随机输入都整合到一个点。
但是实践表明,将所有层都进行Batch Normalization,会导致样本震荡和模型不稳定,因此 只对生成器(G)的输出层和鉴别器(D)的输入层使用BN。
Leaky Relu 激活函数: 生成器(G),输出层使用tanh 激活函数,其余层使用relu 激活函数。鉴别器(D),都采用leaky rectified activation。
DCGAN生成器G的结构如下图所示:

生成器代码
class Generator(torch.nn.Module):def __init__(self):super(Generator,self).__init__()self.linear1=torch.nn.Linear(100,7*7*256)self.bn1=torch.nn.BatchNorm1d(7*7*256)self.uconv1=torch.nn.ConvTranspose2d(256,128,kernel_size=(3,3),padding=1)self.bn2=torch.nn.BatchNorm2d(128)self.uconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4),stride=2, padding=1)self.bn3 = torch.nn.BatchNorm2d(64)self.uconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1)def forward(self,x):#print('--------------------------------------')#print('x.shape:',x.shape)x=F.relu(self.linear1(x)) #torchsize([,])# print('x.shape:',x.shape)x=self.bn1(x)x=x.view(-1,256,7,7)#64,256,7,7# print('x.shape:',x.shape)x=F.relu(self.uconv1(x))#print('x.shape:',x.shape)x = self.bn2(x)#print('x.shape:', x.shape)x = F.relu(self.uconv2(x))#print('x.shape:', x.shape)x = self.bn3(x)#print('x.shape:', x.shape)x = torch.tanh(self.uconv3(x))#print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])return x判别器D的结构如下图所示:
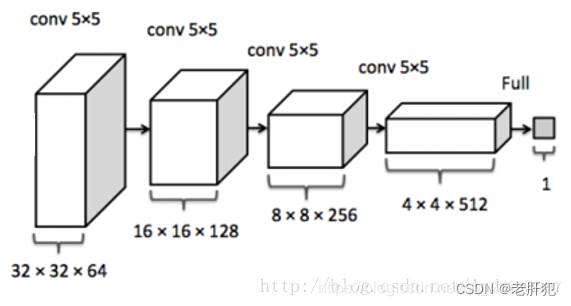
判别器代码
#判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):def __init__(self):super(Discraiminator,self).__init__()self.conv1=torch.nn.Conv2d(1,64,3,2)self.conv2=torch.nn.Conv2d(64,128,3,2)self.bn=torch.nn.BatchNorm2d(128)self.fc=torch.nn.Linear(128*6*6,1)def forward(self,x):# print('--------------------')#print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])x=F.dropout2d(F.leaky_relu(self.conv1(x)),p=0.3)# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])x = F.dropout2d(F.leaky_relu(self.conv2(x)),p=0.3)#print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])x=self.bn(x)x=x.view(-1,128*6*6)#print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])x=torch.sigmoid(self.fc(x))#print('x.shape:', x.shape)#torch.size([64,1])return x其余和GAN一样。
补充知识
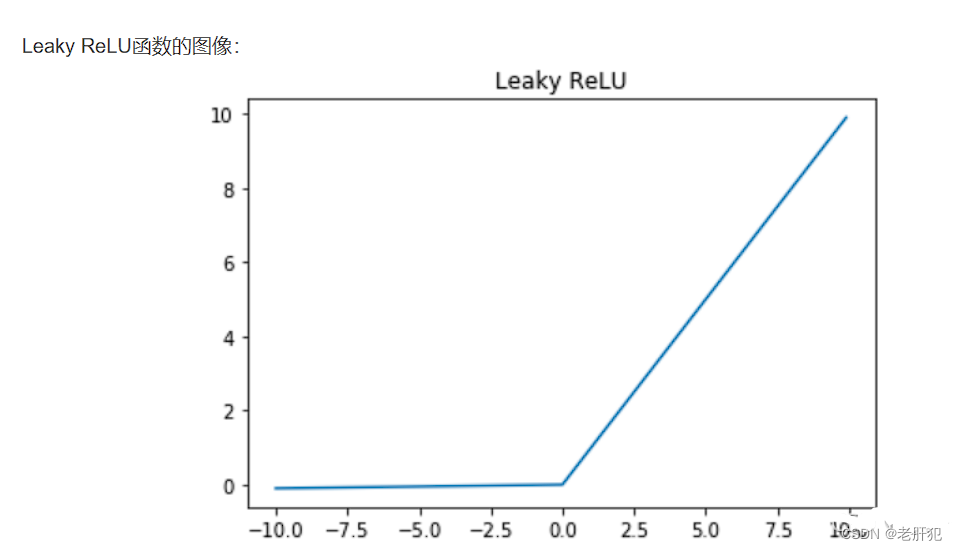
LeakyReLU(x)

图像:
torch.nn.Dropout
torch.nn.Dropout(Python class, in Dropout)
将输入的每个数值按(伯努利分布)概率赋值为0。即部分数值赋值为0。
import torch
import torch.nn as nn
import torch.nn.functional as F
def run1nn():input_ = torch.randn(4, 2)m = nn.Dropout(p=0.5)# m = nn.AlphaDropout(p=0.5)output = m(input_)print("input_ = \n", input_)print("output = \n", output)
结果
input_ = tensor([[-1.1293, -1.2553],[-0.7586, 0.3034],[ 1.6672, -0.6755],[-1.8980, 1.1677]])
output = # 部分数值赋值为0。 tensor([[-0.0000, -0.0000],[-1.5172, 0.6068],[ 0.0000, -0.0000], [-3.7961, 0.0000]])
torch.nn.Dropout2d
torch.nn.Dropout2d(Python class, in Dropout2d)
Dropout2d 的赋值对象是彩色的图像数据(batch N,通道 C,高度 H,宽 W)的一个通道里的每一个数据,即输入为 Input: (N, C, H, W) 时,对每一个通道维度 C 按概率赋值为 0。
import torch
import torch.nn as nn
import torch.nn.functional as F
def run_2d():input_ = torch.randn(2, 3, 2, 4)m = nn.Dropout2d(p=0.5, inplace=False)output = m(input_)print("input_ = \n", input_)print("output = \n", output)
结果
input_ = tensor([[[[ 0.4218, -0.6617, 1.0745, 1.2412],[ 0.2484, 0.6037, 0.3462, -0.4551]],[[-0.9153, 0.8769, -0.7610, -0.7405],[ 0.1170, -0.8503, -1.0089, -0.5192]],[[-0.6971, -0.9892, 0.1342, 0.1211],[-0.3756, 1.9225, -1.0594, 0.1419]]],[[[-1.2856, -0.3241, 0.2331, -1.5565],[ 0.6961, 1.0746, -0.9719, 0.5585]],[[-0.1059, -0.7259, -0.4028, 0.1968],[ 0.8201, -0.0833, -1.2811, 0.1915]],[[-0.2207, 0.3850, 1.4132, 0.8216],[-0.1313, 0.2915, 0.1996, 0.0021]]]])
output = tensor([[[[ 0.8436, -1.3234, 2.1489, 2.4825],[ 0.4968, 1.2073, 0.6924, -0.9101]],[[-1.8305, 1.7537, -1.5219, -1.4810],[ 0.2340, -1.7006, -2.0178, -1.0385]],[[-0.0000, -0.0000, 0.0000, 0.0000],[-0.0000, 0.0000, -0.0000, 0.0000]]],[[[-0.0000, -0.0000, 0.0000, -0.0000],[ 0.0000, 0.0000, -0.0000, 0.0000]],[[-0.2118, -1.4518, -0.8056, 0.3935],[ 1.6401, -0.1667, -2.5622, 0.3830]],[[-0.0000, 0.0000, 0.0000, 0.0000],[-0.0000, 0.0000, 0.0000, 0.0000]]]])
DCGAN完整代码
import matplotlib.pyplot as plt
from matplotlib import font_manager
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
import numpy as np
import torch.nn.functional as F
#导入数据集并且进行数据处理
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.5,0.5)])
traindata=torchvision.datasets.MNIST(root='D:\learn_pytorch\数据集',train=True,download=True,transform=transform)#训练集60,000张用于训练
#利用DataLoader加载数据集
trainload=DataLoader(dataset=traindata,shuffle=True,batch_size=64)
#GAN生成对抗网络,步骤:
#首先编写生成器和判别器
#然后固定生成器,用我们的数据优化判别器,试得我们最开始生成器生成的图片判断为0,真实图片判断为1
#接着固定判别器,利用我们的判别器判断生成器生成的图片,以判断的尽可能接近一为目的优化我们的生成器
#生成器的代码(针对手写字体识别)
class Generator(torch.nn.Module):def __init__(self):super(Generator,self).__init__()self.linear1=torch.nn.Linear(100,7*7*256)self.bn1=torch.nn.BatchNorm1d(7*7*256)self.uconv1=torch.nn.ConvTranspose2d(256,128,kernel_size=(3,3),padding=1)self.bn2=torch.nn.BatchNorm2d(128)self.uconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4),stride=2, padding=1)self.bn3 = torch.nn.BatchNorm2d(64)self.uconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1)def forward(self,x):#print('--------------------------------------')#print('x.shape:',x.shape)x=F.relu(self.linear1(x)) #torchsize([,])# print('x.shape:',x.shape)x=self.bn1(x)x=x.view(-1,256,7,7)#64,256,7,7# print('x.shape:',x.shape)x=F.relu(self.uconv1(x))#print('x.shape:',x.shape)x = self.bn2(x)#print('x.shape:', x.shape)x = F.relu(self.uconv2(x))#print('x.shape:', x.shape)x = self.bn3(x)#print('x.shape:', x.shape)x = torch.tanh(self.uconv3(x))#print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])return x
#判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):def __init__(self):super(Discraiminator,self).__init__()self.conv1=torch.nn.Conv2d(1,64,3,2)self.conv2=torch.nn.Conv2d(64,128,3,2)self.bn=torch.nn.BatchNorm2d(128)self.fc=torch.nn.Linear(128*6*6,1)def forward(self,x):# print('--------------------')#print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])x=F.dropout2d(F.leaky_relu(self.conv1(x)),p=0.3)# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])x = F.dropout2d(F.leaky_relu(self.conv2(x)),p=0.3)#print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])x=self.bn(x)x=x.view(-1,128*6*6)#print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])x=torch.sigmoid(self.fc(x))#print('x.shape:', x.shape)#torch.size([64,1])return x
#定义损失函数和优化函数
device='cuda' if torch.cuda.is_available() else 'cpu'
gen=Generator().to(device)
dis=Discraiminator().to(device)
#定义优化器
gen_opt=torch.optim.Adam(gen.parameters(),lr=0.0001)
dis_opt=torch.optim.Adam(dis.parameters(),lr=0.0001)
loss_fn=torch.nn.BCELoss()#损失函数
#图像显示
def gen_img_plot(model,testdata):pre=np.squeeze(model(testdata).detach().cpu().numpy())
#tensor.detach()
#返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
# 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
# 这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播plt.figure()for i in range(16):plt.subplot(4,4,i+1)plt.imshow(pre[i])plt.show()#后向传播
dis_loss=[]#判别器损失值记录
gen_loss=[]#生成器损失值记录
lun=[]#轮数
for epoch in range(100):d_epoch_loss=0g_epoch_loss=0cout=len(trainload)#938批次for step, (img, _) in enumerate(trainload):img=img.to(device) #图像数据#print('img.size:',img.shape)#img.size: torch.Size([64, 1, 28, 28])size=img.size(0)#一批次的图片数量64#随机生成一批次的100维向量样本,或者说100个像素点random_noise=torch.randn(size,100,device=device)#先进性判断器的后向传播dis_opt.zero_grad()real_output=dis(img)d_real_loss=loss_fn(real_output,torch.ones_like(real_output))#真实数据的损失函数值d_real_loss.backward()gen_img=gen(random_noise)fake_output=dis(gen_img.detach())d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output))#人造的数据的损失函数值d_fake_loss.backward()d_loss=d_real_loss+d_fake_lossdis_opt.step()#生成器的后向传播gen_opt.zero_grad()fake_output=dis(gen_img)g_loss=loss_fn(fake_output, torch.ones_like(fake_output))g_loss.backward()gen_opt.step()d_epoch_loss += d_lossg_epoch_loss += g_lossdis_loss.append(float(d_epoch_loss))gen_loss.append(float(g_epoch_loss))print(f'第{epoch+1}轮的生成器损失值:{g_epoch_loss},判别器损失值{d_epoch_loss}')lun.append(epoch+1)
font = font_manager.FontProperties(fname="C:\\Users\\ASUS\\Desktop\\Fonts\\STZHONGS.TTF")
plt.figure()
plt.plot(lun,dis_loss,'r',label='判别器损失值')
plt.plot(lun,gen_loss,'b',label='生成器损失值')
plt.xlabel('训练轮数', fontproperties=font, fontsize=12)
plt.ylabel('损失值', fontproperties=font, fontsize=12)
plt.title('损失值随着训练轮数得变化情况:',fontproperties=font, fontsize=18)
plt.legend(prop=font)
plt.show()
random_noise=torch.randn(16,100,device=device)
gen_img_plot(gen,random_noise)运行结果
D:\Anaconda3\envs\pytorch\python.exe D:\learn_pytorch\学习过程\第七周的代码\DCGAN.py
D:\Anaconda3\envs\pytorch\lib\site-packages\torch\autograd\graph.py:744: UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed cudnn_status: CUDNN_STATUS_NOT_SUPPORTED (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\cudnn\Conv_v8.cpp:919.)return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
第1轮的生成器损失值:1579.252197265625,判别器损失值515.1350708007812
第2轮的生成器损失值:2391.0146484375,判别器损失值337.9918518066406
第3轮的生成器损失值:2587.632080078125,判别器损失值321.1123962402344
第4轮的生成器损失值:2657.2861328125,判别器损失值343.73687744140625
第5轮的生成器损失值:2749.431884765625,判别器损失值357.3765869140625
第6轮的生成器损失值:2759.000732421875,判别器损失值379.94580078125
第7轮的生成器损失值:2857.893310546875,判别器损失值349.0403747558594
第8轮的生成器损失值:2998.0986328125,判别器损失值333.7505798339844
第9轮的生成器损失值:3100.708740234375,判别器损失值311.7953796386719
第10轮的生成器损失值:3153.125732421875,判别器损失值313.1640319824219
第11轮的生成器损失值:3235.841064453125,判别器损失值295.12188720703125
第12轮的生成器损失值:3211.852783203125,判别器损失值291.1082458496094
第13轮的生成器损失值:3276.736328125,判别器损失值280.8247375488281
第14轮的生成器损失值:3373.0068359375,判别器损失值291.33453369140625
第15轮的生成器损失值:3417.03515625,判别器损失值289.5420837402344
第16轮的生成器损失值:3411.50048828125,判别器损失值284.36627197265625
第17轮的生成器损失值:3404.64013671875,判别器损失值299.56231689453125
第18轮的生成器损失值:3395.18359375,判别器损失值313.3019104003906
第19轮的生成器损失值:3445.557373046875,判别器损失值298.1582336425781
第20轮的生成器损失值:3426.35400390625,判别器损失值318.19586181640625
第21轮的生成器损失值:3408.61279296875,判别器损失值312.55517578125
第22轮的生成器损失值:3366.21337890625,判别器损失值319.8542175292969
第23轮的生成器损失值:3399.591064453125,判别器损失值320.7420654296875
第24轮的生成器损失值:3403.3154296875,判别器损失值315.85333251953125
第25轮的生成器损失值:3447.93798828125,判别器损失值313.5019836425781
第26轮的生成器损失值:3457.364013671875,判别器损失值315.4457702636719
第27轮的生成器损失值:3523.110107421875,判别器损失值318.5495910644531
第28轮的生成器损失值:3500.356201171875,判别器损失值332.38311767578125
第29轮的生成器损失值:3480.306640625,判别器损失值321.0238342285156
第30轮的生成器损失值:3389.260986328125,判别器损失值325.1155700683594
第31轮的生成器损失值:3436.16650390625,判别器损失值307.0777587890625
第32轮的生成器损失值:3394.552490234375,判别器损失值333.5028381347656
第33轮的生成器损失值:3457.662841796875,判别器损失值319.47381591796875
第34轮的生成器损失值:3399.335693359375,判别器损失值331.17071533203125
第35轮的生成器损失值:3457.115478515625,判别器损失值325.4178161621094
第36轮的生成器损失值:3398.646484375,判别器损失值343.2962951660156
第37轮的生成器损失值:3445.762939453125,判别器损失值326.4263916015625
第38轮的生成器损失值:3437.1435546875,判别器损失值329.8385009765625
第39轮的生成器损失值:3485.200927734375,判别器损失值335.22430419921875
第40轮的生成器损失值:3435.8955078125,判别器损失值352.4512939453125
第41轮的生成器损失值:3433.603759765625,判别器损失值335.2181701660156
第42轮的生成器损失值:3425.03466796875,判别器损失值349.93438720703125
第43轮的生成器损失值:3420.529052734375,判别器损失值348.5238952636719
第44轮的生成器损失值:3454.771240234375,判别器损失值339.51812744140625
第45轮的生成器损失值:3333.04541015625,判别器损失值339.0191345214844
第46轮的生成器损失值:3403.718017578125,判别器损失值339.38201904296875
第47轮的生成器损失值:3374.437255859375,判别器损失值359.489501953125
第48轮的生成器损失值:3367.917236328125,判别器损失值354.06610107421875
第49轮的生成器损失值:3376.383544921875,判别器损失值359.9549255371094
第50轮的生成器损失值:3342.87451171875,判别器损失值344.5625305175781
第51轮的生成器损失值:3319.769775390625,判别器损失值361.1434326171875
第52轮的生成器损失值:3409.950927734375,判别器损失值364.78814697265625
第53轮的生成器损失值:3283.47509765625,判别器损失值348.1431579589844
第54轮的生成器损失值:3358.107421875,判别器损失值376.7725830078125
第55轮的生成器损失值:3332.283203125,判别器损失值351.0509033203125
第56轮的生成器损失值:3436.684326171875,判别器损失值373.5537414550781
第57轮的生成器损失值:3324.50390625,判别器损失值370.8129577636719
第58轮的生成器损失值:3348.836669921875,判别器损失值363.35333251953125
第59轮的生成器损失值:3385.3681640625,判别器损失值359.1947326660156
第60轮的生成器损失值:3320.71728515625,判别器损失值369.278076171875
第61轮的生成器损失值:3314.728271484375,判别器损失值370.73291015625
第62轮的生成器损失值:3309.6015625,判别器损失值362.6439514160156
第63轮的生成器损失值:3319.76708984375,判别器损失值379.465087890625
第64轮的生成器损失值:3276.16748046875,判别器损失值347.47113037109375
第65轮的生成器损失值:3285.185302734375,判别器损失值366.93292236328125
第66轮的生成器损失值:3316.2236328125,判别器损失值369.2450866699219
第67轮的生成器损失值:3360.760986328125,判别器损失值374.16351318359375
第68轮的生成器损失值:3289.914306640625,判别器损失值373.56793212890625
第69轮的生成器损失值:3201.9619140625,判别器损失值387.50726318359375
第70轮的生成器损失值:3286.493896484375,判别器损失值365.38116455078125
第71轮的生成器损失值:3316.646728515625,判别器损失值356.8478088378906
第72轮的生成器损失值:3347.092529296875,判别器损失值374.73040771484375
第73轮的生成器损失值:3325.108154296875,判别器损失值371.69854736328125
第74轮的生成器损失值:3306.774169921875,判别器损失值387.7281188964844
第75轮的生成器损失值:3306.62353515625,判别器损失值381.65435791015625
第76轮的生成器损失值:3344.023193359375,判别器损失值387.91357421875
第77轮的生成器损失值:3358.8564453125,判别器损失值359.6070556640625
第78轮的生成器损失值:3260.2861328125,判别器损失值372.3000793457031
第79轮的生成器损失值:3302.4677734375,判别器损失值366.2215881347656
第80轮的生成器损失值:3202.896484375,判别器损失值375.2501525878906
第81轮的生成器损失值:3295.48828125,判别器损失值397.47943115234375
第82轮的生成器损失值:3250.3466796875,判别器损失值355.27374267578125
第83轮的生成器损失值:3242.819580078125,判别器损失值364.61016845703125
第84轮的生成器损失值:3194.531494140625,判别器损失值393.2528076171875
第85轮的生成器损失值:3248.498046875,判别器损失值386.95989990234375
第86轮的生成器损失值:3302.18115234375,判别器损失值363.2670593261719
第87轮的生成器损失值:3268.8681640625,判别器损失值389.0802307128906
第88轮的生成器损失值:3215.17138671875,判别器损失值373.05340576171875
第89轮的生成器损失值:3286.826416015625,判别器损失值379.6147766113281
第90轮的生成器损失值:3217.275390625,判别器损失值405.34417724609375
第91轮的生成器损失值:3246.24267578125,判别器损失值376.77703857421875
第92轮的生成器损失值:3233.778076171875,判别器损失值390.8014221191406
第93轮的生成器损失值:3225.767333984375,判别器损失值390.83782958984375
第94轮的生成器损失值:3254.76708984375,判别器损失值383.3574523925781
第95轮的生成器损失值:3242.814697265625,判别器损失值389.95660400390625
第96轮的生成器损失值:3202.566650390625,判别器损失值368.3985290527344
第97轮的生成器损失值:3311.66064453125,判别器损失值379.5376892089844
第98轮的生成器损失值:3245.30029296875,判别器损失值382.5791931152344
第99轮的生成器损失值:3194.65478515625,判别器损失值377.3322448730469
第100轮的生成器损失值:3224.66796875,判别器损失值372.3442687988281进程已结束,退出代码0
图形显示
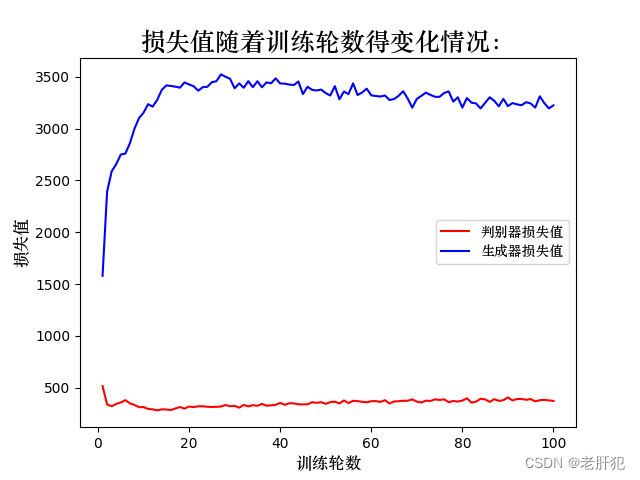

这里训练了100轮,其实30轮就差不多,这里可以清楚的看出来,我们生成器生成的图片(我们是以手写字体数据集为例子),很接近真实图片了。







![[蓝桥杯2024]-PWN:ezheap解析(堆glibc2.31,glibc2.31下的double free)](https://img-blog.csdnimg.cn/direct/024fd81f6b5349b3a54d001c5aab31e8.png)
![[HNOI2003]激光炸弹](https://img-blog.csdnimg.cn/direct/4b9f37466d494471bfd12a444a93d721.png)