一: MyBatis XML 配置文件
Mybatis 的开发有两种方式:
- 注解
- XML
我们已经学习了注解的方式, 接下来我们学习 XML 的方式
MyBatis XML 的方式需要以下两步:
- 配置数据库连接字符串和 MyBatis
- 写持久层代码
1.1 配置连接字符串和 MyBatis
此步骤需要进行两项设置,数据库连接字符串设置和 MyBatis 的 XML 文件配置。
- application.yml 文件
# 数据库连接配置
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mybatis_test?characterEncoding=utf8&useSSL=falseusername: rootpassword: rootdriver-class-name: com.mysql.cj.jdbc.Driver
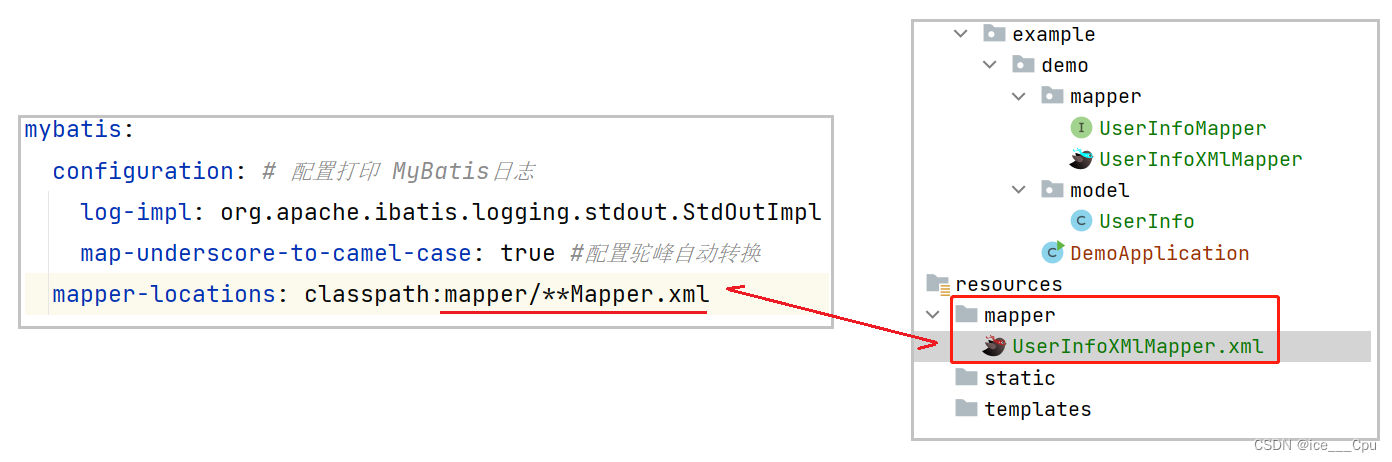
# 配置 mybatis xml 的⽂件路径,在 resources/mapper 创建所有表的 xml ⽂件
mybatis:mapper-locations: classpath:mapper/**Mapper.xml
- application.properties 文件
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/mybatis_test? characterEncoding=utf8&useSSL=false
#连接数据库的⽤⼾名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=root
# 配置 mybatis xml 的⽂件路径,在 resources/mapper 创建所有表的 xml ⽂件
mybatis.mapper-locations=classpath:mapper/**Mapper.xml
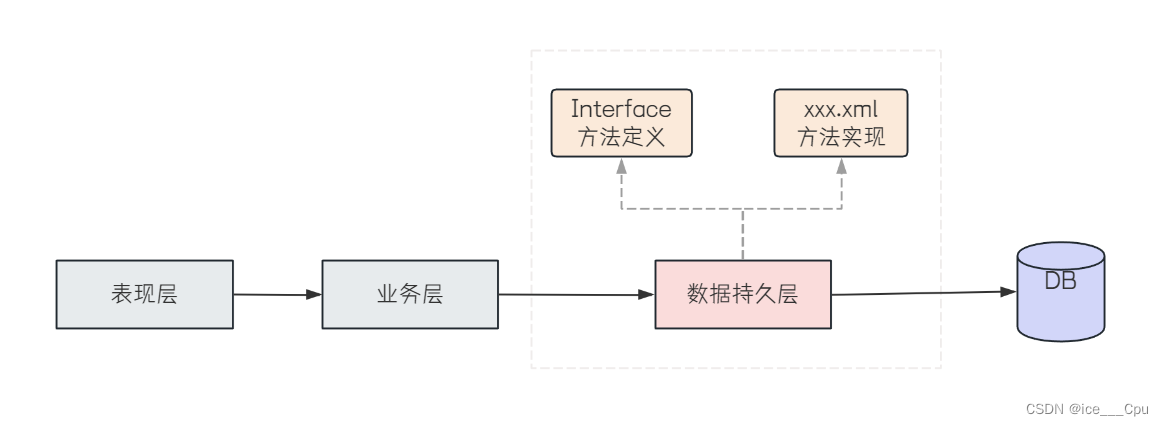
1.2 写持久层代码
持久层代码分两部分
- 方法定义 Interface
- 方法实现: XXX.xml
1.2.1 添加 mapper 接口
数据持久层的接口定义:
import com.example.demo.model.UserInfo;
import org.apache.ibatis.annotations.Mapper;import java.util.List;@Mapper
public interface UserInfoXMlMapper {List<UserInfo> queryAllUser();
}
1.2.2 添加 UserInfoXMLMapper.xml
数据持久成的实现,MyBatis 的固定 xml 格式:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserInfoMapper"></mapper>
创建 UserInfoXMLMapper.xml, 路径参考 yml 中的配置
查询所有用户的具体实现 :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
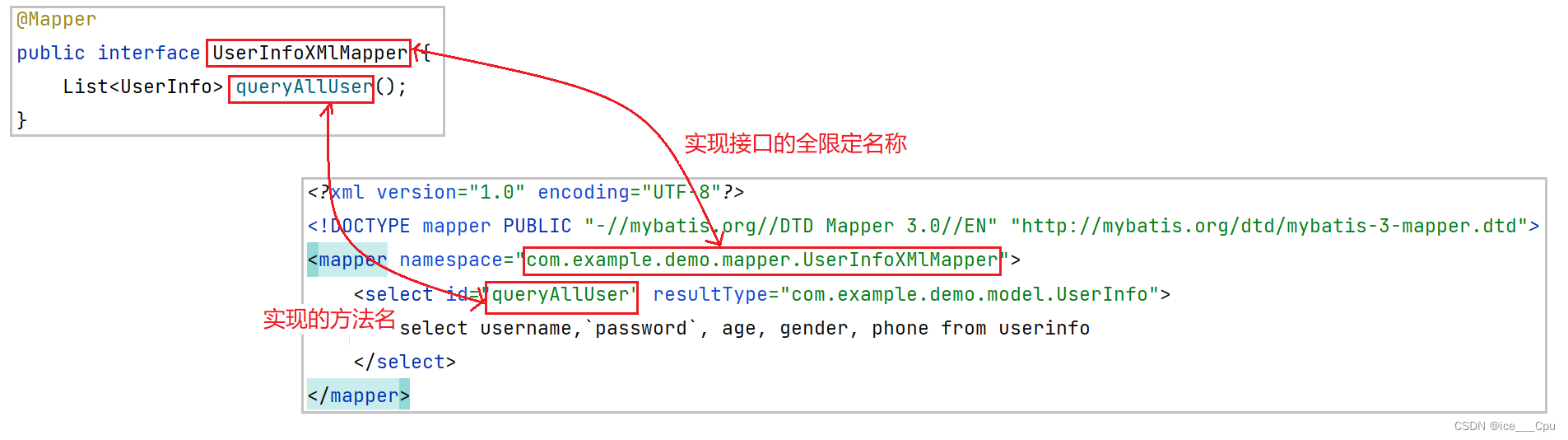
<mapper namespace="com.example.demo.mapper.UserInfoXMlMapper"><select id="queryAllUser" resultType="com.example.demo.model.UserInfo">select username,`password`, age, gender, phone from userinfo</select>
</mapper>
这段代码是一个 MyBatis 的 XML 映射文件,用于配置数据库操作的 SQL 语句和映射关系。让我一步步来解释:
-
mapper namespace="com.example.demo.mapper.UserInfoXMlMapper":这行代码指定了 XML 映射文件的命名空间,即该文件中定义的 SQL 语句的作用域为 com.example.demo.mapper.UserInfoXMlMapper。 -
<select id="queryAllUser" resultType="com.example.demo.model.UserInfo">:这是一个 SQL 查询语句的定义。其中:id="queryAll":指定了这个 SQL 查询语句的唯一标识符,resultType="com.example.demo.model":指定了查询结果映射类型,即查询结果将被映射为.example.demo.model.UserInfo 类型的对象。这意味着查询结果的每一行将会被映射为一个 UserInfo 对象。
-
select username,password, age, gender, phone from userinfo:这是实际的 SQL 查询句。它从名为 的表中选择了 username、password、age、gender 和 phone 列的值。这个查询将返回符合条件的所有信息。
1.2.3 单元测试
@SpringBootTest
class UserInfoMapperTest {@Autowiredprivate UserInfoMapper userInfoMapper;@Testvoid queryAllUser() {List<UserInfo> userInfoList = userInfoMapper.queryAllUser();System.out.println(userInfoList);}
}
运行结果如下:

1.3 增删改查
接下来,我们来实现⼀下用户的增删改查操作.
1.3.1 增(Insert)
UserInfoMapper 接口:
Integer insertUser(UserInfo userInfo);
UserInfoMapper.xml 实现:
<insert id="insertUser">insert into userinfo (username, `password`, age, gender, phone) values (#{username}, #{password}, #{age},#{gender},#{phone})
</insert>
如果使用 @Param 设置参数名称的话, 使用方法和注解类似
UserInfoMapper 接口:
Integer insertUser(@Param("userinfo") UserInfo userInfo);
UserInfoMapper.xml 实现:
<insert id="insertUser">insert into userinfo (username, `password`, age, gender, phone) values (#{userinfo.username},#{userinfo.password},#{userinfo.age},#{userinfo.gender},#{userinfo.phone})
</insert>
返回自增 id:
接口定义不变, Mapper.xml 实现 设置 useGeneratedKeys 和 keyProperty 属性
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">insert into userinfo (username, `password`, age, gender, phone) values (#{userinfo.username},#{userinfo.password},#{userinfo.age},#{userinfo.gender},#{userinfo.phone})
</insert>
1.3.2 删(Delete)
UserInfoMapper 接口:
Integer deleteUser(Integer id);
UserInfoMapper.xml 实现:
<delete id="deleteUser">delete from userinfo where id = #{id}
</delete>
1.3.3 改(Update)
UserInfoMapper 接口:
Integer updateUser(UserInfo userInfo);
UserInfoMapper.xml 实现:
<update id="updateUser">update userinfo set username=#{username} where id=#{id}
</update>
1.3.4 查(Select)
同样的, 使用 XML 的方式进行查询, 也存在数据封装的问题,我们把 SQL 语句进行简单修改, 查询更多的字段内容
<select id="queryAllUser" resultType="com.example.demo.model.UserInfo">select id, username,`password`, age, gender, phone, delete_flag, create_time, update_time from userinfo
</select>
运行结果:
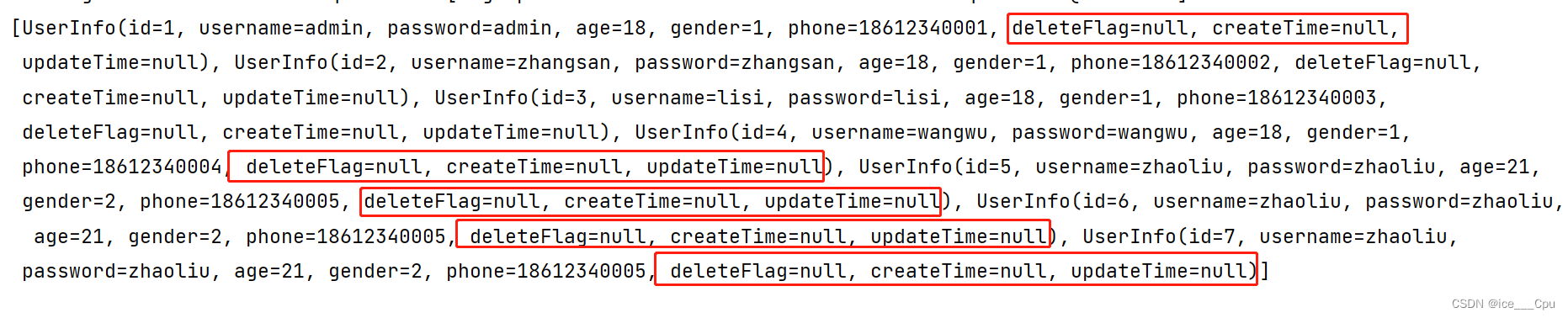
结果显示: deleteFlag, createTime, updateTime 也没有进行赋值.
解决办法和注解类似:
- 起别名
- 结果映射
- 开启驼峰命名
其中1,3的解决办法和注解⼀样,不再多说, 接下来看下 xml 如何来写结果映射
- Mapper.xml
<resultMap id="BaseMap" type="com.example.demo.model.UserInfo"><id column="id" property="id"></id><result column="delete_flag" property="deleteFlag"></result><result column="create_time" property="createTime"></result><result column="update_time" property="updateTime"></result>
</resultMap><select id="queryAllUser" resultMap="BaseMap">select id, username,`password`, age, gender, phone, delete_flag, create_time, update_time from userinfo
</select>

开发中使用哪种模式这个问题, 没有明确答案. 仁者见仁智者见智, 并没有统⼀的标准, 更多是取决于你的团队或者项目经理, 项目负责人.
1.4 其他查询操作
1.4.1 多表查询
多表查询和单表查询类似, 只是 SQL 不同而已
1.4.1.1 准备工作
上⾯建了⼀张用户表, 我们再来建⼀张文章表, 进行多表关联查询.文章表的 uid, 对应用户表的 id.
数据准备:
-- 创建⽂章表
DROP TABLE IF EXISTS articleinfo;
CREATE TABLE articleinfo (id INT PRIMARY KEY auto_increment,title VARCHAR ( 100 ) NOT NULL,content TEXT NOT NULL,uid INT NOT NULL,delete_flag TINYINT ( 4 ) DEFAULT 0 COMMENT '0-正常, 1-删除',create_time DATETIME DEFAULT now(),update_time DATETIME DEFAULT now()
) DEFAULT charset 'utf8mb4';-- 插⼊测试数据
INSERT INTO articleinfo ( title, content, uid ) VALUES ( 'Java', 'Java正⽂', 1);
对应 Model:
import lombok.Data;
import java.util.Date;@Data
public class ArticleInfo {private Integer id;private String title;private String content;private Integer uid;private Integer deleteFlag;private Date createTime;private Date updateTime;
}
1.4.1.2 数据查询
需求: 根据 uid 查询作者的名称等相关信息
SQL代码:
SELECTta.id,ta.title,ta.content,ta.uid,tb.username,tb.age,tb.gender
FROMarticleinfo taLEFT JOIN userinfo tb ON ta.uid = tb.id
WHEREta.id =1
补充实体类:
@Data
public class ArticleInfo {private Integer id;private String title;private String content;private Integer uid;private Integer deleteFlag;private Date createTime;private Date updateTime;//⽤⼾相关信息private String username;private Integer age;private Integer gender;
}
接口定义:
import com.example.demo.model.ArticleInfo;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface ArticleInfoMapper {@Select("SELECT ta.id,ta.title,ta.content,ta.uid,tb.username,tb.age,tb.gender " + "FROM articleinfo ta LEFT JOIN userinfo tb ON ta.uid = tb.id " + "WHERE ta.id = #{id}")
ArticleInfo queryUserByUid(Integer id);
}
Mybatis 不分单表还是多表, 主要就是三部分: SQL, 映射关系和实体类,通过映射关系, 把 SQL 运行结果和实体类关联起来.
1.5 #{} 和 ${}
MyBatis 参数赋值有两种方式, 咱们前面使用了 #{} 进行赋值, 接下来我们看下⼆者的区别
1.5.1 #{} 和${} 使用
- 先看 Interger 类型的参数
@Select("select username, `password`, age, gender, phone from userinfo where id= #{id} ")
UserInfo queryById(Integer id);
观察我们打印的日志:
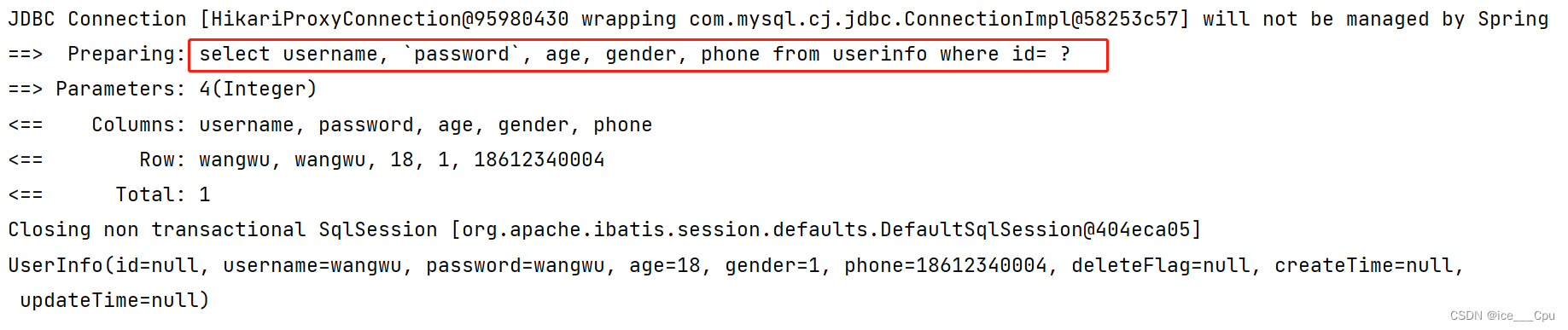
发现我们输出的 SQL 语句:
select username, `password`, age, gender, phone from userinfo where id= ?
我们输入的参数并没有在后面拼接,id 的值是使用 ? 进行占位. 这种 SQL 我们称之为 “预编译SQL”
我们把 #{} 改成 ${} 再观察打印的日志:
@Select("select username, `password`, age, gender, phone from userinfo where id= ${id} ")
UserInfo queryById(Integer id);
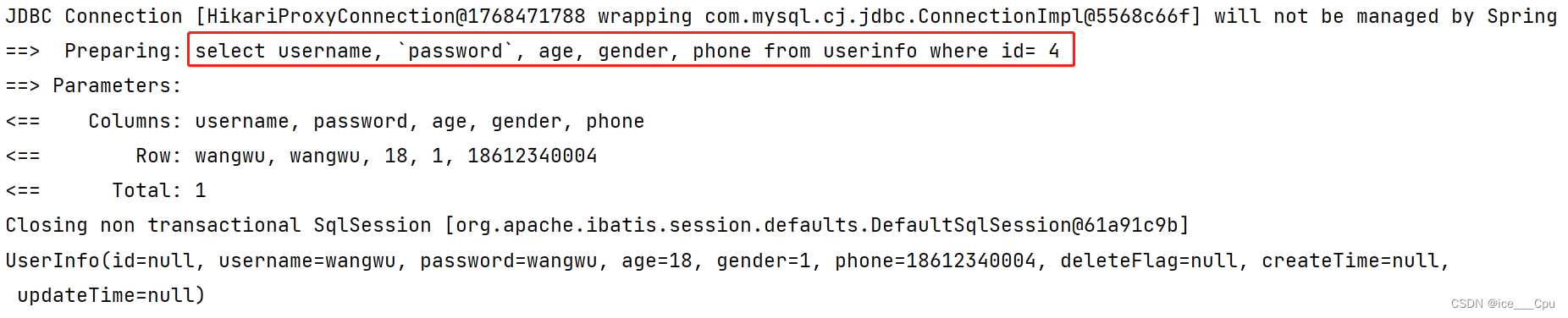
可以看到, 这次的参数是直接拼接在 SQL 语句中了.
- 接下来我们再看 String 类型的参数
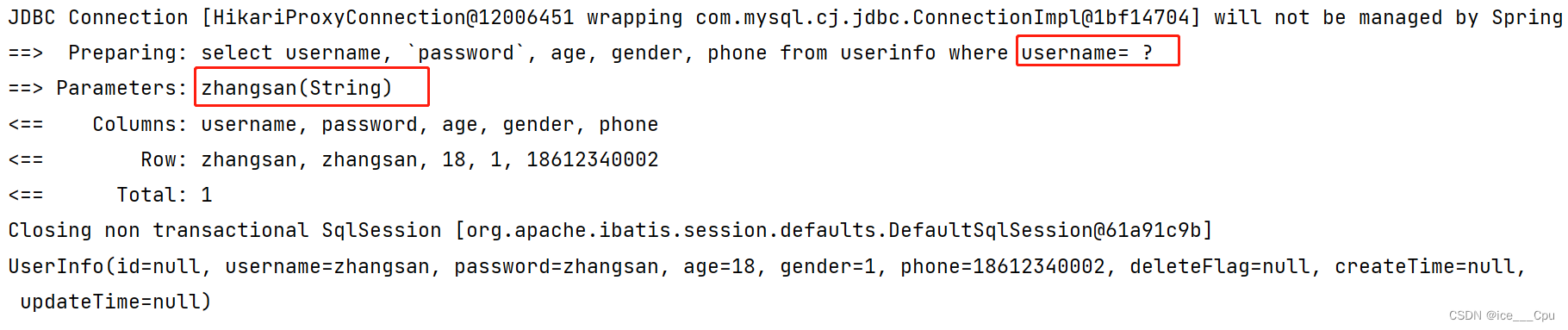
@Select("select username, `password`, age, gender, phone from userinfo where username= #{name} ")
UserInfo queryByName(String name);
观察我们打印的日志, 结果正常返回:
我们把 #{} 改成 ${} 再观察打印的日志:
@Select("select username, `password`, age, gender, phone from userinfo where username= ${name} ")
UserInfo queryByName(String name);
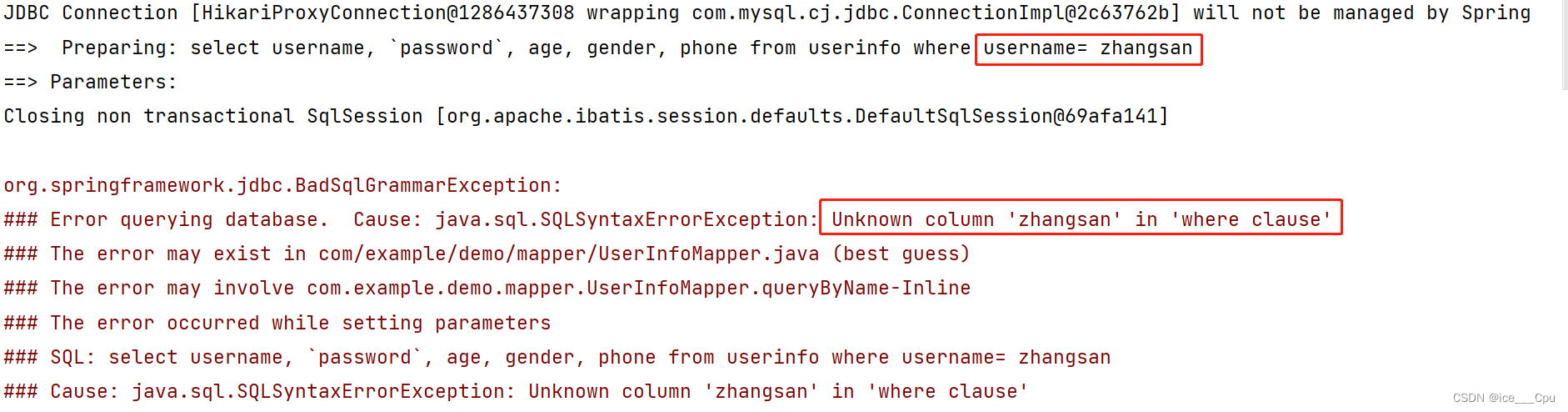
可以看到, 这次的参数依然是直接拼接在 SQL 语句中了, 但是字符串作为参数时, 需要添加引号 ‘’ , 使用 ${} 不会拼接引号 ‘’ , 导致程序报错.
修改代码如下:
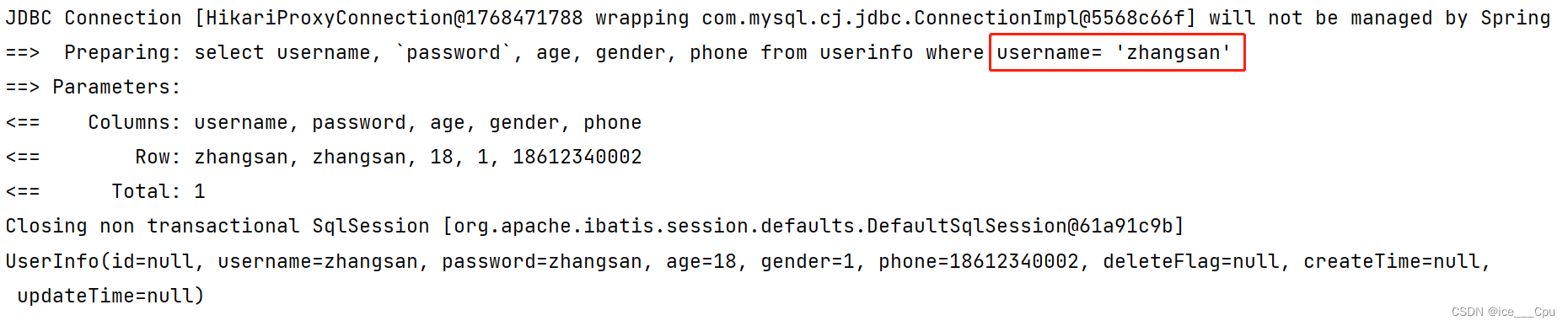
@Select("select username, `password`, age, gender, phone from userinfo where username= '${name}' ")
UserInfo queryByName(String name);
再次运行, 结果正常返回
从上面两个例子可以看出:
- #{} 使用的是预编译 SQL, 通过 ? 占位的方式, 提前对 SQL 进行编译, 然后把参数填充到 SQL 语句中. #{} 会根据参数类型, 自动拼接引号 ‘’ .
- ${} 会直接进行字符替换, ⼀起对 SQL 进行编译. 如果参数为字符串, 需要加上引号 ‘’
参数为数字类型时, 也可以加上, 查询结果不变, 但是可能会导致索引失效, 性能下降.
1.5.2 #{} 和 ${}区别
#{} 和 ${} 的区别就是预编译 SQL 和即时 SQL 的区别.
-
预编译 SQL(Prepared Statement):
- 预编译 SQL 是指在执行 SQL 语句之前,数据库会先将 SQL 语句编译成一种特殊的格式,这种格式包含了占位符,而不是具体的参数值。
- 在执行时,应用程序会将参数值传递给数据库,数据库会将参数值填充到 SQL 语句中占位符中,然后执行已经编译好的句。
- 预编译 SQL 的好处在于,可以减少 SQL 注入的风险,因为参数值不会直接与 SQL 语句拼接,而是通过占位符的方式传递,提高了安全性。
- 另外,预编译 SQL 还可以提高执行效率,因为数据库执行 SQL 语句之前已经进行了编译和优化,可以重复利用编译后的执行计划,减少了重复编译的开销。
-
即时 SQL(Immediate SQL):
- 即时 SQL 是指每次执行 SQL 语句时,都会将 语句直接发送给数据库,并在数据库端即时编译和执行。
- 这种方式下,每次执行 SQL 都需要经过编译和优的过程,可能会增加一定的开销。
- 即时 SQL 的好处在于可以动态生成 SQL 语句,适用于一些动态生成 SQL 语句的场景,但相对于预编译 SQL,可能存在一定的安全风险和执行效率上的损失。
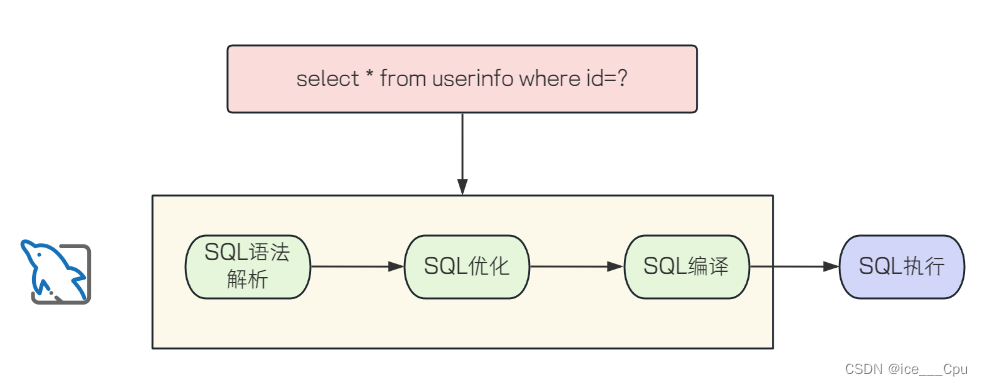
下面简单讲解一个 SQL 注入的情况:、
- 正常访问情况:
@Test
void queryByName() {List<UserInfo> userInfos = userInfoMapper.queryByName("admin");System.out.println(userInfos);
}
结果运行正常
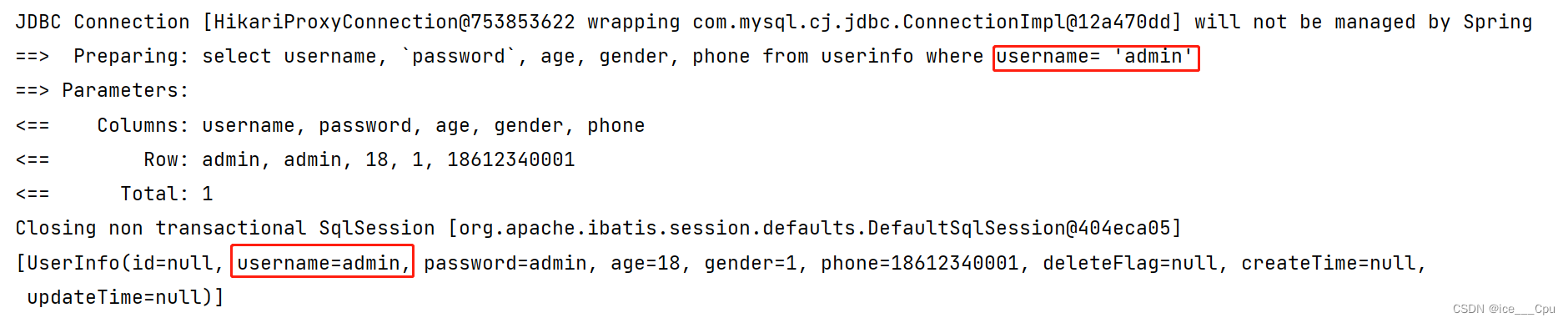
- SQL 注入场景:
@Test
void queryByName() {List<UserInfo> userInfos = userInfoMapper.queryByName("' or 1='1");System.out.println(userInfos);
}
结果依然被正确查询出来了, 其中参数 or 被当做了 SQL 语句的⼀部分
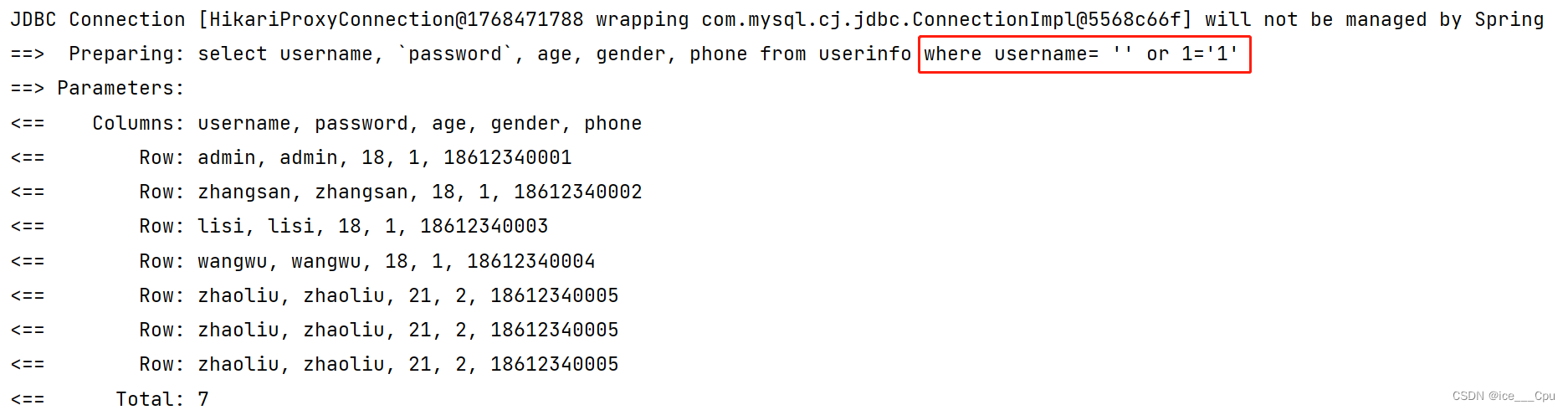
可以看出来, 查询的数据并不是自己想要的数据. 所以用于查询的字段,尽量使用 #{} 预查询的方式
1.6 排序功能
从上面的例子中, 可以得出结论: ${} 会有 SQL 注入的风险, 所以我们尽量使用 #{} 完成查询,既然如此, 是不是 ${} 就没有存在的必要性了呢?当然不是.接下来我们看下 ${} 的使用场景
Mapper实现:
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " + "from userinfo order by id ${sort} ")
List<UserInfo> queryAllUserBySort(String sort);
使用 ${sort} 可以实现排序查询, 而使用 #{sort} 就不能实现排序查询了,我们试着把 ${} 改成 #{}
注意:此处 sort 参数为 String 类型, 但是 SQL 语句中, 排序规则是不需要加引号 ‘’ 的, 所以此时的 ${sort} 也不加引号
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " + "from userinfo order by id #{sort} ")
List<UserInfo> queryAllUserBySort(String sort);
运行结果:
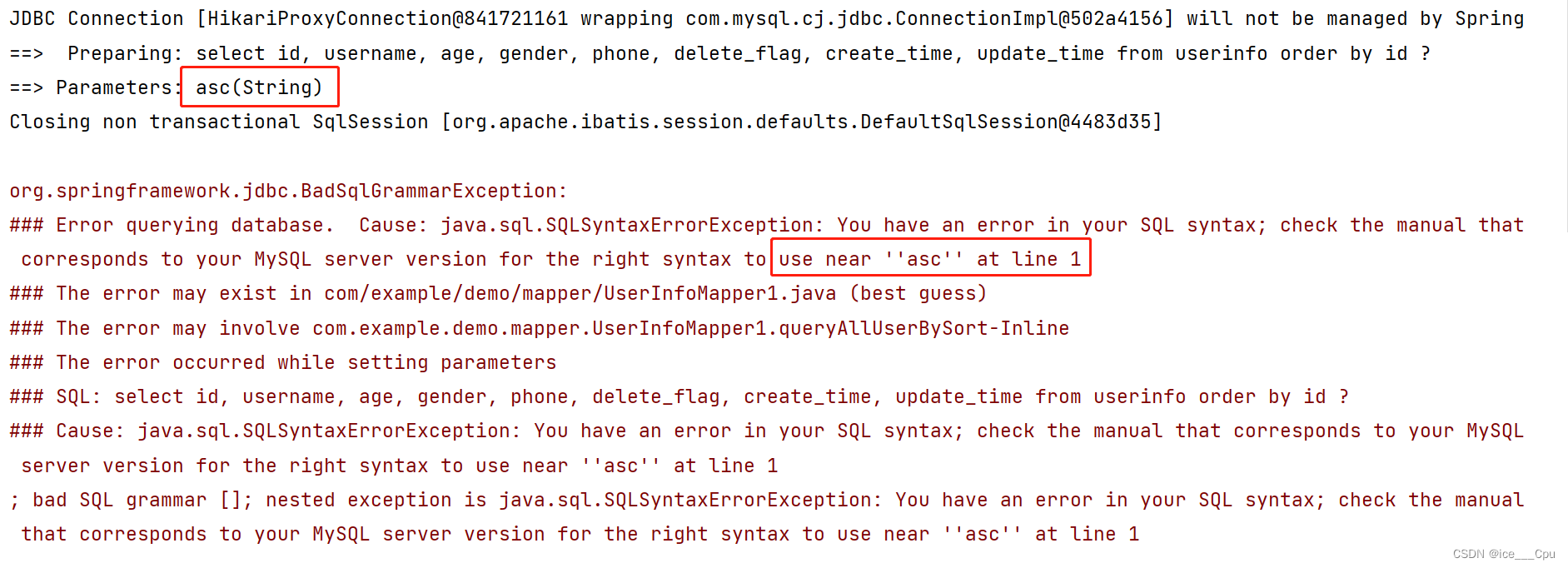
可以发现, 当使⽤ #{sort} 查询时, asc 前后自动给加了引号, 导致 sql 错误,#{} 会根据参数类型判断是否拼接引号 ‘’,如果参数类型为 String, 就会加上引号.
除此之外, 还有表名作为参数时, 也只能使用 ${}
1.7 like 查询
like 使用 #{} 报错
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " + "from userinfo where username like '%#{key}%' ")
List<UserInfo> queryAllUserByLike(String key);
把 #{} 改成 ${} 可以正确查出来, 但是 ${} 存在 SQL 注入的问题, 所以不能直接使用 ${}.
解决办法: 使用 mysql 的内置函数 concat() 来处理,实现代码如下:
@Select("select id, username, age, gender, phone, delete_flag, create_time, update_time " + "from userinfo where username like concat('%',#{key},'%')")
List<UserInfo> queryAllUserByLike(String key);
二: 数据库连接池
数据库连接池技术可以避免频繁的创建连接, 销毁连接,下面我们来了解下数据库连接池
2.1 引入连接池
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用⼀个现有的数据库连接,而不是再重新建立⼀个.
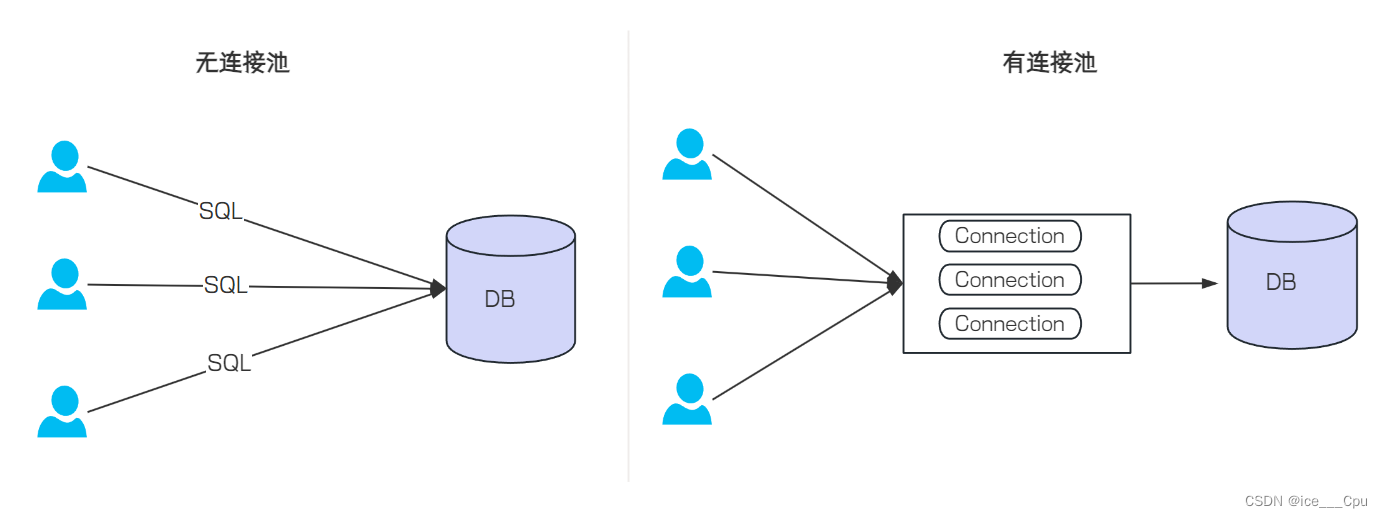
- 没有使用数据库连接池的情况:
每次执行 SQL 语句, 要先创建⼀个新的连接对象, 然后执行 SQL 语句, SQL 语句执行完,再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接比较消耗资源
- 使用数据库连接池的情况:
程序启动时, 会在数据库连接池中创建⼀定数量的 Connection 对象, 当客户请求数据库连接池,会从数据库连接池中获取 Connection 对象, 然后执行 SQL, SQL 语句执行完, 再把 Connection 归还给连接池.
数据库连接池优点:
- 减少了网络开销
- 资源重用
- 提升了系统的性能
2.2 使用
常见的数据库连接池:
- C3P0
- DBCP
- Druid
- Hikari
目前比较流行的是 Hikari, Druid
- Hikari : SpringBoot 默认使用的数据库连接池

- Druid
如果我们想把默认的数据库连接池切换为 Druid 数据库连接池, 只需要引入相关依赖即可
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.17</version>
</dependency>
运行结果:
三:MySQL 开发企业规范
- 表名,字段名使用小写字母或数字, 单词之间以下划线分割. 尽量避免出现数字开头或者两个下划线中间只出现数字. 数据库字段名的修改代价很大, 所以字段名称需要慎重考虑。
MySQL 在 Windows 下不区分大小写, 但在 Linux 下默认是区分大小写. 因此, 数据库名, 表名, 字段名都不允许出现任何大写字母, 避免节外生枝
- 正例: aliyun_admin, rdc_config, level3_name
- 反例: AliyunAdmin, rdcConfig, level_3_name
- 表必备三字段: id, create_time, update_time
下面详细解释一下这三个字段
- id 必为主键, 类型为 bigint unsigned, 单表时自增, 步长为 1
- create_time, update_time 的类型均为 datetime 类型, create_time 表示创建时间,
- update_time表示更新时间
有同等含义的字段即可, 字段名不做强制要求
- 在表查询中, 避免使用 * 作为查询的字段列表, 要用哪些字段标明哪些字段即可
原因有三点:
- 增加查询分析器解析成本
- 增减字段容易与 resultMap 配置不⼀致
- 无用字段增加网络消耗, 尤其是 text 类型的字段