目录
一、左值引用 && 右值引用
二、左值引用于右值引用的比较
三、 右值引用使用场景和意义
1、函数返回值
①移动赋值
②移动构造
2、STL容器插入接口
3、完美转发
一、左值引用 && 右值引用
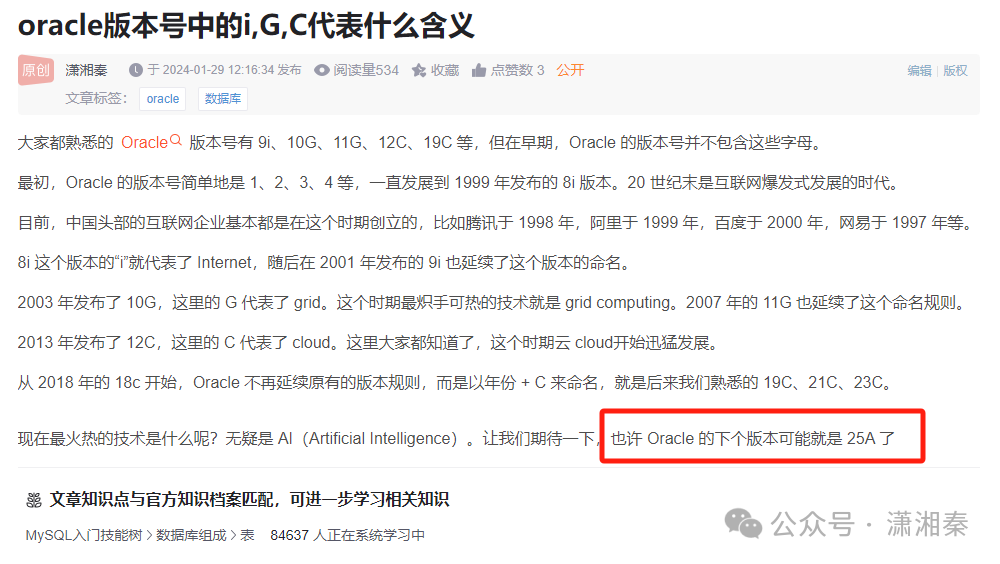
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们 之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋 值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左 值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
什么是右值?什么是右值引用?
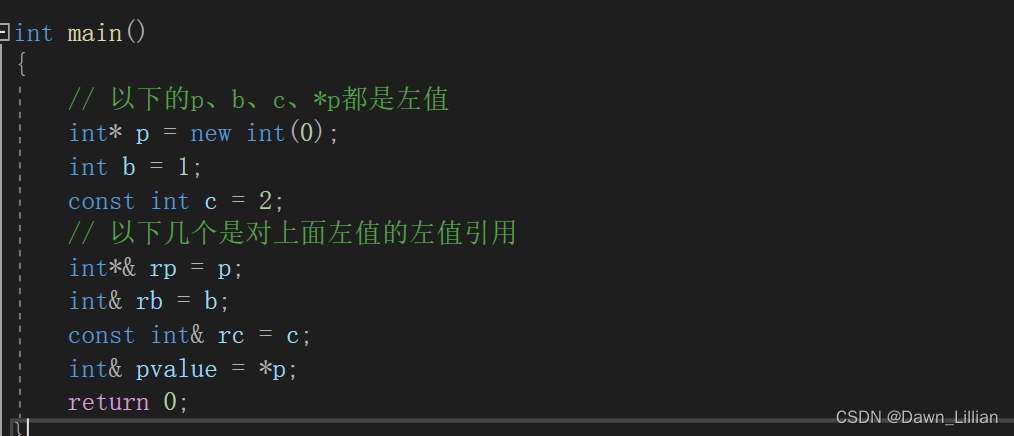
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引 用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能 取地址。右值引用就是对右值的引用,给右值取别名。
⭕【注意】
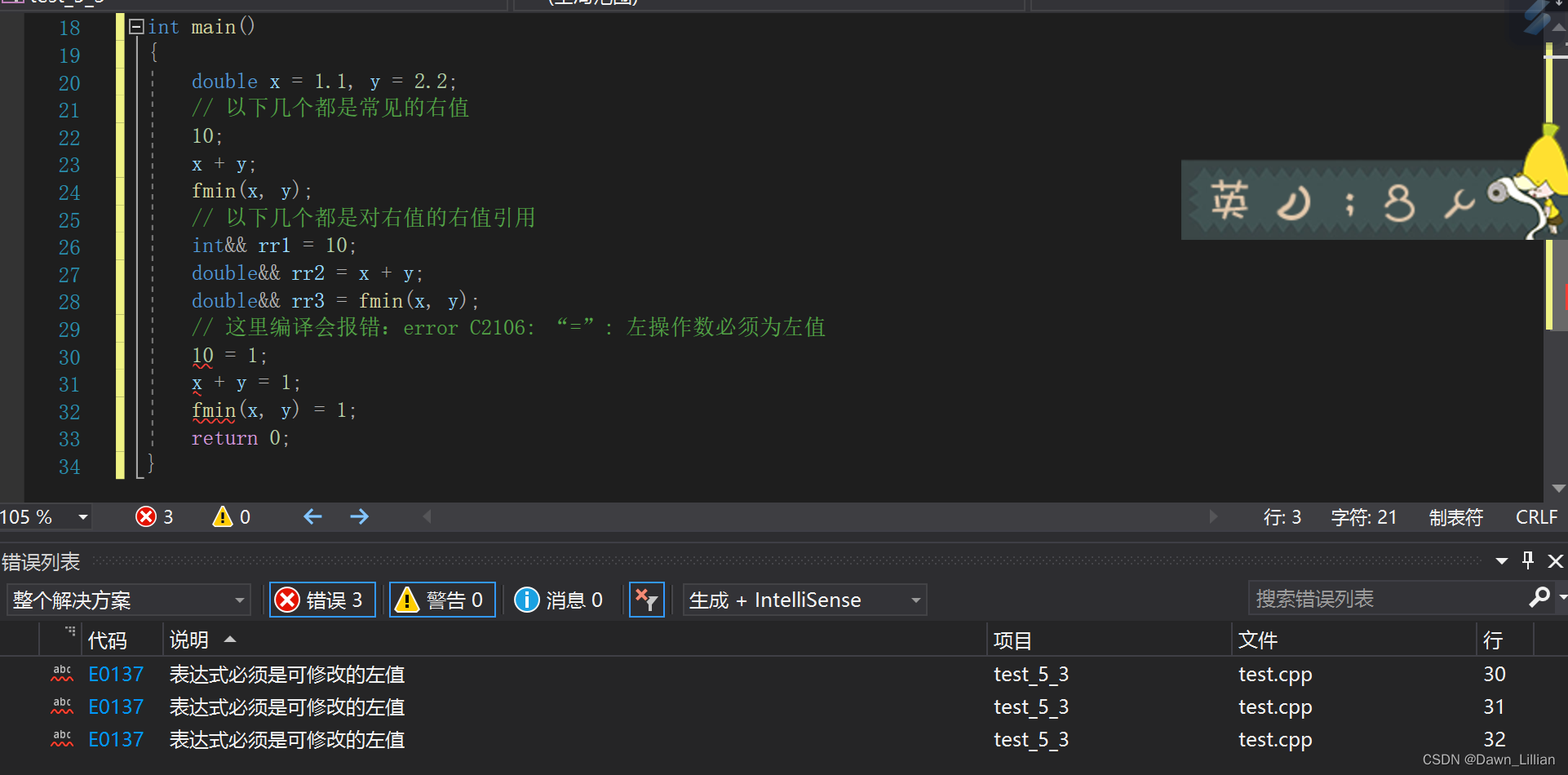
需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可 以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地 址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用
二、左值引用于右值引用的比较
左值引用总结:
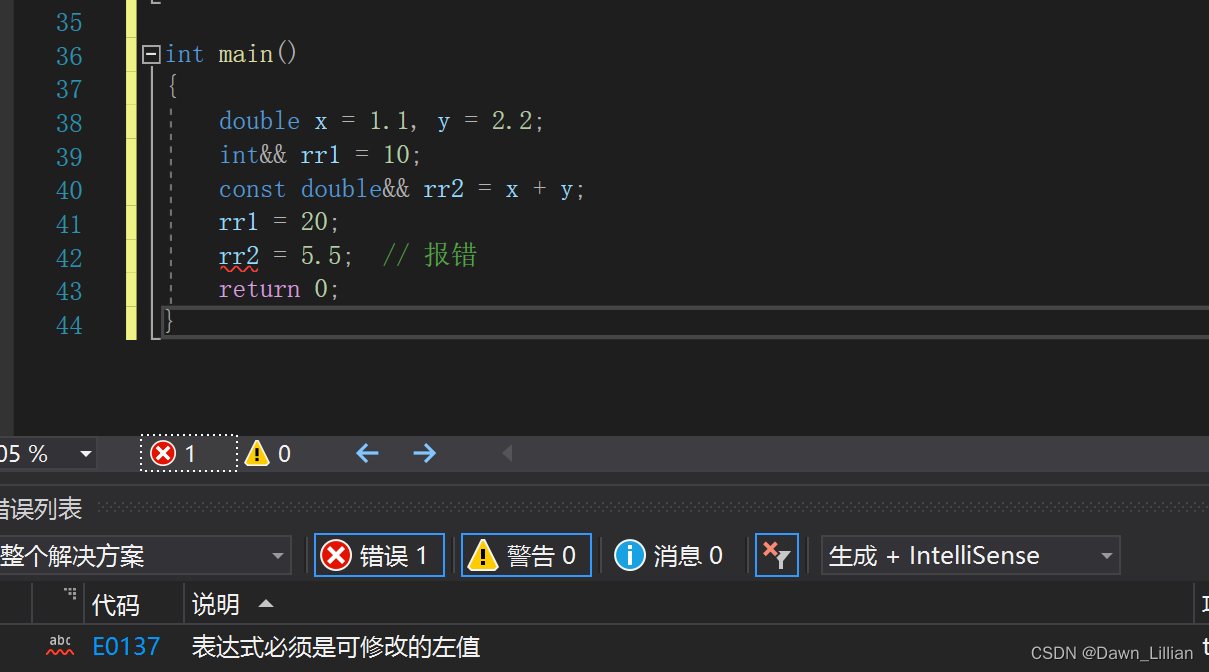
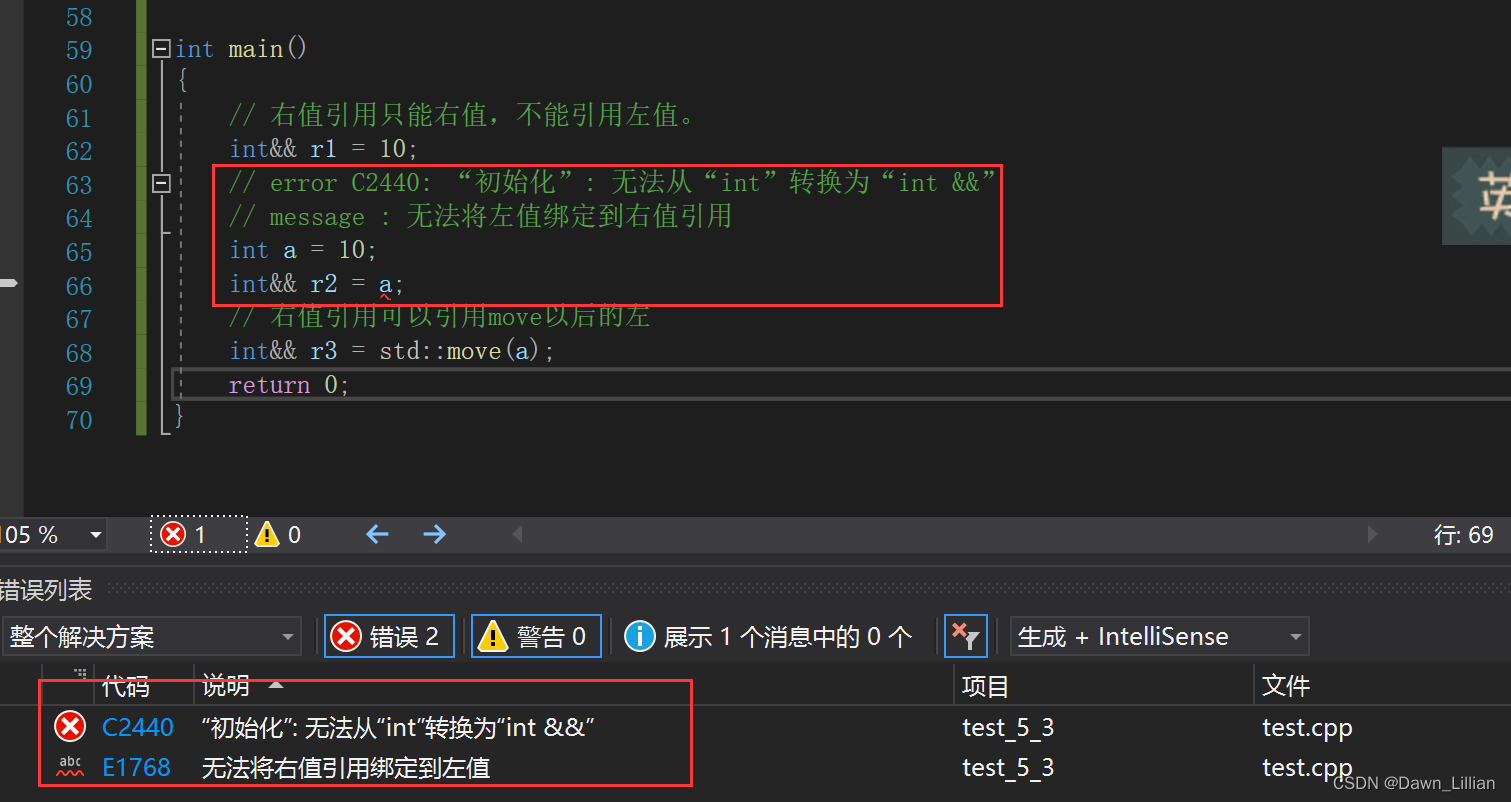
🟢左值引用只能引用左值,不能引用右值。
🟢const左值引用既可引用左值,也可引用右值。

右值引用总结:
🟢右值引用只能右值,不能引用左值。
🟢右值引用可以move以后的左值。 (move可以将左值转换位右值,也就是使用move后它会传回一个右值。)
三、 右值引用使用场景和意义
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引 用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
左值引用的核心价值就是减少拷贝,提高效率。但也有局限场景:
①当作为函数参数时,用左值引用非常好,可以减少拷贝。
②当作为函数返回值时,这里的前提就是变量要么是静态变量要么是全局变量,反正在函数结束后,该引用变量仍然存在,这个场景下才可以使用左值引用,减少拷贝。
③当变量是局部变量时,就无法使用左值引用作为函数返回值了,必须使用传值返回!但在传值返回时,函数结束后变量就销毁了,所以需要拷贝一个临时变量存储返回值。这里就存在拷贝。当返回值是内置类型,拷贝代价低,当返回值是自定义类型,那么拷贝的代价就很大了。因为拷贝都是深拷贝,需要开空间。
右值引用都应用在哪呢?
右值引用的核心也是为了减少拷贝,并且是进一步减少拷贝,弥补左值引用中没有解决的场景:比如上面所说的函数传值返回需要拷贝。那么右值引用是如何解决的呢?转移资源!直接将资源转移
1、函数返回值
就是对于那些自定义类型中需要深拷贝的类,并且需要传值返回的类。对象如果是内置类型那么拷贝的代价很低,所以主要考虑的是自定义类型。而如果在自定义类型中不存在深拷贝的操作,那么也不需要考虑,这些操作的消耗不是很大。但是如果是自定义类型中深拷贝的话,那么这个消耗就巨大了,不仅需要开跟对象一样大的空间,将数据拷贝过来,最后还要释放空间。
接下来用自己手搓的 string 来演示【手把手教你手搓string类】
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include<assert.h>
#include<string>namespace zhou
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str+_size;}iterator begin() const{return _str;}iterator end() const{return _str + _size;}//无参的构造函数/*string():_str(new char[1]),_size(0),_capacity(0){ _str[0] = '\0';}*///带参的构造函数//str是被const修饰的,是库里面决定的,不能改变//string(const char* str=nullptr) 不可以,strlen遇到'\0'才停止,遇到空指针会崩溃 //string(const char* str = '\0') 不可以,类型不匹配,左边是char类型的//string(const char* str = "\0") //可以,是常量字符串,strlen是0,可以正常运算。string(const char* str = "") //可以,不写默认是'\0':_size(strlen(str)){_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}//返回c形式的字符串const char* c_str(){return _str;}string(const string& s):_size(s._size), _capacity(s._capacity){_str = new char[s._capacity + 1];strcpy(_str, s._str);}//无 const 修饰char& operator[](size_t pos){assert(pos < _size);return _str[pos];}//有 const 修饰const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}size_t size(){return _size;}//赋值string& operator=(const string s){if (this != &s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[]_str;_str = tmp;_size = s._size;_capacity = s._capacity;}return *this;}//不修改成员变量数据的函数,最好都加上constbool operator>(const string& s) const{return strcmp(_str, s._str) > 0;}bool operator==(const string& s) const{return strcmp(_str, s._str) == 0;}bool operator>=(const string& s) const{//return *this > s || *this == s;return *this > s || s == *this;}bool operator<(const string& s) const{return !(*this >= s);}bool operator<=(const string& s) const{return !(*this > s);}bool operator!=(const string& s) const{return !(*this == s);}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void resize(size_t n, char ch = '\0'){if (n <= _size){_size = n;_str[_size] = '\0';}else {if (n > _capacity){reserve(n);}size_t i = _size;while (i < n){_str[i] = ch;i++;}_size = n;_str[_size] = '\0';}}void push_back(char ch){//要判断内存if (_size + 1 > _capacity){reserve(2 * _capacity);}_str[_size] = ch;_size++;//不要忘'\0'_str[_size] = '\0';}void append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}string& insert(size_t pos, char ch){assert(pos <=_size);if (_size + 1 > _capacity){reserve(2 * _capacity);}//问题代码,会发现头插时会崩溃/*size_t end = _size;while (end >=pos){_str[end + 1] = _str[end];end--;}*/size_t end = _size + 1;while (end > pos){_str[end] = _str[end-1];end--;}_str[pos] = ch;_size++;return *this;}string& insert(size_t pos, const char* str){size_t len = strlen(str);assert(pos <= _size);if (_size + len > _capacity){reserve(_size + len);}size_t end = _size + len;while (end > pos + len-1){_str[end] = _str[end-len];end--;}strncpy(_str + pos, str,len);_size += len;return *this;}string& erase(size_t pos, size_t len = npos){assert(pos < _size);if (len == npos || pos + len >= _size){_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len;}return *this;}void swap(string& s){std::swap(_str, s._str);std::swap(_capacity, s._capacity);std::swap(_size, s._size);}size_t find(char ch, size_t pos = 0){assert(pos < _size);for (size_t i = pos; i < _size; ++i){if (_str[i] == ch){return i;}}return npos;}size_t find(const char* str, size_t pos = 0){assert(pos < _size);char* p = strstr(_str + pos, str);if (p == nullptr){return npos;}else{return p - _str;}}void clear(){_str[0] = '\0';_size = 0;}~string(){delete[] _str;_str = nullptr;_capacity =_size= 0;}private:char* _str;size_t _size;size_t _capacity;static const size_t npos;};const size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear();char ch = in.get();char buff[128];size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}void test_string1(){string s1;string s2("hello world");cout << s1.c_str() << endl;cout << s2.c_str() << endl;}void test_string2(){string s("hello world");//下标遍历for (size_t i = 0; i < s.size(); i++){cout<<s[i];}cout << endl;//iterator遍历string::iterator it = s.begin();while (it < s.end()){cout << *it;it++;}cout << endl;//范围for for (auto ch : s){cout << ch;}}}
①移动赋值
这里我们再对右值进一步分类,右值也称为将亡值。为什么叫将亡值呢?一般有的右值的生命周期只有一行,下一行,这个右值就销毁了,所以称为将亡值,就比如函数的返回值就是将亡值。对于内置类型呢,右值称呼为纯右值,对于自定义类型,称为将亡值。
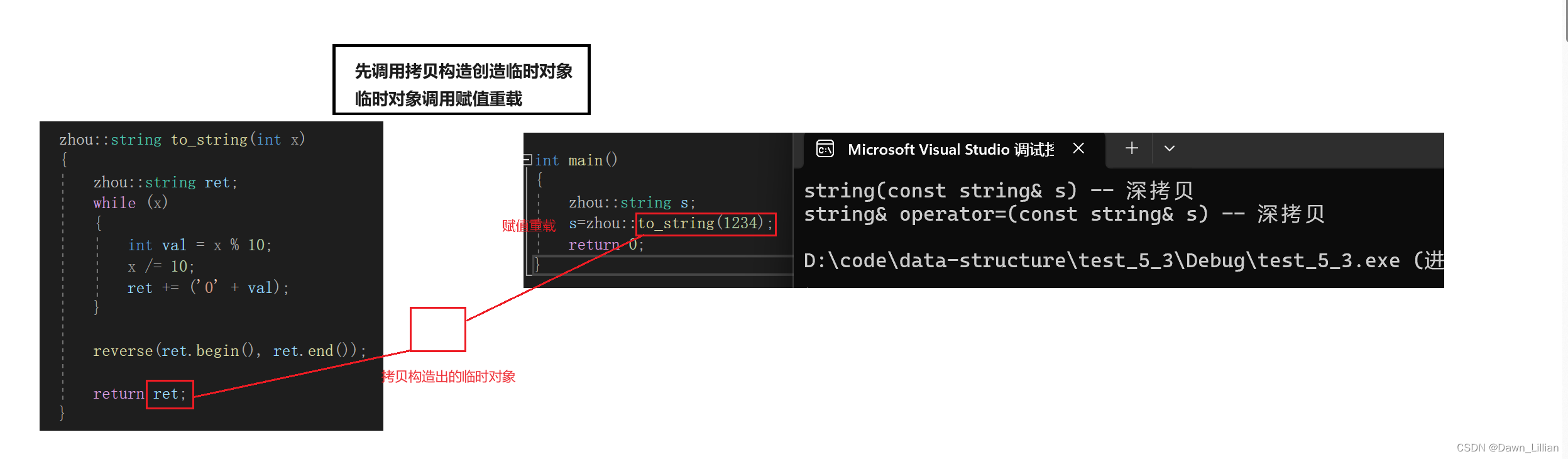
这样必须调用两次深拷贝,代价太大了。我们注意到 to_string 函数的地址是无法获取到的,也就是说 to_string 函数的返回值是右值,而 to_string 函数的返回值又是自定义类型,所以这个右值是个将亡值,生命周期就在这一行,我们可以利用这个将要销毁的将亡值的特性,将这个将亡值的资源全部吸走,再将自己的不要的给它,这样不需要开辟空间,也不需要深度拷贝,ret 这个变量就获取到了想要的资源。

⭕【总结】当要赋值的对象是右值时,就调用移动赋值,当拷贝的对象是左值时,就调用普通重载赋值 。因为左值不会立即销毁,如果将左值的资源全部抢走明显是不合理的。所以当拷贝左值时,该深拷贝就深拷贝。
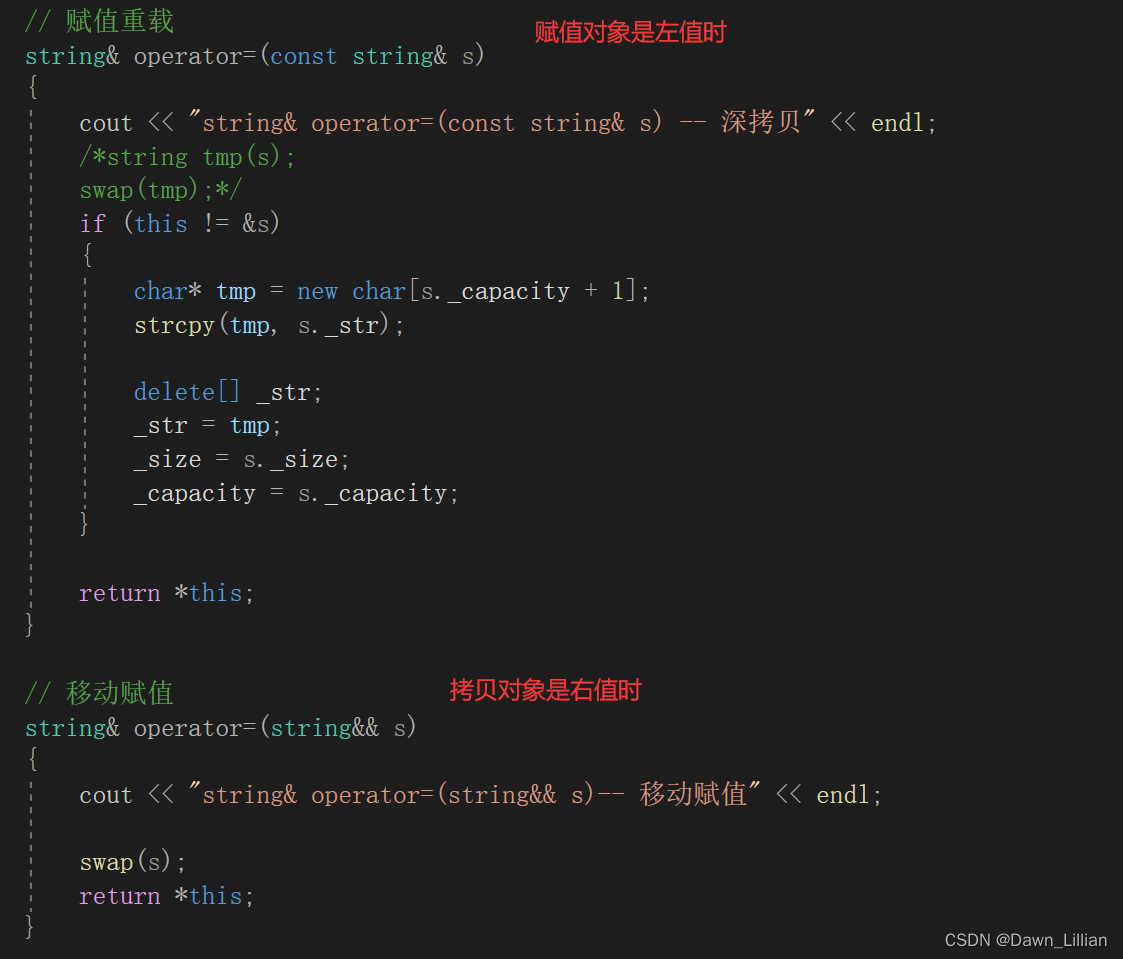

②移动构造
我们不仅可以重载赋值运算符的移动赋值,还可以重载拷贝构造的移动拷贝,因为重载后,对整体来说是没有问题的,当拷贝的对象是左值那么就调用拷贝构造,当拷贝的对象是右值那么就调用移动拷贝。

to_string 的返回值是一个右值,用右值构造s,如果没有移动构造,调用就会匹配调用拷贝构造,因为 const 左值引用是可以引用右值的,这里就是一个深拷贝。
移动构造本质是将参数右值的资源窃取过来,占位已有,那么就不 用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己
1.连续的构造/拷贝构造,会合二为一。
2.编译器会将 ret 识别成右值,即将亡值。
【问题①】如何合二为一的?
在函数结束之前,就让 ret 作为拷贝对象,s 调用拷贝构造。而不是在函数结束之后再赋值,因为函数结束后,ret 就销毁了,所以需要在函数结束之前拷贝,也就是在函数结束之前将 ret 返回,再将 ret 看成将亡值,这一步是编译器做的,我们看不到。
【问题②】为什么将 ret 识别成将亡值?
因为 ret 识别成将亡值更符合概念,编译器不优化的话, to_string 函数的返回值也是将亡值,编译器优化后, to_string 返回值是 ret ,那这样一对, ret 理论上就应该被识别成将亡值,并且将 ret 看成将亡值并没有什么问题,反正 ret 也快销毁了。

这样的话最后的过程就只调用了移动构造。由原来的会调用拷贝构造进行深拷贝变成了现在的只调用移动拷贝.这里移动拷贝直接就将 ret 的资源转载到了 s,中间没有开辟空间.to_string 的返回值是一个右值,用这个右值构造s,如果既有拷贝构造柱又有移动构造,调用就会匹配调用移动构造,因为编译器会选择最匹配的参数调用。

2、STL容器插入接口
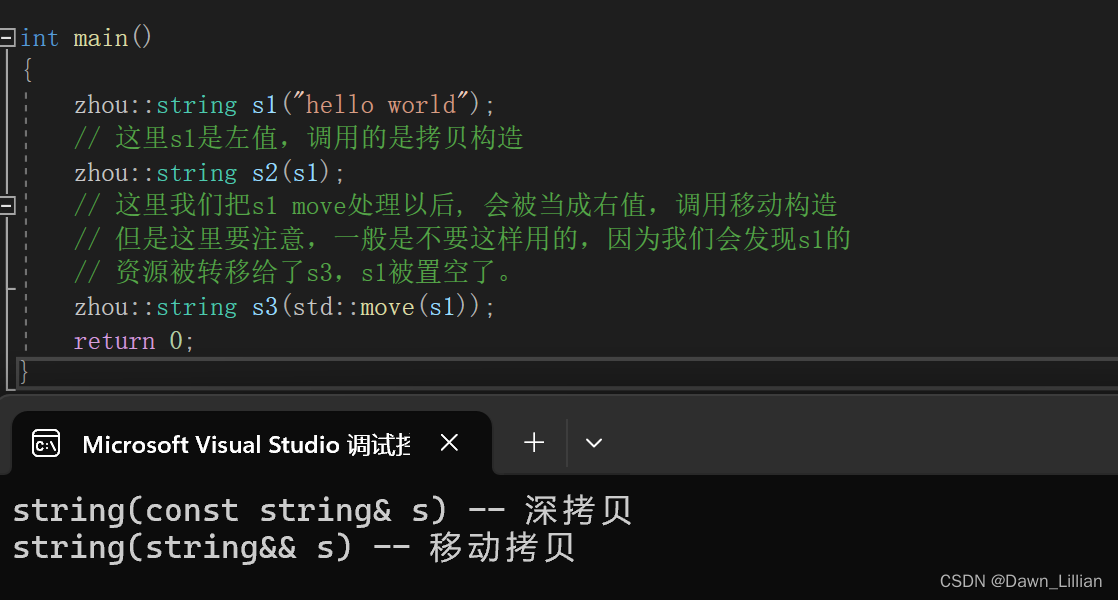
按照语法,右值引用只能引用右值,但右值引用一定不能引用左值吗?因为:有些场景下,可能 真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过move 函数将左值转化为右值。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性, 它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
 我们接下来用 list 来实现:
我们接下来用 list 来实现:
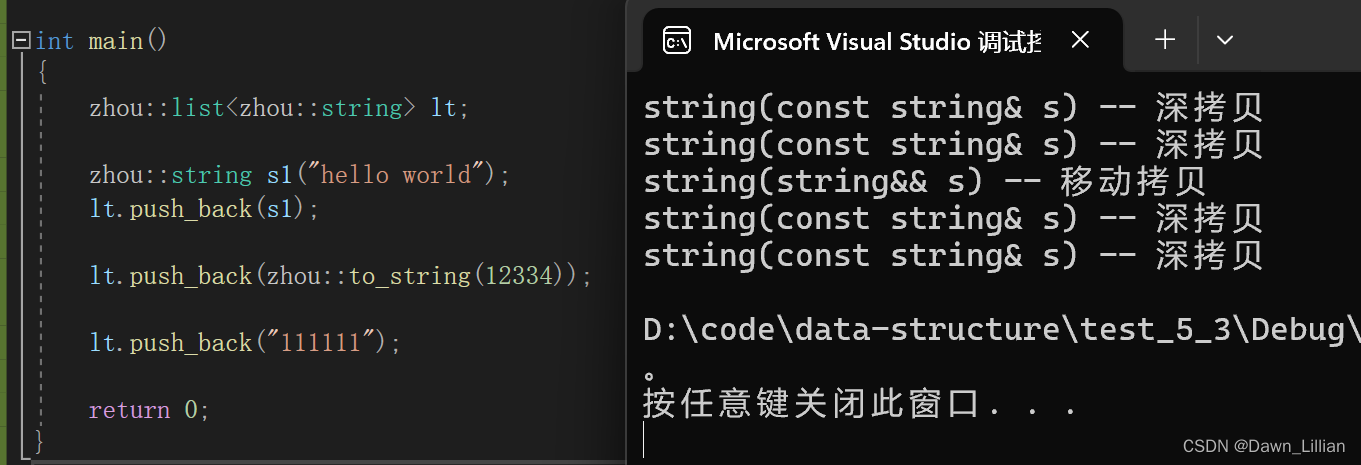
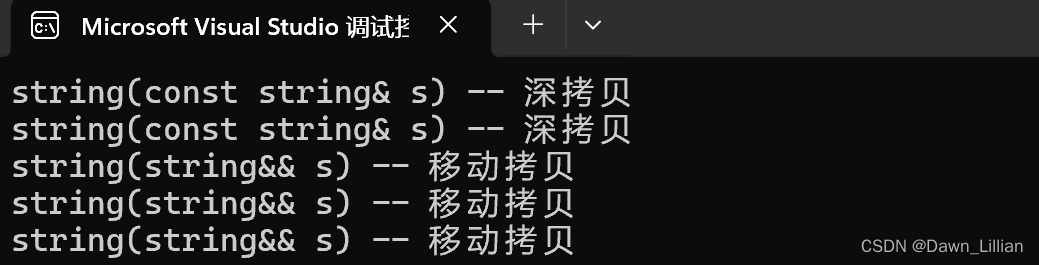
❓【问题】为什么只有一个移动拷贝呢?按我们上面方法to_string 应该是移动拷贝才对啊。
✅【解答】因为右值被右值引用以后得属性是左值。to_string 返回的是右值,但右值经过函数引用之后又变成了左值,左值拷贝就变成了深拷贝。
❓【问题】那为什么要这么设计呢?
✅【解答】因为右值不能直接修改,但是右值被右值引用之后,需要被修改,否则无法实现移动赋值和移动构造。


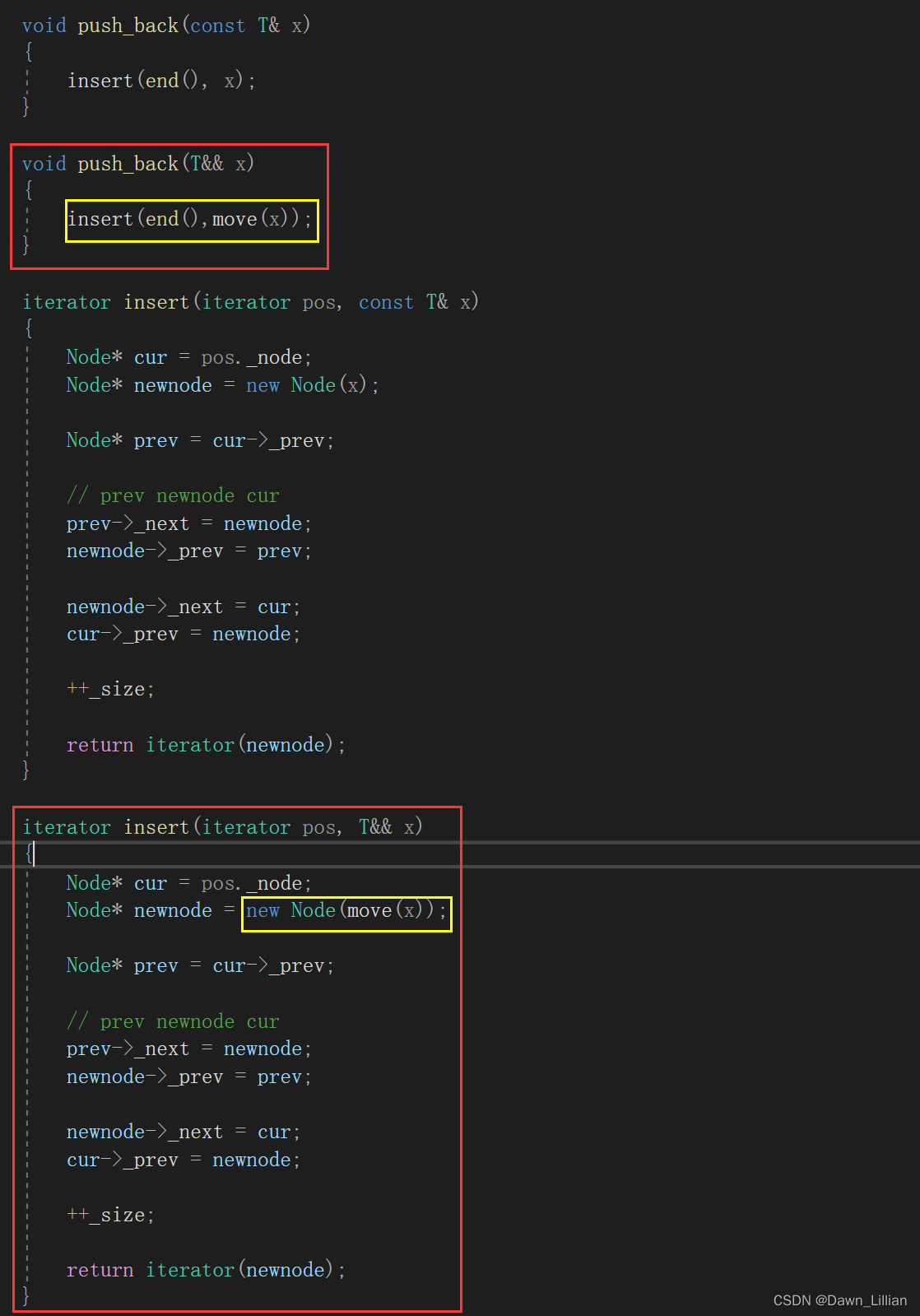
为了解决上面的问题我们可以通过 move 函数将左值修改为右值
 3、完美转发
3、完美转发
定义一个模板,既可以接收左值,又可以接受右值。

【模板验证】
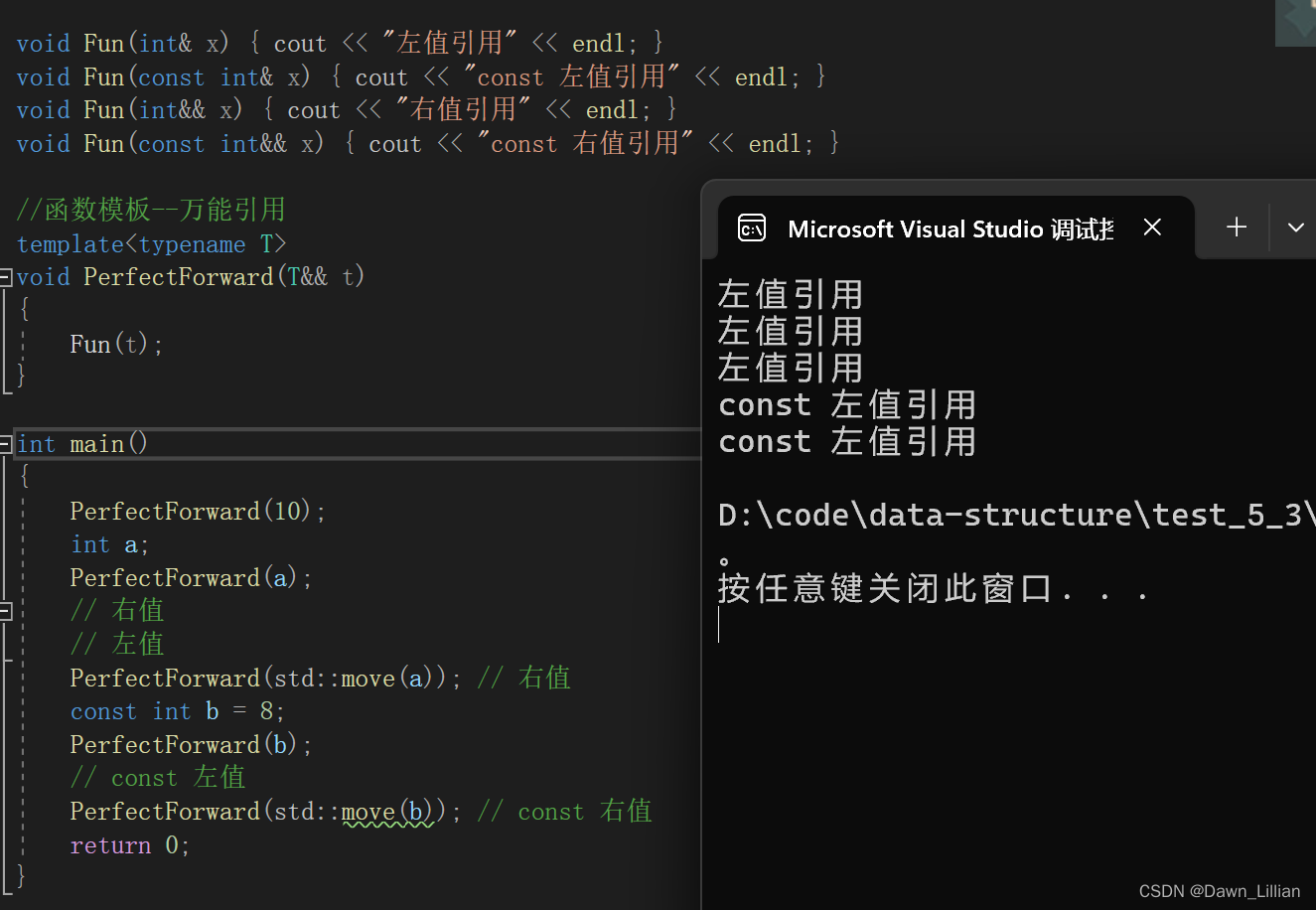 ❓【问题】为什么全是左值引用呢?
❓【问题】为什么全是左值引用呢?
✅【解答】因为左值引用返回左值引用,右值被引用之后的属性也是左值。
❓【问题】怎么保持值的原有属性呢?保持T属性
✅【解答】使用 forward<T>,当实参是左值时,它就是左值引用,当实参是右值时,它就是右值引用。
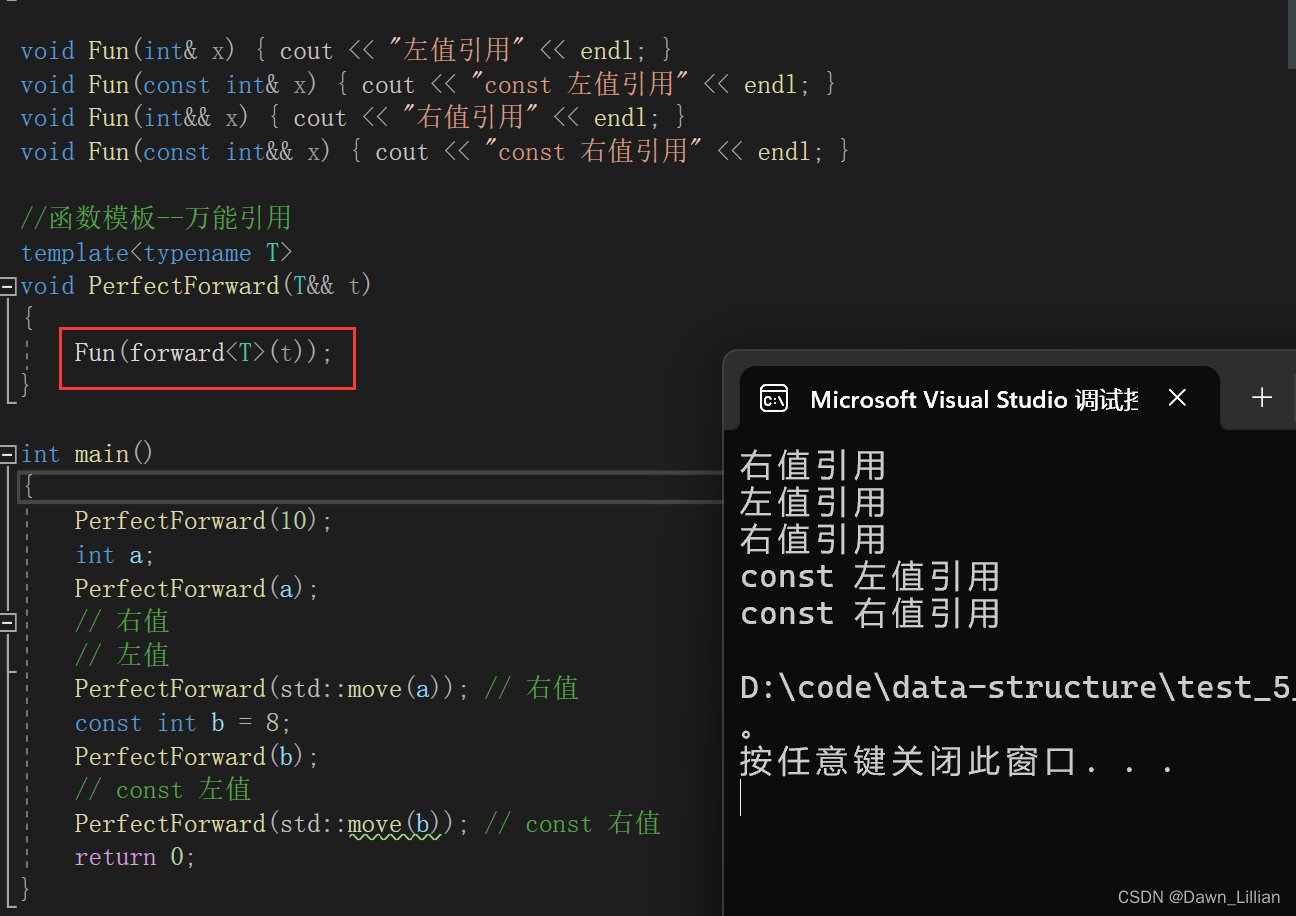
所以我们也可以将 forward<T> 来取代 move() 函数在list之间的应用。

 【list 完整代码】
【list 完整代码】
#pragma once#include<set>namespace zhou
{template<class T>struct list_node{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T& x = T()):_data(x), _next(nullptr), _prev(nullptr){}list_node(T&& x):_data(move(x)), _next(nullptr), _prev(nullptr){}template <class... Args>list_node(Args&&... args): _data(args...), _next(nullptr), _prev(nullptr){}};// T T& T*// T cosnt T& const T*template<class T, class Ref, class Ptr>struct __list_iterator{typedef list_node<T> Node;typedef __list_iterator<T, Ref, Ptr> self;Node* _node;__list_iterator(Node* node):_node(node){}self& operator++(){_node = _node->_next;return *this;}self& operator--(){_node = _node->_prev;return *this;}self operator++(int){self tmp(*this);_node = _node->_next;return tmp;}self operator--(int){self tmp(*this);_node = _node->_prev;return tmp;}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const self& s){return _node != s._node;}bool operator==(const self& s){return _node == s._node;}};template<class T>class list{typedef list_node<T> Node;public:typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;//typedef __list_const_iterator<T> const_iterator;const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}iterator begin(){//return iterator(_head->_next);return _head->_next;}iterator end(){//return iterator(_head->_next);return _head;}void empty_init(){_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;}list(){empty_init();}// lt2(lt1)list(const list<T>& lt){empty_init();for (auto e : lt){push_back(e);}}void swap(list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}// lt3 = lt1list<int>& operator=(list<int> lt){swap(lt);return *this;}~list(){clear();delete _head;_head = nullptr;}void clear(){iterator it = begin();while (it != end()){it = erase(it);}}void push_back(const T& x){insert(end(), x);}void push_back(T&& x){insert(end(), forward<T>(x));}template <class... Args>void emplace_back(Args&&... args){Node* newnode = new Node(args...);// 链接节点}void push_front(const T& x){insert(begin(), x);}void pop_front(){erase(begin());}void pop_back(){erase(--end());}iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;++_size;return iterator(newnode);}iterator insert(iterator pos, T&& x){Node* cur = pos._node;Node* newnode = new Node(forward<T>(x));Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;++_size;return iterator(newnode);}iterator erase(iterator pos){Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;delete cur;prev->_next = next;next->_prev = prev;--_size;return iterator(next);}size_t size(){return _size;}private:Node* _head;size_t _size;};
}





![[Docker]容器的网络类型以及云计算](https://img-blog.csdnimg.cn/direct/3bb3a7a08a4344da8a78eaea01a785f2.png)